
【三维目标检测】VoxelNet(三):模型详解
本文为博主原创文章,未经博主允许不得转载。
本文为专栏《python三维点云从基础到深度学习》系列文章,地址为“https://blog.csdn.net/suiyingy/article/details/124017716”。
前两节详细介绍了VoxelNet的数据处理部分,本节主要介绍VoxelNet详细的模型结构及其损失函数。数据处理部分请参考:三维点云目标检测 — VoxelNet详解之数据处理 (二)_Coding的叶子的博客-CSDN博客。
1 代码环境部署
请参考:三维点云目标检测 — VoxelNet详解crop.py (一)_Coding的叶子的博客-CSDN博客。
另外有两处需要进行修改:
(1)config.py:第35、36行需要进行如下修改,否则会报错:TypeError: 'float' object cannot be interpreted as an integer。
x = np.linspace(xrange[0]+vw, xrange[1]-vw, W//2)
y = np.linspace(yrange[0]+vh, yrange[1]-vh, H//2)(2)voxelnet.py:第163行需要进行如下修改,否则会报维度不匹配的错误。
dense_feature[:, coords[:,0], coords[:,1], coords[:,2], coords[:,3]]= sparse_features.transpose(0, 1)2 voxelnet模型结构
Voxelnet的主要模型结构如下图所示:

voxelnet模型主要包含数据处理、VFW、SVFW、CML和RPN几个部分,其中数据处理已经在上一节中详细介绍过。
2.1 体素特征编码 VFW(voxel feature encoding layer)
假设输入体素的维度为NxTxK,N为含有点云的体素个数,T=35为体素中点的个数,K为体素中每个点的特征维度。
(1)首先,筛选出原始特征最大值不等于0的点,生成Nx3维度的mask,即对这些空值点不进行特征提取。
(2)对每个点的特征进行全连接(N,N1),得到NxTxN1维度特征pwf (point-wise feature)。
(3)对每个体素每个点的特征,每个特征维度保留最大值,相当于最大值池化,得到局部体素的全局特征Nx1xN1,然后将特征重复T次,维度恢复到NxTxN1特征laf(locally aggregated feature)。
(4)将pwf和laf进行拼接,相当于分别考虑各个体素中局部特征和全局特征。这一点与PointNet语义分割完全一致。拼接后体素特征的维度为NxTx2N1,即pwcf(point-wise concat feature)。
(5)将(1)中mask维度扩展成NxTx2N1后与pwcf相乘得到VFW层的最终输出。
因此,VFW的作用是对每个体素的局部特征和全局特征进行提取,并且将空值点的特征置为0。
2.2 SVFW(Stacked Voxel Feature Encoding)
VoxelNet连续用到两次VFW,合并称为SVFW(Stacked Voxel Feature Encoding)。VFW1中N=7、N1=16,则输出为Nx35x32;VFW1中N=32、N1=64,则输出为Nx35x128。输出的特征再次经过全连接(128,128)后在T方向进行最大池化,得到每个体素的特征,维度为Nx128 (vwfs)。
以上特征为含有点云的体素特征,体素个数为N。总的空间中体素个数为10x400x352,这个在数据部分已经介绍。将Nx128为特征,填充回所有体素中,没有特征的体素用0进行填充,进而得到稠密的体素特征128x10x400x352(vwfs)。
2.3 CML(Convolutional Middle Layer)
经过SVFE层后输出的特征维度为128x10x400x352,这些是每个体素的特征。相比于图像来说,这相当于每个像素的特征。CML(Convolutional Middle Layer)模块是采用3D卷积对整个体素空间进行特征提取,这一步在计算机视觉算法中是非常常规的一步。
(1)Conv3d(128, 64, 3, s=(2, 1, 1), p=(1, 1, 1)):64x5x200x512
