
Spark_Day07:Spark SQL(DataFrame是什么和数据分析(案例讲解))
Spark Day07:Spark SQL

文章目录
- Spark Day07:Spark SQL
- 02-[了解]-内容提纲
- 03-[了解]-SparkSQL 概述之前世今生
- 04-[了解]-SparkSQL 概述之官方定义及特性
- 05-[掌握]-DataFrame是什么及案例演示
- 06-[掌握]-DataFrame中Schema和Row
- 07-[掌握]-RDD转换DataFrame之反射类型推断
- 08-[掌握]-RDD转换DataFrame之自定义Schema
- 09-[掌握]-toDF函数指定列名称转换为DataFrame
- 10-[了解]-SparkSQL中数据处理方式
- 11-[掌握]-基于DSL分析(函数说明)和SQL分析
- 12-[掌握]-电影评分数据分析之需求说明和加载数据
- 13-[掌握]-电影评分数据分析之数据ETL
- 14-[掌握]-电影评分数据分析之SQL分析
- 15-[掌握]-电影评分数据分析之Shuffle分区数
- 16-[掌握]-电影评分数据分析之DSL分析
- 17-[掌握]-电影评分数据分析之保存结果至MySQL
- 18-[掌握]-电影评分数据分析之保存结果至CSV文件
- 附录一、创建Maven模块
02-[了解]-内容提纲
主要2个方面内容:DataFrame是什么和数据分析(案例讲解)
1、DataFrame是什么
SparkSQL模块前世今生、官方定义和特性
DataFrame是什么
DataFrame = RDD[Row] + Schema,Row表示每行数据,抽象的,并不知道每行Row数据有多少列,弱类型
案例演示,spark-shell命令行
Row 表示每行数据,如何获取各个列的值
RDD如何转换为DataFrame
- 反射推断
- 自定义Schema
调用toDF函数,创建DataFrame
2、数据分析(案例讲解)
编写DSL,调用DataFrame API(类似RDD中函数,比如flatMap和类似SQL中关键词函数,比如select)
编写SQL语句
注册DataFrame为临时视图
编写SQL语句,类似Hive中SQL语句
使用函数:
org.apache.spark.sql.functions._
电影评分数据分析
分别使用DSL和SQL
03-[了解]-SparkSQL 概述之前世今生
SparkSQL模块一直到Spark 2.0版本才算真正稳定,发挥其巨大功能,发展经历如下几个阶段。
1、Spark 1.0之前
Shark = Hive + Spark
将Hive框架源码,修改其中转换SQL为MapReduce,变为转换RDD操作,称为Shark
问题:
维护成本太高,没有更多精力在于框架性能提升
2、Spark 1.0开始提出SparkSQL模块
重新编写引擎Catalyst,将SQL解析为优化逻辑计划Logical Plan
此时数据结构:SchemaRDD
测试开发版本,不能用于生产环境
3、Spark 1.3版本,SparkSQL成为Release版本
数据结构DataFrame,借鉴与Python和R中dataframe
提供外部数据源接口
方便可以从任意外部数据源加载load和保存save数据
4、Spark 1.6版本,SparkSQL数据结构Dataset
坊间流传,参考Flink中DataSet数据结构而来
Dataset = RDD + schema
5、Spark 2.0版本,DataFrame和Dataset何为一体
Dataset = RDD + schema
DataFrame = Dataset[Row]
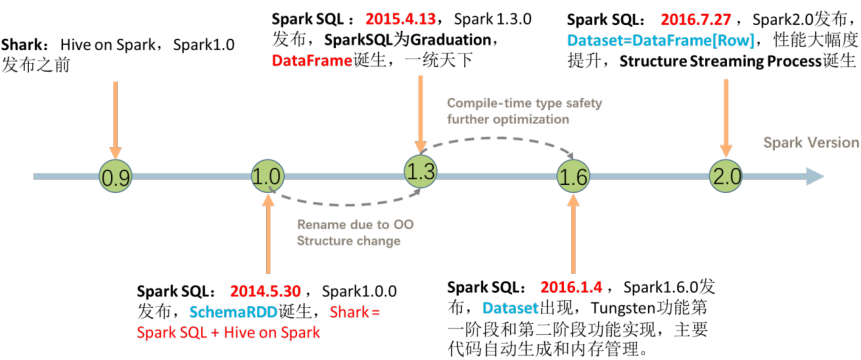
Spark 2.x发布时,将Dataset和DataFrame统一为一套API,以Dataset数据结构为主(Dataset= RDD + Schema),其中
DataFrame = Dataset[Row]。
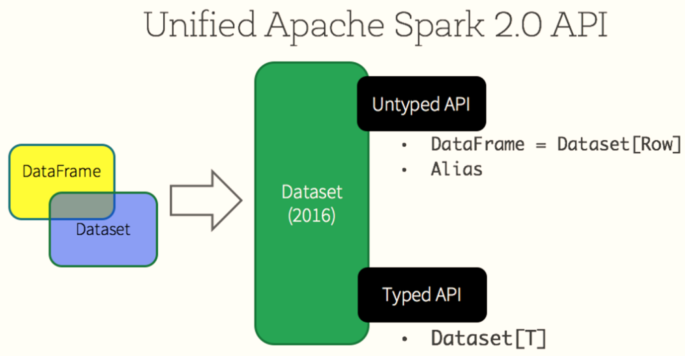
04-[了解]-SparkSQL 概述之官方定义及特性
SparkSQL模块官方定义:
针对结构化数据处理Spark Module模块。

