
使用jenkins pipeline,并发selenium测试 --- 你值得了解
一、契机
相信很多使用selenium进行UI测试,再对接jenkins时,都是简单的在jenkins上将命令输入就完事了。
但是,相信你一定会遇到以下问题:
1、你需要同时跑不同文件或不同类的用例,怎么处理?用selenium grid,但我仅仅是功能,不想去区分浏览器,并且代码中我也不想写grid?
2、在jenkins中并发,怎么将报告合并成一份?
3、用测试框架的并发插件,比如nose processes, pytest的xdist,都是在一台机器上,执行selenium 同时打开多个浏览器,你确保机器能受得了?
二、思路
带着以上几个问题,网上一直没有好的解决方法,普遍使用的是selenium grid,但相信很多人对grid都不喜欢
最近在看jenkins中的pipeline模式,发现其中有一个很好用的功能:parallel 并发,那就来用parallel来解决我们以上的问题
三、解决
jenkins的pipeline就不多介绍,看官网https://jenkins.io/doc/book/pipeline/就行,以后看时间会写写这方面的文章
1)先看看用Declarative方法写的并发parallel


pipeline { agent none stages { stage('Run Tests') { parallel { stage('Run_test1') { agent { label "10.3.208.151" } steps { script{ sh "sleep 20" } } } //----------------------------------------------------------- stage('Run_test2') { agent { label "10.3.208.151" } steps { script{ sh "sleep 10" } } } //----------------------------------------------------------- //---------------------------------------------------------- } } } }
这么简单的一个并发脚本,看看执行时间,总的构建时长为23秒
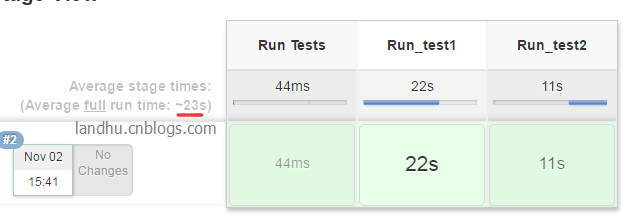
那有了这个基础后,我们将我们的在jenkins上执行selenium脚本全改成pipeline方式,按类或者按文件执行,这里就由你自己控制了。
2)问题一解决了,我们看看问题二,将报告合并
相信很多测试者生成的报告有很多种,有xml格式的,有html格式的,有用allure生成的。这里我们介绍xml和allure格式的,因为html格式的还要自己写合并程序,太麻烦
1, xml方式的,在jenkins上会直接生成TestReport,所以这个很好处理,只需要在pipeline中的每个stage中用post将 xml发布,如下
post { always { junit 'acl.xml' } }
2, allure方式的,这个我们了解下allure原理,allure是将本地的生成的xml文件最后用allure命令生成报告的,所以我们的难点是怎么拿到在不同机器上的文件,然后再放在一台机器上,最后生成报告。
还好,pipeline有一个stash的方式,是在构建后将文件存在master上,给后续的job使用,后续的job再用unstash拿到
所以我们可以在每个stage中这么写
stash includes: 'allure-results\\*', name: 'xxxxx'
将报告存起来,名字叫xxxx
然后我们在parallel并发的stage外再起一个stage,拿到文件,最后生成报告,如下
stage('Report') { agent { label "master" } steps { unstash 'xxxxxx' unstash 'xxxxxx2' } post { always { allure includeProperties: false, jdk: '', results: [[path: 'allure-results']] } } }
完美解决
3) 任务的并发限制
如果你想控制你的并发数量,可以有两种方式实现
1,用节点的executors来限制
2,下载jenkins插件 Throttle Concurrent Plugin
好了,基本解决方案已实现,但实际落地,还需要学习很多。比如jenkins中pipeline的各种使用方法,过程中的各种坑。有问题大家可以留言。
相关文章
- 在使用java -jar命令启动jenkins时,如何指定http端口号
- 【自动化测试】如何在jenkins中搭建allure
- 一文2000字手把手教你Jenkins整合Jmeter实现自动化接口测试
- Jenkins持续集成项目搭建与实践—基于Python Selenium自动化测试
- Jmeter+jenkins接口性能测试平台实践整理
- jenkins学习笔记第十一篇pipeline发送邮件
- Jenkins邮件通知
- Jenkins构建Maven项目
- jenkins接通gitee的webhook做自动部署 vue、react、java、springBoot
- Jenkins持续集成实战之Jenkins构建Python项目提示:'python' 不是内部或外部命令,也不是可运行的程序。
- Jenkins持续集成实战之配置QQ邮箱自动发送RobotFramework测试结果及构建结果通知
- 浅析持续集成/持续部署(CI/CD)及如何使用 jenkins 自动部署
- Jenkins之发送html附件邮件配置
- jenkins 集成产品 产品: jira 禅道 测试 :sonaqube 开发:gitllab
- jenkins和gitlab版本
- RobotFramework与Jenkins集成发送邮件
- jmeter+ant+jenkins的自动化接口测试
- centos+Jenkins+maven+gradle+分布式scp+无密码登录
- Jenkins插件及 测试源码
- jenkins+php+svn快速部署测试环境开发环境快速部署