
Spark Day05:Spark Core之Sougou日志分析、外部数据源和共享变量
Spark Day05:Spark Core

文章目录
- Spark Day05:Spark Core
- 01-[了解]-内容回顾
- 02-[了解]-内容提纲
- 03-[掌握]-SogouQ日志分析之数据调研和业务分析
- 04-[掌握]-SogouQ日志分析之HanLP 中文分词
- 05-[掌握]-SogouQ日志分析之数据封装SogouRecord
- 06-[掌握]-SogouQ日志分析之搜索关键词统计
- 07-[掌握]-SogouQ日志分析之用户搜索点击统计
- 08-[掌握]-SogouQ日志分析之搜索时间段统计
- 09-[了解]-外部数据源之Spark与HBase交互概述
- 10-[掌握]-外部数据源之HBase Sink
- 11-[掌握]-外部数据源之HBase Source
- 12-[了解]-外部数据源之MySQL 概述
- 13-[掌握]-外部数据源之MySQL Sink(基本版)
- 14-[掌握]-外部数据源之MySQL Sink(高级版)
- 15-[了解]-RDD 共享变量之含义及案例需求说明
- 16-[掌握]-共享变量之编程实现非单词过滤
01-[了解]-内容回顾
主要讲解:RDD函数,分为两类Transformation转换函数和Action触发函数。
1、RDD函数类型
- 转换函数
当RDD调用转换函数,产生新的RDD
lazy懒惰,不会立即执行
- 触发函数
当RDD调用Action函数,返回值不是RDD,要么没有返回值Unit,要么就是非RDD
立即执行
2、RDD 常用函数
- 基本函数使用
map、flatMap、filter、reduceByKey、foreach等等
- 分区函数
针对RDD中每个分区数据操作处理
mapPartitions(iter => iter)
foreachPartition(iter => Unit)
- 重分区函数
调整RDD中分区数目
增加RDD分区数目:repartition,产生Shuffle,也可以减少分区
减少RDD分区数目:coalesce,不会产生Shuffle,仅仅只能减少分区
- 聚合函数
集合列表中聚合函数:reduce、fold
聚合函数,往往对数据进行聚合时,需要聚合中间临时变量
RDD中reduce和fold函数
基本与列表List中reduce和fold类似
聚合分为2部分:分区数据聚合(局部聚合)和分区间数据聚合(全局聚合)
RDD中高级聚合函数:aggregate
聚合中间临时变量初始值
分区内数据聚合函数
分区间数据聚合函数
PairRDDFunctions中聚合函数
针对RDD为KeyValue类型聚合函数,对相同Key的Value进行聚合
groupByKey,按照Key分组,不建议使用,数据倾斜和OOM
reduceByKey和foldByKey,词频统计中使用
aggregateByKey
关联JOIN函数,RDD数据类型必须时KeyValue对,按照Key进行关联JOIN
等值JOIN
左外连接LeftOuterJoin
3、RDD 持久化
可以将RDD数据缓存,要么存储到内存(Executor内存),要么存储到本地磁盘
为什么要对RDD数据进行持久化,为了快速读取数据,分析处理
- 持久化函数
cache、persist
persist(StorageLevel)
- 持久化级别
5类
- 释放资源
当RDD不在被使用时,要缓存数据进行释放资源
- 什么时候对RDD进行持久化操作
4、RDD Checkpoint
将RDD Checkpoint到可靠文件系统中
- 为什么需要对RDD 进行Checkpoint操作
- Checkpoint与持久化区别
02-[了解]-内容提纲
主要讲解3个方面内容:Sougou日志分析、外部数据源和共享变量。
1、案例分析,熟悉RDD中函数使用
以Sougou官方提供搜索日志进行基本统计分析
3个业务需求
2、外部数据源
SparkCore(RDD)与HBase和MySQL数据库交互
- 与HBase交互
从HBase数据库表读取数据,封装到RDD中
将RDD数据保存到HBase表中
- 与MySQL交互
将RDD数据保存到MySQL表中,必须掌握,无任何理由
JdbcRDD,可以直接将MySQL表数据封装为RDD,基本上不在使用,所以不在讲解
3、共享变量
- broadcast variables
广播变量
- accumulators
累加器
针对知识点,创建Maven Module模块,编写代码结构及进行编号。
03-[掌握]-SogouQ日志分析之数据调研和业务分析
使用搜狗实验室提供【用户查询日志(SogouQ)】数据,使用Spark框架,将数据封装到RDD中进行业务数据处理分析。
- 1)、数据介绍:
搜索引擎查询日志库设计为包括约1个月(2008年6月)Sogou搜索引擎部分网页查询需求及用户点击情况的网页查询日志数据集合。
- 2)、数据格式
访问时间\t用户ID\t[查询词]\t该URL在返回结果中的排名\t用户点击的顺序号\t用户点击的URL
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-sRu202yb-1644834575572)(/img/image-20210423150750606.png)]
- 3)、数据下载:分为三个数据集,大小不一样
迷你版(样例数据, 376KB):
http://download.labs.sogou.com/dl/sogoulabdown/SogouQ/SogouQ.mini.zip
精简版(1天数据,63MB):
http://download.labs.sogou.com/dl/sogoulabdown/SogouQ/SogouQ.reduced.zip
完整版(1.9GB):
http://www.sogou.com/labs/resource/ftp.php?dir=/Data/SogouQ/SogouQ.zip
针对SougouQ查询日志数据,分析业务需求:
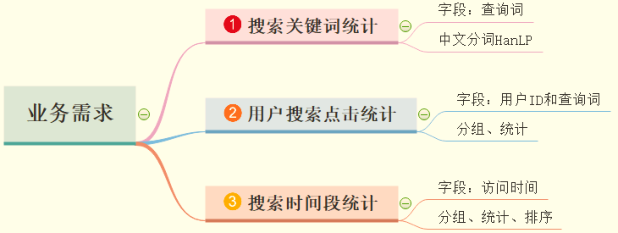
