大神一看题目就知道用python中的string.split('\'),记得之前处理大量的文件的时候,有时候有几十万的文本文件,经常会读取获取名称,并且保存为名字一样的另外一种格式的文件
其实python中有一句话可以解决这个问题的方法,如下

根据全路径获取文件名称的方法os.path.basename(path)
获取文件所在路径的方法os.path.dirname(path)
转自:http://blog.csdn.net/linux__kernel/article/details/8271326
很多人在Google上不停的找合适自己的压缩,殊不知Py的压缩很不错。可以试试。当然C#,Java的压缩也有第三方的类。Py有很多美名:数学理论强大,数据结构高级等等,关于压缩算法当然用Py更加简单易用,达到目的才是最重要的。
Python压缩ZIP文件:
import zipfile
f = zipfile.ZipFile(target,'w',zipfile.ZIP_DEFLATED)
f.write(filename,file_url)
f.close()
其中target:是压缩后要保存的路径,可以是: 'C:\\temp\\'
ZIP_DEFLATED:表示压缩,还有一个参数:ZIP_STORE:表示只打包,不压缩。这个Linux中的gz跟tar格式有点类似.
write方法如果只有一个参数filename的话,表示把你filename所带的路径全部压缩到zip文件中。如果带两个参数,表示把filename路径中的那个file压缩一下并且存放到file_url中,中间没有增加任何的文件夹。
如果要压缩很多的文件,循环的write就ok了
最后close掉。
Python解压ZIP文件:
f = zipfile.ZipFile("zipfilePath",'r')
for file in f.namelist():
f.extract(file,"temp/")
zipfilePath是压缩文件的路径
循环访问该压缩文件中的文件,并且一个一个file的解压到对应的"temp\"文件夹中
解压当前目录下的zip文件到当前目录,并删除原有的zip文件


import zipfile
import os
file_list = os.listdir(r'.')
for file_name in file_list:
if os.path.splitext(file_name)[1] == '.zip':
print file_name
file_zip = zipfile.ZipFile(file_name, 'r')
for file in file_zip.namelist():
file_zip.extract(file, r'.')
file_zip.close()
os.remove(file_name)
View Code这里讨论使用Python解压例如以下五种压缩文件:
.gz .tar .tgz .zip .rar
简单介绍
gz: 即gzip。通常仅仅能压缩一个文件。与tar结合起来就能够实现先打包,再压缩。
tar: linux系统下的打包工具。仅仅打包。不压缩
tgz:即tar.gz。先用tar打包,然后再用gz压缩得到的文件
zip: 不同于gzip。尽管使用相似的算法,能够打包压缩多个文件。只是分别压缩文件。压缩率低于tar。
rar:打包压缩文件。最初用于DOS,基于window操作系统。
压缩率比zip高,但速度慢。随机訪问的速度也慢。
关于zip于rar之间的各种比較。可见:
http://www.comicer.com/stronghorse/water/software/ziprar.htm
gz
因为gz一般仅仅压缩一个文件,全部常与其它打包工具一起工作。比方能够先用tar打包为XXX.tar,然后在压缩为XXX.tar.gz
解压gz,事实上就是读出当中的单一文件,Python方法例如以下:
import gzip
import os
def un_gz(file_name):
"""ungz zip file"""
f_name = file_name.replace(".gz", "")
#获取文件的名称,去掉
g_file = gzip.GzipFile(file_name)
#创建gzip对象
open(f_name, "w+").write(g_file.read())
#gzip对象用read()打开后,写入open()建立的文件里。
g_file.close()
#关闭gzip对象
tar
XXX.tar.gz解压后得到XXX.tar,还要进一步解压出来。
*注:tgz与tar.gz是同样的格式,老版本号DOS扩展名最多三个字符,故用tgz表示。
因为这里有多个文件,我们先读取全部文件名称。然后解压。例如以下:
import tarfile
def un_tar(file_name):
untar zip file"""
tar = tarfile.open(file_name)
names = tar.getnames()
if os.path.isdir(file_name + "_files"):
pass
else:
os.mkdir(file_name + "_files")
#因为解压后是很多文件,预先建立同名目录
for name in names:
tar.extract(name, file_name + "_files/")
tar.close()
*注:tgz文件与tar文件同样的解压方法。
zip
与tar类似,先读取多个文件名称,然后解压。例如以下:
import zipfile
def un_zip(file_name):
"""unzip zip file"""
zip_file = zipfile.ZipFile(file_name)
if os.path.isdir(file_name + "_files"):
pass
else:
os.mkdir(file_name + "_files")
for names in zip_file.namelist():
zip_file.extract(names,file_name + "_files/")
zip_file.close()
rar
由于rar通常为window下使用,须要额外的Python包rarfile。
可用地址: http://sourceforge.net/projects/rarfile.berlios/files/rarfile-2.4.tar.gz/download
解压到Python安装文件夹的/Scripts/文件夹下,在当前窗体打开命令行,