(2)Conv3d(64, 64, 3, s=(1, 1, 1), p=(0, 1, 1)):64x3x400x352
(3)Conv3d(64, 64, 3, s=(2, 1, 1), p=(1, 1, 1)):64x2x400x352
经过CML模块后,特征维度降为64x2x400x352,深度方向上的维度降低为2,可以认为是与两种角度的anchor相对应。
2.4 RPN(Region Proposal Network)
RPN(Region Proposal Network)模块主要是用于anchor的分类和回归。这个在图像领域两阶段的目标检测算法中有详细介绍和应用,如faster RCNN。
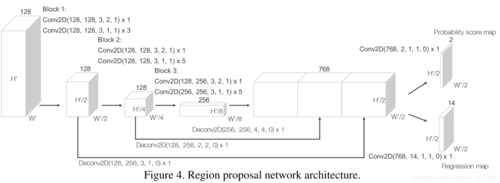
将CML模块特征reshape成128x400x352作为RPN的输入。
(1)Block_1:Conv2d(128, 128, 3, 2, 1)、Conv2d(128, 128, 3, 1, 1)、Conv2d(128, 128, 3, 1, 1)、Conv2d(128, 128, 3, 1, 1):128x200x176 (x_skip_1)。
(2)Block_2:Conv2d(128, 128, 3, 2, 1)、Conv2d(128, 128, 3, 1, 1)、Conv2d(128, 128, 3, 1, 1)、Conv2d(128, 128, 3, 1, 1)、Conv2d(128, 128, 3, 1, 1):128x100x88 (x_skip_2)。
(3)Block_2:Conv2d(128, 256, 3, 2, 1)、Conv2d(256, 256, 3, 1, 1)、Conv2d(256, 256, 3, 1, 1)、Conv2d(256, 256, 3, 1, 1)、Conv2d(256, 256, 3, 1, 1):256x50x44 (x)。
(4)Deconv_1(256, 256, 4, 4):利用反卷积对x进行上采样,256x200x176(x_0)。
(5)Deconv_2(128, 256, 2, 2):利用反卷积对x_skip_2进行上采样,256x200x176(x_1)。
(6)Deconv_3(128, 256, 1, 1):利用反卷积对x_skip_1进行上采样,256x200x176(x_2)。
(7)将x_0、x_1、x_2拼接成768x200x352维度的新特征。
(8)Score_head:利用卷积Conv2d(768, 2, 1, 1)生成2x200x176个特征,用于对每个anchor的分类,psm(probability score map)。
(9)Reg_head:利用卷积Conv2d(768, 14, 1, 1)生成14x200x176个特征,用于对每个anchor的位置回归,rm(regression map)。
RPN模块中用了特征金字塔FPN提取了多尺度特征,并且进行融合。这个也可以改进成常见的逐层上采样,逐层融合,而不是最后一层采用1次拼接融合。
3 损失函数
损失函数计算在一个3D的数据的标注中,包含了7个参数(x, y ,z, l, w, h, θ),其中xyz代表了一个物体的中心点在雷达坐标系中的位置。lwh代表了这个物体的长宽高。θ代表了这个物体绕Z轴旋转角度(偏航角)。因此生成的anchor也包含对应的7个参数(xa, ya ,za, la, wa, ha, θa),其中xa, ya ,za表示这个anchor在雷达坐标系中的位置。la, wa, ha反应了这个anchor的长宽高。θa表示这个anchor的角度。
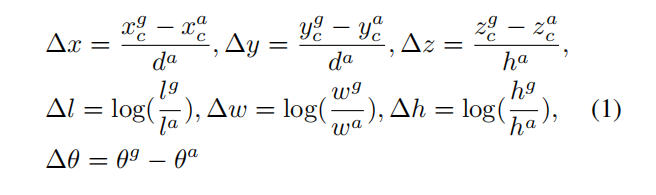
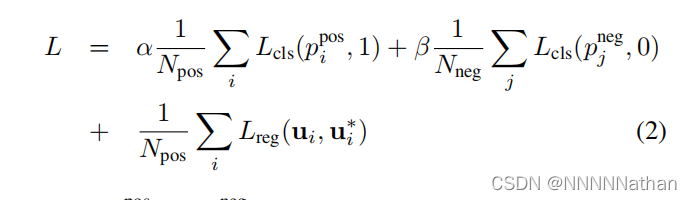
损失函数的输入为rm、psm、pos_equal_one(正样本mask,200x176x2)、neg_equal_one(正样本mask,200x176x2)、targets(正样本与真实值之间的偏差,200x176x14),pos_equal_one、neg_equal_one、targets的具体处理过程请参考上一节的数据处理部分。
(1)将psm维度reshape成200x176x2后利用sigmoid转换为概率,p_pos。