使用SparkContext读取日志数据,封装到RDD数据集中,调用Transformation函数和Action函数处
理分析,灵活掌握Scala语言编程。
04-[掌握]-SogouQ日志分析之HanLP 中文分词
使用比较流行好用中文分词:HanLP,面向生产环境的自然语言处理工具包,HanLP 是由一系列模型与算法组成的 Java 工具包,目标是普及自然语言处理在生产环境中的应用。
官方网站:http://www.hanlp.com/,添加Maven依赖
<!-- https://mvnrepository.com/artifact/com.hankcs/hanlp -->
<dependency>
<groupId>com.hankcs</groupId>
<artifactId>hanlp</artifactId>
<version>portable-1.7.7</version>
</dependency>
演示范例:HanLP 入门案例,基本使用
package cn.itcast.spark.test.hanlp
import java.util
import com.hankcs.hanlp.HanLP
import com.hankcs.hanlp.seg.common.Term
import com.hankcs.hanlp.tokenizer.StandardTokenizer
object HanLpTest {
def main(args: Array[String]): Unit = {
// 入门Demo
val terms: util.List[Term] = HanLP.segment("杰克奥特曼全集视频")
println(terms)
import scala.collection.JavaConverters._
println(terms.asScala.map(term => term.word.trim))
// 标准分词
val terms1: util.List[Term] = StandardTokenizer.segment("放假++端午++重阳")
println(terms1.asScala.map(_.word.replaceAll("\\s+", "")))
}
}
05-[掌握]-SogouQ日志分析之数据封装SogouRecord
将每行日志数据封装到CaseClass样例类SogouRecord中,方便后续处理
package cn.itcast.spark.search
/**
* 用户搜索点击网页记录Record
*
* @param queryTime 访问时间,格式为:HH:mm:ss
* @param userId 用户ID
* @param queryWords 查询词
* @param resultRank 该URL在返回结果中的排名
* @param clickRank 用户点击的顺序号
* @param clickUrl 用户点击的URL
*/
case class SogouRecord(
queryTime: String, //
userId: String, //
queryWords: String, //
resultRank: Int, //
clickRank: Int, //
clickUrl: String //
)
构建
SparkContext实例对象,读取本次SogouQ.sample数据,封装到SougoRecord中 。
// 在Spark 应用程序中,入口为:SparkContext,必须创建实例对象,加载数据和调度程序执行
val sc: SparkContext = {
// 创建SparkConf对象
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 构建SparkContext实例对象
SparkContext.getOrCreate(sparkConf)
}
// TODO: 1. 从本地文件系统读取搜索日志数据
val rawLogsRDD: RDD[String] = sc.textFile("datas/sogou/SogouQ.sample", minPartitions = 2)
//println(s"First:\n ${rawLogsRDD.first()}")
//println(s"Count: ${rawLogsRDD.count()}")
// TODO: 2. 解析数据(先过滤不合格的数据),封装样例类SogouRecord对象
val sogouLogsRDD: RDD[SogouRecord] = rawLogsRDD
// 过滤数据
.filter(log => null != log && log.trim.split("\\s+").length == 6)
// 解析日志,封装实例对象
.mapPartitions(iter => {
iter.map(log => {
// 安装分隔符划分数据
val split: Array[String] = log.trim.split("\\s+")
// 构建实例对象
SogouRecord(
split(0),
split(1), //
split(2).replaceAll("\\[", "").replace("]", ""),
split(3).toInt,
split(4).toInt,
split(5)
)
})
})
//println(s"Count = ${sogouLogsRDD.count()}")
//println(s"First: ${sogouLogsRDD.first()}")
补充知识点:详解 “\s+”
正则表达式中\s匹配任何空白字符,包括空格、制表符、换页符等等, 等价于[ \f\n\r\t\v]
\f -> 匹配一个换页
\n -> 匹配一个换行符
\r -> 匹配一个回车符
\t -> 匹配一个制表符
\v -> 匹配一个垂直制表符
而“\s+”则表示匹配任意多个上面的字符。另因为反斜杠在Java里是转义字符,所以在Java里,我们要这么用“\\s+”.
那么问题来了,“\\s+”有啥使用场景呢?
