
分布式实时消息队列Kafka(五)
分布式实时消息队列Kafka(五)
知识点01:课程回顾
-
一个消费者组中有多个消费者,消费多个Topic多个分区,分区分配给消费者的分配规则有哪些?
- 分配场景
- 第一次消费:将分区分配给消费者
- 负载均衡实现:在消费过程中,如果有部分消费者故障或者增加了新的消费
- 基本规则
- 一个分区只能被一个消费者所消费
- 一个消费者可以消费多个分区
- 分配规则
- 范围分配
- 规则:每个消费者消费一定范围的分区,尽量均分,如果不能均分,优先分配给标号小的
- 应用:消费比较少的Topic,或者多个Topic都能均分
- 轮询分配
- 规则:按照所有分区的编号进行顺序轮询分配
- 应用:所有消费者消费的Topic都是一致的,能实现将所有分区轮询分配给所有消费者
- 黏性分配
- 规则:尽量保证分配的均衡,尽量避免网络的IO,如果出现故障,保证 每个消费者依旧消费原来的分区,将多出来的分区均分给剩下的消费者
- 应用:建议使用分配规则
- 范围分配
- 分配场景
-
Kafka写入数据过程是什么?
- step1:生产者提交写入请求给Kafka:Topic、K、V
- step2:Kafka根据Topic以及根据Key的分区规则,获取要写入的分区编号
- step3:Kafka要获取元数据【ZK】找到对应分区所在的Broker
- step4:先写入Broker对应的PageCache,添加Offset
- step5:OS会进行同步将PageCache中的数据写入磁盘文件:最新Segment对应.log文件中
- step5:Follower副本到Leader副本中同步数据
-
Kafka读取数据过程是什么?
- step1:消费者消费请求提交Kafka:Topic、Partition、Offset
- step2:根据Topic以及Partition来获取要读取的分区编号
- step3:根据分区编号从元数据中找到这个分区对应的leader副本
- step4:先读取Broker对应的PageCache,如果有,使用零拷贝机制读取内存中的数据
- step5:没有就读取Segment,先根据offset决定读取哪个Segment
- step6:先读.index文件,从索引中获取offset对应在这个文件中的最近位置
- step7:根据最近位置读取.log文件,获取要读取的数据
-
为什么Kafka读写会很快?
- 写
- 先写PageCache:内存缓冲机制
- 实现了顺序写的过程
- 读
- 先读PageCache,使用零拷贝机制
- 按照offset顺序读取数据
- 划分Segment
- 构建index索引
- 写
-
为什么要设计Segment?
-
设计原因
- 加快查询效率
- 增加删除效率:避免一条一条删除,按照整个Segment进行删除
-
如何实现:一对文件
- .log
- .index
-
划分规则
- 时间:7天
- 大小:1G
-
命名规则:每个文件中存储最小offset
-
-
Kafka的如何实现数据清理?
- delete:时间
知识点02:课程目标
- Kafka数据安全的保障机制【重要】
- 集群数据安全:副本机制
- AR
- ISR
- OSR
- HW
- LEO
- Leader副本的选举:Kafka Crontroller
- 一次性语义:保证数据不丢失、不重复
- 生产
- 不丢失:acks + retry
- 不重复
- 消费:通过自己手动管理Offset,消费分区成功、处理分区成功、手动提交offset存储
- 不丢失
- 不重复
- 生产
- 集群数据安全:副本机制
- Kafka Eagle:基于网页版本的可视化工具
- 用于监控Kafka集群
- 自动实现Kafka集群负载的报表
知识点03:Kafka分区副本概念:AR、ISR、OSR
-
目标:了解分区副本机制,掌握分区副本中的特殊概念
Topic: bigdata01 PartitionCount: 3 ReplicationFactor: 2 Configs: segment.bytes=1073741824 Topic: bigdata01 Partition: 0 Leader: 2 Replicas: 1,2 Isr: 2,1 Topic: bigdata01 Partition: 1 Leader: 0 Replicas: 0,1 Isr: 1,0 Topic: bigdata01 Partition: 2 Leader: 2 Replicas: 2,0 Isr: 2,0 -
路径
- Kafka中的分区数据如何保证数据安全?
- 什么是AR、ISR、OSR?
-
实施
-
分区副本机制:每个kafka中分区都可以构建多个副本,相同分区的副本存储在不同的节点上
- 为了保证安全和写的性能:划分了副本角色
- leader副本:对外提供读写数据
- follower副本:与Leader同步数据,如果leader故障,选举一个新的leader
-
AR:All - Replicas
-
所有副本:指的是一个分区在所有节点上的副本
每个分区有两个副本 Partition: 0 Replicas: 1,2
-
-
ISR:In - Sync - Replicas
-
可用副本:Leader与所有正在与Leader同步的Follower副本
Partition: 0 Leader: 2 Replicas: 1,2 Isr: 2,1 -
列表中:按照优先级排列【Controller根据副本同步状态以及Broker健康状态】,越靠前越会成为leader
-
-
OSR:Out - Sync - Replicas
-
不可用副本:与Leader副本的同步差距很大,成为一个OSR列表的不可用副本
-
原因:网路故障等外部环境因素,某个副本与Leader副本的数据差异性很大
-
判断是否是一个OSR副本?
-
0.9之前:时间和数据差异
replica.lag.time.max.ms = 10000 可用副本的同步超时时间 replica.lag.max.messages = 4000 可用副本的同步记录差,==该参数在0.9以后被删除== -
0.9以后:只按照时间来判断
replica.lag.time.max.ms = 10000 可用副本的同步超时时间
-
-
-
-
小结
- Kakfa保证数据安全的机制:副本机制
- AR:所有副本
- ISR:可用副本
- OSR:不可用副本
知识点04:Kafka数据同步概念:HW、LEO
-
目标:了解Kafka副本同步过程及同步中的概念
-
路径
- 什么是HW、LEO?
