
根据kafka官方API对线上问题进行优化
目录
目标
- 分析并解决消息丢失问题;
- 分析并解决消息重复消费问题;
- 分析并解决消息积压问题;
- 实现一个分区和多个分区消息顺序消费的功能;
- 掌握设计分区最佳数量的方法。
环境
- Spring Boot版本:2.7.0
- kafka版本:3.1.0
kafka官方API
DOCUMENTATION![]() https://kafka.apache.org/documentation/#apiSpring Kafka Support
https://kafka.apache.org/documentation/#apiSpring Kafka Support![]() https://github.com/spring-projects/spring-kafka
https://github.com/spring-projects/spring-kafka
kafka消息丢失的问题
分析
消息丢失发生的环节
- 生产者发送消息时;
- 消费者消费消息时。
生产者发送消息丢失的原因和解决思路
生产者发送消息到kafka集群,如果消息在leader和follower之间还未完成同步,此时leader宕机。
思路:通过acks进行消息确认,即设定消息至少同步到多少个broker才返回客户端提示发送成功。
消费者消费消息丢失的原因和解决思路
消费者设定自动提交偏移量和提交偏移量的时间间隔,消费者拿到消息后处理相关业务,此时业务还未处理完偏移量就自动提交了,如果业务代码异常则会导致消息未被消费完,从而引发消息丢失问题。
思路:设置手动提交偏移量;消费者拿到消息并处理完业务才提交偏移量。
解决生产者发送消息丢失的问题
官方文档
The number of acknowledgments the producer requires the leader to have received before considering a request complete. This controls the durability of records that are sent. The following settings are allowed:
acks=0If set to zero then the producer will not wait for any acknowledgment from the server at all. The record will be immediately added to the socket buffer and considered sent. No guarantee can be made that the server has received the record in this case, and theretriesconfiguration will not take effect (as the client won't generally know of any failures). The offset given back for each record will always be set to-1.acks=1This will mean the leader will write the record to its local log but will respond without awaiting full acknowledgement from all followers. In this case should the leader fail immediately after acknowledging the record but before the followers have replicated it then the record will be lost.acks=allThis means the leader will wait for the full set of in-sync replicas to acknowledge the record. This guarantees that the record will not be lost as long as at least one in-sync replica remains alive. This is the strongest available guarantee. This is equivalent to the acks=-1 setting.Note that enabling idempotence requires this config value to be 'all'. If conflicting configurations are set and idempotence is not explicitly enabled, idempotence is disabled.
Type: string Default: all Valid Values: [all, -1, 0, 1] Importance: low
When a producer sets acks to "all" (or "-1"), min.insync.replicas specifies the minimum number of replicas that must acknowledge a write for the write to be considered successful. If this minimum cannot be met, then the producer will raise an exception (either NotEnoughReplicas or NotEnoughReplicasAfterAppend).
When used together, min.insync.replicas and acks allow you to enforce greater durability guarantees. A typical scenario would be to create a topic with a replication factor of 3, set min.insync.replicas to 2, and produce with acks of "all". This will ensure that the producer raises an exception if a majority of replicas do not receive a write.