注:
[\s]表示,只要出现空白就匹配
[\S]表示,非空白就匹配
06-[掌握]-SogouQ日志分析之搜索关键词统计
获取用户【查询词】,使用HanLP进行分词,按照单词分组聚合统计出现次数,类似WordCount程序,具体代码如下:
- 第一步、获取每条日志数据中【查询词
queryWords】字段数据- 第二步、使用HanLP对查询词进行中文分词
- 第三步、按照分词中单词进行词频统计,类似WordCount
// TODO: 3. 依据需求对数据进行分析
/*
需求一、搜索关键词统计,使用HanLP中文分词
- 第一步、获取每条日志数据中【查询词`queryWords`】字段数据
- 第二步、使用HanLP对查询词进行中文分词
- 第三步、按照分词中单词进行词频统计,类似WordCount
*/
val queryKeyWordsCountRDD: RDD[(String, Int)] = sogouLogsRDD
// 提取查询词字段的值
.flatMap { record =>
val query: String = record.queryWords
// 使用HanLP分词
val terms: util.List[Term] = HanLP.segment(query.trim)
// 转换为Scala中集合列表,对每个分词进行处理
terms.asScala.map(term => term.word.trim)
}
// 转换每个分词为二元组,表示分组出现一次
.map(word => (word, 1))
// 按照单词分组,统计次数
.reduceByKey((tmp, item) => tmp + item)
//queryKeyWordsCountRDD.take(10).foreach(println)
// TODO: 获取查询词Top10
queryKeyWordsCountRDD
.map(tuple => tuple.swap)
.sortByKey(ascending = false) // 降序排序
.take(10)
.foreach(println)
07-[掌握]-SogouQ日志分析之用户搜索点击统计
统计出每个用户每个搜索词点击网页的次数,可以作为搜索引擎搜索效果评价指标。先按照用户ID分组,再按照【查询词】分组,最后统计次数,求取最大次数、最小次数及平均次数。
/*
需求二、用户搜索次数统计
TODO: 统计每个用户对每个搜索词的点击次数,二维分组:先对用户分组,再对搜索词分组
SQL:
SELECT user_id, query_words, COUNT(1) AS total FROM records GROUP BY user_id, query_words
*/
val clickCountRDD: RDD[((String, String), Int)] = sogouLogsRDD
// 提取字段值
.map(record => (record.userId, record.queryWords) -> 1)
// 按照Key(先userId,再queryWords)分组,进行聚合统计
.reduceByKey(_ + _)
//clickCountRDD.take(50).foreach(println)
//TODO: 单独提取出每个用户搜索时次数,进行统计
val countRDD: RDD[Int] = clickCountRDD.map(tuple => tuple._2)
println(s"Max Click Count: ${countRDD.max()}")
println(s"Min Click Count: ${countRDD.min()}")
println(s"stats Click Count: ${countRDD.stats()}") // 数理统计
08-[掌握]-SogouQ日志分析之搜索时间段统计
按照【访问时间】字段获取【小时】,分组统计各个小时段用户查询搜索的数量,进一步观察用户喜欢在哪些时间段上网,使用搜狗引擎搜索。
/*
需求三、搜索时间段统计, 按照每个小时统计用户搜索次数
00:00:00 -> 00 提取出小时
*/
val hourCountRDD: RDD[(Int, Int)] = sogouLogsRDD
// 提取时间字段值
.map { record =>
val queryTime = record.queryTime
// 获取小时
val hour = queryTime.substring(0, 2)
// 返回二元组
(hour.toInt, 1)
}
// 按照小时分组,进行聚合统计
.foldByKey(0)(_ + _)
//hourCountRDD.foreach(println)
// TODO: 按照次数进行降序排序
hourCountRDD
.top(24)(Ordering.by(tuple => tuple._2))
.foreach(println)
09-[了解]-外部数据源之Spark与HBase交互概述
Spark可以从外部存储系统读取数据,比如RDBMs表中或者HBase表中读写数据,这也是企业中常常使用,如下两个场景:

Spark如何从HBase数据库表中读(read:RDD)写(write:RDD)数据呢???
- 加载数据:从HBase表读取数据,封装为RDD,进行处理分析
- 保存数据:将RDD数据直接保存到HBase表中
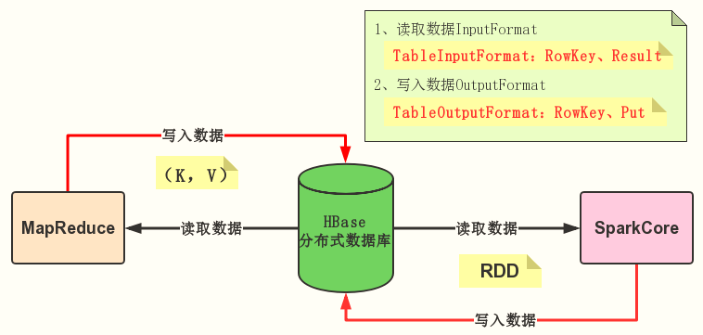
Spark可以从HBase表中读写(Read/Write)数据,底层采用TableInputFormat和TableOutputFormat方式,与MapReduce与HBase集成完全一样,使用输入格式InputFormat和输出格式OutputFoamt。
10-[掌握]-外部数据源之HBase Sink
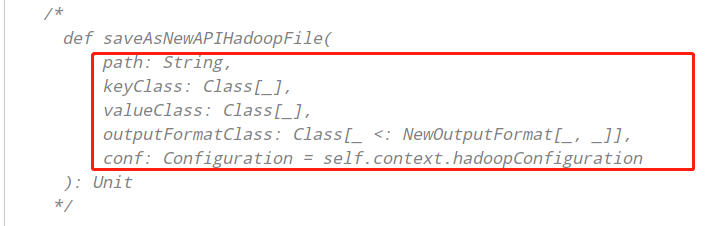
写 入 数 据 时 , 需 要 将 RDD 转 换 为
RDD[(ImmutableBytesWritable, Put)]类 型 , 调 用
saveAsNewAPIHadoopFile方法数据保存至HBase表中。
HBase Client连接时,需要设置依赖Zookeeper地址相关信息及表的名称,通过
Configuration设置属性值进行传递。

范例演示:将词频统计结果保存HBase表,表的设计
