
[Scrapy教学5]掌握Scrapy框架重要的XPath定位元素方法

Scrapy网页爬虫框架除了提供[Scrapy教学4]掌握Scrapy框架重要的CSS定位元素方法文章中所分享的css()方法(方法)来定位网页元素(Element)外,也提供了xpath()定位方法(方法)让开发者使用。
XPath(XML路径语言)是一个使用类似档案路径的语法,来定位XML文件中特定特定的(节点)的语言,因为能够有效的查找节点(节点)的位置,所以也被广泛的使用在Python网页爬虫的元素(Element)定位上。
本文就延续使用[Scrapy教学4]掌握Scrapy框架重要的CSS定位元素方法文章中的INSIDE硬塞的网路趋势观察网站-AI新闻,来带大家来认识如何在Scrapy框架中,使用内建的xpath ()方法(Method)来定位想要爬取的网页内容。重点包含:
Scrapy XPath方法获得单一元素值
Scrapy XPath方法获取多个元素值
Scrapy XPath方法取得子元素值
Scrapy XPath方法获取元素属性值
一,Scrapy XPath方法获得单一元素值
首先,开启INSIDE硬塞的网路趋势观察网站-AI新闻网页,在文章标题的地方按滑鼠快捷键,选择“检查”,可以看到如下图的HTML原始码:
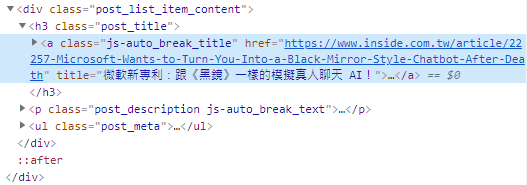
如果想要以XPath语法定位这个标签的位置,语法就像档案路径一样,如下范例:
// a [@ class ='js-auto_break_title']
意思就是是根目录下的标签,并且利用“ [@ class =’’]”来指定它的样式类别(class),如此就能够定位到文章标题的标签。
接下来,开启[Scrapy教学4]掌握Scrapy框架重要的CSS定位元素方法文章所建的的Scrapy网页爬虫专案,在spiders / inside.py的parse()方法(Method)中,将网页回应的结果( response),改为呼叫xpath()方法(Method),并且,贴上刚刚所发现的XPath路径,如下范例:
进口沙皮 刮y的
类InsideSpider (scrapy 。蜘蛛):
名称= “内部”
allowed_domains = [ 'www.inside.com.tw' ]
start_urls = [ 'https://www.inside.com.tw/tag/ai' ]
def parse (self ,response ):
标题=回复。xpath (
“ // a [@ class ='js-auto_break_title'] / text()” )。得到()
打印(标题)
接着,利用以下指令执行inside网页爬虫:
$ scrapy爬进里面
执行结果
微软新专利:跟《黑镜》一样的模拟真人聊天AI!AI !
以上范例的第11行,利用XPath路径定位到所要爬取的标签后,由于要取得其中的网页内容文字,所以在XPath路径的最后需要加上「/ text()」关键字,并且,呼叫get()方法(Method)获得单一元素值。
二,Scrapy XPath方法获得多个元素值
如果想要利用Scrapy xpath()方法(方法)获得多个元素值,使用XPath路径定位到所要爬取的网页元素标签后,调用getall()方法(Method)即可,如下例:
进口沙皮 刮y的
类InsideSpider (scrapy 。蜘蛛):
名称= “内部”
allowed_domains = [ 'www.inside.com.tw' ]
start_urls = [ 'https://www.inside.com.tw/tag/ai' ]
def parse (self ,response ):
标题=回应。xpath (
“ // a [@ class ='js-auto_break_title'] / text()” )。getall ()
打印(标题)
执行结果
[
'微软新专利:跟《黑镜》一样的模拟真人聊天AI!”, '微软新专利:跟《黑镜》一样的模拟真人聊天AI!” ,
'【手臂专栏】一次看懂人工智慧:云端,边缘与终端人工智慧“,'【手臂专栏】一次看懂人工智慧:云端,边缘与终端人工智慧“ ,
'2021台北电玩展以新形态亮相:虚实同步布局', “ 2021台北电玩展以新形态亮相:虚实同步布局” ,
“用科技保护环境!AI可侦测亚马逊雨林生态中非法道路的增减”,“用科技保护环境!AI可侦测亚马逊雨林生态中非法道路的增减” ,
“烘焙王!Google AI未烤先猜你的配方会变什么食物,更创造混种甜点“ breakie”,“ cakie””,“烘焙王!Google AI未烤先猜你的配方会变什么食物,更创造混种甜点“ breakie”,“ cakie”” ,
'她用数据战胜人性,主推近似课程一年后用户翻七倍','她用数据战胜人性,主推近似课程一年后用户翻七倍' ,
“【有线硬塞】你知道银河系的历史,已被重新改写了吗?”, “【有线硬塞】你知道银河系的历史,已被重新改写了吗?” ,
“祖克柏放弃新年愿望!2020过的好吗?盘点脸书满城风雨的一年”,“祖克柏放弃新年愿望!2020过的好吗?盘点脸书满城风雨的一年” ,
......