主要包含三层含义:
- 第一、针对结构化数据处理,属于Spark框架一个部分
- 第二、抽象数据结构:DataFrame
DataFrame = RDD[Row] + Schema信息;
- 第三、分布式SQL引擎,类似Hive框架
从Hive框架继承而来,Hive中提供bin/hive交互式SQL命令行及HiveServer2服务,SparkSQL都可以;
Spark SQL模块架构示意图如下:
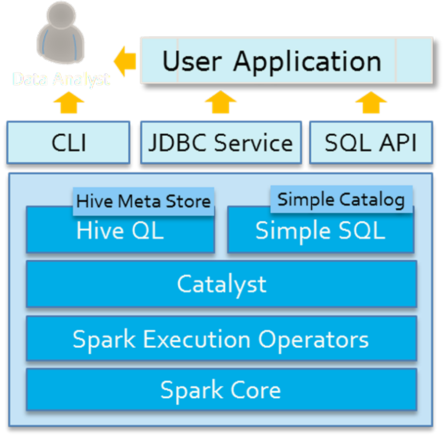
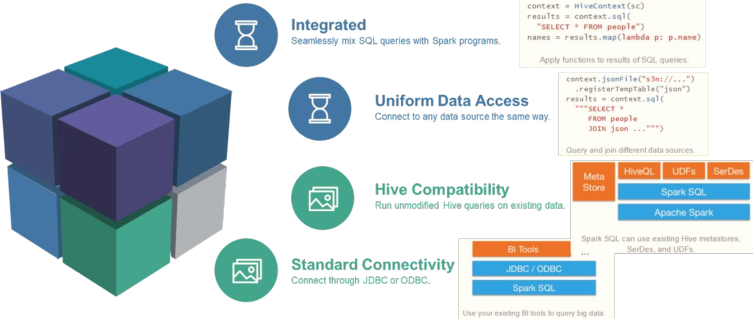
Spark SQL是Spark用来处理结构化数据的一个模块,主要四个特性:
官方文档:http://spark.apache.org/docs/2.4.5/sql-distributed-sql-engine.html
05-[掌握]-DataFrame是什么及案例演示
在Spark中,DataFrame是一种以RDD为基础的分布式数据集,类似于传统数据库中的二维表格。
DataFrame与RDD的主要区别在于,前者
带有schema元信息,即DataFrame所表示的二维表数据集的每一列都带有名称和类型。
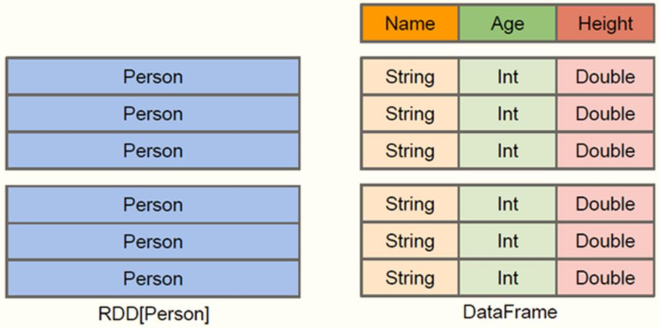
使得Spark SQL得以洞察更多的结构信息,从而对藏于DataFrame背后的数据源以及作用于DataFrame之上的变换进行针对性的优化,最终达到大幅提升运行时效率

