
小白学python爬虫:1.找到数据
1.1网页真实的面目:HTML
对于爬虫来说,着手的首要目标就是找到你想要爬取的数据。那么你在网页上看到的数据到底是以怎样的一个形式存在的呢?或者说,web网页它的本质到底是什么?下面我会为大家详细的介绍。
1.1.1 标签
<html>
<head>
<title>我的第一个网页</title>
</head>
<body>
<p>来看看我的第一个网页吧</p>
</body>
</html>
请将以上代码复制到txt中并保存,再将文档后缀‘txt’更改为‘html’,最后双击打开。
没错,你每天所看到的网页的真实面目就是由这些‘代码’所构成的,它的名字叫作HTML(Hyper Text Markup Language:超文本标记语言)。我们要在页面上展示所看到的内容是原原本本写在代码之中的,而这些内容是被形如…的符号“标记”了起来,这些符号被称之为标签。这也是它被称作标记语言的原因。
细心的同学会发现,上面的HTML代码中的标签都是成双成对的出现的。没错,规范的HTML语法是以<标签名>开头,学名‘开始标签’,在标签名前加上反斜杠‘/’(</标签名>)表示这个标签的结束,学名‘结束标签’。并且标签之间可以包含。
其实HTML的性质更像是一份文本文档,里面的标签是给浏览器看的,而被标签标记了的内容才是给我们看的。
那你可能会问:这些标签具体有什么用?我将会在下文展示给你看
1.1.2 每种标签都有不用的功能
还是以上面的HTML代码为例:在‘
来看看我的第一个网页吧
’的下面插入<h1>来看看我的第一个网页吧</h1>
<h2>来看看我的第一个网页吧</h2>
<h3>来看看我的第一个网页吧<h3>
结果如下

-
:h是Heading(标题)的缩写,1表示它是一级标题。
告诉浏览器:你得给我里面的内容整的又大又粗,我可是一级标题。
-
告诉浏览器:我是二级标题,你给我像一级标题那样整,不过要把字体整的比一级标题小点。
-
:p是paragraph(段落)的缩写,它告诉浏览器:我就是我,普普通通的一个段落。
相信通过以上的例子,大家能够对标签的功能有个大概的理解了。下面再给大家普及一下有哪些我们会常见的标签:
我们以后会经常见到的标签包括下面几种:
- :声明这是一份HTML文档,任何标准的HTML文档都应以开头,以结尾。
- :头部,里面用来装一些特定的信息,如文档编码等
-
:就是下图的这个。一般title都是写在head中

- :主体部分都会写在body中
- :division的缩写,用以区分整个HTML文档中各个部分,你可以把他理解成一个容器,不同的内容装在不同的容器当中
- :表示一个可以点击跳转到另外界面的一个链接
- :专门用来放文本的
- :专门用来放图像的
- :表示表格中的一行
- :表示表格的表头
- :表示表格每一行的元素
1.1.3 标签中的属性
如果你将每种标签想象成不同的人,那么属性则对应每个人的比如说性别、年龄、身高等。我们可能有时候需要爬的数据就是标签的属性。
你可以定义标签的属性来获得你想要的功能。比如说的href定义了你点击之后会跳转到哪个网址;常见的属性如下:
- class:每个标签都有,它是用来给标签分类,方便程序员管理HTML代码。比如说你把这一群人(标签)的分类定义为胖子,另外一群人(标签)的分类定义为瘦子。
- id:每个标签都有且唯一,有点像每个人的名字。
- style:每个标签都有,是定义每个标签的模样
- href:a标签才有,定义了要跳转的网址
- src:img标签中代表了图像的位置
标签的属性一般都是写在开始标签当中,形如 属性=“属性的值”
你可以在上文的HTML代码中加上:
<a href="https://www.baidu.com">点击我跳转百度</a>
当你点击它的时候,就会跳转到百度了。
1.1的小结
当你看到了这里,相信你现在也能够看懂一些简单的HTML代码了,对于爬虫来说也够用了。如果你想学的深入一点:点这里去W3C的html教程
你所想要获得的数据当然也会存在于HTML代码之中。那么如果你想要定位你的目标数据,你应该在页面的HTML代码(在下文中我会‘源码’代替)中寻找。下面我来介绍如何在源码中寻找并获得你想要的数据。
1.2如何在源码寻找你要爬的数据?