]]
从执行结果可以看到,getall()方法(方法)会回传一个串列(List),包含所有样式类别(class)为“ js-auto_break_title ”的标签标题文字,接下来,就需要透过回圈来进行读取,如下范例:
进口沙皮 刮y的
类InsideSpider (scrapy 。蜘蛛):
名称= “内部”
allowed_domains = [ 'www.inside.com.tw' ]
start_urls = [ 'https://www.inside.com.tw/tag/ai' ]
def parse (self ,response ):
标题=回应。xpath (
“ // a [@ class ='js-auto_break_title'] / text()” )。getall ()
为标题在标题:
打印(标题)
执行结果
微软新专利:跟《黑镜》一样的模拟真人聊天AI!AI !
【手臂专栏】一次看懂人工智慧:云端,边缘与终端人工智慧【Arm专栏】一次看懂人工智慧:云端,边缘与终端人工智慧
2021台北电玩展以新形态亮相:虚实同步布局2021台北电玩展以新形态亮相:虚实同步布置
用科技保护环境!AI可侦测亚马逊雨林生态中非法道路的增减用科技保护环境!AI可侦测亚马逊雨林生态中非法道路的增减
烘焙王!Google AI未烤先猜你的配方会变什么食物,更创造混种甜点「breakie」,「cakie」烘焙王!Google AI未烤先猜你的配方会变什么食物,更创造混种甜点「breakie 」,「cakie 」
她用数据战胜人性,主推疗法课程一年后用户翻七倍她用数据战胜人性,主推疗法课程一年后用户翻七倍
【有线硬塞】你知道银河系的历史,已被重新改写了吗?【有线硬塞】你知道银河系的历史,已被重新改写了吗?
2020年过的好吗?盘点脸书满城风雨的一年祖克柏放弃新年愿望!2020过的好吗?盘点脸书满城风雨的一年
......
本文使用的get()及getall()方法(方法),和[Scrapy教学4]掌握Scrapy框架重要的CSS定位元素方法文章一样为Scrapy官方的新版使用方式,而旧版的extract_first()及extract( )方法(方法),依据以下的官方文件说明,依然支持,不过还是建议读者可以使用新版的方法(方法),紧密配合以性。

三,Scrapy XPath方法获取子元素值
在开发Python网页爬虫时,有很常的机率会需要透过逐层的方式,往下定位所要爬取的子元素(Element),这时候Scrapy xpath()方法(Method)中,所取代的XPath以标签的HTML原始码为例,如下图:

假设我们想从
进口沙皮 刮y的
类InsideSpider (scrapy 。蜘蛛):
名称= “内部”
allowed_domains = [ 'www.inside.com.tw' ]
start_urls = [ 'https://www.inside.com.tw/tag/ai' ]
def parse (self ,response ):
标题=回应。xpath (
“ // div [@ class ='post_list_item_content'] / h3 [@ class ='post_title'] / a / text()” )。getall ()
为标题在标题:
打印(标题)
执行结果
微软新专利:跟《黑镜》一样的模拟真人聊天AI!AI !
【手臂专栏】一次看懂人工智慧:云端,边缘与终端人工智慧【Arm专栏】一次看懂人工智慧:云端,边缘与终端人工智慧
2021台北电玩展以新形态亮相:虚实同步布局2021台北电玩展以新形态亮相:虚实同步布置
用科技保护环境!AI可侦测亚马逊雨林生态中非法道路的增减用科技保护环境!AI可侦测亚马逊雨林生态中非法道路的增减
烘焙王!Google AI未烤先猜你的配方会变什么食物,更创造混种甜点「breakie」,「cakie」烘焙王!Google AI未烤先猜你的配方会变什么食物,更创造混种甜点「breakie 」,「cakie 」
她用数据战胜人性,主推疗法课程一年后用户翻七倍她用数据战胜人性,主推疗法课程一年后用户翻七倍
【有线硬塞】你知道银河系的历史,已被重新改写了吗?【有线硬塞】你知道银河系的历史,已被重新改写了吗?