DataFrame有如下特性:

范例演示:
加载json格式数据
[root@node1 spark]# bin/spark-shell --master local[2]
21/04/26 09:26:14 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
Spark context Web UI available at http://node1.itcast.cn:4040
Spark context available as 'sc' (master = local[2], app id = local-1619400386041).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_\ \/ _ \/ _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_\ version 2.4.5
/_/
Using Scala version 2.11.12 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_241)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val empDF = spark.read.json("/datas/resources/employees.json")
empDF: org.apache.spark.sql.DataFrame = [name: string, salary: bigint]
scala> empDF.printSchema()
root
|-- name: string (nullable = true)
|-- salary: long (nullable = true)
scala>
scala> empDF.show()
+-------+------+
| name|salary|
+-------+------+
|Michael| 3000|
| Andy| 4500|
| Justin| 3500|
| Berta| 4000|
+-------+------+
scala>
scala> empDF.rdd
res2: org.apache.spark.rdd.RDD[org.apache.spark.sql.Row] = MapPartitionsRDD[12] at rdd at <console>:26
所以,可以看出:DataFrame = RDD[Row] + Schema信息
06-[掌握]-DataFrame中Schema和Row
查看DataFrame中Schema是什么,执行如下命令:
scala> empDF.schema

可以发现Schema封装类:
StructType,结构化类型,里面存储的每个字段封装的类型:StructField,结构化字段。
- 其一、StructType 定义,是一个样例类,属性为StructField的数组

- 其二、StructField 定义,同样是一个样例类,有四个属性,其中字段名称和类型为必填

自定义Schema结构,官方提供实例代码:

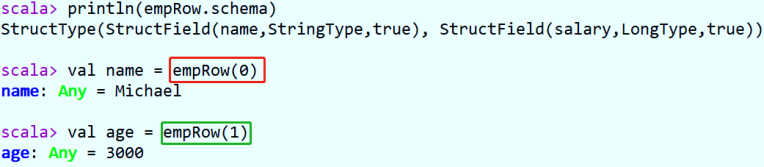
DataFrame中每条数据封装在Row中,Row表示每行数据,具体哪些字段位置,获取DataFrame中第一条数据。

如何获取Row中每个字段的值呢????
- 方式一:下标获取,从0开始,类似数组下标获取
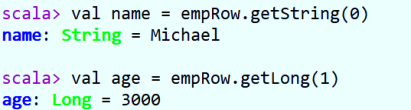
- 方式二:指定下标,知道类型
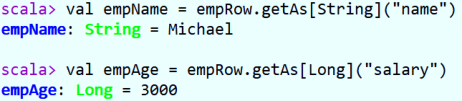
- 方式三:通过As转换类型, 此种方式开发中使用最多
如何创建Row对象呢???要么是传递value,要么传递Seq

07-[掌握]-RDD转换DataFrame之反射类型推断
实际项目开发中,往往需要将RDD数据集转换为DataFrame,本质上就是给RDD加上Schema信息,官方提供两种方式:
类型推断和自定义Schema。文档:http://spark.apache.org/docs/2.4.5/sql-getting-started.html#interoperating-with-rdds