# 选择node1.itcast.cn 虚拟机,还原到快照[5、Spark 本地模式],启动虚拟机,运行服务组件: [root@node1 ~]# zookeeper-daemon.sh start [root@node1 ~]# hadoop-daemon.sh start namenode starting namenode, logging to /export/server/hadoop-2.6.0-cdh5.16.2/logs/hadoop-root-namenode-node1.itcast.cn.out [root@node1 ~]# [root@node1 ~]# hadoop-daemon.sh start datanode starting datanode, logging to /export/server/hadoop-2.6.0-cdh5.16.2/logs/hadoop-root-datanode-node1.itcast.cn.out [root@node1 ~]# hbase-daemon.sh start master starting master, logging to /export/server/hbase/logs/hbase-root-master-node1.itcast.cn.out [root@node1 ~]# hbase-daemon.sh start regionserver starting regionserver, logging to /export/server/hbase/logs/hbase-root-regionserver-node1.itcast.cn.out [root@node1 ~]# hbase shell hbase(main):004:0* create 'htb_wordcount', 'info' 0 row(s) in 1.3160 seconds => Hbase::Table - htb_wordcount

package cn.itcast.spark.hbase.sink
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.HBaseConfiguration
import org.apache.hadoop.hbase.client.Put
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableOutputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 将RDD数据保存至HBase表中
*/
object _02SparkWriteHBase {
def main(args: Array[String]): Unit = {
// 1. 在Spark 应用程序中,入口为:SparkContext,必须创建实例对象,加载数据和调度程序执行
val sc: SparkContext = {
// 创建SparkConf对象,设置应用相关信息,比如名称和master
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 构建SparkContext实例对象,传递SparkConf
new SparkContext(sparkConf)
}
// 2. 第一步、从LocalFS读取文件数据,sc.textFile方法,将数据封装到RDD中
val inputRDD: RDD[String] = sc.textFile("datas/wordcount.data")
// 3. 第二步、调用RDD中高阶函数,进行处理转换处理,函数:flapMap、map和reduceByKey
val resultRDD: RDD[(String, Int)] = inputRDD
// 过滤
.filter(line => null != line && line.trim.length > 0 )
// a. 对每行数据按照分割符分割
.flatMap(line => line.trim.split("\\s+"))
// b. 将每个单词转换为二元组,表示出现一次
.map(word => (word ,1))
.reduceByKey((temp, item) => temp + item)
// 4. 第三步、将最终处理结果RDD保存到HDFS或打印控制台
/*
(hive,6)
(spark,11)
(mapreduce,4)
(hadoop,3)
(sql,2)
(hdfs,2)
*/
//resultRDD.foreach(tuple => println(tuple))
// TODO: step 1. 转换RDD为RDD[(RowKey, Put)]
/*
* HBase表的设计:
* 表的名称:htb_wordcount
* Rowkey: word
* 列簇: info
* 字段名称: count
create 'htb_wordcount', 'info'
*/
val putsRDD: RDD[(ImmutableBytesWritable, Put)] = resultRDD.map{case (word, count) =>
// 其一、构建RowKey对象
val rowKey: ImmutableBytesWritable = new ImmutableBytesWritable(Bytes.toBytes(word))
// 其二、构建Put对象
val put: Put = new Put(rowKey.get())
// 设置字段的值
put.addColumn(Bytes.toBytes("info"), Bytes.toBytes("count"), Bytes.toBytes(count + ""))
// 其三、返回二元组(RowKey, Put)
rowKey -> put
}
// TODO: step2. 调用RDD中saveAsNewAPIHadoopFile保存数据
val conf: Configuration = HBaseConfiguration.create()
// 设置连接Zookeeper属性
conf.set("hbase.zookeeper.quorum", "node1.itcast.cn")
conf.set("hbase.zookeeper.property.clientPort", "2181")
conf.set("zookeeper.znode.parent", "/hbase")
// 设置将数据保存的HBase表的名称
conf.set(TableOutputFormat.OUTPUT_TABLE, "htb_wordcount")
/*
def saveAsNewAPIHadoopFile(
path: String,
keyClass: Class[_],
valueClass: Class[_],
outputFormatClass: Class[_ <: NewOutputFormat[_, _]],
conf: Configuration = self.context.hadoopConfiguration
): Unit
*/
putsRDD.saveAsNewAPIHadoopFile(
"datas/hbase/htb_wordcount/", //
classOf[ImmutableBytesWritable], //
classOf[Put], //
classOf[TableOutputFormat[ImmutableBytesWritable]], //
conf
)
// 5. 当应用运行结束以后,关闭资源
sc.stop()
}
}
面试题:
HBase数据读写流程???
HBase存储数据表Table如何设计的???