- Follower副本如何与Leader进行同步的?
-
实施
-
什么是HW、LEO?

- HW:当前这个分区所有副本同步的最低位置 + 1,消费者能消费到的最大位置
- LEO:当前Leader已经写入数据的最新位置 + 1
-
数据写入Leader及同步过程
-
step1:数据写入分区的Leader副本

-
step2:Follower到Leader副本中同步数据

-
-
-
小结
- HW:所有副本都同步的位置,消费者可以消费到的位置
- LEO:leader当前最新的位置
知识点05:Kafka分区副本Leader选举
-
目标:掌握Kafka的分区副本的Leader选举机制,实现Leader的故障选举测试
-
路径
- 一个分区的Leader副本和Follower副本由谁负责选举?
- 如何实现Leader负载均衡分配?
-
实施
-
Leader的选举
- Controler根据所有节点的负载均衡进行选举每个分区的Leader
-
指定Leader负载均衡分配
-
查看
kafka-topics.sh --describe --topic bigdata01 --zookeeper node1:2181,node2:2181,node3:2181 -
重新分配leader
kafka-leader-election.sh --bootstrap-server node1:9092 --topic bigdata01 --partition=0 --election-type preferred
-
-
-
小结
-
Kafka中Controller的选举由ZK辅助实现
-
Kafka中分区副本的选举:由Controller来实现
-
知识点06:消息队列的一次性语义
- 目标:了解消息队列的三种一次性语义
- 路径
- 什么是一次性语义?
- 实施
- at-most-once:至多一次
- 会出现数据丢失的问题
- at-least-once:至少一次
- 会出现数据重复的问题
- exactly-once:有且仅有一次
- 只消费处理成功一次
- 所有消息队列的目标
- at-most-once:至多一次
- 小结
- Kafka从理论上可以实现Exactly Once
- 大多数的消息队列一般不能满足Exactly Once就满足at-least-once
知识点07:Kafka保证生产不丢失
-
目标:掌握Kafka的生产者如何保证生产数据不丢失的机制原理
-
路径
- Kafka如何保证生产者生产的数据不丢失?
-
实施
-
ACK + 重试机制
- 生产者生产数据写入kafka,等待kafka返回ack确认,收到ack,生产者发送下一条
-
选项
- 0:不等待ack,直接发送下一条
- 优点:快
- 缺点:数据易丢失
- 1:生产者将数据写入Kafka,Kafka等待这个分区Leader副本,返回ack,发送下一条
- 优点:性能和安全做了中和的选项
- 缺点:依旧存在一定概率的数据丢失的情况
- all:生产者将数据写入Kafka,Kafka等待这个分区所有副本同步成功,返回ack,发送下一条
- 优点:安全
- 缺点:性能比较差
- 方案:搭配min.insync.replicas来使用
- min.insync.replicas:表示最少同步几个副本就可以返回ack
- 0:不等待ack,直接发送下一条
-
重试机制
retries = 0 发送失败的重试次数
-
-
小结
- Kafka如何保证生产者生产的数据不丢失?
- step1:生产数据时等待Kafka的ack
- step2:返回ack再生产下一条
知识点08:Kafka保证生产不重复
-
目标:掌握Kafka如何保证生产者生产数据不重复的机制原理
-
路径
- Kafka如何保证生产者生产的数据不重复?
- 什么是幂等性机制?
-
实施
-
数据重复的情况
- step1:生产发送一条数据A给kafka
- step2:Kafka存储数据A,返回Ack给生产者
- step3:如果ack丢失,生产者没有收到ack,超时,生产者认为数据丢失没有写入Kafka
- step4:生产者基于重试机制重新发送这条数据A,Kafka写入数据A,返回Ack
- step5:生产者收到ack,发送下一条B
- 问题:A在Kafka中写入两次,产生数据重复的问题
-
Kafka的解决方案
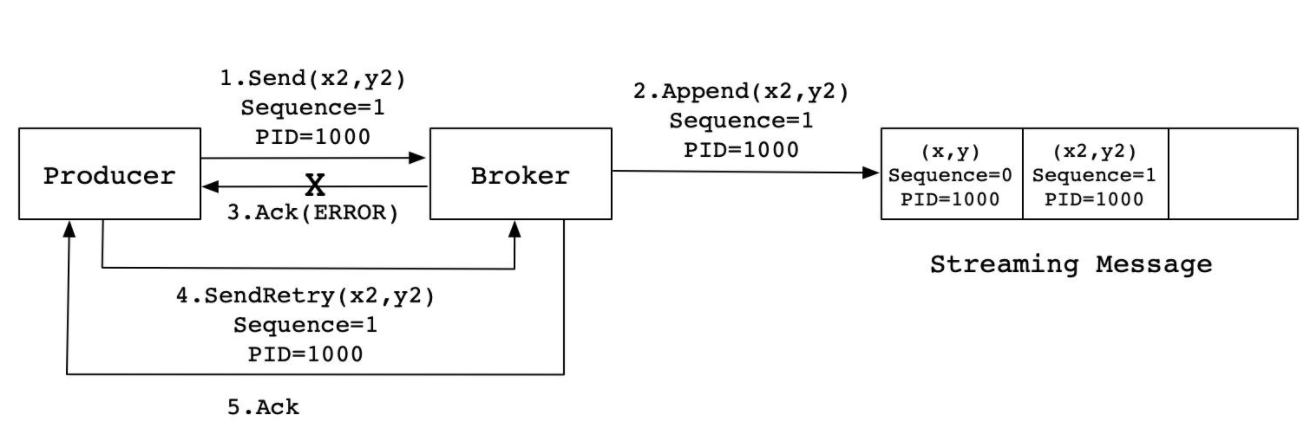
- 实现:在每条数据中增加一个数据id,下一条数据会比上一条数据id多1,Kafka会根据id进行判断是否写入过了
- 如果没有写入:写入kafka
- 如果已经写入:直接返回ack
- 实现:在每条数据中增加一个数据id,下一条数据会比上一条数据id多1,Kafka会根据id进行判断是否写入过了
-
幂等性机制
f(x) = f(f(x))- 一个操作被执行多次,结果是一致的
-
-
小结
- Kafka通过幂等性机制在数据中增加数据id,每条数据的数据id都不一致
- Kafka会判断每次要写入的id是否比上一次的id多1,如果多1,就写入,不多1,就直接返回ack
知识点09:Kafka保证消费一次性语义
-
目标:掌握Kafka如何保证消费者消费数据不丢失不重复
-
路径
- Kafka如何保证消费者消费数据不丢失不重复?