范例演示说明:
使用经典数据集【电影评分数据u.data】,先读取为RDD,再转换为DataFrame。
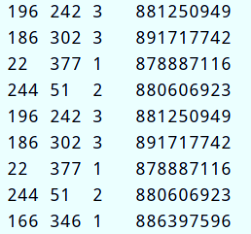
字段信息:user id 、 item id、 rating 、 timestamp。
当RDD中数据类型CaseClass样例类时,通过反射Reflecttion获取属性名称和类型,构建Schema,应用到RDD数据集,将其转换为DataFrame。
package cn.itcast.spark.convert
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, Dataset, SparkSession}
/**
* 采用反射的方式将RDD转换为DataFrame和Dataset
*/
object _01SparkRDDInferring {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象,设置应用名称和master
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.getOrCreate()
import spark.implicits._
// 1. 加载电影评分数据,封装数据结构RDD
val rawRatingRDD: RDD[String] = spark.sparkContext.textFile("datas/ml-100k/u.data")
// 2. 将RDD数据类型转化为 MovieRating
/*
将原始RDD中每行数据(电影评分数据)封装到CaseClass样例类中
*/
val ratingRDD: RDD[MovieRating] = rawRatingRDD.mapPartitions { iter =>
iter.map { line =>
// 按照制表符分割
val arr: Array[String] = line.trim.split("\\t")
// 封装样例对象
MovieRating(
arr(0), arr(1), arr(2).toDouble, arr(3).toLong
)
}
}
// 3. 通过隐式转换,直接将CaseClass类型RDD转换为DataFrame
val ratingDF: DataFrame = ratingRDD.toDF()
//ratingDF.printSchema()
//ratingDF.show(10, truncate = false)
/*
Dataset 从Spark1.6提出
Dataset = RDD + Schema
DataFrame = RDD[Row] + Schema
Dataset[Row] = DataFrame
*/
// 将DataFrame转换为Dataset,只需要加上CaseClass强类型即可
val ratingDS: Dataset[MovieRating] = ratingDF.as[MovieRating]
ratingDS.printSchema()
ratingDS.show(10, truncate = false)
// TODO: 将RDD转换为Dataset,可以通过隐式转, 要求RDD数据类型必须是CaseClass
val dataset: Dataset[MovieRating] = ratingRDD.toDS()
dataset.printSchema()
dataset.show(10, truncate = false)
// 将Dataset直接转换为DataFrame
val dataframe = dataset.toDF()
dataframe.printSchema()
dataframe.show(10, truncate = false)
// 应用结束,关闭资源
spark.stop()
}
}
08-[掌握]-RDD转换DataFrame之自定义Schema
依据RDD中数据自定义Schema,类型为StructType,每个字段的约束使用StructField定义,具体步骤如下:

package cn.itcast.spark.convert
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.types.{DoubleType, LongType, StringType, StructField, StructType}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
/**
* 自定义Schema方式转换RDD为DataFrame
*/
object _02SparkRDDSchema {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象,设置应用名称和master
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.getOrCreate()
import spark.implicits._
// 1. 加载电影评分数据,封装数据结构RDD
val rawRatingsRDD: RDD[String] = spark.sparkContext.textFile("datas/ml-100k/u.data", minPartitions = 2)
// 2. TODO: step1. RDD中数据类型为Row:RDD[Row]
val rowRDD: RDD[Row] = rawRatingsRDD.mapPartitions { iter =>
iter.map {
line =>
// 按照制表符分割
val arr: Array[String] = line.trim.split("\\t")
// 封装样例对象
Row(arr(0), arr(1), arr(2).toDouble, arr(3).toLong)
}
}
// 3. TODO:step2. 针对Row中数据定义Schema:StructType
val schema: StructType = StructType(
Array(
StructField("user_id", StringType, nullable = true),
StructField("movie_id", StringType, nullable = true),
StructField("rating", DoubleType, nullable = true),
StructField("timestamp", LongType, nullable = true)
)
)
// 4. TODO:step3. 使用SparkSession中方法将定义的Schema应用到RDD[Row]上
val ratingDF: DataFrame = spark.createDataFrame(rowRDD, schema)
ratingDF.printSchema()
ratingDF.show(10, truncate = false)
// 应用结束,关闭资源
spark.stop()
}
}
09-[掌握]-toDF函数指定列名称转换为DataFrame
SparkSQL中提供一个函数:
toDF,通过指定列名称,将数据类型为元组的RDD或Seq转换为DataFrame,实际开发中也常常使用。

