
2017云栖大会·杭州峰会:《在线用户行为分析:基于流式计算的数据处理及应用》之《流数据采集:海量流式视频日志收集》篇
了解更多2017云栖大会·杭州峰会 TechInsight Workshop.
本手册为云栖大会Workshop之《在线用户行为分析:基于流式计算的数据处理及应用》场的《流数据采集:海量流式视频日志收集》篇所需。主要帮助现场学员熟悉并掌握阿里云日志服务Log的操作和使用。
实验涉及大数据产品 阿里云日志服务Log必备条件:
确保已经从云中沙箱中获取了实验所需的阿里云账号和密码。 购买开通日志服务产品。 开通日志服务Log step1:进入阿里云日志服务Log管控台并使用阿里云账号进行登录。

您获得账号需要按照引导进行自助开通日志服务。开通后即可体验如下课程。
step2:进入阿里云日志服务管理控制台。
阿里云日志服务project名称是全局唯一的,建议大家本次实验按照workshop-abc的规则来命名,abc为您获取的云账号后三位数字。如获取云账号为train00620@aliyun-inc.com,那么project名称命名为workshop-620。
step1:点击右上角创建Project进入创建Project页面。 step2:在弹出框中填写需要配置的Project参数。
step2:在弹出框中填写需要配置的Project参数。
Project名称:按照workshop-abc的规则来命名,如workshop-620,620为您获取到云账号后三位数字。 所属区域:华东2,即上海。 step3:点击确认之后,弹出如下对话框,并点击创建按钮,进入创建LogStore页面。
 创建日志服务Logstore
创建日志服务Logstore
本案例场景需要您一共创建三个Logstore,分别说明如下:
vedio-server-log:用于收集服务端流媒体的编码解码等日志。 client-operation-log:用于收集用户在浏览器、客户端的操作日志。 web-tracking-log:用于演示WebTracking采集播放器操作日志。step6:将配置应用到机器组:

上述步骤做完之后便完成了vedio-server-log日志的采集配置。