-
实施
- 规则
- 消费者是根据offset来持续消费,只要保证任何场景下消费者都能知道上一次的Offset即可
- 需要:将offset存储在一种可靠外部存储中
- 实现
- step1:第一次消费根据属性进行消费
- step2:消费分区数据,处理分区数据
- step3:处理成功:将处理成功的分区的Offset进行额外的存储
- Kafka:默认存储__consumer_offsets
- 外部:MySQL、Redis、Zookeeper
- step4:如果消费者故障,可以从外部存储读取上一次消费的offset向Kafka进行请求
- 规则
-
小结
-
通过自己手动管理存储Offset来实现
-
消费处理成功
//消费 records = consumer.poll //处理 println //将offset存储在MySQL中 saveToMySQL(partition ,offset){ sql = replace into table value(groupid,topic,part,offset) } -
程序故障,重启
//消费:根据上一次的offset进行消费 offset = readFromMySQL(groupid,topic) records = consumer.poll(offset)
-
-
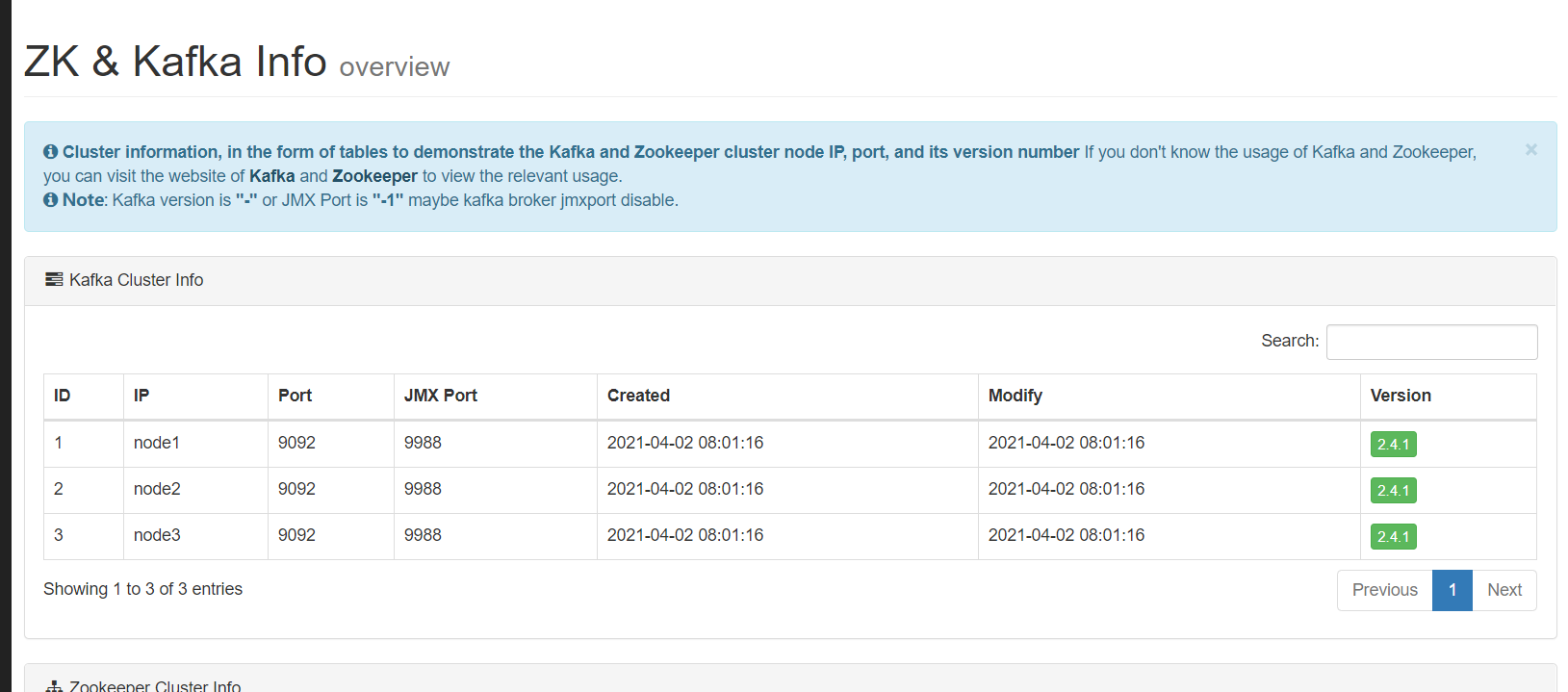
知识点10:Kafka集群常用配置
-
目标:了解Kafka集群、生产者、消费者的常用属性配置
-
路径
- 有哪些常用的集群配置?