范例演示:将数据类型为元组的RDD或Seq直接转换为DataFrame。
package cn.itcast.spark.todf
import org.apache.spark.rdd.RDD
import org.apache.spark.sql.{DataFrame, SparkSession}
/**
* 隐式调用toDF函数,将数据类型为元组的Seq和RDD集合转换为DataFrame
*/
object _03SparkSQLToDF {
def main(args: Array[String]): Unit = {
// 构建SparkSession实例对象,设置应用名称和master
val spark: SparkSession = SparkSession.builder()
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.master("local[3]")
.getOrCreate()
import spark.implicits._
// 1. 将数据类型为元组的RDD,转换为DataFrame
val rdd: RDD[(Int, String, String)] = spark.sparkContext.parallelize(
List((1001, "zhangsan", "male"), (1003, "lisi", "male"), (1003, "xiaohong", "female"))
)
// 调用toDF方法,指定列名称,将RDD转换为DataFrame
val dataframe: DataFrame = rdd.toDF("id", "name", "gender")
dataframe.printSchema()
dataframe.show(10, truncate = false)
println("==========================================================")
// 定义一个Seq序列,其中数据类型为元组
val seq: Seq[(Int, String, String)] = Seq(
(1001, "zhangsan", "male"), (1003, "lisi", "male"), (1003, "xiaohong", "female")
)
// 将数据类型为元组Seq序列转换为DataFrame
val df: DataFrame = seq.toDF("id", "name", "gender")
df.printSchema()
df.show(10, truncate = false)
// 应用结束,关闭资源
spark.stop()
}
}
10-[了解]-SparkSQL中数据处理方式
在SparkSQL模块中,将结构化数据封装到DataFrame或Dataset集合中后,提供两种方式分析处理数据,正如前面案例【词频统计WordCount】两种方式:
- 第一种:DSL(domain-specific language)编程
- 调用DataFrame/Dataset API(函数),类似RDD中函数;
- DSL编程中,调用函数更多是类似SQL语句关键词函数,比如select、groupBy,同时要使用函数处理

数据分析人员,尤其使用Python数据分析人员
- 第二种:SQL 编程
- 将DataFrame/Dataset注册为临时视图或表,编写SQL语句,类似HiveQL;
- 分为2步操作,先将DataFrame注册为临时视图,然后再编写SQL
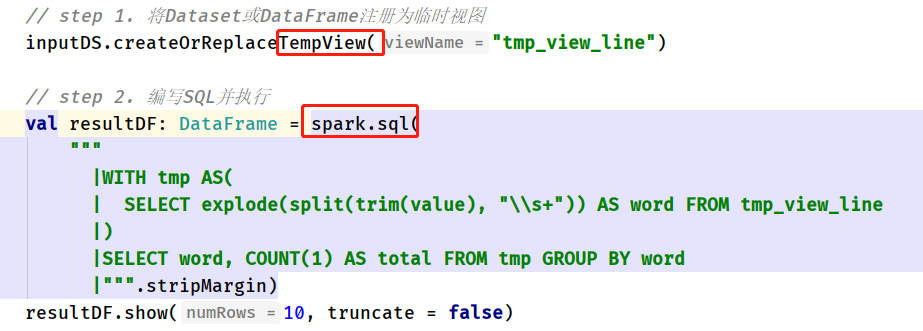
尤其DBA和数据仓库分析人员擅长编写SQL语句,采用SQL编程
11-[掌握]-基于DSL分析(函数说明)和SQL分析
- 基于DSL分析
- 调用DataFrame/Dataset中API(函数)分析数据,其中函数包含RDD中转换函数和类似SQL
语句函数,部分截图如下:

- 基于SQL分析
- 将Dataset/DataFrame注册为临时视图,编写SQL执行分析,分为两个步骤:
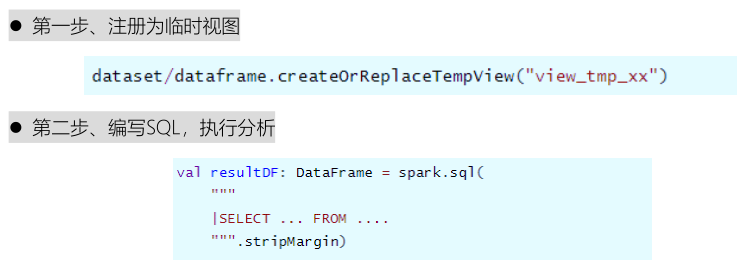
其中SQL语句类似Hive中SQL语句,查看Hive官方文档,SQL查询分析语句语法,官方文档文档:
https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Select