创建Logstore:client-operation-log大体操作步骤同上,创建Logstore:vedio-server-log,差异点在指定采集模式上。
step1:首先点击左侧菜单中的日志库,继而点击右上角创建,进入创建Logstore页面。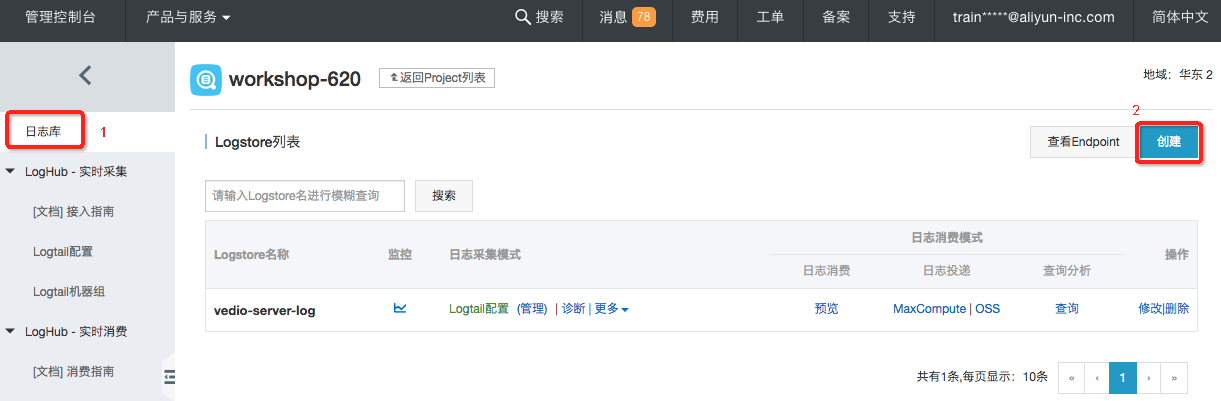

Logstore名称:client-operation-log,其他选项均为默认。
step3:继而在弹出中选择创建Logtail配置。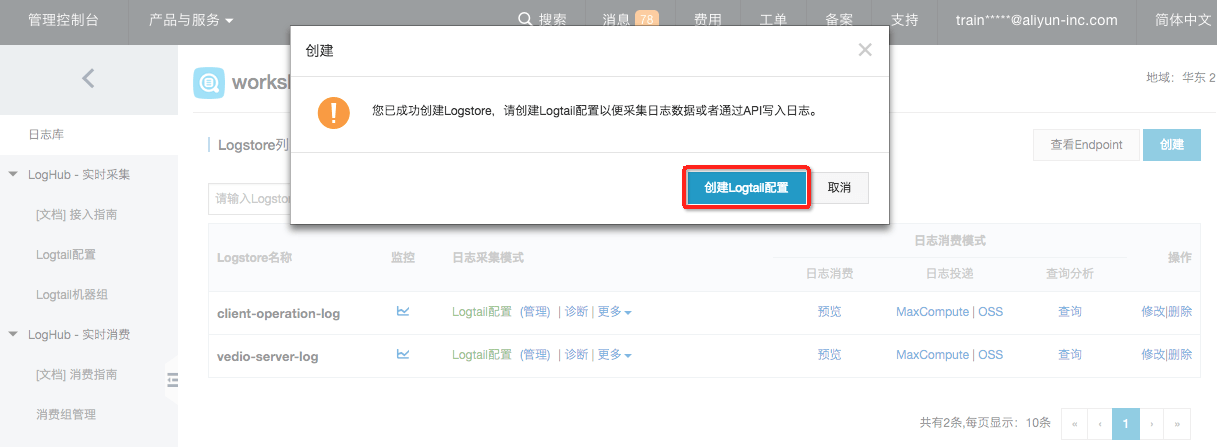
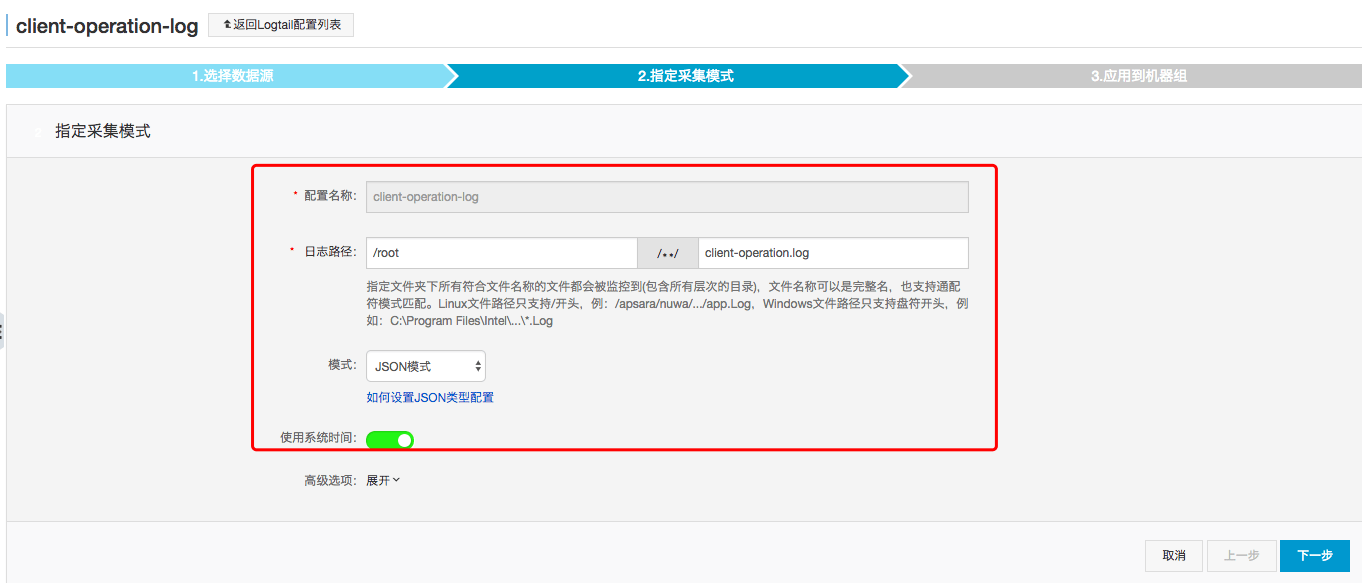
配置项说明如下:
配置名称:client-operation-log 日志路径:/root,具体日志文件名为:client-operation.log 模式:选择JSON模式。step3:点击确定按钮后,弹出创建Logtail框,直接点击取消即可。

注意创建该Logstore时,需要打开WebTracking,另外,这个Logstore不需要创建采集配置,到这里web-tracking-log就创建好了。
所有已经配置的Logstore就已经完成,如下图所示:
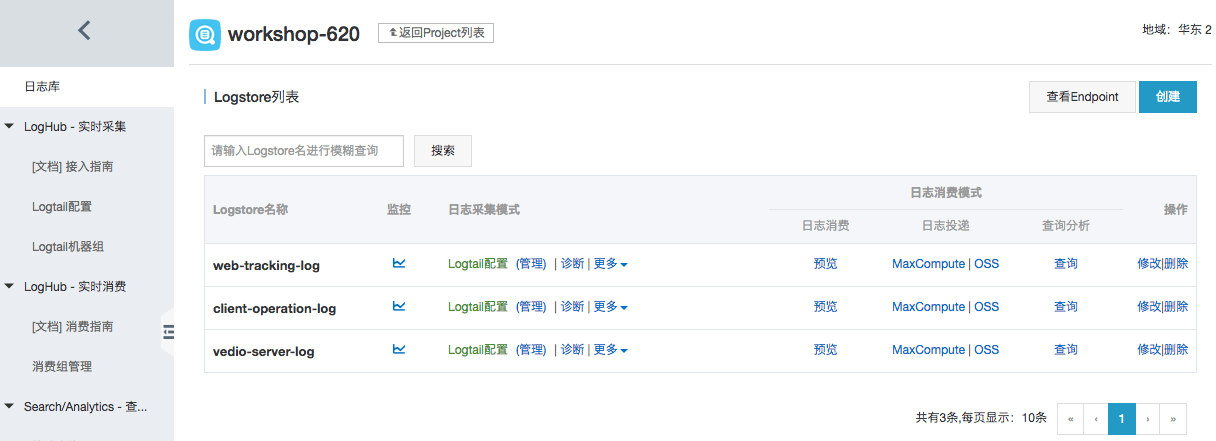
为了更真实的模拟直播视频的日志产生、采集再到处理的整个链路,我们为每个学员都提供了一台专属ECS,便于体验全链路workshop流程。
step1:登陆ECS控制台,找到在Logtail配置过程中的机器组实例,点击远程连接,登陆到ECS VM上。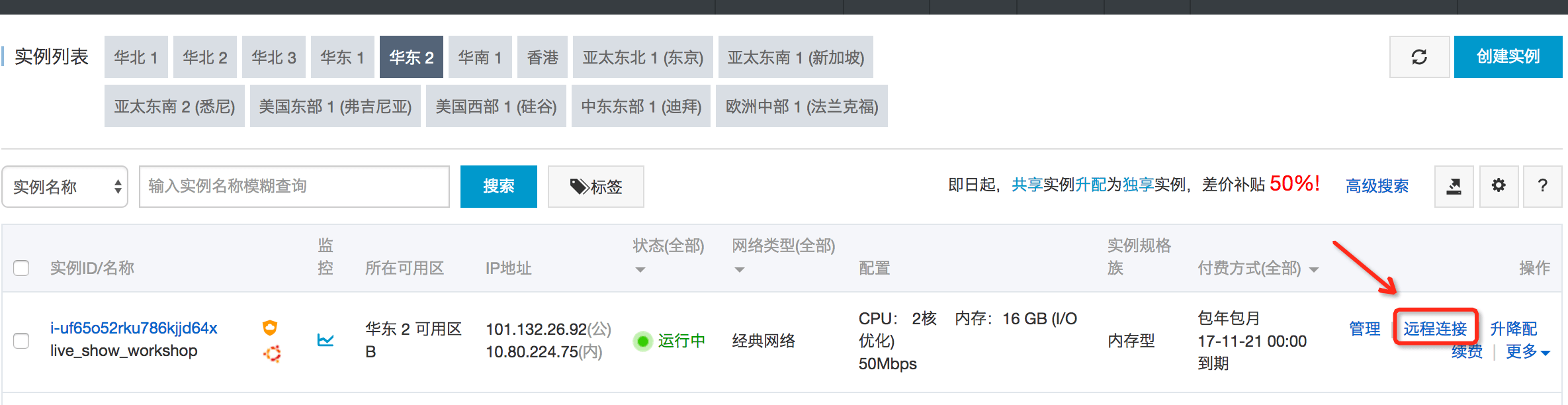
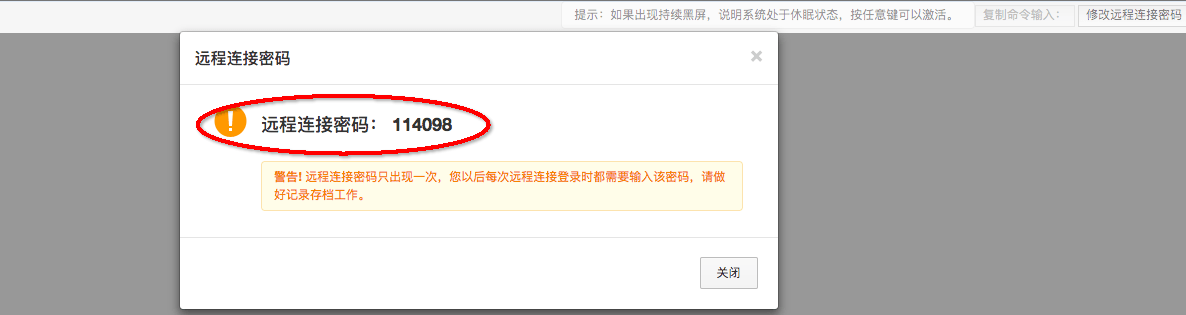
 step4:从云中沙箱获取登录账号和密码,并登陆成功之后,进入到ECS VM的命令窗口:
step4:从云中沙箱获取登录账号和密码,并登陆成功之后,进入到ECS VM的命令窗口:


sh start.sh workshop-hz [your log project name]

其中第二个参数(your log project name)填写之前创建好的日志服务的Project名称。