如果你现在完全没有了解过html,那么下面的部分内容可能对你来说有些难以理解。
ps:我用的是google chrome浏览器,每种浏览器的选项位置有些许差异。
a.右键单击页面,选择‘查看网页源代码’
b.前者看到的源码可能会比较乱,你可以换一种方式(开发者工具):右键单击页面,‘检查’- ‘Elements’。这样你就能看到一个比较‘整齐’的源码。
在这里我建议大家选择第二种方式去查看源码,第二种方式在定位数据上比较‘傻瓜式’
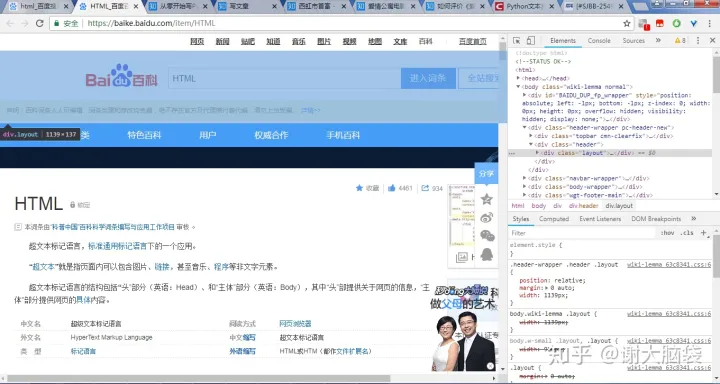
当你将鼠标悬放在某一源码块上,左侧页面的对应部分就会突出显示。利用这样的一个功能,我们可以轻易的用鼠标定位到你想要爬取的数据。
比如我想爬取下图用红色方框标记的那一段落的文字
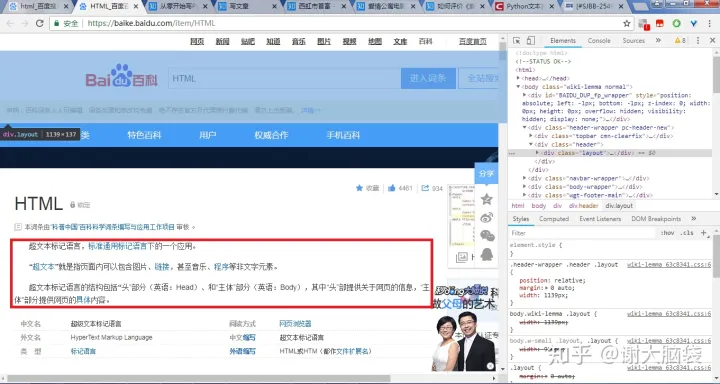
通过在每个代码块上移动鼠标来查看其所对应的页面的位置,我们最终能够找到我们目标数据所在的代码块(我已经用红色方框圈起来了),如下图
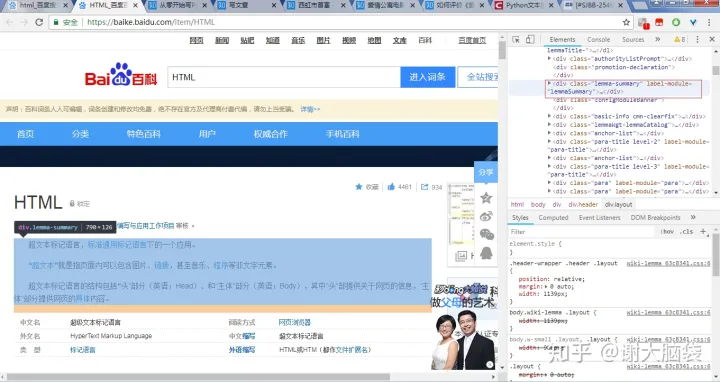
将代码块展开,我们就已经能够看到我们的目标数据了。
1.3利用xpath在源码定位并获得你的目标数据
注意:以下内容需要你有一定的python编程基础
在茫茫码海中,我们如何精确定位并获得我们想要的数据呢。这里我们选择的是xpath,其他的方法有beautifulsoup和正则表达式。(注意,以上这些方法是在python上实现的)。
以上文的例子:
将源码复制到python中
html = '''
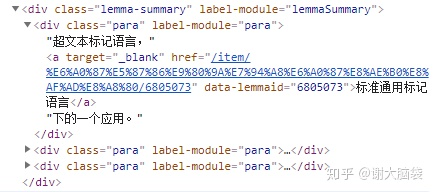
<div class="lemma-summary" label-module="lemmaSummary">
<div class="para" label-module="para">
超文本标记语言,
<a target="_blank"
href="/item/%E6%A0%87%E5%87%86%E9%80%9A%E7%94%A8%E6%A0%87%E8%AE%B0%E8%AF%AD%E8%A8%80/6805073" data-lemmaid="6805073">标准通用标记语言</a>
下的一个应用。
</div>
<div class="para" label-module="para">
<b>“</b>
<a target="_blank" href="/item/%E8%B6%85%E6%96%87%E6%9C%AC/2832422" data-lemmaid="2832422">超文本</a>
<b>”</b>
就是指页面内可以包含图片、
<a target="_blank" href="/item/%E9%93%BE%E6%8E%A5/2665501" data-lemmaid="2665501">链接</a>
,甚至音乐、
<a target="_blank" href="/item/%E7%A8%8B%E5%BA%8F/71525" data-lemmaid="71525">程序</a>等非文字元素。
</div>
<div class="para" label-module="para">超文本标记语言的结构包括
<b>“</b>
头”部分(英语:Head)、和“主体”部分(英语:Body),其中“头”部提供关于网页的信息,“主体”部分提供网页的
<a target="_blank" href="/item/%E5%85%B7%E4%BD%93/4577821" data-lemmaid="4577821">具体</a>内容。
</div>
</div>
'''