(2)将rm和targets维度reshape成200x176x2x7,并分别乘以pos_equal_one,这是因为仅需要对正样本进行回归,得到rm_pos和targets_pos。
(3)分别计算正负样本分类的交叉熵损失,cls_pos_loss和cls_neg_loss。
(4)根据rm_pos和target_pos计算smoothl1loss损失,reg_loss。
(5)将1.5倍cls_pos_loss和1倍cls_neg_loss之和作为总的分类置信度损失,conf_loss,对应图中的α和β。这是因为通常正样本的数量远远小于负样本数量,通过不同的权重来增加正样本损失对总损失的贡献程度。
python三维点云从基础到深度学习_Coding的叶子的博客-CSDN博客_python三维点云重建从三维基础知识到深度学习,将按照以下目录持续进行更新。更新完成的部分可以在三维点云专栏中查看。https://blog.csdn.net/suiyingy/category_11740467.htmlhttps://blog.csdn.net/suiyingy/category_11740467.html1、点云格式介绍(已完成)常见点云存储方式有pcd、ply、bin、txt文件。open3d读写pcd和pl https://blog.csdn.net/suiyingy/article/details/124017716
https://blog.csdn.net/suiyingy/article/details/124017716
更多三维、二维感知算法和金融量化分析算法请关注“乐乐感知学堂”微信公众号,并将持续进行更新。
本文为博主原创文章,未经博主允许不得转载。
本文为专栏《python三维点云从基础到深度学习》系列文章,地址为“https://blog.csdn.net/suiyingy/article/details/124017716”。
相关文章
- 机器学习 Out-of-Fold 折外预测详解 | 使用折外预测 OOF 评估模型的泛化性能和构建集成模型
- JavaSwing:JRadioButton-单选按钮开发详解
- PaddleClas套件——PP-ShiTuV2模型详解
- 语音合成:Tacotron详解【端到端语音合成模型】【与传统语音合成相比,它没有复杂的语音学和声学特征模块,而是仅用<文本序列,语音声谱>配对数据集对神经网络进行训练,因此简化了很多流程】
- js中几种实用的跨域方法原理详解
- seq2seq模型详解及对比(CNN,RNN,Transformer)
- 详解Transformer模型(Atention is all you need)
- Java 内存模型 JMM 详解!
- 详解 Java 中 4 种 IO 模型
- Java自动化王者 —— TestNG详解跑【2600字保姆级教程】
- 模型训练中的分批BatchSize详解
- 推荐系统[五]:重排算法详解相关概念、整体框架、常用模型;涉及用户体验[打散、多样性],算法效率[多任务融合、上下文感知]等
- 详解互联网运维需要把握的四力模型
- supervisord管理进程详解
- IO模型之NIO代码及其实践详解
- IO模型之BIO代码详解及其优化演进
- JAVA中PRIORITYQUEUE详解
- 基于WordCount详解MapReduce编程模型!
- Cookie 详解以及实现一个 cookie 操作库
- 【RabbitMQ】常用消息模型详解
- 自然语言处理NLP星空智能对话机器人系列:第21章:基于Bayesian Theory的MRC文本理解基础经典模型算法详解
- 自然语言处理NLP星空智能对话机器人系列:NLP on Transformers 101 第8章 轻量级ALBERT模型剖析及BERT变种中常见模型优化方式详解
- GT sport真实赛道详解 - Brands Hatch | 伯蘭士赫治GP賽車場
- Talib技术因子详解(十)
- SpringBoot2.x系列教程(三十九)SpringBoot中SecurityConstraint使用详解
- Android Drawable 详解
- 【NLP相关】从零开始理解BERT模型:NLP领域的突破(BERT详解与代码实现)