11-[掌握]-外部数据源之HBase Source
回 顾 MapReduce 从 读 HBase 表 中 的 数 据 , 使 用 TableMapper , 其 中 InputFormat 为
TableInputFormat,读取数据Key:ImmutableBytesWritable,Value:Result。

从HBase表读取数据时,同样需要设置依赖Zookeeper地址信息和表的名称,使用Configuration
设置属性,形式如下:
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-c4nWt0ch-1644834575577)(/img/image-20210423171418282.png)]
此外,读取的数据封装到RDD中,Key和Value类型分别为:ImmutableBytesWritable和Result,不支持Java Serializable导致处理数据时报序列化异常。
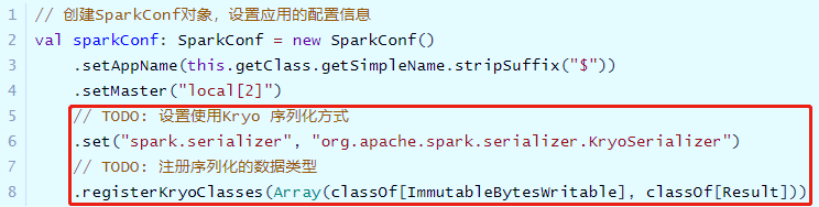
设置Spark Application使用Kryo序列化,性能要比Java 序列化要好,创建SparkConf对象设置相关属性,如下所示:
范例演示:从HBase表读取词频统计结果,代码如下
package cn.itcast.spark.hbase.source
import org.apache.hadoop.conf.Configuration
import org.apache.hadoop.hbase.{CellUtil, HBaseConfiguration}
import org.apache.hadoop.hbase.client.Result
import org.apache.hadoop.hbase.io.ImmutableBytesWritable
import org.apache.hadoop.hbase.mapreduce.TableInputFormat
import org.apache.hadoop.hbase.util.Bytes
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 从HBase 表中读取数据,封装到RDD数据集
*/
object _03SparkReadHBase {
def main(args: Array[String]): Unit = {
// 1. 在Spark 应用程序中,入口为:SparkContext,必须创建实例对象,加载数据和调度程序执行
val sc: SparkContext = {
// 创建SparkConf对象,设置应用相关信息,比如名称和master
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// TODO: 设置使用Kryo 序列化方式
.set("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
// TODO: 注册序列化的数据类型
.registerKryoClasses(Array(classOf[ImmutableBytesWritable], classOf[Result]))
// 构建SparkContext实例对象,传递SparkConf
new SparkContext(sparkConf)
}
// TODO: 从HBase表读取数据,调用RDD方法:newAPIHadoopRDD
val conf: Configuration = HBaseConfiguration.create()
// 设置连接Zookeeper属性
conf.set("hbase.zookeeper.quorum", "node1.itcast.cn")
conf.set("hbase.zookeeper.property.clientPort", "2181")
conf.set("zookeeper.znode.parent", "/hbase")
// 设置将数据保存的HBase表的名称
conf.set(TableInputFormat.INPUT_TABLE, "htb_wordcount")
/*
def newAPIHadoopRDD[K, V, F <: NewInputFormat[K, V]](
conf: Configuration = hadoopConfiguration,
fClass: Class[F],
kClass: Class[K],
vClass: Class[V]
): RDD[(K, V)]
*/
val hbaseRDD: RDD[(ImmutableBytesWritable, Result)] = sc.newAPIHadoopRDD(
conf, //
classOf[TableInputFormat], //
classOf[ImmutableBytesWritable], //
classOf[Result] //
)
println(s"Count = ${hbaseRDD.count()}")
// 打印HBase表样本数据
hbaseRDD
.take(6)
.foreach{case (rowKey, result) =>
result.rawCells().foreach{cell =>
println(s"RowKey = ${Bytes.toString(result.getRow)}")
println(s"\t${Bytes.toString(CellUtil.cloneFamily(cell))}:" +
s"${Bytes.toString(CellUtil.cloneQualifier(cell))} = " +
s"${Bytes.toString(CellUtil.cloneValue(cell))}")
}
}
// 5. 当应用运行结束以后,关闭资源
sc.stop()
}
}
12-[了解]-外部数据源之MySQL 概述
实际开发中常常将分析结果RDD保存至MySQL表中,使用foreachPartition函数;
调用RDD#foreachPartition函数将每个分区数据保存至MySQL表中,保存时
考虑降低RDD分区数目和批量插入,提升程序性能。
- 建表语句
USE db_test ;
CREATE TABLE `tb_wordcount` (
`count` varchar(100) CHARACTER SET utf8mb4 COLLATE utf8mb4_0900_ai_ci NOT NULL,
`word` varchar(100) NOT NULL,
PRIMARY KEY (`word`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 COLLATE=utf8mb4_0900_ai_ci ;
13-[掌握]-外部数据源之MySQL Sink(基本版)
范例演示:将词频统计WordCount结果保存MySQL表tb_wordcount。
package cn.itcast.spark.mysql
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 将RDD数据保存至MySQL表中: tb_wordcount
*/
object _04SparkWriteMySQL {
def main(args: Array[String]): Unit = {
// 1. 在Spark 应用程序中,入口为:SparkContext,必须创建实例对象,加载数据和调度程序执行
val sc: SparkContext = {
// 创建SparkConf对象,设置应用相关信息,比如名称和master
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 构建SparkContext实例对象,传递SparkConf
new SparkContext(sparkConf)
}
// 2. 第一步、从LocalFS读取文件数据,sc.textFile方法,将数据封装到RDD中
val inputRDD: RDD[String] = sc.textFile("datas/wordcount.data")
// 3. 第二步、调用RDD中高阶函数,进行处理转换处理,函数:flapMap、map和reduceByKey
val resultRDD: RDD[(String, Int)] = inputRDD
// TODO: 过滤
.filter(line => null != line && line.trim.length > 0 )
// a. 对每行数据按照分割符分割
.flatMap(line => line.trim.split("\\s+"))
// b. 将每个单词转换为二元组,表示出现一次
.map(word => (word ,1))
.reduceByKey((temp, item) => temp + item)
// 4. 第三步、将最终处理结果RDD保存到HDFS或打印控制台
/*
(spark,11)
(hive,6)
(hadoop,3)
(mapreduce,4)
(hdfs,2)
(sql,2)
*/
//resultRDD.foreach(tuple => println(tuple))
// TODO: 将结果数据resultRDD保存至MySQL表中
/*
a. 对结果数据降低分区数目
b. 针对每个分区数据进行操作
每个分区数据插入数据库时,创建一个连接Connection
*/
resultRDD
// 降低RDD分区数目
.coalesce(1)
.foreachPartition{iter =>
// val xx: Iterator[(String, Int)] = iter
// 直接调用保存分区数据到MySQL表的方法
saveToMySQL(iter)
}
// 5. 当应用运行结束以后,关闭资源
sc.stop()
}
/**
* 定义一个方法,将RDD中分区数据保存至MySQL表,第一个版本
*/
def saveToMySQL(iter: Iterator[(String, Int)]): Unit = {
// step1. 加载驱动类
Class.forName("com.mysql.cj.jdbc.Driver")
// 声明变量
var conn: Connection = null
var pstmt: PreparedStatement = null
try{
// step2. 创建连接
conn = DriverManager.getConnection(
"jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true",
"root",
"123456"
)
pstmt = conn.prepareStatement("INSERT INTO db_test.tb_wordcount (word, count) VALUES(?, ?)")