举个例子,如果之前创建的日志服务的Project名称是workshop-620,执行的命令如下:
sh start.sh workshop-hz workshop-620
执行成功后,在该台ECS上,一个播放网站以及模拟产生播放日志的程序就启动好了。这里请务必保证输入的日志服务的Project名称正确无误。
step5:在当前目录下执行ls -la命令,确认环境是否被正确搭建。
在当前目录(/root/),执行ls -la命令,如果看到上图红框中两个日志文件已经产生,那就表示环境已经搭建好了,如果没有搭建好,请在WorkShop现场举手示意。
经过创建Logstore、配置Logtail以及启动ECS上相关程序后,整个视频日志流采集的流程就全部完成了。接下来就是验证日志数据是否成功收集到日志服务中了。
step1:回到日志服务控制台,点击之前创建的Project,进入Project管理页面。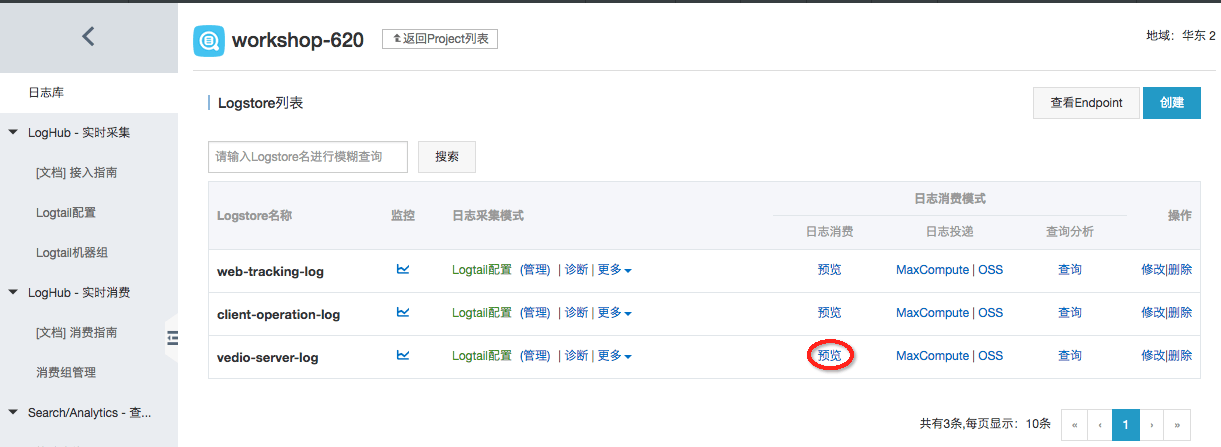

通过上述步骤可以验证,vedio-server-log和client-operation-log日志库中是否已经有采集到日志进来。
step3:验证web-tracking-log播放器操作日志。回到ECS控制台,找到ECS实例的公网IP,比如我的ECS的公网IP是:101.132.26.92 step4:浏览器中访问该公网网址:http://101.132.26.92,打开播放页面如下。
step4:浏览器中访问该公网网址:http://101.132.26.92,打开播放页面如下。
可以反复多次点击播放、暂定按钮。
step5:点击预览进入日志预览页面。

上图可以看到刚才在播放器的操作行为都被记录到web-tracking-log这个Logstore里面了。至此,一个完整的日志采集流程便完成了。
Elasticsearch生态&技术峰会 | 基于流式计算平台搭建实时分析 开源最大的特征就是开放性,云生态则让开源技术更具开放性与创造性,Elastic 与阿里云的合作正是开源与云生态共生共荣的典范。值此合作三周年之际,我们邀请业界资深人士相聚云端,共话云上Elasticsearch生态与技术的未来。