在这里你可能有疑问,为什么源码在python中的数据类型是字符的?这一点我会陆续在后面的文章中说明。你现在只需要知道一般在python爬虫中,源码的数据类型一般都是字符型,这也是为什么正则表达式也能够用来定位目标数据的原因。
1.3.1 对于xpath来看源码的结构
在上面的那段源码中,根据每行的缩进,你能够明显的看出源码中的每个标签之间都存在着一定关系(包含关系,同级关系)
class="lemma-summary"的div包含着三个class="para"的div
第一个class="para"的div又包含着一个链接标签…。
这个大家应该很容易看出来。我们可以说每一个标签都是一个‘节点’
class="lemma-summary"的div是class="para"的div的父节点,
反过来则是class="para"的div是class="lemma-summary"的div的子节点。
而那三个class="para"的div,它们之间的关系则是兄弟节点。(想深入学习的可以参考W3C的xpath教程)
xpath就是根据这种结构加上特定的语法,在源码中快速定位的。
1.3.2 xpath语法
例1:如果我想要第一个class="para"的div下的标签a的的文字“标准通用标记语言”,相应的python代码如下:
from lxml import etree
tree = etree.HTML(html)#转成tree对象
tree.xpath("/html/body/div/div[1]/a/text()")
#output
In [149]:tree.xpath("/html/body/div/div[1]/a/text()")
Out[149]: ['标准通用标记语言']
其中的"/html/body/div/div[1]/a/text()"就是xpath啦,下面我们一项一项来说明:
1‘/’代表从根节点(顾名思义就是源码的第一个节点)开始选取
2‘html’则表示第一个节点(标签)的名称,有些同学会好奇,为什么我上面的源码的第一节点明明是
tree = etree.HTML(html)#转成tree对象
他会自动补全你的源码(因为严格意义上来说,html文档必须是以标签开头,在上文我也提到过),不信的话你可以运行以下代码:
etree.tostring(tree).decode('utf-8')
你会看到它将tree对象转成string的时候,不仅多了一个标签,还多了一个标签。
3 ‘[]’表示索引,1的话则表示选择第一个div,其中还可以表示对标签的属性的索引,我会在下文说到。
4 ‘text()’表示获取a的文本内容,如果你想获得a的href属性,将text()’替换成‘@href’即可
例2:如果我想要第一个class=“para"的div下的标签a的href”/item/%E6%A0%87%E5%87%86%E9%80%9A%E7%94%A8%E6%A0%87%E8%AE%B0%E8%AF%AD%E8%A8%80/6805073",相应的python代码如下:
tree.xpath("//div[@class='lemma-summary']/div[1]/a/@href")
#output
In [152]: tree.xpath("//div[@class='lemma-summary']/div[1]/a/@href")
Out[152]: ['/item/%E6%A0%87%E5%87%86%E9%80%9A%E7%94%A8%E6%A0%87%E8%AE%B0%E8%AF%AD%E8%A8%80/6805073']
那么我们又怎么理解"//div[@class=‘lemma-summary’]/div[1]/a/@href"呢?