// step3. 插入数据
iter.foreach{case (word, count) =>
pstmt.setString(1, word)
pstmt.setInt(2, count)
pstmt.execute()
}
}catch {
case e: Exception => e.printStackTrace()
}finally {
// step4. 关闭连接
if(null != pstmt) pstmt.close()
if(null != conn) conn.close()
}
}
}
在上述代码中,有个小问题:每个分区数据进行插入时,都是一条一条插入,没有进行批量插入,可以进行优化。
package cn.itcast.spark.mysql
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 将RDD数据保存至MySQL表中: tb_wordcount
*/
object _04SparkWriteMySQLV2 {
def main(args: Array[String]): Unit = {
// 1. 在Spark 应用程序中,入口为:SparkContext,必须创建实例对象,加载数据和调度程序执行
val sc: SparkContext = {
// 创建SparkConf对象,设置应用相关信息,比如名称和master
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 构建SparkContext实例对象,传递SparkConf
new SparkContext(sparkConf)
}
// 2. 第一步、从LocalFS读取文件数据,sc.textFile方法,将数据封装到RDD中
val inputRDD: RDD[String] = sc.textFile("datas/wordcount.data")
// 3. 第二步、调用RDD中高阶函数,进行处理转换处理,函数:flapMap、map和reduceByKey
val resultRDD: RDD[(String, Int)] = inputRDD
// TODO: 过滤
.filter(line => null != line && line.trim.length > 0 )
// a. 对每行数据按照分割符分割
.flatMap(line => line.trim.split("\\s+"))
// b. 将每个单词转换为二元组,表示出现一次
.map(word => (word ,1))
.reduceByKey((temp, item) => temp + item)
// 4. 第三步、将最终处理结果RDD保存到HDFS或打印控制台
//resultRDD.foreach(tuple => println(tuple))
// TODO: 将结果数据resultRDD保存至MySQL表中
/*
a. 对结果数据降低分区数目
b. 针对每个分区数据进行操作
每个分区数据插入数据库时,创建一个连接Connection
c. 批次插入每个分区数据
addBatch
executeBatch
*/
resultRDD
.coalesce(1)
.foreachPartition(iter => saveToMySQL(iter))
// 5. 当应用运行结束以后,关闭资源
sc.stop()
}
/**
* 定义一个方法,将RDD中分区数据保存至MySQL表,第二个版本
*/
def saveToMySQL(iter: Iterator[(String, Int)]): Unit = {
// step1. 加载驱动类
Class.forName("com.mysql.cj.jdbc.Driver")
// 声明变量
var conn: Connection = null
var pstmt: PreparedStatement = null
try{
// step2. 创建连接
conn = DriverManager.getConnection(
"jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true",
"root",
"123456"
)
pstmt = conn.prepareStatement("INSERT INTO db_test.tb_wordcount (word, count) VALUES(?, ?)")
// step3. 插入数据
iter.foreach{case (word, count) =>
pstmt.setString(1, word)
pstmt.setInt(2, count)
//pstmt.executeUpdate();
// TODO: 加入一个批次中
pstmt.addBatch()
}
// TODO:批量执行批次
pstmt.executeBatch()
}catch {
case e: Exception => e.printStackTrace()
}finally {
// step4. 关闭连接
if(null != pstmt) pstmt.close()
if(null != conn) conn.close()
}
}
}
14-[掌握]-外部数据源之MySQL Sink(高级版)
针对上述代码,还可以进一步优化:
第一个方面:手动提交事务,将每个分区数据保存时,要么都成功,要么都失败
第二个方面:插入语句INSERT语句
INSERT INTO db_test.tb_wordcount (word, count) VALUES(?, ?)不能实现主键存在时更新数据,不存在时插入数据功能。
REPLACE INTO db_test.tb_wordcount (word, count) VALUES(?, ?)