12-[掌握]-电影评分数据分析之需求说明和加载数据
使用电影评分数据进行数据分析,分别使用DSL编程和SQL编程,熟悉数据处理函数及SQL使用,业务需求说明:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6ypUaVpL-1627176341890)(/img/image-20210426105132291.png)]
数据集ratings.dat总共100万条数据,数据格式如下,每行数据各个字段之间使用双冒号分开:
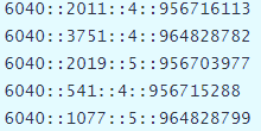
数据处理分析步骤如下:

将分析结果,分别保存到MySQL数据库表中及CSV文本文件中。
首先加载电影评分数据,封装到RDD中
// 构建SparkSession实例对象
val spark: SparkSession = SparkSession.builder()
.master("local[4]")
.appName(this.getClass.getSimpleName.stripSuffix("$"))
.getOrCreate()
// 导入隐式转换
import spark.implicits._
// TODO: step1. 读取电影评分数据,从本地文件系统读取,封装数据至RDD中
val ratingRDD: RDD[String] = spark.read.textFile("datas/ml-1m/ratings.dat").rdd
println(s"Count = ${ratingRDD.count()}")
println(s"first:\n\t${ratingRDD.first()}")
13-[掌握]-电影评分数据分析之数据ETL
读取电影评分数据,将其转换为DataFrame,使用指定列名方式定义Schema信息,采用toDF函数,代码下:
val ratingDF: DataFrame = ratingRDD
.filter(line => null != line && line.trim.split("::").length == 4)
.mapPartitions{iter =>
iter.map{line =>
// a. 解析每条数据
val arr = line.trim.split("::")
// b. 构建元组对象
(arr(0).toInt, arr(1).toInt, arr(2).toDouble, arr(3).toLong)
}
}
// c. 调用toDF函数,指定列名称
.toDF("user_id", "item_id", "rating", "timestamp")
ratingDF.printSchema()
ratingDF.show(10, truncate = false)
println(s"count = ${ratingDF.count()}")
将RDD转换为DataFrame数据集,方便采用DSL或SQL分析数据。
14-[掌握]-电影评分数据分析之SQL分析
首先将DataFrame注册为临时视图,再编写SQL语句,最后使用SparkSession执行,代码如下;
// TODO: step3. 基于SQL方式分析
/*
a. 注册为临时视图
b. 编写SQL,执行分析
*/
// a. 将DataFrame注册为临时视图
ratingDF.createOrReplaceTempView("view_temp_ratings")
// b. 编写SQL,执行分析
val top10MovieDF: DataFrame = spark.sql(
"""
|SELECT
| item_id, ROUND(AVG(rating), 2) AS avg_rating, COUNT(1) AS cnt_rating
|FROM
| view_temp_ratings
|GROUP BY
| item_id
|HAVING
| cnt_rating >= 2000
|ORDER BY
| avg_rating DESC
|LIMIT
| 10
|""".stripMargin)
/*
root
|-- item_id: integer (nullable = false)
|-- avg_rating: double (nullable = true)
|-- count_rating: long (nullable = false)
*/
top10MovieDF.printSchema()
/*
+--------+----------+------------+
|movie_id|avg_rating|count_rating|
+--------+----------+------------+
|318 |4.55 |2227 |
|858 |4.52 |2223 |
|527 |4.51 |2304 |
|1198 |4.48 |2514 |
|260 |4.45 |2991 |
|2762 |4.41 |2459 |
|593 |4.35 |2578 |
|2028 |4.34 |2653 |
|2858 |4.32 |3428 |
|2571 |4.32 |2590 |
+--------+----------+------------+
*/
top10MovieDF.show(10, truncate = false)
15-[掌握]-电影评分数据分析之Shuffle分区数
运行上述程序时,查看WEB UI监控页面发现,某个Stage中有200个Task任务,也就是说RDD有200分区Partition。

