
INTERSPEECH 2017系列 | 语音识别技术之自适应技术
编者:今年的INTERSPEECH于8月20日至24日在瑞典的斯德哥尔摩顺利召开,众多的高校研究机构和著名的公司纷纷在本次会议上介绍了各自最新的技术、系统和相关产品,而阿里巴巴集团作为钻石赞助商也派出了强大的阵容前往现场。从10月25日开始,阿里iDST语音团队和云栖社区将共同打造一系列语音技术分享会,旨在为大家分享INTERSPEECH2017会议上语音技术各个方面的进展。第一期分享的主题是语音识别技术之自适应技术,以下是本次分享的主要内容。
1. 语音识别技术中的自适应技术简介
语音识别中的自适应,即针对某一个说话人或者某一domain来优化语音识别系统的识别性能,使得识别系统对他们的性能有一定的提升。语音识别的自适应技术的目的是为了减少训练集和测试集说话人或者domain之间差异性造成的语音识别性能下降的影响。这种差异性主要包括语音学上的差异还有生理上发音习惯上不同导致的差异性等等。自适应技术主要被应用于语音识别技术相关的产品,还有针对VIP客户的语音识别等。
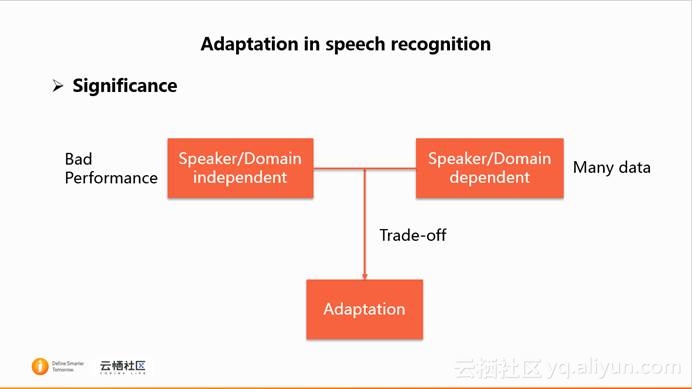
上述的差异性问题,它容易造成说话人或者domain无关的识别系统性能上不好,但是如果针对该说话人或者domain训练一个相关的识别系统,那么需要收集很多数据,这个成本是很高的。而语音识别中的自适应技术作为一种折中,它的数据量较少,并且性能上也能达到较好的效果。
语音识别中的自适应技术有很多,根据自适应的空间,可以分成两类:特征空间自适应和模型空间自适应。对于特征空间自适应来说,它试图将相关的特征通过特征转换成无关的特征,从而能够和无关的模型相匹配。而对于模型空间的自适应来说,它试图将无关的模型转换成相关的模型,从而能够和相关的特征相匹配。总而言之,这两类算法目的是为了让相关的特征与无关的模型相匹配。
2. INTERPSEECH 2017 paper reading
2.1 Paper 1