Type: int Default: 1 Valid Values: [1,...] Importance: high Update Mode: cluster-wide
官网文档释义
acks=all或者acks=-1
此时要看min.insync.replicas(最小同步副本数量,默认等于1)参数设定的值。例如:min.insync.replicas=2,表示需要有2个kafka节点写入数据才会返回客户端提示成功。推荐大于等于2。
acks=0
生产者不需要等待kafka节点回复确认收到消息,就可以继续发送下一条消息。
acks=1
消息写入Leader(主节点),但是不需要等待其他Follower(从节点)同步消息,就可以继续发送下一条消息。如果Follower没有同步到消息,而Leader宕机,则消息丢失。这种模式等同于acks=all或者acks=-1,且min.insync.replicas=1。
综上所述
acks=all或者acks=-1,且min.insync.replicas>1时安全性最高,但发送消息的效率差。适用于金融业务。
acks=0时发送消息效率最高,但安全性最差。适用不重要的日志。
acks=1时介于两者之间。
实战
《普通项目》
第一步:配置acks模式。
Properties props = new Properties();
props.put(ProducerConfig.ACKS_CONFIG,"all");第二步:配置kafka服务器配置。
#我这里设定值为2,表示消息至少需要同步到一个Leader和一个Follower上才会返回客户端提示成功。
min.insync.replicas=2《Spring Boot项目》
第一步:在application.yml中配置acks模式。
spring:
kafka:
producer:
acks: -1第二步:配置kafka服务器配置。
#我这里设定值为2,表示消息至少需要同步到一个Leader和一个Follower上才会返回客户端提示成功。
min.insync.replicas=2解决消费者消费消息丢失的问题
官方文档
If true the consumer's offset will be periodically committed in the background.
Type: boolean Default: true Valid Values: Importance: medium
The frequency in milliseconds that the consumer offsets are auto-committed to Kafka if
enable.auto.commitis set totrue.
Type: int Default: 5000 (5 seconds) Valid Values: [0,...] Importance: low
官网文档释义
enable.auto.commit
如果设置为true,则消费者的偏移量自动提交会以一定的频率自动提交。默认值为true。
auto.commit.interval.ms
如果enable.auto.commit=true,则该配置生效,其值表示消费者自动提交的频率,单位毫秒。默认事件是5秒。
实现
《普通项目》
第一步:关闭自动提交。
Properties props = new Properties();
props.setProperty(ConsumerConfig.ENABLE_AUTO_COMMIT_CONFIG, "false");第二步:设置手动提交,这里介绍手动同步提交和手动异步提交。
KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅给定的主题列表以获取动态分配的分区。
consumer.subscribe(Arrays.asList(TOPIC_NAME));
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
//100毫秒循环一次。
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println("偏移量=" + record.offset() + ";" + "key=" + record.key() + ";" + "value=" + record.value());
buffer.add(record);
}
//每当消费消息>=5就提交一次偏移量。
if (buffer.size() >= 5) {
System.out.println("提交偏移量。");
//一般可以在这里加try,在catch里面重复提交。
consumer.commitSync();
buffer.clear();
}
} KafkaConsumer<String, String> consumer = new KafkaConsumer<>(props);
//订阅给定的主题列表以获取动态分配的分区。
consumer.subscribe(Arrays.asList(TOPIC_NAME));
List<ConsumerRecord<String, String>> buffer = new ArrayList<>();
while (true) {
//100毫秒循环一次。
ConsumerRecords<String, String> records = consumer.poll(Duration.ofMillis(100));
for (ConsumerRecord<String, String> record : records) {
System.out.println("偏移量=" + record.offset() + ";" + "key=" + record.key() + ";" + "value=" + record.value());
buffer.add(record);
}
//每当消费消息>=5就提交一次偏移量。
if (buffer.size() >= 5) {
System.out.println("提交偏移量。");
consumer.commitAsync(new OffsetCommitCallback() {
@Override
public void onComplete(Map<TopicPartition, OffsetAndMetadata> map, Exception e) {
//e!=null表示异步提交失败,此时可以再次提交。
//生产上一般用同步提交。
if(e!=null){
System.out.println("异步提交消息失败。");
}
}
});
buffer.clear();
}
}《Spring Boot项目》