- 有哪些常用的生产者配置?
- 有哪些常用的消费者配置?
-
实施
-
集群配置:server.properties
属性 值 含义 broker.id int类型 Kafka服务端的唯一id,用于注册zookeeper,一般一台机器一个 host.name hostname 绑定该broker对应的机器地址 port 端口 Kafka服务端端口:9092 log.dirs 目录 kafka存放数据的路径 zookeeper.connect hostname:2181 zookeeper的地址 zookeeper.session.timeout.ms 6000 zookeeper会话超时时间 zookeeper.connection.timeout.ms 6000 zookeeper客户端连接超时时间 num.partitions 1 分区的个数 default.replication.factor 1 分区的副本数 log.segment.bytes 1073741824 单个log文件的大小,默认1G生成一个 log.index.interval.bytes 4096 log文件每隔多大生成一条index log.roll.hours 168 单个log文件生成的时间规则,默认7天一个log log.cleaner.enable true 开启日志清理 log.cleanup.policy delete,compact 默认为delete,删除过期数据,compact为合并数据 log.retention.minutes 分钟值 segment生成多少分钟后删除 log.retention.hours 小时值 segment生成多少小时后删除【168】,7天 log.retention.ms 毫秒值 segment生成多少毫秒后删除 log.retention.bytes -1 删除文件阈值,如果整个数据文件大小,超过阈值的一个segment大小,将会删除最老的segment,直到小于阈值 log.retention.check.interval.ms 毫秒值【5分钟】 多长时间检查一次是否有数据要标记删除 log.cleaner.delete.retention.ms 毫秒值 segment标记删除后多长时间删除 log.cleaner.backoff.ms 毫秒值 多长时间检查一次是否有数据要删除 log.flush.interval.messages Long.MaxValue 消息的条数达到阈值,将触发flush缓存到磁盘 log.flush.interval.ms Long.MaxValue 隔多长时间将缓存数据写入磁盘 auto.create.topics.enable false 是否允许自动创建topic,不建议开启 delete.topic.enable true 允许删除topic replica.lag.time.max.ms 10000 可用副本的同步超时时间 replica.lag.max.messages 4000 可用副本的同步记录差,该参数在0.9以后被删除 unclean.leader.election.enable true 允许不在ISR中的副本成为leader num.network.threads 3 接受客户端请求的线程数 num.io.threads 8 处理读写硬盘的IO的线程数 background.threads 4 后台处理的线程数,例如清理文件等 -
生产配置:producer.properties
属性 值 含义 bootstrap.servers hostname:9092 KafkaServer端地址 poducer.type sync 同步或者异步发送,0,1,all min.insync.replicas 3 如果为同步,最小成功副本数 buffer.memory 33554432 配置生产者本地发送数据的 缓存大小 compression.type none 配置数据压缩,可配置snappy partitioner.class Partition 指定分区的类 acks 1 指定写入数据的保障方式 request.timeout.ms 10000 等待ack确认的时间,超时发送失败 retries 0 发送失败的重试次数 batch.size 16384 批量发送的大小 metadata.max.age.ms 300000 更新缓存的元数据【topic、分区leader等】 -
消费配置:consumer.properties
属性 值 含义 bootstrap.servers hostname:9092 指定Kafka的server地址 group.id id 消费者组的 名称 consumer.id 自动分配 消费者id auto.offset.reset latest 新的消费者从哪里读取数据latest,earliest auto.commit.enable true 是否自动commit当前的offset auto.commit.interval.ms 1000 自动提交的时间间隔
-
-
小结
- 常用属性了解即可
知识点11:可视化工具Kafka Eagle部署及使用
-
目标:了解Kafka Eagle的功能、实现Kafka Eagle的安装部署、使用Eagle监控Kafka集群
-
路径
- Kafka Eagle是什么?
- 如何安装部署Kafka Eagle?
- Kafka Eagle如何使用?
