
elasticsearch + hive环境搭建
一、环境介绍:
elasticsearch:2.3.1
hive:0.12
二、环境搭建
2.1 首先获取elasticsearc-hadoop的jar包
链接地址:http://jcenter.bintray.com/org/elasticsearch/elasticsearch-hadoop/2.3.1/elasticsearch-hadoop-2.3.1.jar,下载即可。需要说明的是你的elasticsearch什么版本,那么elasticsearch-hadoop的jar包就什么版本,否则后果难料
2.2 hive集成elasticsearch
将elasticsearch-hadoop-2.3.1.jar拷贝到hive的默认lib目录即可。我的目录是:$HIVE_HOME/auxlib目录
启动hive,查看效果:
/home/q/java/default/bin/java -Xmx256m -Djava.net.preferIPv4Stack=true *** -hiveconf hive.aux.jars.path=file:///home/q/hive/hive-0.12.0-bin/auxlib/elasticsearch-hadoop-2.0.1.jar
只要包含了上面的红色部分说明集成成功
三、插入数据
3.1 建立数据表
3.1.1 建立view表
CREATE EXTERNAL TABLE user (id INT, name STRING) STORED BY 'org.elasticsearch.hadoop.hive.EsStorageHandler' TBLPROPERTIES('es.resource' = 'radiott/artiststt','es.index.auto.create' = 'true','es.nodes' = 'elastisticsearch.*.qunar.com','es.port' = '9222');
有几个参数,es.nodes是配置的es的url地址,默认是localhost。es.port是端口号码,默认是9200
3.1.2 建立数据表
CREATE TABLE user_source (id INT, name STRING) ROW FORMAT DELIMITED FIELDS TERMINATED BY ',';
3.2 加载数据
3.2.1 加载基础数据
数据示例,我放在/tmp/user_source.log
1,medcl 2,lcdem 3,tom 4,jack
加载到user_source表,命令如下:LOAD DATA LOCAL INPATH '/tmp/user_source.log' OVERWRITE INTO TABLE user_source;
3.2.2 加载到es
INSERT OVERWRITE TABLE user SELECT s.id, s.name FROM user_source s;
查看效果:
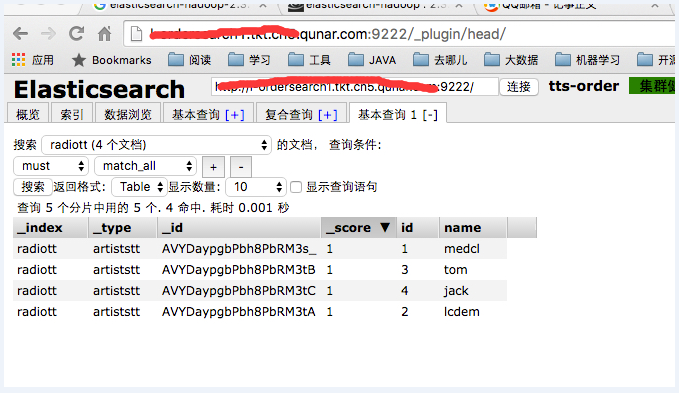
四、参考文档:
http://blog.csdn.net/sunflower_cao/article/details/39896189
https://www.elastic.co/guide/en/elasticsearch/hadoop/current/configuration.html#_essential_settings
相关文章
- Nginx生产环境配置、elasticsearch生产环境配置、rocketmq生产环境配置 (史上最全)
- elasticsearch 安装(基于java运行环境)
- 数据源管理 | 搜索引擎框架,ElasticSearch集群模式
- Elasticsearch - 理解字段分析过程(_analyze与_explain)
- 分布式搜索elasticsearch 基本概念
- ElasticSearch中的过滤查询(filter)
- Elasticsearch Logstash 入门及架构介绍
- ELK实时日志分析平台环境部署--完整记录(ElasticSearch+Logstash+Kibana )
- Elasticsearch之索引模板index template与索引别名index alias
- linux7安装elasticsearch-7.4.0集群配置
- ES (ElasticSearch) 简易解读(四)Docker环境下安装和配置;非常简单的方式
- Elasticsearch 5
- Elasticsearch使用BulkProcessor批量插入
- Linux安装配置ELK日志收集系统,elasticsearch+kibana+filebeat轻量级配置安装