第一步:在application.yml中关闭自动提交。
spring:
kafka:
consumer:
enable-auto-commit: false
listener:
#确认以后立刻提交偏移量。要关闭自动提交才生效。
ack-mode: MANUAL_IMMEDIATE第二步:在消费方法中手动提交偏移量。
@KafkaListener(
topics = IPHONE_TOPIC,
groupId = APPLE_GROUP
)
public void setCommitType(ConsumerRecord<String, String> record, Acknowledgment ack) {
System.out.println("setCommitType");
System.out.println("内容:" + record.value());
System.out.println("分区:" + record.partition());
System.out.println("偏移量:" + record.offset());
System.out.println("创建消息的时间戳:" + record.timestamp());
ack.acknowledge();
}kafka消息重复消费的问题
分析
消息重复的环节
生产者发送消息时。
生产者重复发送消息的原因和解决思路
生产者发送消息到kafka集群,因为网络延迟而没有及时客户端提示发送成功,生产者此时认为消息发送失败,触发重试机制,使得消息重复发送,最终导致消费者消费到相同的消息。
思路:给消息设定唯一的id,在分布式锁中把这个id当成锁。或者在数据库设定多个字段组合的唯一索引,保证数据唯一。
kafka顺序消费消息
分析
kafka有消费者组的概念。消费者隶属于消费者组,同一个分区的消息可以被多个消费者消费,但是同一个消费者组中只能有一个消费者可以消费。
kafka有分区的概念。每个Topic下都至少有一个分区,分区内部的消息是有序的。
方案
设置一个主题只有一个分区,把这个主题指定给一个消费者组消费。根据消费者组和分区的特新可以保证顺序消费。
kafka消息积压的问题
分析
kafka消费者poll数据非常快,但是消费者获取数据以后还要进行业务处理,如果业务流程耗时长,或者网络拥堵等因素发生,则会导致数据积压,严重影响数据处理的实时性。
网络不稳定导致消息积压的解决方案
kafka集群一直处于平稳高效状态,某天突然出现消息积压,此时查看kafka日志文件,发现是网络不稳定导致Broker和消费者之间的心跳超时导致消费者被剔除出了消费者组(Rebalance机制)。
思路:加大消费者和Broker之间的心跳超时时间。
官网文档
The expected time between heartbeats to the consumer coordinator when using Kafka's group management facilities. Heartbeats are used to ensure that the consumer's session stays active and to facilitate rebalancing when new consumers join or leave the group. The value must be set lower than
session.timeout.ms, but typically should be set no higher than 1/3 of that value. It can be adjusted even lower to control the expected time for normal rebalances.
Type: int Default: 3000 (3 seconds) Valid Values: Importance: high
官网文档释义
消费者从Broker拉取消息,他们之间通过心跳机制来建立长连接,如果超过了设定值,则消费者组重新平衡,该消费者会被剔除出消费者组,分区将重新分配。这个值必须小于session.timeout.ms值,通常该值小于等于session.timeout.ms值的三分之一,默认值为3秒。
实现
《普通项目》
Properties props = new Properties();
//心跳时间为5秒
props.setProperty(ConsumerConfig.HEARTBEAT_INTERVAL_MS_CONFIG,"5000");《Spring Boot项目》
spring:
kafka:
consumer:
properties:
heartbeat.interval.ms: 5000业务流程耗时长导致消息积压的解决方案
消费者poll到消息后如果在一定时间内没有再次poll,则消费者被剔除出消费者组(Rebalance机制)。
思路:1.加大消费者poll的间隔时间;2.减少批量拉取消息数量;3.把消息转发到其他主题,其他消费者来消费;4.增加分区和消费者数量。
官网文档(max.poll.interval.ms)
The maximum delay between invocations of poll() when using consumer group management. This places an upper bound on the amount of time that the consumer can be idle before fetching more records. If poll() is not called before expiration of this timeout, then the consumer is considered failed and the group will rebalance in order to reassign the partitions to another member. For consumers using a non-null
group.instance.idwhich reach this timeout, partitions will not be immediately reassigned. Instead, the consumer will stop sending heartbeats and partitions will be reassigned after expiration ofsession.timeout.ms. This mirrors the behavior of a static consumer which has shutdown.