原因:在SparkSQL中当Job中产生Shuffle时,默认的分区数(
spark.sql.shuffle.partitions)为200,在实际项目中要合理的设置。在构建SparkSession实例对象时,设置参数的值
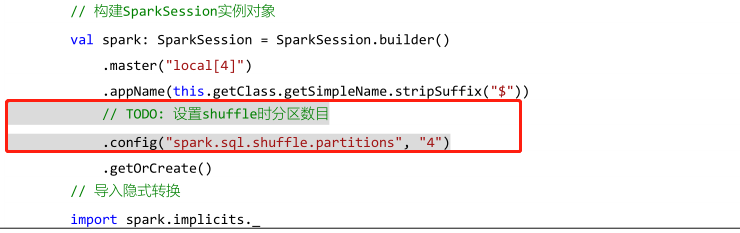
好消息:
在Spark3.0开始,不用关心参数值,程序自动依据Shuffle时数据量,合理设置分区数目。
16-[掌握]-电影评分数据分析之DSL分析
调用Dataset中函数,采用链式编程分析数据,核心代码如下:
val resultDF: DataFrame = ratingDF
// a. 按照电影ID分组
.groupBy($"item_id")
// b. 组合数据进行聚合,评分平均值和评分的次数
.agg(
round(avg($"rating"), 2).as("avg_rating"), //
count($"user_id").as("cnt_rating")
)
// c. 过滤评分次数大于2000
.filter($"cnt_rating" > 2000)
// d. 按照评分平均值降序排序
.orderBy($"avg_rating".desc)
// e. 获取前10条数据
.limit(10)
resultDF.printSchema()
resultDF.show(10, truncate = false)
使用需要导入函数库:import org.apache.spark.sql.functions._
使用DSL编程分析和SQL编程分析,哪一种方式性能更好呢?实际开发中如何选择呢???
17-[掌握]-电影评分数据分析之保存结果至MySQL
将分析数据保持到MySQL表中,直接调用Dataframe中writer方法,写入数据到MYSQL表中
// TODO: step 4. 将分析结果数据保存到外部存储系统中,比如保存到MySQL数据库表中或者CSV文件中
resultDF.persist(StorageLevel.MEMORY_AND_DISK)
// 保存结果数据至MySQL表中
val props = new Properties()
props.put("user", "root")
props.put("password", "123456")
props.put("driver", "com.mysql.cj.jdbc.Driver")
resultDF
.coalesce(1) // 对结果数据考虑降低分区数
.write
.mode(SaveMode.Overwrite)
.jdbc(
"jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true", //
"db_test.tb_top10_movies", //
props
)
/*
mysql> select * from tb_top10_movies ;
+---------+------------+------------+
| item_id | avg_rating | cnt_rating |
+---------+------------+------------+
| 318 | 4.55 | 2227 |
| 858 | 4.52 | 2223 |
| 527 | 4.51 | 2304 |
| 1198 | 4.48 | 2514 |
| 260 | 4.45 | 2991 |
| 2762 | 4.41 | 2459 |
| 593 | 4.35 | 2578 |
| 2028 | 4.34 | 2653 |
| 2858 | 4.32 | 3428 |
| 2571 | 4.32 | 2590 |
+---------+------------+------------+
*/
// 保存结果数据至CSv文件中
// 数据不在使用时,释放资源
resultDF.unpersist()
18-[掌握]-电影评分数据分析之保存结果至CSV文件
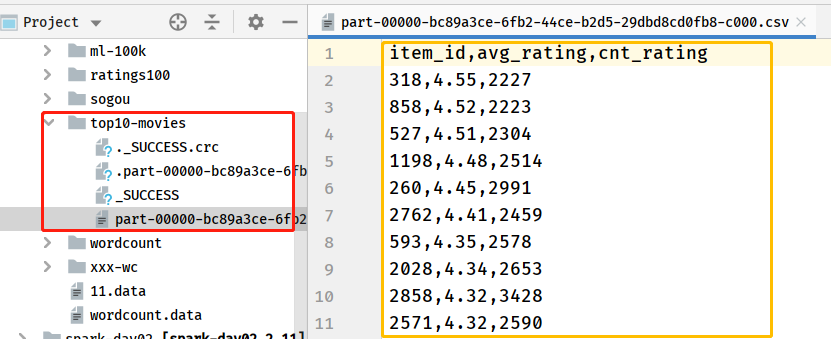
将结果DataFrame保存值CSV文件中,文件首行为列名称,核心代码如下:
// 保存结果数据至CSv文件中
resultDF
.coalesce(1)
.write
.mode(SaveMode.Overwrite)
.option("header", "true")
.csv("datas/top10-movies")
截图如下所示:
发现,SparkSQL加载数据源数据和保存结果数据,操作非常方便,原因在于:SparkSQL提供强大功能【外部数据源接口】,使得操作数据方便简洁。
附录一、创建Maven模块
1)、Maven 工程结构
2)、POM 文件内容
Maven 工程POM文件中内容(依赖包):
<!-- 指定仓库位置,依次为aliyun、cloudera和jboss仓库 -->
<repositories>
<repository>
<id>aliyun</id>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
</repository>
<repository>
<id>cloudera</id>
<url>https://repository.cloudera.com/artifactory/cloudera-repos/</url>
</repository>
<repository>
<id>jboss</id>
<url>http://repository.jboss.com/nexus/content/groups/public</url>
</repository>
</repositories>
<properties>
<scala.version>2.11.12</scala.version>
<scala.binary.version>2.11</scala.binary.version>
<spark.version>2.4.5</spark.version>
<hadoop.version>2.6.0-cdh5.16.2</hadoop.version>
<hbase.version>1.2.0-cdh5.16.2</hbase.version>