第一篇文章的题目是Dynamic Layer Normalization for Adaptive Neural Acoustic Modeling in Speech Recognition,它来自蒙特利尔大学。这篇文章的主要思想是将layer normalization的scale和shift两个参数由上下文无关的变成上下文相关的,从而根据上下文信息来获得动态的scale和shift。这是一种模型空间的自适应。它的主要创新的地方主要是,它不需要自适应阶段(自适应阶段就是使用目标 domain的数据进行自适应,从而能够学习到目标domain的知识),另外,它同样不需要提供包含说话人信息的相关特征,例如i-vector等等。
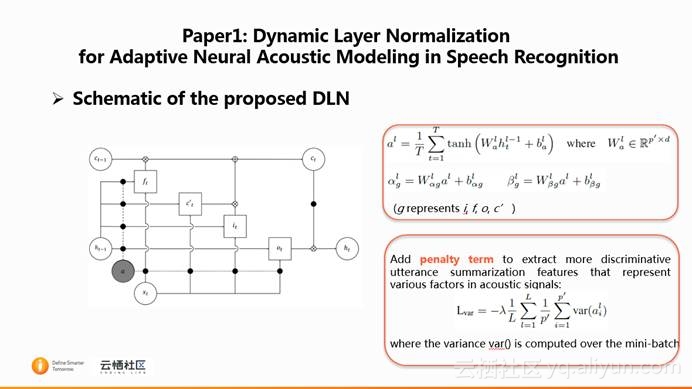
DLN对应的公式如上图右边所示,首先,取前一层的minibatch ( $T$ )大小的隐层矢量或者输入矢量$h^{l-1}_t$进行summarization,从而获得$a^l$。然后,通过线性变换矩阵和偏置来动态地控制scale ( $\alpha^l_g$ )和shift ( $\beta^l_g$ )。
同时,在原来的CE训练的基础上,在目标函数上增加一个惩罚项(上图的右下角$L_{var}$),用于增加句子内的variance,从而summarization出来的信息会更加具有区分性。
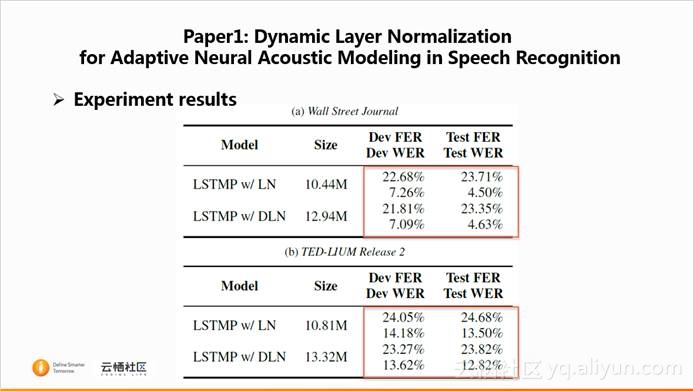
这篇paper主要是在81小时的WSJ以及212小时的TED数据集上进行实验,WSJ的训练集包含283个说话人,TED的训练集包含5076个说话人。
首先,在WSJ数据集上对比LN和DLN之间的性能,性能主要包括开发集和测试集的FER和WER(FER表示帧错误率,WER表示词错误率)。可以看出,除了测试集WER外,DLN均优于LN。文章分析,这是由于WSJ的说话人数目较少,导致句子间的差异性不明显,同时WSJ数据集是在安静环境下录制的,句子都比较平稳,DLN不能够起作用。
在TED数据集上的结果如第二个表格所示,发现在四个性能参数下,DLN均优于LN。文章对比WSJ和TED数据,TED数据集能够取得比较好的性能的原因是,TED数据集较WSJ speaker数目更多,句子数更多,variability更加明显。通过这篇文章,我们可以发现这种动态的LN与句子的variability相关。并且总体上看来,DLN是要优于LN。
2.2 Paper 2

第二篇文章的题目是Large-Scale Domain Adaptation via Teacher-Student Learning,它来自微软。这篇文章的主要思想是通过teacher/student的结构来进行domain adaptation。这种方法不需要目标 domain的带标注的数据。但是,它需要和训练集相同的并行数据。它的创新点和价值主要在于,这种方法可以使用非常多的无标注数据,同时借用teacher network的输出来进一步提升student模型的性能。
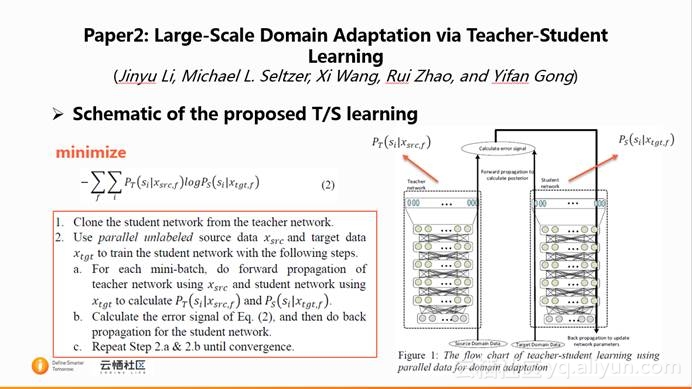
将teacher/student 简称为T/S。T/S的训练流图如上图右边所示。Figure 1 中的左侧为teacher network,右侧为student network,它们的输出后验概率分别设为$P_T$和$P_S$。
student network的训练过程:首先,将teacher network复制一份作为student network的初始化。然后,利用student domain data和teacher domain data通过对应的网络获得相应的后验概率$P_T$和$P_S$。最后,利用这两个后验概率计算error signal,进行back梯度反传更新student network。