Type: int Default: 300000 (5 minutes) Valid Values: [1,...] Importance: medium
官网文档释义(max.poll.interval.ms)
消费者处理消息超时时间。即从消费者poll到消息后开始计时,如果因为处理业务耗时过长而没有再次poll,则消费者组将重新平衡,把分区分配给其他消费者。默认值是5分钟。
官网文档(max.poll.records)
The maximum number of records returned in a single call to poll(). Note, that
max.poll.recordsdoes not impact the underlying fetching behavior. The consumer will cache the records from each fetch request and returns them incrementally from each poll.
Type: int Default: 500 Valid Values: [1,...] Importance: medium
官网文档释义(max.poll.records)
消费者拉取消息时,最多一次批量拉取的数量,默认500条。
实现
《普通项目》
Properties props = new Properties();
//每次最多拉取200条消息
props.setProperty(ConsumerConfig.MAX_POLL_RECORDS_CONFIG,"200");
//poll间隔10分钟。
props.setProperty(ConsumerConfig.MAX_POLL_INTERVAL_MS_CONFIG,"600000");《Spring Boot项目》
第一步:在application.yml中配置相关配置。
spring:
kafka:
consumer:
properties:
max.poll.interval.ms: 600000
max.poll.records: 3第二步:设置消费者数量。
@KafkaListener(
topics = IPHONE_TOPIC,
groupId = APPLE_GROUP,
//3个消费者
concurrency = "3"
)
public void setCommitType(ConsumerRecord<String, String> record, Acknowledgment ack) {
System.out.println("setCommitType");
System.out.println("内容:" + record.value());
System.out.println("分区:" + record.partition());
System.out.println("偏移量:" + record.offset());
System.out.println("创建消息的时间戳:" + record.timestamp());
ack.acknowledge();
}扩容分区(在kafka的bin目录下执行)
#把liNingShortSleeveTopic主题扩容为6个分区。
#注意:目前不支持减少分区,扩容前必须存在这个主题。
./kafka-topics.sh -alter --partitions 6 --bootstrap-server localhost:9092 --topic liNingShortSleeveTopic设计分区最佳数量的方法
分析
kafka自带了性能测试工具kafka-producer-perf-test.sh,为了更好地使用该工具,我们可以用命令查询该工具的使用方式和文档。