package cn.itcast.spark.mysql
import java.sql.{Connection, DriverManager, PreparedStatement}
import org.apache.spark.rdd.RDD
import org.apache.spark.{SparkConf, SparkContext}
/**
* 将RDD数据保存至MySQL表中: tb_wordcount
*/
object _04SparkWriteMySQLV3 {
def main(args: Array[String]): Unit = {
// 1. 在Spark 应用程序中,入口为:SparkContext,必须创建实例对象,加载数据和调度程序执行
val sc: SparkContext = {
// 创建SparkConf对象,设置应用相关信息,比如名称和master
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 构建SparkContext实例对象,传递SparkConf
new SparkContext(sparkConf)
}
// 2. 第一步、从LocalFS读取文件数据,sc.textFile方法,将数据封装到RDD中
val inputRDD: RDD[String] = sc.textFile("datas/wordcount.data")
// 3. 第二步、调用RDD中高阶函数,进行处理转换处理,函数:flapMap、map和reduceByKey
val resultRDD: RDD[(String, Int)] = inputRDD
// TODO: 过滤
.filter(line => null != line && line.trim.length > 0 )
// a. 对每行数据按照分割符分割
.flatMap(line => line.trim.split("\\s+"))
// b. 将每个单词转换为二元组,表示出现一次
.map(word => (word ,1))
.reduceByKey((temp, item) => temp + item)
// 4. 第三步、将最终处理结果RDD保存到HDFS或打印控制台
//resultRDD.foreach(tuple => println(tuple))
// TODO: 将结果数据resultRDD保存至MySQL表中
/*
a. 对结果数据降低分区数目
b. 针对每个分区数据进行操作
每个分区数据插入数据库时,创建一个连接Connection
c. 批次插入每个分区数据
addBatch
executeBatch
d. 事务性
手动提交事务,并且还原原来事务
e. 考虑主键存在时,如何保存数据数据
存在,更新数据;不存在,插入数据
*/
resultRDD.coalesce(1).foreachPartition(saveToMySQL)
// 5. 当应用运行结束以后,关闭资源
sc.stop()
}
/**
* 定义一个方法,将RDD中分区数据保存至MySQL表,第三个版本
*/
def saveToMySQL(iter: Iterator[(String, Int)]): Unit = {
// step1. 加载驱动类
Class.forName("com.mysql.cj.jdbc.Driver")
// 声明变量
var conn: Connection = null
var pstmt: PreparedStatement = null
try{
// step2. 创建连接
conn = DriverManager.getConnection(
"jdbc:mysql://node1.itcast.cn:3306/?serverTimezone=UTC&characterEncoding=utf8&useUnicode=true",
"root",
"123456"
)
pstmt = conn.prepareStatement("replace INTO db_test.tb_wordcount (word, count) VALUES(?, ?)")
// TODO: 考虑事务性,一个分区数据要全部保存,要不都不保存
val autoCommit: Boolean = conn.getAutoCommit // 获取数据库默认事务提交方式
conn.setAutoCommit(false)
// step3. 插入数据
iter.foreach{case (word, count) =>
pstmt.setString(1, word)
pstmt.setInt(2, count)
// TODO: 加入一个批次中
pstmt.addBatch()
}
// TODO:批量执行批次
pstmt.executeBatch()
conn.commit() // 手动提交事务,进行批量插入
// 还原数据库原来事务
conn.setAutoCommit(autoCommit)
}catch {
case e: Exception => e.printStackTrace()
}finally {
// step4. 关闭连接
if(null != pstmt) pstmt.close()
if(null != conn) conn.close()
}
}
}
15-[了解]-RDD 共享变量之含义及案例需求说明
Spark提供了两种类型的变量:

- 广播变量
广播变量允许开发人员
在每个节点(Worker or Executor)缓存只读变量,而不是在Task之间传递这些变量。
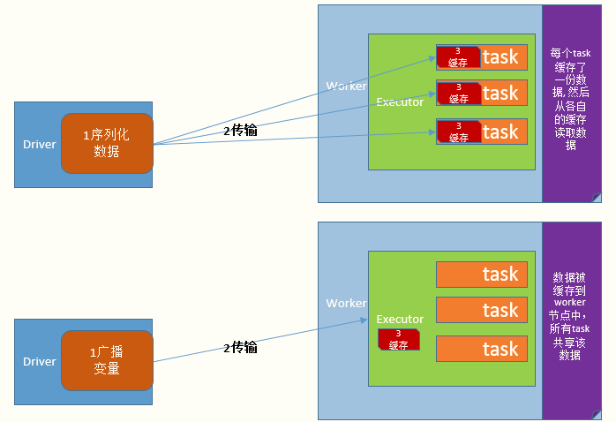
可以通过调用sc.broadcast(v)创建一个广播变量,该广播变量的值封装在v变量中,可使用获取该变量value的方法进行访问。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-z0vexXPD-1644834575580)(/img/image-20210423181056676.png)]
- 累加器
Accumulator只提供了累加的功能,即确提供了多个task对一个变量并行操作的功能。但是task只能对Accumulator进行累加操作,不能读取Accumulator的值,只有Driver程序可以读取Accumulator的值。
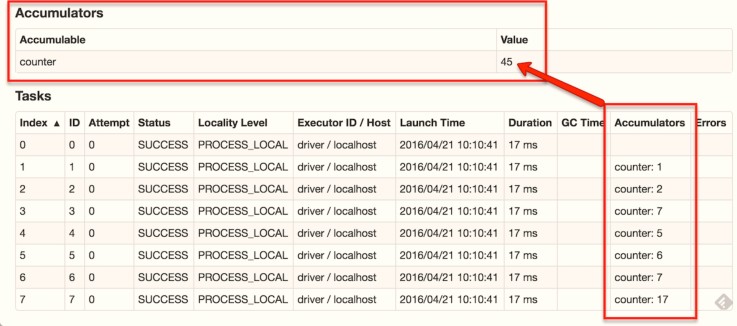
Spark内置了三种类型的Accumulator,分别是