本paper的实验是在375小时的英文cortana数据上进行的。测试集根据不同的domain,有不同的测试集。
针对干净/带噪,在Cortana测试集上进行实验。首先,使用teacher network进行测试,发现在带噪语音上测试性能(18.8%)要远差于noise-free的语音(15.62%)。如果通过仿真的方式来训练teacher network,发现noisy的测试性能(17.34%)有一定的提升,这个等价于在student network上使用hard label来训练。第四行和第五行使用T/S 算法,在同样数据量上,soft label (16.66%)要优于hard label (17.34%)。如果将训练student network的数据增加到3400小时,性能会有进一步的提升(16.11%)。

对于成年人/小孩来说,实验首先将375小时中的女性以及儿童数据去除,获得adult male 模型。实验发现,小孩的识别性能很差,分别是39.05和34.16。与干净/带噪相同,在使用T/S算法后,能够在性能上获得进一步的提升,并且数据扩大对于性能是有优势的。
2.3 Paper 3

第三篇文章是来自香港科技大学和谷歌的文章。这篇文章主要的想法和创新点是将Factorized Hidden Layer (FHL)的自适应方法 应用于LSTM-RNN。

对于FHL adaptation算法来说,它在说话人无关的网络权重$W$基础上加上一个说话人相关的网络权重,从而获得说话人相关的网络权重$W^s$。根据公式(7),我们可以看到,这个SD transformation是根据一组矩阵基$(B(1),B(2),...,B(i))$通过线性插值得到。同样,对神经网络的偏置$b$也可以进行相应的说话人相关变换。
但是,在实际实验中,由于矩阵基会带来大量的参数引入,这些矩阵基都被限制为rank-1,因此公式(7)可以进行一些变换,如上图右边所示。由于矩阵基为rank-1,那它可以被表示成一个列向量$\gamma(i)$和一个行向量$\psi(i)^T$相乘的形式。同时,插值矢量被表示成对角矩阵$D^s$的形式。这样便获得三个矩阵$\Gamma$、$D^s$和$\Psi^T$连乘的方式,方便模型训练。
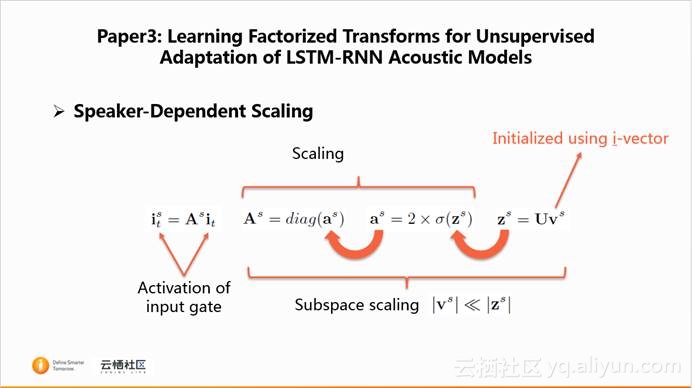
本文还介绍了speaker-dependent scaling。它将LSTM记忆单元中的激活值进行speaker-dependent scale。通过公式带入,发现,只要对每一个说话人学习$z^s$即可以进行说话人相关的scaling。但是这种算法存在一个问题,$z^s$的维度与网络的层宽相关,参数量大。因此,一种subspace scaling的方法被提出,它通过一个固定维度的low-dimensional vector $v^s$来控制$z^s$,$v^s$的维度远小于$z^s$,从而大大地减少了说话人相关的参数量。