Hologres+Flink流批一体首次落地4982亿背后的营销分析大屏 本篇将重点介绍Hologres在阿里巴巴淘宝营销活动分析场景的最佳实践,揭秘Flink+Hologres流批一体首次落地阿里双11营销分析大屏背后的技术考验。
腾讯看点基于 Flink 的实时数仓及多维实时数据分析实践 当业务发展到一定规模,实时数据仓库是一个必要的基础服务。从数据驱动方面考虑,多维实时数据分析系统的重要性也不言而喻。但是当数据量巨大的情况下,拿腾讯看点来说,一天上报的数据量达到万亿级的规模,要实现极低延迟的实时计算和亚秒级的多维实时查询是有技术挑战的。
基于 Flink 的超大规模在线实时反欺诈系统的建设与实践 如何更快速地预防或甄别可能的欺诈行为?如何从超大规模、高并发、多维度的数据中实现在线实时反欺诈?这些都是金融科技公司当下面临的主要难题。针对这一问题,玖富集团打造基于 Flink 的超大规模在线实时反欺诈系统,快速处理海量数据并实现良好的用户体验。
阿里云MVP Meetup 《云数据·大计算:海量日志数据分析与应用》之《数据应用:数据服务》篇 本文主要阐述在使用DataWorks(数据工场)的过程中如何使用数据服务模块,快速将已生成的数据给用起来。此功能可用于快速将数仓中的结果表生成API,通过API给下游应用使用,或者通过API服务完成数据共享等。
时序数据在滴滴实时数据开发平台中的处理和应用 在阿里云栖开发者沙龙时序数据库技术专场上,滴滴高级研发工程师张婷婷为大家介绍了滴滴实时数据开发平台的架构变迁,为大家揭示了滴滴如何应用Druid、Spark Streaming以及Flink等主流技术来优化时序数据的加工、存储与查询。
阿里云MVP Meetup 《云数据·大计算:海量日志数据分析与应用》之《数据质量监控》篇 本手册为阿里云MVP Meetup Workshop《云计算·大数据:海量日志数据分析与应用》的《数据质量监控》篇而准备。主要阐述在使用大数据开发套件过程中如何将已经采集至MaxCompute上的日志数据质量进行监控,学员可以根据本实验手册,去学习如何创建表的监控规则,如何去订阅表等。