<mysql.version>8.0.19</mysql.version>
</properties>
<dependencies>
<!-- 依赖Scala语言 -->
<dependency>
<groupId>org.scala-lang</groupId>
<artifactId>scala-library</artifactId>
<version>${scala.version}</version>
</dependency>
<!-- Spark Core 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-core_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Spark SQL 与 Hive 集成 依赖 -->
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-hive-thriftserver_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-sql-kafka-0-10_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-avro_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<dependency>
<groupId>org.apache.spark</groupId>
<artifactId>spark-mllib_${scala.binary.version}</artifactId>
<version>${spark.version}</version>
</dependency>
<!-- Hadoop Client 依赖 -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- HBase Client 依赖 -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-hadoop2-compat</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<!-- MySQL Client 依赖 -->
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>${mysql.version}</version>
</dependency>
</dependencies>
<build>
<outputDirectory>target/classes</outputDirectory>
<testOutputDirectory>target/test-classes</testOutputDirectory>
<resources>
<resource>
<directory>${project.basedir}/src/main/resources</directory>
</resource>
</resources>
<!-- Maven 编译的插件 -->
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.0</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
<encoding>UTF-8</encoding>
</configuration>
</plugin>
<plugin>
<groupId>net.alchim31.maven</groupId>
<artifactId>scala-maven-plugin</artifactId>
<version>3.2.0</version>
<executions>
<execution>
<goals>
<goal>compile</goal>
<goal>testCompile</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
aven 编译的插件 -->
org.apache.maven.plugins
maven-compiler-plugin
3.0
1.8
1.8
UTF-8
net.alchim31.maven
scala-maven-plugin
3.2.0
compile
testCompile
相关文章
- PaddleNLP语义检索参考案例
- SQL案例分析-应用系统用户权限设计.sql
- K-近邻算法之案例2:预测facebook签到位置
- 【FPGA教程案例71】基础操作1——Xilinx原语学习及应用1
- 54dwr - 购物车案例(调用远程对象)
- 35 爬虫 - XPath爬虫案例
- 大数据与机器学习:实践方法与行业案例.1.1 数据的基本形态
- 大数据与机器学习:实践方法与行业案例.2.2 数据缓冲区
- 《深度学习导论及案例分析》一第3章 受限玻耳兹曼机3.1 受限玻耳兹曼机的标准模型
- 《Android 应用案例开发大全(第3版)》——第2章,第2.2节壁纸的策划及准备工作
- 《精通移动App测试实战:技术、工具和案例》一1.7 创建一个Android项目
- 超融合的未来发展与使用案例
- SQL教程之使用 SQL 进行产品销售分析典型案例
- PHP(基本语法)PHP中的Session-登录案例
- 【转发】PHP连接MSSQL数据库案例,PHPWAMP多个PHP版本连接SQL Server数据库
- 百倍性能的PL/SQL优化案例(r11笔记第13天)
- 通过手动创建统计信息优化sql查询性能案例
- SQL Server 死锁案例分析
- 软考高级之信息系统案例分析七重奏-《7》
- Oracle数据库案例整理-Oracle系统执行失败-sql_trace至TRUE导致Oracle在根文件夹中缺乏可用空间
- mysql一个SQL案例
- 什么是xhr?XMLHttpRequest的基本使用及xhr Level2的新特性详解及案例
- Spring Security 与 OAuth2(完整案例)
- html table 如何导出为excel表格案例分享