-
实施
-
Kafka Eagle的功能
- 用于集成Kafka,实现Kafka集群可视化以及监控报表平台
-
Kafka Eagle的部署启动
-
下载解压:以第三台机器为例
cd /export/software/ rz tar -zxvf kafka-eagle-bin-1.4.6.tar.gz -C /export/server/ cd /export/server/kafka-eagle-bin-1.4.6/ tar -zxf kafka-eagle-web-1.4.6-bin.tar.gz -
修改配置
-
准备数据库:存储eagle的元数据,在Mysql中创建一个数据库
create database eagle;.assets/image-20210402101750024.png)
-
修改配置文件:
cd /export/server/kafka-eagle-bin-1.4.6/kafka-eagle-web-1.4.6/ vim conf/system-config.properties#配置zookeeper集群的名称 kafka.eagle.zk.cluster.alias=cluster1 #配置zookeeper集群的地址 cluster1.zk.list=node1:2181,node2:2181,node3:2181 #31行左右配置开启统计指标 kafka.eagle.metrics.charts=true #配置连接MySQL的参数,并注释自带的sqlite数据库 kafka.eagle.driver=com.mysql.jdbc.Driver kafka.eagle.url=jdbc:mysql://node3:3306/eagle kafka.eagle.username=root kafka.eagle.password=123456
-
-
配置环境变量
vim /etc/profile #KE_HOME export KE_HOME=/export/server/kafka-eagle-bin-1.4.6/kafka-eagle-web-1.4.6 export PATH=$PATH:$KE_HOME/bin source /etc/profile -
添加执行权限
cd /export/server/kafka-eagle-bin-1.4.6/kafka-eagle-web-1.4.6 chmod u+x bin/ke.sh -
启动服务
ke.sh start -
登陆
网页:node3:8048/ke 用户名:admin 密码:123456
-
-
Kafka Eagle使用
-
监控Kafka集群
-
监控Zookeeper集群

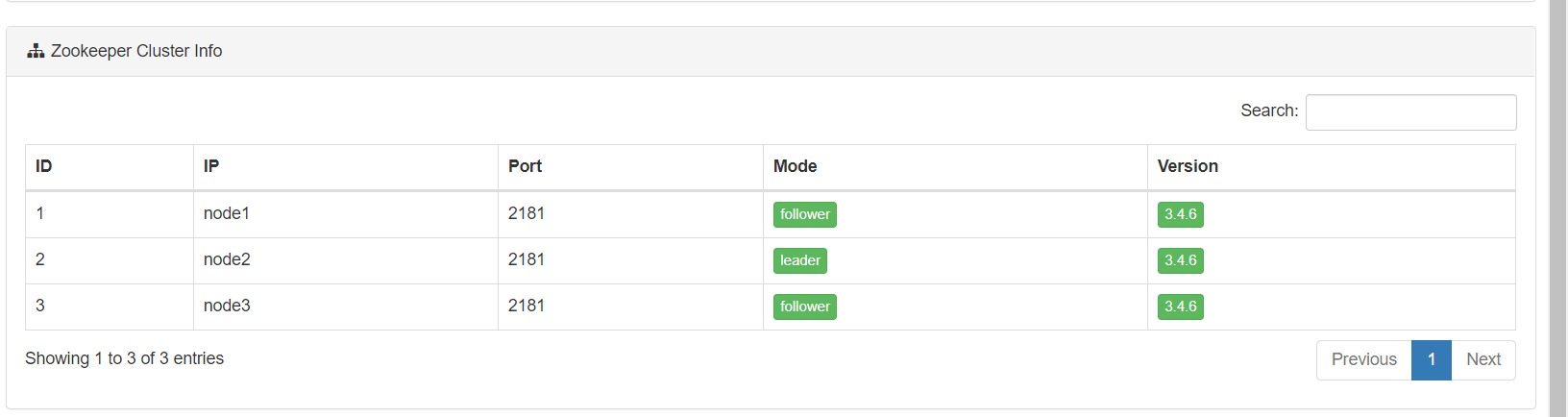
