
将OpenStack部署到Hadoop的四种方案
一些基础知识
第一是OpenStack 。作为目前最流行的开源云版本,它包括控制器、计算 (Nova)、存储 (Swift)、消息队列 (RabbitMQ) 和网络 (Quantum) 组件。图 1 提供了这些组件的一个图示(不包含 Quantum 网络组件)。
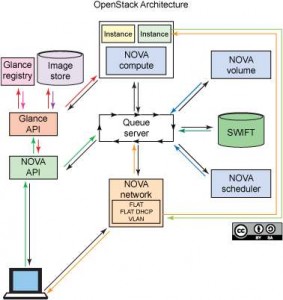
▲图 1. OpenStack 的组件
这些组件共同提供了一个允许动态配给计算和存储资源的环境。从硬件角度看,这些服务可扩展到许多虚拟的和物理的服务器上。例如,大多数组织部署一个物理服务器作为控制器节点,部署另一个物理服务器作为计算节点。许多组织还选择将其存储环境分离到一个专用的物理服务器上,对于 OpenStack 部署而言,这意味着对 Swift 存储环境使用单独的服务器。
第二是大数据。 一般可以理解为三个数据源的数据汇集:传统数据(结构化数据)、感知数据(日志数据和元数据)和社交(社交媒体)数据。大数据通常采用新的技术模式进行存储,比如非关系分布式数据库 NoSQL。共有四种非关系数据库管理此系统 (NRDBMS):基于列、关键值、图表和基于文档。这些 NRDBMS 将源数据聚集在一起,同时用 MapReduce 之类的分析程序对汇总的信息进行分析。
传统的大数据环境包括一个分析程序、一个数据存储、一个可扩展文件系统、一个工作流管理器、一个分布式排序和散列解决方案以及一个数据流编程框架。常用于商业应用程序的数据流编程框架是 Structured Query Language (SQL),对于开源应用程序,通常会使用 SQL 的替代方案,如 Apache Pig for Hadoop。在商用方面,Cloudera 提供了最稳定、最全面的解决方案之一,而 Apache Hadoop 是最流行的开源 Hadoop 版本。
第三是Apache Hadoop 。包含多种组件,包括 Hadoop Distributed File System(即 HDFS,是一种可扩展的文件系统),HBase(数据库/数据存储)、Pig、Hadoop(分析方法)和 MapReduce(分布式排序和散列)。如图 2 所示,Hadoop 任务被分解为几个节点,而 MapReduce 任务则被分解为跟踪器 (tracker)。
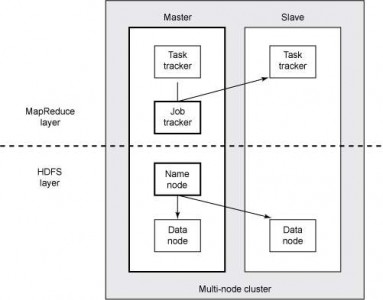
▲图 2. HDFS/MapReduce 层的组成部分
图 3 显示了 MapReduce 如何执行任务,它将获取输入并执行一系列分组、排序和合并操作,然后呈现经过排序和散列的输出。
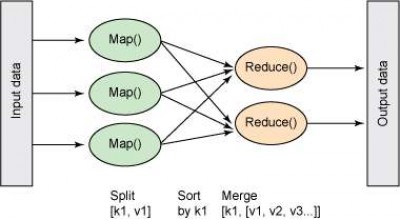
▲图 3. 高级 MapReduce 图
图 4 演示了一个更复杂的 MapReduce 任务及其组成部分。
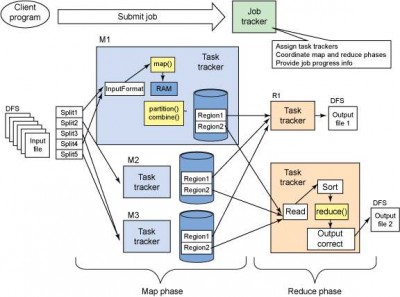
▲图 4. MapReduce 数据流图解
尽管 Hadoop MapReduce 要比传统的分析环境(如 IBM Cognos和 Satori proCube 在线分析处理)更复杂一些,但它的部署仍然具有可扩展能力和高成本效益。
作者:王玉圆
来源:IT168
原文链接:将OpenStack部署到Hadoop的四种方案
保姆级丨Hadoop部署 Hadoop是一个由Apache基金会所开发的分布式系统基础架构。用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
相关文章
- Hadoop NameNode 高可用 (High Availability) 实现解析
- 跟我学丨如何用鲲鹏服务器搭建Hadoop全分布式集群
- 成本与性能兼得 简化Hadoop云部署的高招
- Hadoop创始人寄语2017:五种让开源项目成功的方法
- 《Spark与Hadoop大数据分析》——3.1 启动 Spark 守护进程
- 大数据入门第五天——离线计算之hadoop(下)hadoop-shell与HDFS的JavaAPI入门
- eclipse中集成hadoop插件
- 红帽与Cloudera结成大数据联盟 释放企业级Hadoop潜能
- Docker部署Hadoop集群
- 【Hadoop】Hive HSQ 使用 && 自定义HQL函数
- 生产环境实战spark (8)分布式集群 Hadoop集群WEBUI打不开问题解决,关闭防火墙firewall
- Hadoop 的 TotalOrderPartitioner
- hadoop 部署和调优
- 大数据成长之路------hadoop集群的部署 配置系统网络(静态) 新增集群(三台)
- ❤️hadoop常用命令总结及百万调优❤️
- 【原创 Hadoop&Spark 动手实践 13】Spark综合案例:简易电影推荐系统
- 【Big Data - Hadoop - MapReduce】通过腾讯shuffle部署对shuffle过程进行详解
- 大数据Hadoop(十六):MapReduce计算模型介绍
- hadoop分布式计算,集群
- Hadoop、HBase、Hive、Spark
- hadoop集群+spark集群部署