本paper是在78小时的数据集上进行的。上图中的表格表示使用文章中的算法的最终WER。表格中,none表示不使用任何自适应算法,SD bias表示FHL中不使用SD权重矩阵,仅使用SD 偏置。CMLLR是一种自适应算法。首先,文章中的算法(Best)相比于SD bias和CMLLR取得了最好的性能。然后,LSTM-RNN取得的识别性能的提升少于DNN,说明在LSTM-RNN上进行自适应难度更大。
3. 总结
通过调研阅读今年INTERSPEECH的自适应技术相关的论文,受益匪浅,主要是研究者们提出了很多有意思的想法。希望大家通过我的这篇文章能够对自适应技术有一定的了解。
4. 参考文献
[1] Kim T, Song I, Bengio Y. Dynamic Layer Normalization for Adaptive Neural Acoustic Modeling in Speech Recognition[J]. 2017.
[2] Li J, Seltzer M L, Wang X, et al. Large-Scale Domain Adaptation via Teacher-Student Learning[J]. 2017.
[3] Samarakoon L, Mak B, Sim K C. Learning Factorized Transforms for Unsupervised Adaptation of LSTM-RNN Acoustic Models[C]// INTERSPEECH. 2017:744-748.
自拍照被拿去训练AI?这款AI工具帮你「骗」过人脸识别算法 尽管公众监督的呼声很高,然而面部识别AI已悄然地被机构用作监视的手段。魔高一尺,道高一丈,科学家们也在如火如荼地开发阻止上传到社交网络的自拍被AI训练的工具。
CVPR oral解读:医疗AI最新进展,可媲美人类医师推理能力的图像检测算法 疫情让大众更加关注医疗健康。而在刚刚过去的CVPR2020中,也有很多医学方面的研究工作。深睿医疗就有四篇论文入选,其中三篇为oral,其论文涵盖了医疗图像识别,姿态估计等多个主题,在医疗AI方面取得了优异的成绩。
给图片打「马赛克」可骗过AI视觉系统,阿里安全新研究入选ICCV 2021 来自阿里安全人工智能治理与可持续发展实验室(AAIG)等机构的研究者提出了一个新的机制来生成对抗样本,即与增加对抗扰动相反,他们通过扔掉一些不可察觉的图像细节来生成对抗样本。这项研究成果已被 AI 顶会 ICCV 2021 收录。
语音合成到了跳变点?深度神经网络变革TTS最新研究汇总 近年来,随着深度神经网络的应用,计算机理解自然语音能力有了彻底革新,例如深度神经网络在语音识别、机器翻译中的应用。但是,使用计算机生成语音(语音合成(speech synthesis)或文本转语音(TTS)),仍在很大程度上基于所谓的拼接 TTS(concatenative TTS)。而这种传统的方法所合成语音的自然度、舒适度都有很大的缺陷。深度神经网络,能否像促进语音识别的发展一样推进语音合成的进步?这也成为了人工智能领域研究的课题之一
ai视觉能有多强? 在这个人工智能已经普及的时代,各行各业都充斥着AI的身影。大部分人认为人工智能起点高,入门难,想要使用AI服务又无法独立完成编写,阿里云视觉平台是基于阿里巴巴视觉智能技术实践经验,面向视觉智能技术企业和开发商(含开发者),为其提供高易用、普惠的视觉API服务,帮助企业快速建立视觉智能技术的应用能力的综合性视觉AI能力平台。让我们跟阿里达摩院一起看看AI视觉到底能有多强?
阿里云语音识别模型端核心技术选讲 语音识别技术作为人工智能技术中的重要组成部分,也作为影响人机交互的核心组件之一,从各种智能家用IoT设备的语音交互能力,到公共服务、智慧政务等场合的应用,语音识别技术正在影响着人们生活的方方面面。本文将挑选阿里云语音识别技术中的一些模型端技术进行简要介绍。
【新智元干货】计算机视觉必读:目标跟踪、网络压缩、图像分类、人脸识别等 深度学习目前已成为发展最快、最令人兴奋的机器学习领域之一。本文以计算机视觉的重要概念为线索,介绍深度学习在计算机视觉任务中的应用,包括网络压缩、细粒度图像分类、看图说话、视觉问答、图像理解、纹理生成和风格迁移、人脸识别、图像检索、目标跟踪等。
相关文章
- Pytorch入门实战(2)-使用BP神经网络实现MNIST手写数字识别
- 基于自注意力机制与无锚点的仔猪姿态识别(农业工程学报)
- 【计算机视觉】人脸表情识别技术
- TensorFlow2-实战-手写数字识别(二):模型版【初始化参数】-->【循环(①根据参数W、B通过模型前向计算,计算出输入X对应的输出Y;②计算Loss;③计算梯度;④利用梯度下降来更新参数)】
- CNCC 2016 | 山世光:深度化的人脸检测与识别技术—进展与展望
- 语音专题第四讲,语音识别之解码器技术简介|大牛讲堂
- 电子元器件识别与检测一点通(第2版)
- 中国人工智能学会通讯——文字识别技术现状、挑战及机遇
- 银行卡识别SDK亮相 扫清支付最后障碍
- 小知识·语音识别的技术原理
- 刷脸和指纹识别out啦,这些公司正在用静脉识别技术颠覆金融业
- 苹果充电器USB端的识别电阻的设置