-
监控Topic
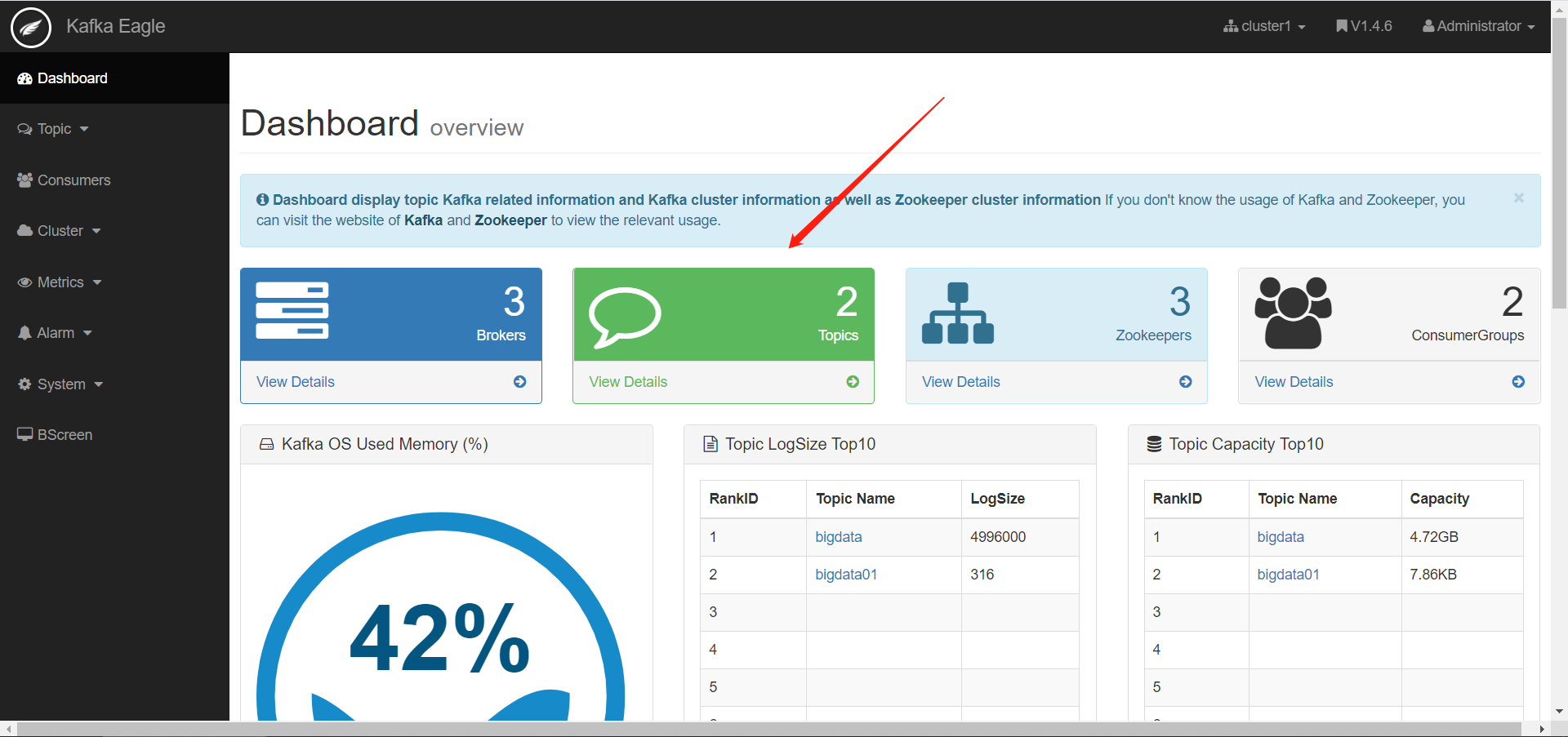
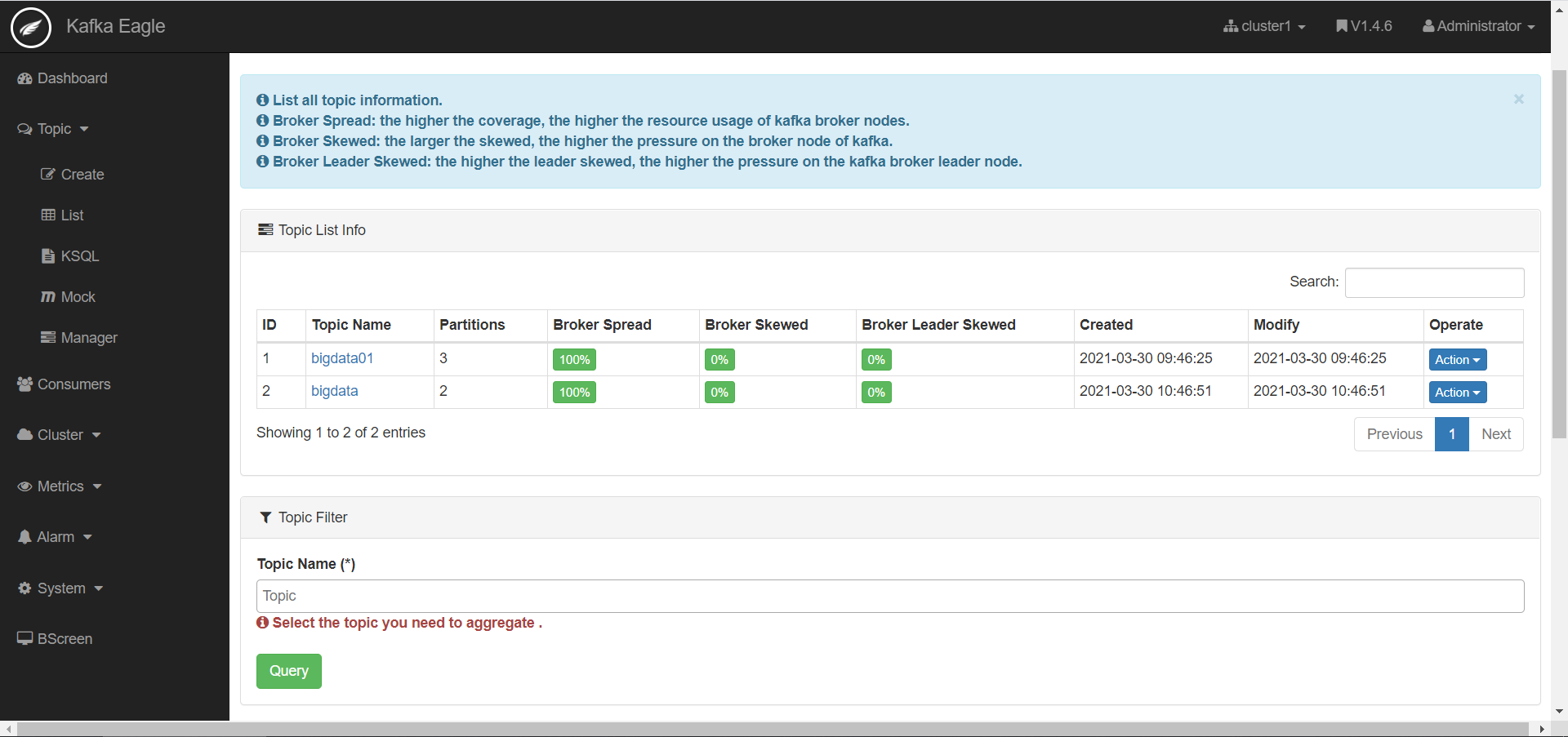
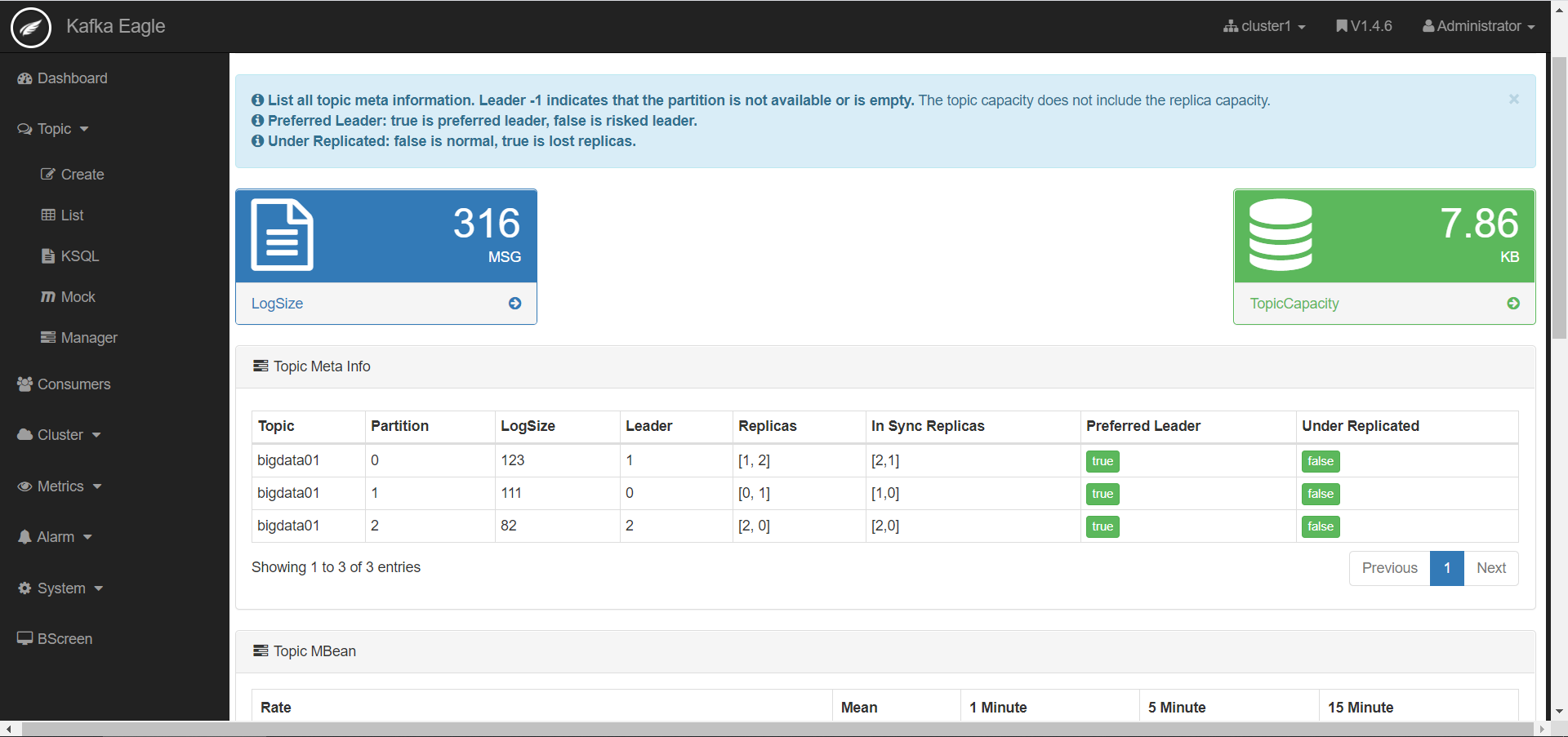
-
查看数据积压
-
现象:消费跟不上生产速度,导致处理的延迟
-
原因
- 消费者组的并发能力不够
- 消费者处理失败
- 网络故障,导致数据传输较慢
-
解决
- 提高消费者组中消费者的并行度
- 分析处理失败的原因
- 找到网络故障的原因
-
查看监控
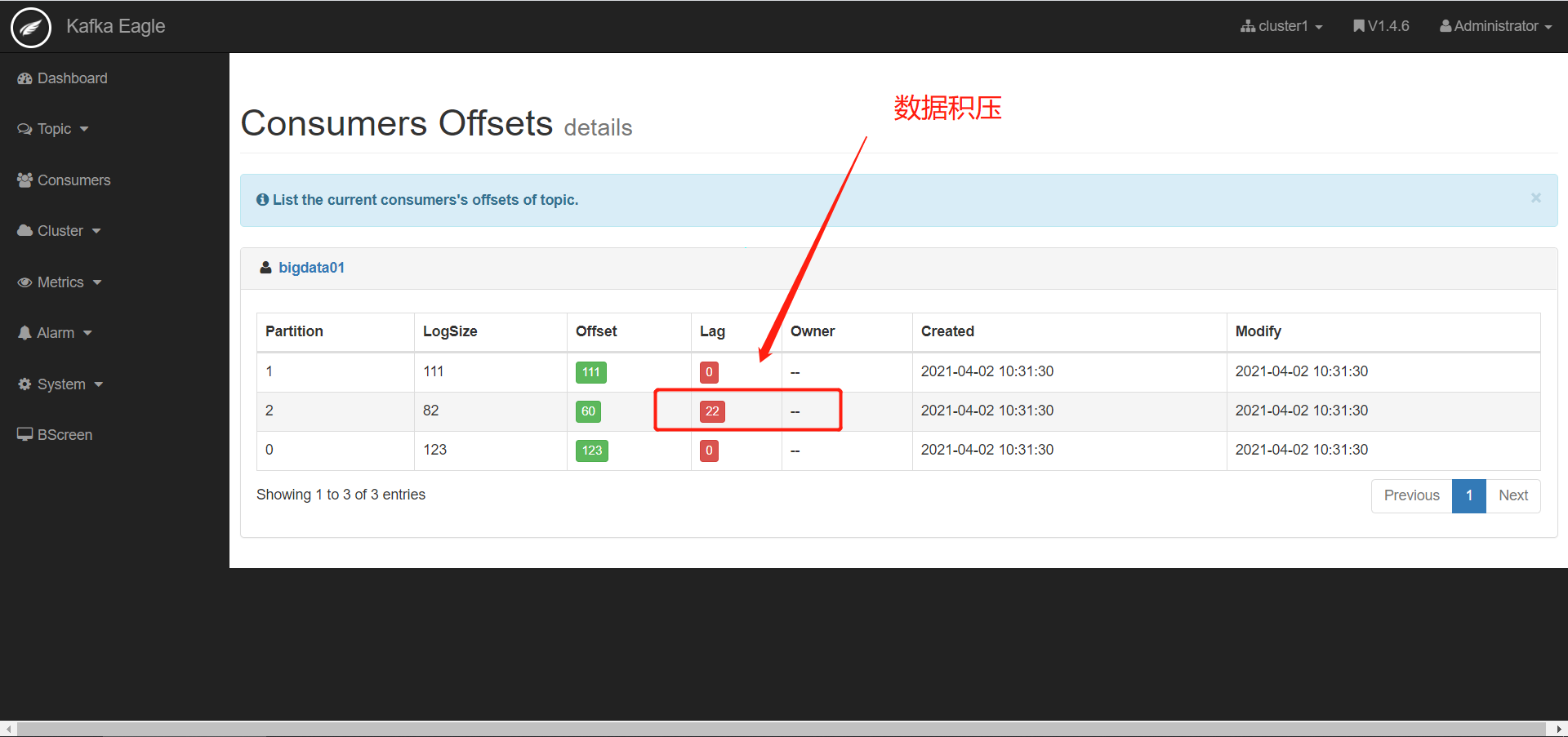
-
-
报表
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-hvDXaak9-1625805420739)(https://gitee.com/the_efforts_paid_offf/picture-blog/raw/master/img/20210709123617.png)]
-
-
-
小结
-
Kafka中最常用的监控工具
-
用于查看集群信息、管理集群、监控集群
-
知识点12:Kafka数据限流
-
目标:了解Kafka的数据限流及使用场景
-
路径
- 什么是数据限流?