LongAccumulator用来累加整数型,DoubleAccumulator用来累加浮点型,CollectionAccumulator用来累加集合元素。
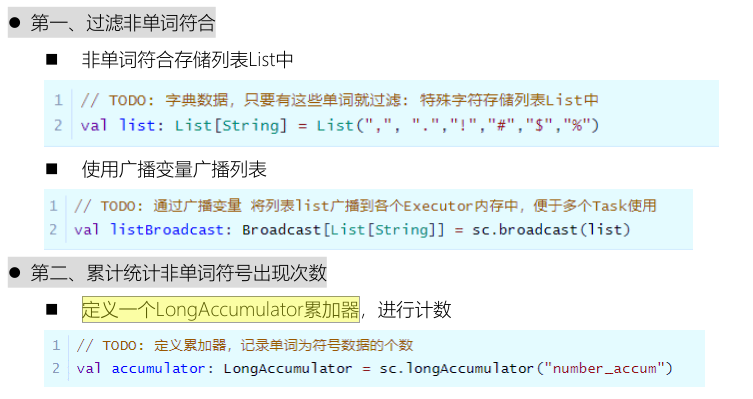
需求:以词频统计WordCount程序为例,假设处理的数据如下所示,包括非单词符合,统计数据词
频时过滤非单词的符合并且统计总的格式。

实现功能如下所示:
16-[掌握]-共享变量之编程实现非单词过滤
编程实现词频统计,对非单词字符进行过滤,并且统计非单词字符的个数,此处使用Spark中共享变量(广播变量和累加器)。
package cn.itcast.spark.shared
import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import org.apache.spark.util.LongAccumulator
import org.apache.spark.{SparkConf, SparkContext}
/**
* 基于Spark框架使用Scala语言编程实现词频统计WordCount程序,将符号数据过滤,并统计出现的次数
* -a. 过滤标点符号数据
* 使用广播变量
* -b. 统计出标点符号数据出现次数
* 使用累加器
*/
object _05SparkSharedVariableTest {
def main(args: Array[String]): Unit = {
// 1. 在Spark 应用程序中,入口为:SparkContext,必须创建实例对象,加载数据和调度程序执行
val sc: SparkContext = {
// 创建SparkConf对象,设置应用相关信息,比如名称和master
val sparkConf: SparkConf = new SparkConf()
.setAppName(this.getClass.getSimpleName.stripSuffix("$"))
.setMaster("local[2]")
// 构建SparkContext实例对象,传递SparkConf
new SparkContext(sparkConf)
}
// 2. 第一步、从LocalFS读取文件数据,sc.textFile方法,将数据封装到RDD中
val inputRDD: RDD[String] = sc.textFile("datas/filter/datas.input", minPartitions = 2)
// TODO: 字典数据,只要有这些单词就过滤: 特殊字符存储列表List中
val list: List[String] = List(",", ".", "!", "#", "$", "%")
// TODO: 将字典数据进行广播变量
val broadcastList: Broadcast[List[String]] = sc.broadcast(list)
// TODO: 定义计数器
val accumulator: LongAccumulator = sc.longAccumulator("number_accu")
// 3. 第二步、调用RDD中高阶函数,进行处理转换处理,函数:flapMap、map和reduceByKey
val resultRDD: RDD[(String, Int)] = inputRDD
// 过滤空行数据
.filter(line => null != line && line.trim.length > 0)
// 分割为单词
.flatMap(line => line.trim.split("\\s+"))
// TODO: 过滤非单词字符
.filter{word =>
// 获取广播变量的值
val wordsList: List[String] = broadcastList.value
// 判断每个单词是否时非单词字符
val flag: Boolean = wordsList.contains(word)
if(flag){
// 如果是非单词字符,累加器加1
accumulator.add(1L)
}
// 返回
! flag
}
// 按照单词分组,进行聚合操作
.map(word => (word, 1))
.reduceByKey(_ + _)
// 4. 第三步、将最终处理结果RDD保存到HDFS或打印控制台
resultRDD.foreach(println)
// 可以累加器的值,必须使用RDD Action函数进行触发
println("Accumulator: " + accumulator.value)
// 5. 当应用运行结束以后,关闭资源
Thread.sleep(10000000)
sc.stop()
}
}
相关文章
- EntityFramework Core并发导致显式插入主键问题
- abp(net core)+easyui+efcore实现仓储管理系统——ABP WebAPI与EasyUI结合增删改查之一(二十七)
- (六)Net Core项目使用Controller之一 c# log4net 不输出日志 .NET Standard库引用导致的FileNotFoundException探究 获取json串里的某个属性值 common.js 如何调用common.js js 筛选数据 Join 具体用法
- .Net Core和.Net Standard直观理解
- 【23种设计模式】外观模式(Facade Pattern) .Net Core实现
- POJ 3469 Dual Core CPU
- 如何将.NET Core部署为Windows服务
- 【HMS Core】Health Kit关于订阅消息的资讯
- 【HMS Core】运动健康服务数据采集必学篇
- 【HMS Core】运动健康服务发起授权失败
- 【HMS Core】机器学习服务助力APP快速集成图像分割与上传功能
- iOS之Core Data及其线程安全
- .Net Core Grpc 实现通信
- .Net Core 中使用NLog作为日志中间件
- 在Linux环境下使用Jexus部署ASP.NET Core
- SwiftUI 中使用 Core Data 的快速指南,在 iOS 中将 Core Data 框架与 SwiftUI 结合使用的基础知识 当谈到在 iOS 中持久化复杂的数据结构时,Apple 为我
- Core Animation - 事务之隐式动画
- MacOS下VScode安装PlatformIO Core卡死和新建项目速度慢的解决方法
- 给ASP.NET Core WebAPI添加Swagger支持