
[译] Node.js 之战: 如何在生产环境中调试错误
在这篇文章,这篇文章讲述了 Netflix、RisingStack 和 nearForm 在生产环境中遇到 Node.js 错误的故事 - 因此你可以此为鉴,避免犯上同样的错误。同时你将会学到如何调试 Node.js 的错误。
感谢来自 Netflix 的 Yunong Xiao、来自 Strongloop 的 NearForm 和来自 Shubhra Kar 的 Matteo Collina 对这篇文章的见解与帮助。
过去4年里,我们在 RisingStack 的生产环境中运行 Node 应用,积累了许多相关经验 - 感谢Node.js 咨询、学习和开发 的业务支持。
Netflix 和 nearForm 的 Node 开发团队都一样,我们都有把调试过程记录下来的习惯,因此整个开发团队 (现在是全世界的开发团队) 都可以从我们的错误中学习。
Netflix 与 Node 调试: 了解你的依赖库让我们慢慢阅读我们的朋友 Yunong Xiao 在 Netflix 发生的故事。
Netflix 的开发团队发现他们的应用的响应时间在逐渐变长 - 他们部分终端的延迟每小时增加 10 ms。
同时,CPU 使用率的上升也反映了问题的存在。
不同时间段请求的传输时间 - 图片来源: Netflix
一开始,他们调查是否是 request handler 造成其响应时间变长。
在隔离测试后,他们发现 request handler 的响应时间稳定在 1 ms 左右。
所以问题并不是这个,他们开始怀疑到底层,是不是栈出现了问题。
接下来 Yunong 和 Netflix 开发团队的尝试是这个 CPU 火焰图 和 Linux 性能事件。
 Flame graph of Netflix Nodejs slowdown
Flame graph of Netflix Nodejs slowdown
火焰图反映了 Netflix 的响应速度正在变慢 - 图片来源: Netflix
你可以从火焰图中看到的东西是
它有一些很高的栈 (这代表有许多函数被调用) 并且一些矩形很宽 (代表我们在这些函数中耗费了一些时间)经过深入调查,开发团队发现 Express 的 router.handle 和 router.handle.next 有许多引用。
Express.js 的源代码揭示了一系列有趣的事情:
所有终端的 Route handlers 都储存在一个全局数组中。 Express.js 递归地遍历并唤醒所有 handlers 直到它找到合适的 route handler。在揭示谜题的解决方案前,我们需要知道更多的细节:
Netflix 的底层代码包含了每 6 分钟运行的定时代码,从拓展资源中抓取新的路由配置信息,更新应用的 route handlers 从而响应改变的信息。
这些是通过删除并添加新的 handlers 来实现的。意外的是,同时它再一次添加了相同的静态 handler - 甚至是以前的 API route handlers。这造成的结果是,响应时间额外增加了 10 ms。
从 Netflix 的错误中获取的教训从这里阅读整个故事: 火焰图中的 Node.js。
当你最需要帮助时候的专家指引 商业化 Node.js,由 RisingStack 提供 RisingStack CTO: "加密是要花时间的"你可能已经听过我们的故事 拆分单体式应用的故事,我们的 CTO Peter Marton 把 Trace (我们的 Node.js 监控系统) 分离成多个微服务模块。