- 如何实现数据限流?
-
实施
-
Kafka的实时性比较高,会出现以下现象
- 生产的太快,消费速度跟不上
- 生产的太慢,消费的速度太快了
-
限流:限制生产和消费的速度
-
限制生产
bin/kafka-configs.sh --zookeeper node1.itcast.cn:2181 --alter --add-config 'producer_byte_rate=1048576' --entity-type clients --entity-default- producer_byte_rate=1048576:限制每个批次生产多少字节
-
限制消费
bin/kafka-configs.sh --zookeeper node1.itcast.cn:2181 --alter --add-config ‘consumer_byte_rate=1048576’ --entity-type clients --entity-default
- consumer_byte_rate=1048576:消费每次消费的字节 - 取消限制 ```shell bin/kafka-configs.sh --zookeeper node1.itcast.cn:2181 --alter --delete-config 'producer_byte_rate' --entity-type clients --entity-default bin/kafka-configs.sh --zookeeper node1.itcast.cn:2181 --alter --delete-config 'consumer_byte_rate' --entity-type clients --entity-default -
-
-
小结
- 了解有该功能即可,一般应用场景较少
Kafka核心:Kafka理论
-
Kafka中分布式架构以及概念
-
Kafka读写流程:为什么很快
-
Kafka怎么保证一次性语义
- 生产不丢失不重复
- 消费不丢失不重复
- 自己管理offset
-
Kafka使用
- Topic的管理:分区、副本
- 生产者:数据采集工具或者分布式计算程序
- 消费者:分布式流式计算程序
Scala:提前预习
1、变量、循环、判断
目的:开发Spark或者Flink程序
-
MapReduce:Java
- Wordcount:100行
-
Spark:Scala
-
Wordcount:3行
-
step1:读取
val inputData = sc.textFile("hdfs地址") -
step2:处理
val rsData = inputData .flatMap(line => line.trim.split(" ")) .map(word => (word,1)) .reduceByKey((tmp,item) => item+tmp) val rsData = inputData .flatMap(_.trim.split(" ")) .map((_,1)) .reduceByKey(_+_) -
step3:输出
rsData.saveAsTextFile(HDFS路径)
-
-
Kafka中分布式架构以及概念
-
Kafka读写流程:为什么很快
-
Kafka怎么保证一次性语义
- 生产不丢失不重复
- 消费不丢失不重复
- 自己管理offset
-
Kafka使用
- Topic的管理:分区、副本
- 生产者:数据采集工具或者分布式计算程序
- 消费者:分布式流式计算程序
Scala:提前预习
1、变量、循环、判断
目的:开发Spark或者Flink程序
-
MapReduce:Java
- Wordcount:100行
-
Spark:Scala
-
Wordcount:3行
-
step1:读取
val inputData = sc.textFile("hdfs地址") -
step2:处理
val rsData = inputData .flatMap(line => line.trim.split(" ")) .map(word => (word,1)) .reduceByKey((tmp,item) => item+tmp) val rsData = inputData .flatMap(_.trim.split(" ")) .map((_,1)) .reduceByKey(_+_) -
step3:输出
rsData.saveAsTextFile(HDFS路径)
-
相关文章
- 2022 最新 Kafka 面试题
- 将postgresql中的数据实时同步到kafka中(转载)
- 实时流计算、Spark Streaming、Kafka、Redis、Exactly-once、实时去重
- kafka streams
- Kafka 面试连环炮, 看看你能撑到哪一步?
- Kafka + Canal + MySQL 集群部署
- 一文搞懂Kafka中的listeners和advertised.listeners以及其他通信配置
- 【spring-kafka】@KafkaListener详解与使用
- kafka设计要点之高吞吐量
- Kafka简介
- Kafka 如何读取offset topic内容 (__consumer_offsets)
- Confluent Platform 3.0支持使用Kafka Streams实现实时的数据处理(最新版已经是3.1了,支持kafka0.10了)
- 6、多节点集群环境下Kafka的Confluent Platform的下载安装配置手册
- spring cloud 搭建(kafka入门)