1 ‘//’表示从任意节点搜索,也就是说你不必从根节点一节一节的往下写了
2 ‘div[@class=‘lemma-summary’]’,其中‘@’表示的是选取属性,整体表示的是索引class="lemma-summary"的div
3‘@href’表示获得href属性的值
整句xpath的意思就是找class="lemma-summary"的div下的第一个div中的a的href属性值
一般在实战中,我们都是从任意节点开始搜索,后面再加上索引,也就是‘[]’,你可以对节点的位置索引,也可以对节点的属性索引。方法都已经在上面的两个例子中说明。要注意的是class的属性值并不是唯一的,他返回的是所有符合你的索引的结果。
1页面分析小结
所以,当我们面对一个爬虫任务的时候,我们的第一反应应该是从源码中寻找你想爬的数据,并确定它的位置。然后在源码中用xpath获得目标数据。关于我们怎么去获得源码,获得源码的原理是什么,我会在下一篇详细的给大家讲解。
好了,理论都讲完了,来个小任务实战一下吧。
python爬虫入门实战1
今天的实战我决定以豆瓣电影的短评为目标
目标网址:微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】。

目标数据:
整个页面的全部二十条短评
根据上文所述的步骤,我们先查看网页源代码:
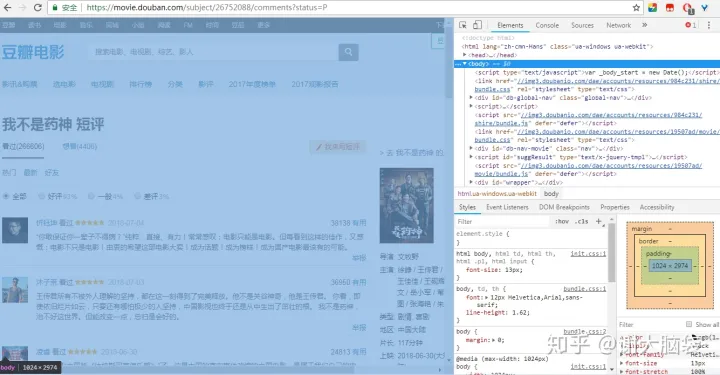
目标数据定位:
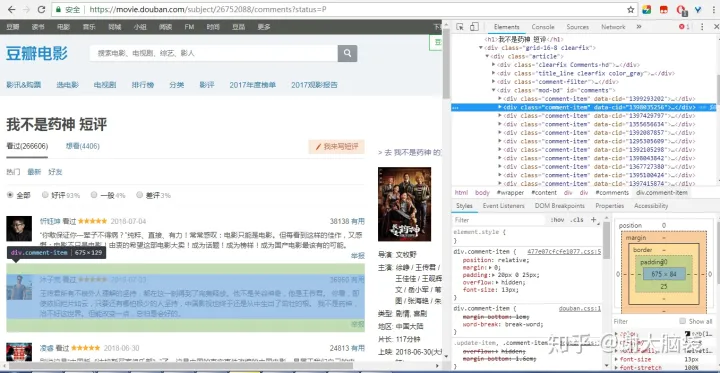
可以看到每一条评论都在class="comment-item"的div中,看到这个,心中要对等下需要写的xpath有个大概的思路了。
接下来我们逐层点开(就是点旁边的那个小三角形)源码,直到我们看到了目标数据为止。
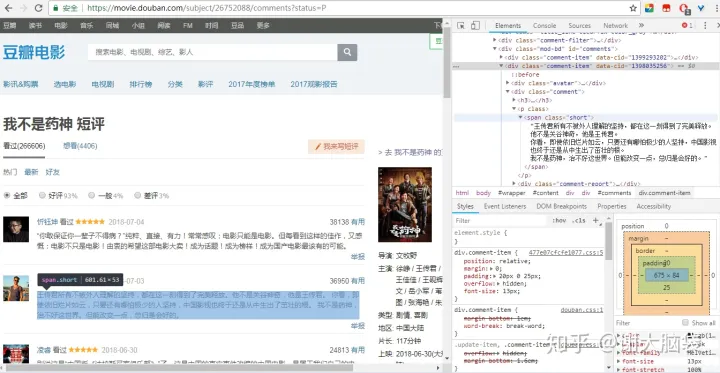
我们可以看到,评论就在class="short"的span标签中。在上文中,我们说过获取标签中的文本要用text()。
所以,完整地xpath应该是
"//div[@class='comment-item']/div[@class='comment']/p/span[@class='short']/text()"
到这里可能有同学会问,你是怎么直到各个节点之间的关系?我的回答是:看缩进!其实这也是用开发者工具查看源码的一个好处,它会自动将节点依照各自的关系进行缩进。
还有的同学会问:为啥不直接写"//span[@class=‘short’/text()"?我在上文中提到过,每个标签的class属性并不是唯一的,在其他地方也有可能有一个class="short"的span。所我们可以看情况多加入一些索引条件,以保证不会混进一些奇奇怪怪的东西。
完整地代码如下
import requests
from lxml import etree
url = "https://movie.douban.com/subject/26752088/comments?status=P"
r = requests.get(url)#获得服务器响应
html_code = r.content.decode(r.encoding)#解码
treeObj = etree.HTML(html_code)
target = treeObj.xpath("//div[@class='comment-item']/div[@class='comment']/p/span[@class='short']/text()")