我们现在讨论的错误是 Trace 开发时的响应速度变慢:
作为一个在 PaaS 运行的 早期 Trace 版本,它通过公共云来与我们的其他服务通信。
为了确保我们的请求是完整的,我们决定对所有请求进行签名。为了实现这个,我们看了 Joyent 的 HTTP signing library。很棒的是,request 这一模块支持开箱即用的HTTP签名。
解决方案代价不仅很大,而且会对我们的响应速度造成不好的影响。
网络延迟增加了我们的响应时间 - 图片来源: Trace
从图中可看到,所给定的终端响应速度为 180 ms,然而对于总体来说,单独两个服务的网络延迟只是 100 ms。
一开始,我们 用 Kubernetes 转移 PaaS provider。我们希望响应速度会快一点,这样内部网络就会平衡。
我们的方法奏效了 - 终端的响应速度提高了。
然而,我们想要更好的结果 - 大幅度降低 CPU 的使用率。下一步是分析 CPU 的使用情况,就像 Netflix 的人们做的一样:
从截图可以看出,crypto.sign 函数消耗的 CPU 时间最多,每次请求花费 10 ms。为了解决这个问题,你有两种选择:
如果你在可信任的环境中运行应用,你可以去除请求签名, 如果你在不可信的环境中运行,你可以升级你的机器让它拥有更强大的 CPU。 从 Peter Marton 中获取的教训nearForm: 不要堵塞 Node.js 的事件循环
React 现在很流行。开发者在前端和后端都会使用它,甚至他们更进一步用它来构建同构的 JavaScript 应用。
然而,渲染 React 页面会让 CPU 有挺大的负担,当绘制复杂的 React 内容时会受到 CPU 限制。
当你的 Node.js 正在进行绘制,它会堵塞事件循环,因为它的行为都是基于同步的。
结果就是,服务器可能会毫无反应 - 当请求堆积起来,会把所有的负担都堆在 CPU 上。
更糟的是即使请求端已经关闭,请求仍然会被处理 - 仍然会对 Node.js 应用造成负担,nearForm 对此有解释 Matteo Collina。
不仅是 React,大多数字符串操作也会这样。 如果你在构建 JSON REST APIs,你应该花心思在 JSON.parse 和 JSON.stringify。
Strongloop(现在是 Joyent) 的 Shubhra Kar 对此解释是,解析和转化成 JSON 字符串的等消耗巨大的操作也会消耗大量时间 (同时在这期间会堵塞事件循环)。
functionrequestHandler(req, res) {
const body = req.rawBody
let parsedBody
try {
parsedBody = JSON.parse(body)
catch(e) {
res.end(newError(Error parsing the body))
res.end(Record successfully received)
}
简易的 request handler
这个例子展示了一个简易的 request handler,用来解析 body。对于内容不多的情况下,它运行的挺好 - 然而,如果 JSON 的大小要以兆来描述的话,可能会花费数秒的时间来执行 而不是在毫秒时间内执行。同理 JSON.stringify 也一样。