【转载】阿里云MVP Meetup:《云数据·大计算:海量日志数据分析与应用》之《数据加工:用户画像》篇 本手册为阿里云MVP《云计算·大数据:海量日志数据分析与应用》的《数据加工:用户画像》篇而准备。主要阐述在使用大数据开发套件过程中如何将已经采集至MaxCompute上的日志数据进行加工并进行用户画像,学员可以根据本实验手册,去学习如何创建SQL任务、如何处理原始日志数据。
【转载】阿里云MVP Meetup 《云数据·大计算:海量日志数据分析与应用》之《数据采集:日志数据上传》篇 本手册为阿里云MVP Meetup Workshop《云计算·大数据:海量日志数据分析与应用》的《数据采集:日志数据上传》篇而准备。主要为保障各位学员在workshop当天能够顺畅进行动手实操,那么本节为学员掌握阿里云数据采集的操作和使用。
MaxCompute(原ODPS)是一项面向分析的大数据计算服务,它以Serverless架构提供快速、全托管的在线数据仓库服务,消除传统数据平台在资源扩展性和弹性方面的限制,最小化用户运维投入,使您经济并高效的分析处理海量数据。
祎休 阿里云MaxCompute产品经理,帮助每一个想使用大数据计算服务的同学轻松上云。
相关文章
- 国产相变存储器开启产业化应用
- “云计算与云存储核心架构与应用”论坛即将举办
- 向高端应用进军 杰和推高计算四路服务器
- 云计算与大数据下的革新 行业应用广泛
- Http请求中Content-Type讲解以及在Spring MVC中的应用
- 大型互联网应用系统的演化过程
- 10分钟10行代码开发APP(delphi 应用案例)
- 阿里云MVP Meetup:《云数据·大计算:海量日志数据分析与应用》之《数据分析展现:可视化报表及嵌入应用》篇
- iOS 10 不提示「是否允许应用访问数据」,导致应用无法使用的解决方案
- MIT线性代数1806(20) 行列式应用:逆矩阵 解X 计算面积
- 高性能计算在电网技术中的应用
- 浅析云计算的七种应用类型
- 电子商务的云计算应用是一片蓝海
- 云计算推动超大规模数据中心发展与应用
- 中国云计算应用进入集中爆发期三大趋势
- Shopify构建分布式可扩展应用的最佳实践
- DockOne微信分享(八十):云计算应用技术发展与企业异构资源池统一管理案例分析