#在kafka的bin目录下执行
./kafka-producer-perf-test.sh -help释义
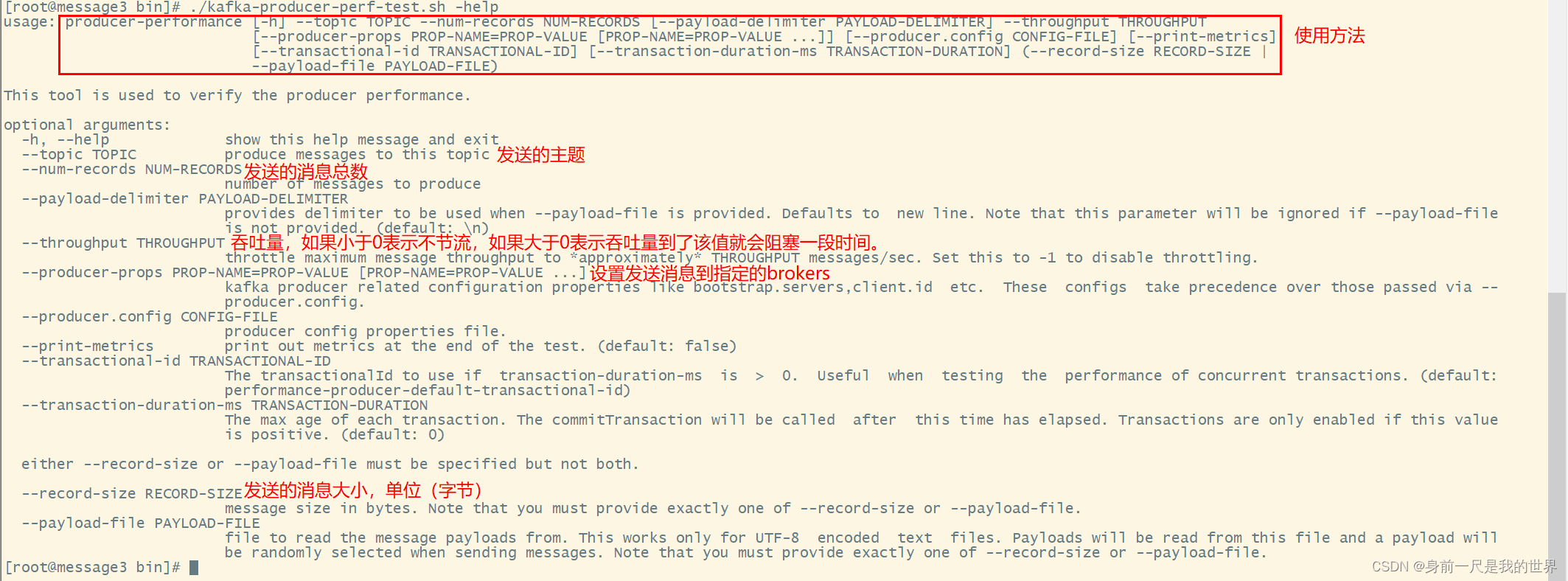
相关测试命令
#删除myTopic主题
./kafka-topics.sh --delete --topic myTopic --bootstrap-server 10.238.208.78:9093
#创建myTopic主题,共80个分区,同步三个副本因子
./kafka-topics.sh --create --bootstrap-server 10.238.208.78:9093 --replication-factor 3 --partitions 80 --topic myTopic
#查看myTopic主题详情
./kafka-topics.sh --describe --topic myTopic --bootstrap-server 10.238.208.78:9093
#向myTopic主题发送50万条消息,每条消息1KB大小。不节流,且消息同步机制acks=-1
./kafka-producer-perf-test.sh --topic myTopic --num-records 500000 --record-size 1024 --throughput -1 --producer-props bootstrap.servers=10.238.208.78:9093 acks=-1
#扩容分区(注意,只支持扩容,不支持缩容。)
./kafka-topics.sh -alter --partitions 100 --bootstrap-server 10.238.208.78:9093 --topic myTopic 测试报告
通过不断扩容测试,发现:当一次性发送50万条消息;acks=-1;消息大小为1KB时,分区数量=80的效率明显高于分区数量=100时的效率。其中分区数为80时,吞吐量为138.52兆/秒;每秒处理消息数量=141843;平均每次延迟182.67ms;每次发送消息最大延迟568.00ms。此时可以用二分法不停地测试,最终取得最佳分区数量。

相关文章
- 《Kafka官方文档》主页
- 《KAFKA官方文档》第三章:快速入门(一)
- 《KAFKA官方文档》第三章:快速入门(二)
- Kafka 0.8 配置参数解析
- 【Docker安装部署Kafka+Zookeeper详细教程】
- kafka可视化客户端工具(Kafka Tool)的基本使用
- 实时数仓系列-网易云音乐基于 Flink + Kafka 的实时数仓建设实践
- 【spring-kafka】属性concurrency的作用及如何配置(RoundRobinAssignor 、RangeAssignor)
- 【spring-kafka】@KafkaListener详解与使用
- Kafka实战:集群SSL加密认证和配置(最新版kafka-2.7.0)
- Kafka Internals: Consumers
- Kafka启用SASL_PLAINTEXT动态配置JAAS文件的几种方式
- Kafka Ecosystem(Kafka生态)
- Flink 1.9 实战:使用 SQL 读取 Kafka 并写入 MySQL
- kafka原理和实践(二)spring-kafka简单实践
- kafka踩坑——java找不到kafka-run-class.sh: line 309: exec: java: not found
- kafka-manager配置及安装Kerberos(Ambari-HDP)认证