为了缓解这个问题,首先你要了解它们。为此,你可以用 Matteo 的 loopbench 模块,或者Trace 的事件循环度量功能。
通过 loopbench,如果请求没有被实现,你可以返回状态码 503 给负载平衡器。为了启用这项功能,你要使用选项 instance.overLimit。这样 ELB 或者 NGINX 可以在不同的后端中重试,这样请求有可能会被处理。
一旦你了解这个问题并理解它,你就能开始修正它 - 你可以通过平衡 Node.js 流或者改变正在使用的架构来进行修正。
从 nearForm 中获取的教训基于node.js开发的文章生成器(八、网页版本的文章生成器--终章) # 引言 不知不觉,我们的文章生成器已经迎来了终章,这是网页版狗屁不通文章生成器的终章,也是本系列的最后一章。接下来我就带着大家完成最后这一部分的学习。 # 项目结构 项目目录如下
上面就是项目的目录,分别是lib文件夹,node_modules目录,resources文件夹,axios文件夹,router文件夹,和router_handle目录。 # lib目
基于node.js开发的文章生成器(七、网页版本的文章生成器--前端页面篇) # 引言 经过前面六章的学习,我们已经有了很多知识的储备,本次我们来制作文章生成器的前端部分。 # 数据的传递 接下来这里我们的传递方式主要通过form表单和axios两种方式来传递数据。 ## 传统的form表单传递 传统的form表单传递方式首先通过` form /form `标签来完成。
基于node.js开发的文章生成器(六、网页版本的文章生成器--工整优化篇) # 引言 前面我们已经学完了基于express框架下服务器的启动,get请求的接收与处理还有post请求的接收与处理。同时我们使用接口测试工具完成了接口的测试,响应值和接受值返回值都是正常的。那么为什么还有这一章节呢? # 问题的提出 原来我们之前对于get请求和Post请求的接受与处理,虽然可以实现其功能,但是整体代码都是写在一个js文件中的,这就导致我们js文件很臃肿,很难看,维护和开发成本都会大大的提高。 那么我们有没有一种方法,让我们的代码工整性和复用性都大大提高呢? # 解决的思路 我的解决方案是:抽成模块,进行模块化开发。 还是拿我们之前的cs.js作为讲解。
基于node.js开发的文章生成器(五、网页版本的文章生成器--准备篇) # 引言 这次我们来做网页版文章生成器,首先我们学习一些node.js开发服务器的入门知识。 # 框架的使用与导入 因为node原生开发服务器较麻烦,这里我们采用express框架来开发。 首先我们调出控制台,在控制台中输入 npm i express 然后等待一会儿,我们下载完express之后,通过 import express from express 导入 express 模块。 因为我们本项目采取的ES Moudle模块,所以这里我们使用import完成导入。 接下来通过定义app完成初始化 `const app = express();` 之后调用 app中的