len(target)
print(target[0])
获得target是一个列表。在上文我说过,xpath会返回所有符合索引的值,所以这个target的长度应该是20。
#output
In [165]: len(target)
Out[165]: 20
In [166]: print(target[0])
“你敢保证你一辈子不得病?”纯粹、直接、有力!常常感叹:电影只能是电影。但每看到这样的佳作,又感慨:电影不只是电影!由衷的希望这部电影大卖!成为话题!成为榜样!成为国产电影最该有的可能。
以上
关于如何获得源码我会在下一篇中为大家详细讲解。
如果大家发现上述知识中有误或者不完善的地方请尽管指出来,谢谢。
相关文章
- Python爬虫之 正则表达式和re模块
- python爬虫知识点总结(二十六)Scrapy+Tushare爬取微博股票数据
- python爬虫知识点总结(二十一)Scrapy中Spiders用法
- python爬虫知识点总结(十二)使用Redis和Flask维护动态代理池
- python爬虫知识点总结(七)PyQuery详解
- python的multiprocessing模块进程创建、资源回收-Process,Pool
- python基于request库,调用聊天机器人接口,request的几种方式汇总
- python的list和数组的区别
- 用Python做兼职接单,简直是爽到离谱
- python中traceback.format_tb()用法详解
- 168 python网络编程 - 服务器动态资源请求
- python asyncio 协程异步【1】详解
- 精通Python网络爬虫:核心技术、框架与项目实战.3.2 爬行策略
- Python类对象的JSON序列化处理
- 速成Python网络爬虫不现实?那是你还没掌握核心!
- Python网络爬虫 - 下载图片
- 在线实习项目|Python爬虫助力疫情数据追踪在线实习项目
- Python数据分析挖掘案例:Python爬虫助力疫情数据追踪
- 《Python Cookbook(第2版)中文版》——1.9 简化字符串的translate方法的使用
- python基础 实战作业 ---Excel基本读写与数据处理
- 分享某Python下的mpi教程 —— A Python Introduction to Parallel Programming with MPI 1.0.2 documentation ( 续 #2 )
- Python模块 实现过渡性模块重载
- python正则表达式2
- 17. python爬虫——基于scrapy框架中的ImagesPipline进行图片数据爬取
- 11. python爬虫——selenium模块综合使用教程
- 4. python爬虫——数据解析技术使用教程和处理中文乱码的方法
- Python 爬虫 之 爬取古代的诗歌,并保存本地(这里以爬取李白的所有诗歌为例)(以备作为AI写诗的训练数据)
- 【Python爬虫】:破解网站字体加密和反反爬虫
- 【Python爬虫】:爬取干货集中营上的全部美女妹子(翻页处理)
- python爬虫学习(一):BeautifulSoup库基础及一般元素提取方法
- pyDes 实现 Python 版的 DES 对称加密/解密--转
- Python开源爬虫项目代码:抓取淘宝、京东、QQ、知网数据--转