
NodeJs request爬虫数据乱码解决方法
2023-09-27 14:27:14 时间
1.引入
本人初识小程序云开发与nodejs不久,文中可能存在错误说法和术语,欢迎指正。
最近写微信小程序云函数,需要用nodejs爬取一个网站的信息,但是结果是一个挺意外的乱码,在自己花费挺多时间下解决了,在此记录下来。
2.爬虫举例流程
- 用fiddler抓取想要爬取的请求,得到原生的请求header和参数
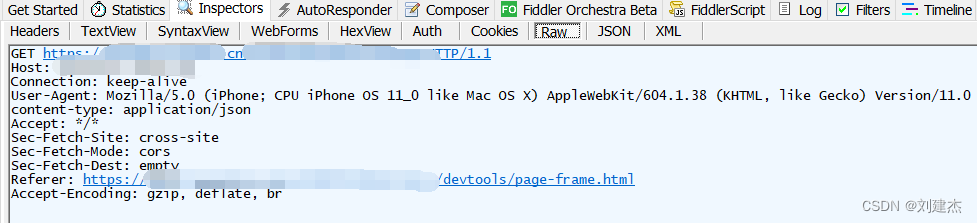
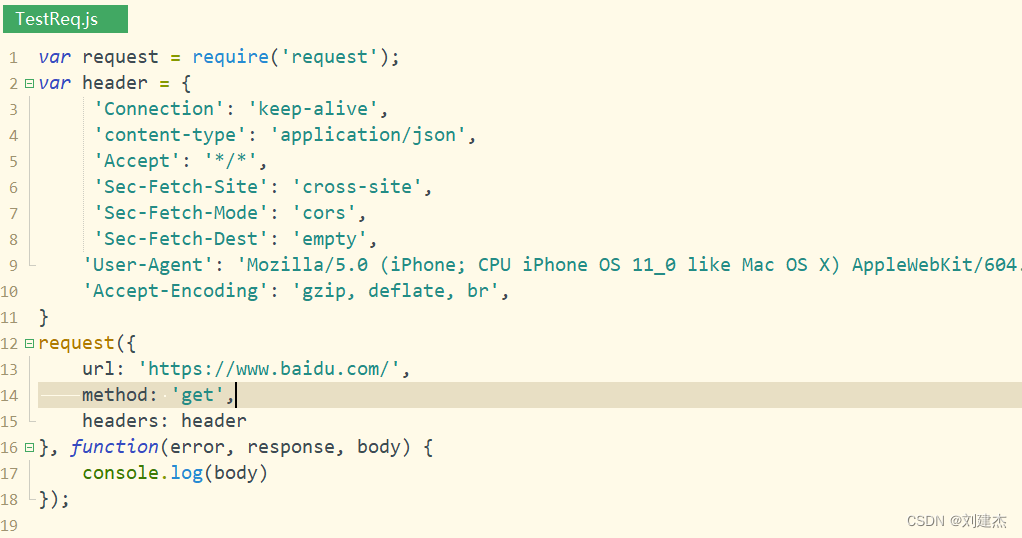
- 用nodejs的request模块写模拟请求的代码,把fiddler得到的header写入其中(用百度网址测试)
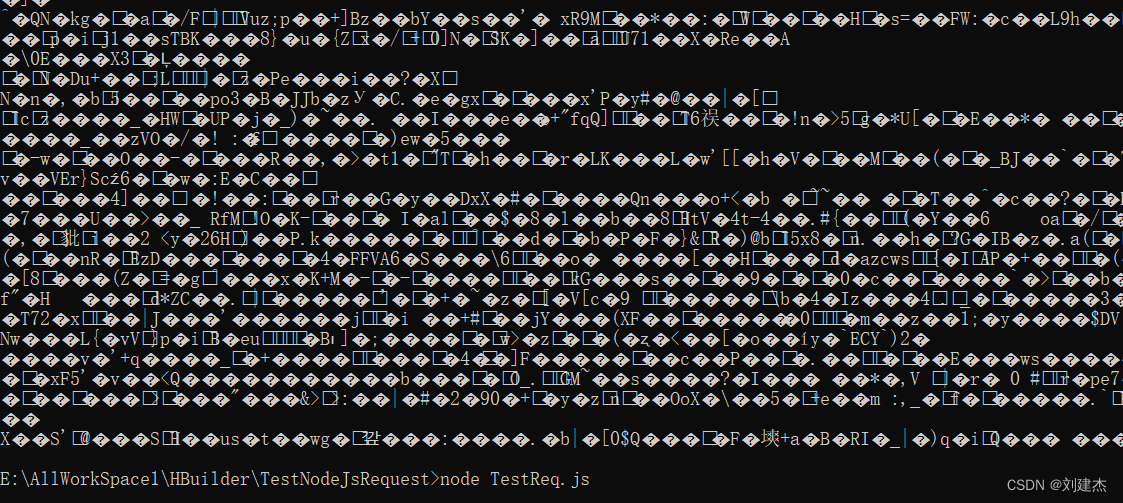
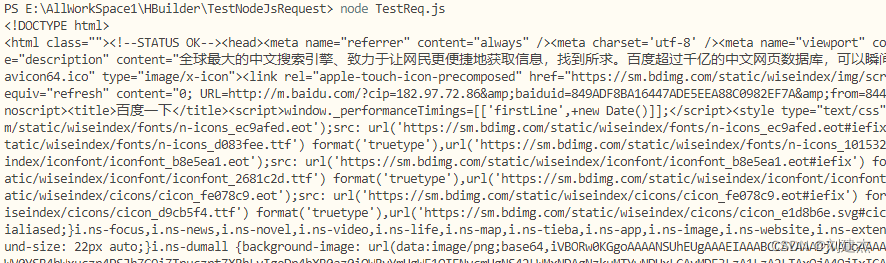
- 运行后,返回的body却是乱码的
用python代码爬取测试
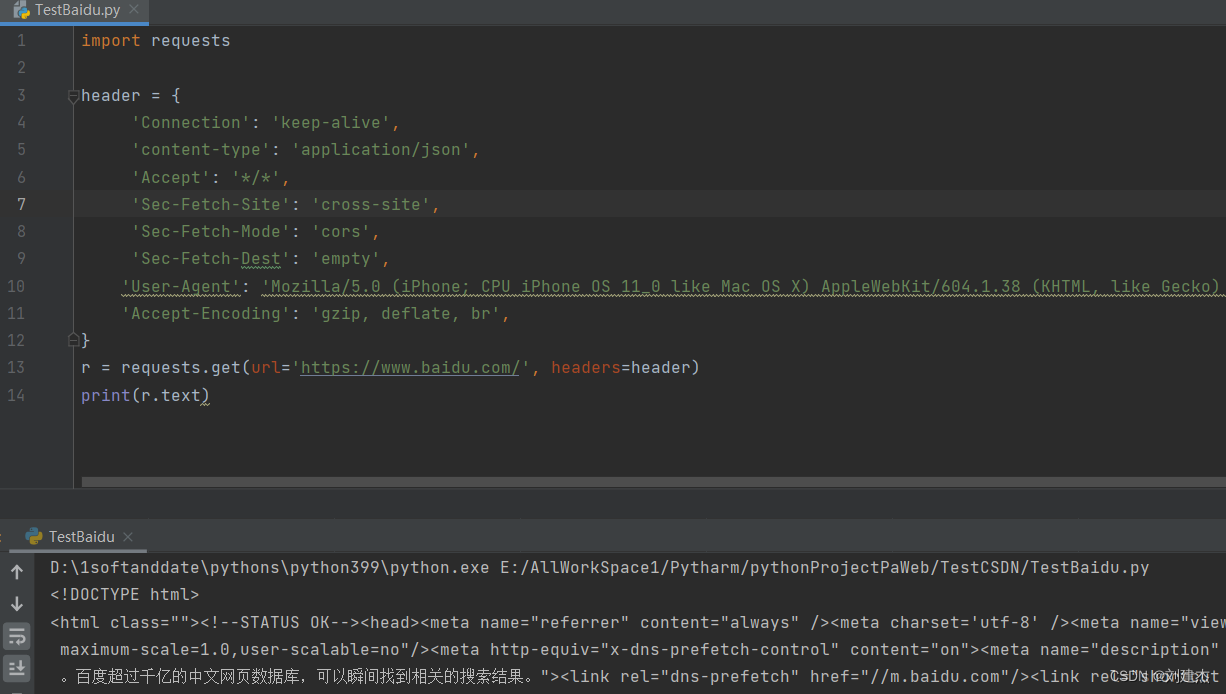
发现相同的代码,python却不会乱码
3.NodeJs乱码错误分析
在经过很多时间测试后,发现了nodejs乱码问题所在。是因为header中设置了

百度给出的解释

于是知道这个是所属浏览器的设置,而nodejs的request如果在header中设置gzip编码类型,就会出现乱码情况,也许是不支持吧。
4.解决方法
在nodejs代码中把Accept-Encoding置为空使用默认所支持的编码,就正常显示了
var request = require('request');
var header = {
'Connection': 'keep-alive',
'content-type': 'application/json',
'Accept': '*/*',
'Sec-Fetch-Site': 'cross-site',
'Sec-Fetch-Mode': 'cors',
'Sec-Fetch-Dest': 'empty',
'User-Agent': 'Mozilla/5.0 (iPhone; CPU iPhone OS 11_0 like Mac OS X) AppleWebKit/604.1.38 (KHTML, like Gecko) Version/11.0 Mobile/15A372 Safari/604.1 wechatdevtools/1.05.2204250 MicroMessenger/8.0.5 Language/zh_CN webview/',
}
request({
url: 'https://www.baidu.com/',
method: 'get',
headers: header
}, function(error, response, body) {
console.log(body)
});