基于node.js开发的文章生成器(四、控制台版本的文章生成器) 持续创作,加速成长!这是我参与「掘金日新计划 10 月更文挑战」的第4天,[点击查看活动详情](https://juejin.cn/post/7147654075599978532 https://juejin.cn/post/7147654075599978532 ) 通过前面的学习,随机句子的选取,段落的生成,文章的生成,我们都已经学会了。接下来我们本次来学习控制台版的狗屁不通文章生成器。 # readline模块的学习与尝试 接下来我们来学习并练习使用readline模块。readline模块是node7之后便开始提供的模块。 接下来我们来详细说说这个模块
基于node.js开发的文章生成器(三、占位符的替换与段落的生成与文章的生成) # 引言 前面我们已经学会了随机抽取语料库,接下来我们来真正意义上的合成句子。 # 生成废话的样子 
接下来我们来做占位符的替换,我们定义一个sentence的函数,然后传入两个参数,pick和replacer,其中,pick函数分为pickFamous,pi
基于node.js开发的文章生成器(二、语料库的读取与生成句子) 前面已经初始化了项目,同时完成了ES Modules的配置。接下来我们开始正式进入代码层面的学习。 # 语料库 首先在article目录下建立 resources 目录 ,在resources下建立一个data.json的json文件。我们这个demo的核心就是通过随机取一些语料库的文字来组成一篇文章。 data.json如下:
爱迪生{{said}},天才是百分之一的勤奋加百分之九十九的汗水。{{conclude}} , 查尔斯 史{{said}}
基于node.js开发的文章生成器(一、准备章) # 引言 今天带来的是狗屁不通文章生成器第一部分,即输入一个文章题目,和相应的字数,便自动生成一篇对应字数的文章。 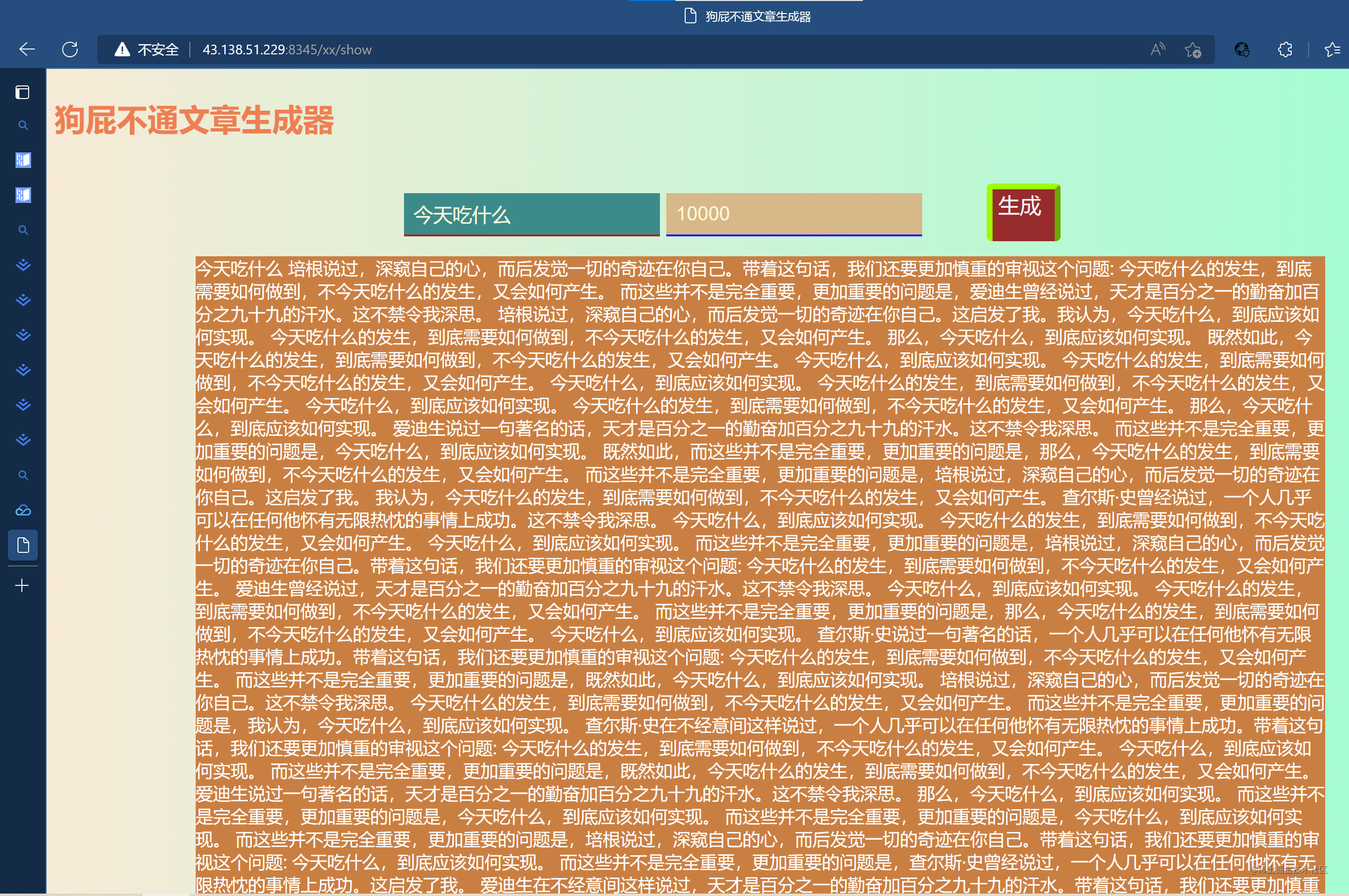 那么这么好玩的文章生成器是怎么制作的,接下来带大家制作这个文章生成器 首先创建一个文件夹article,然后切换到article目录下,调出cmd,执行如下代码完成项目的初始化 `npm init -y` 它会在项目目录下生成一个 pac
相关文章
- web项目中关于引入JS/css文件, 浏览器console出现 net::ERR_ABORTED错误的解决方法
- js实现页面与页面之间传值的三种方法
- node.js应用生成windows service的plugin——winser
- js中的cookie操作!
- 44dwr - util.js 功能(Submission box)
- 利用开源HTML5引擎lufylegend.js结合javascript实现的五子棋人机对弈
- js函数事件对象
- html直接引入vue.js错误(Uncaught ReferenceError: vue is not defined)
- CSS实现常用组件特效(不依赖JS)
- 微信小程序表单校验WxValidate.js使用
- VuePress在Node.js高版本报digital envelope routines::unsupported错误的解决方法
- JS魔法堂:通过marquee标签实现信息滚动效果
- JS魔法堂:追忆那些原始的选择器
- 2023华为OD机试 - 任务总执行时长(JS)
- JS冒泡和闭包案例分析
- js 日期格式转换(转载)
- Vue.js中 watch的理解以及深度监听