2020年过的好吗?盘点脸书满城风雨的一年祖克柏放弃新年愿望!2020过的好吗?盘点脸书满城风雨的一年
......
四,Scrapy XPath方法获取元素属性值
Python网页爬虫除了能够爬取网页上显示的内容外,也可以获取网页元素(元素)的属性值,表示来说,像是图片的src源属性值或超连结的href网址属性值等,这时候,就需要在Scrapy框架的xpath()方法(方法)最后,加上“ @属性名称”,如下范例:
进口沙皮 刮y的
类InsideSpider (scrapy 。蜘蛛):
名称= “内部”
allowed_domains = [ 'www.inside.com.tw' ]
start_urls = [ 'https://www.inside.com.tw/tag/ai' ]
def parse (self ,response ):
标题=回应。xpath (
“ // a [@ class ='js-auto_break_title'] / @ href” )。getall ()
为标题在标题:
打印(标题)
执行结果
https://www.inside.com.tw/article/22257-Microsoft-Wants-to-Turn-You-In-a-Black-Mirror-Style-Chatbot-After-Death://www.inside.com.tw/article/22257-Microsoft-Wants-to-Turn-You-to-a-Black-Mirror-Style-Chatbot-After-Death
https://www.inside.com.tw/article/22234-arm-AI-explained://www.inside.com.tw/article/22234-arm-AI-explained
https://www.inside.com.tw/article/22254-2021-TGS://www.inside.com.tw/article/22254-2021-TGS
https://www.inside.com.tw/article/22208-artificial-intelligence-finds-hidden-roads-threatening-amazon-ecosystems://www.inside.com.tw/article/22208-artificial-intelligence-finds-hidden-roads-threatening-amazon-ecosystems
https://www.inside.com.tw/article/22196-google-ai-concocts-breakie-and-cakie-hybrid-baked-goods://www.inside.com.tw/article/22196-google-ai-concocts-breakie-and-cakie-hybrid-baked-goods
https://www.inside.com.tw/article/22222-sofasoda-growth-in-tech-2021://www.inside.com.tw/article/22222-sofasoda-growth-in-tech-2021
https://www.inside.com.tw/article/22194-The-Milky-Way-Gets-a-New-Origin-Story://www.inside.com.tw/article/22194-The-Milky-Way-Gets-a-New-Origin-Story
https://www.inside.com.tw/article/22057-Mark-Zuckerberg-and-fb-2020://www.inside.com.tw/article/22057-Mark-Zuckerberg-and-fb-2020
......
以上范例,即是爬取所有样式类别(class)为“ js-auto_break_title ”的标签href属性值,也就是文章标题的网址。
五,小结
本文简单示范了Scrapy框架的另一个定位元素方法
取得单一元素值呼叫get()方法(方法)
取得多个元素值呼叫getall()方法(方法)
取得文字内容,加上「/ text()」关键字
取得属性值则加上「@属性名称」关键字
大家可以试着练习利用这里所分享的Scrapy xpath()方法(方法),以及[Scrapy教学4]掌握Scrapy框架重要的CSS定位元素方法文章的css()方法(方法),来爬取想要的网页内容,相信对于想要入门Scrapy框架来开发Python网页爬虫的朋友,能够快速上手。
相关文章
- CSS 布局 ,文档流,定位,中划线,表格属性,line-height居中对齐,z-index,display
- 王爽 汇编语言第三版 第7章 --- 更灵活的定位内存地址的方法(可以理解为 数组形式的内存定位)
- C++ 定位文件 .text 区段地址
- Geolocation 地理定位
- DOA定位算法源码程序
- 产品定位的原则,与同类产品竞争原则、拾遗补缺原则等5个方面
- 大一学生不必为定位着急
- 漫谈ClickHouse在实时分析系统中的定位与作用
- 高精度定位赋能行业创新,Petal Maps Platform 创新地图平台能力
- 快速定位性能瓶颈,检查出所有资源(CPU、内存、磁盘IO等)的利用率(utilization)、饱和度(saturation)和错误(error)度量,即USE方法
- Android使用Google定位服务定位并将经纬度转换为详细地址信息(国省市县街道)
- js实现类似微信网页版在可编辑的div中粘贴内容时过滤剪贴板的内容,光标始终在粘贴内容后面,以及将光标定位到最后的方法
- eclipse svn重定位(relocate)
- 【Location Kit】定位服务设置时间间隔mLocationRequest.setInterval(15 * 1000)不起作用
- 高精度定位赋能行业创新,Petal Maps Platform 创新地图平台能力
- windbg定位WEB性能瓶颈案例一则
- 定位中小企业,微软发布轻型CRM管理应用