输入Python setup.py install
安装完毕。
import rarfile
import os
def un_rar(file_name):
"""unrar zip file"""
rar = rarfile.RarFile(file_name)
if os.path.isdir(file_name + "_files"):
pass
else:
os.mkdir(file_name + "_files")
os.chdir(file_name + "_files"):
rar.extractall()
rar.close()
tar打包
在写打包代码的过程中,使用tar.add()添加文件时,会把文件本身的路径也加进去,加上arcname就能依据自己的命名规则将文件添加tar包
打包代码:
-
- import tarfile
- import os
- import time
-
- start = time.time()
- tar=tarfile.open('/path/to/your.tar,'w')
- for root,dir,files in os.walk('/path/to/dir/'):
- for file in files:
- fullpath=os.path.join(root,file)
- tar.add(fullpath,arcname=file)
- tar.close()
- print time.time()-start
在打包的过程中能够设置压缩规则,如想要以gz压缩的格式打包
tar=tarfile.open('/path/to/your.tar.gz','w:gz')
其它格式例如以下表:
tarfile.open的mode有非常多种:
mode action
| 'r' or 'r:*' |
Open for reading with transparent compression (recommended). |
| 'r:' |
Open for reading exclusively without compression. |
| 'r:gz' |
Open for reading with gzip compression. |
| 'r:bz2' |
Open for reading with bzip2 compression. |
| 'a' or 'a:' |
Open for appending with no compression. The file is created if it does not exist. |
| 'w' or 'w:' |
Open for uncompressed writing. |
| 'w:gz' |
Open for gzip compressed writing. |
| 'w:bz2' |
Open for bzip2 compressed writing. |
tar解包
tar解包也能够依据不同压缩格式来解压。
-
- import tarfile
- import time
-
- start = time.time()
- t = tarfile.open("/path/to/your.tar", "r:")
- t.extractall(path = '/path/to/extractdir/')
- t.close()
- print time.time()-start
上面的代码是解压全部的,也能够挨个起做不同的处理,但要假设tar包内文件过多,小心内存哦~
- tar = tarfile.open(filename, 'r:gz')
- for tar_info in tar:
- file = tar.extractfile(tar_info)
- do_something_with(file)
这几天做程序作业的时候需要用python的读取文件功能,在我用readlines()函数做逐行读取的时候遇到了一个小问题,在这里和大家分享一下。
txt文件里的内容是这样的:
代码也没什么问题:
1 with open('001.txt','r') as f:
2 lines = f.readlines()
3 for line in lines:
4 print(line)
但运行出来就。。。:
1 1
2
3 2
4
5 3
6
7 4
8
9 5
每两行之间都出现了奇怪的空行,这是怎么回事呢?
其实是因为文件中每行末尾会有一个隐藏的换行符“\n”,读取之后“\n”会被解析出来形成换行,而print()语句本身就自带换行的效果,两个换行叠加之后就会出现空行。
那么怎样消除这个bug呢?
其实很简单,python有两个自带的函数:.strip()和.rstrip()
- .strip()的意思是消除字符串整体的指定字符
- .rstrip()的意思是消除字符串末尾的指定字符
括号里什么都不写,默认消除空格和换行符
ok,我们再来试试:
1 with open('001.txt','r') as f:
2 lines = f.readlines()
3 for line in lines:
4 print(line.strip())
运行结果:
问题解决!
删除文件或者文件夹
import os
import shutil
name = "test"
if os.path.exists(name): #判断文件或者文件夹是否存在
if not os.listdir(name): #判断文件夹是否为空
os.rmdir(name) #只能删除空文件夹
else:
shutil.rmtree(str(name)) #删除非空文件夹
if os.path.exists(path): # 如果文件存在
# 删除文件
os.remove(path)
问题:UnicodeDecodeError: 'gb2312' codec can't decode bytes in position 2-3: illegal multibyte sequence
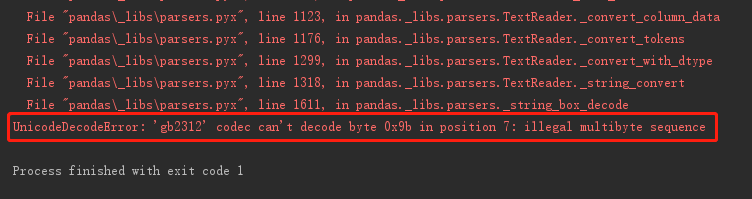
原因:python在做将普通字符串转换为unicode对象时,
例如:u_string = unicode(string , "gb2312"),如果你的字符串string中有诸如某些繁体字,例如"河滘小学"
中的滘,那么gb2312作为简体中文编码是不能进行解析的,必须使用国标扩展码gbk,gbk支持繁体中文和日文假文
解决方法:使用gbk,代替gb2312,例如:u_string = unicode(string , "gbk")