
使用Python,Open3D对点云散点投影到面上并可视化,使用3种方法计算面的法向量及与平均法向量的夹角
使用Python,Open3D对点云散点投影到面上并可视化,使用3种方法计算面的法向量及与平均法向量的夹角
写这篇博客源于博友的提问,他坚定了我继续坚持学习的心,带给了我充实与快乐。
将介绍以下5部分:
- 随机生成点云点
- 投影点到面(给出了6个面的中心点,离哪个中心点距离近就投影到哪个面)
- 对投影到每个面的点云计算法向量点(3种方法 KNN 半径近邻 混合近邻)
- 对每个面上的法向量及与平均法向量的夹角
- 可视化原始点及法向量点
- 对每个面角度进行简单统计并绘制直方图(hist)
- 对每个面角度进行分区间统计并绘制直方图(俩种方法 hist df.plot)
- df.plot 支持中文,绘制多行列子图,及共享xy轴,支持图例,图形大小等设置
1. 效果图
1.1 点云点灰色 VS 法向量点绿色 VS 法向量可视化
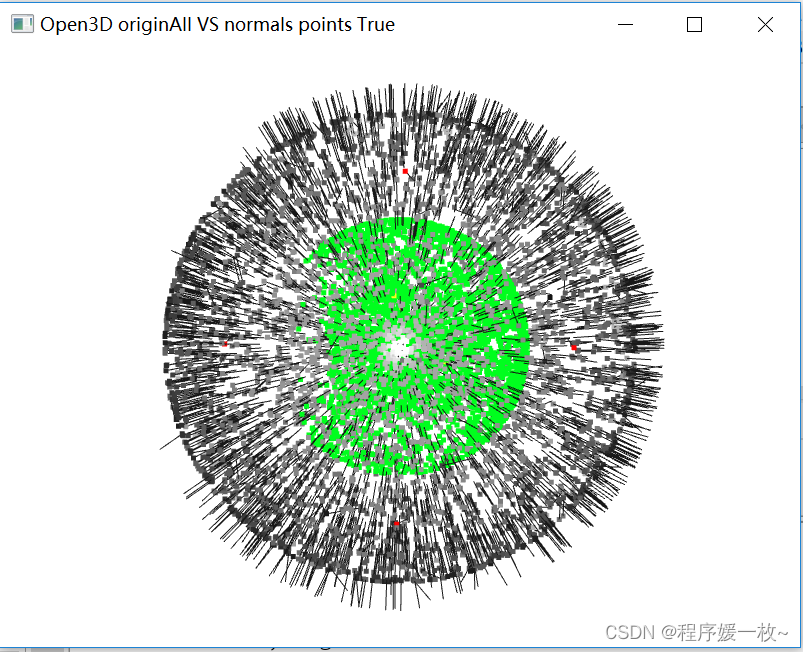
全量点云点灰色 VS 全量法向量点绿色效果图如下:
投影到每个面的均值点为渲染为红色比较明显。法向量点均值点渲染为黄色这里不太明显,可查看下边每个投影面的效果图;

全量点云点灰色 VS 全量法向量点绿色 VS 法向量可视化 效果图如下:
1.2 投影到每个面上的点云点灰色 VS 法向量点绿色 VS 均值点红色,法向量均值点黄色
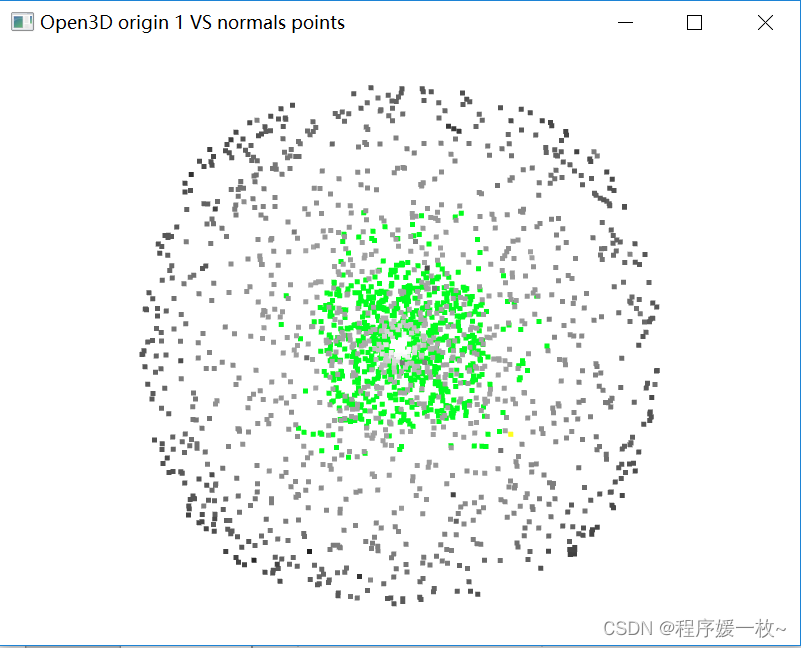
投影到第一个面上的原始点渲染为灰色,均值点渲染为红色;
法向量点渲染为绿色,法向量均值点渲染为黄色,如下图
红色,黄色点不明显,旋转下看下一个图;
投影到第一个面上的原始点渲染为灰色,均值点渲染为红色;
法向量点渲染为绿色,法向量均值点渲染为黄色,旋转后红色、黄色点比较明显 如下图
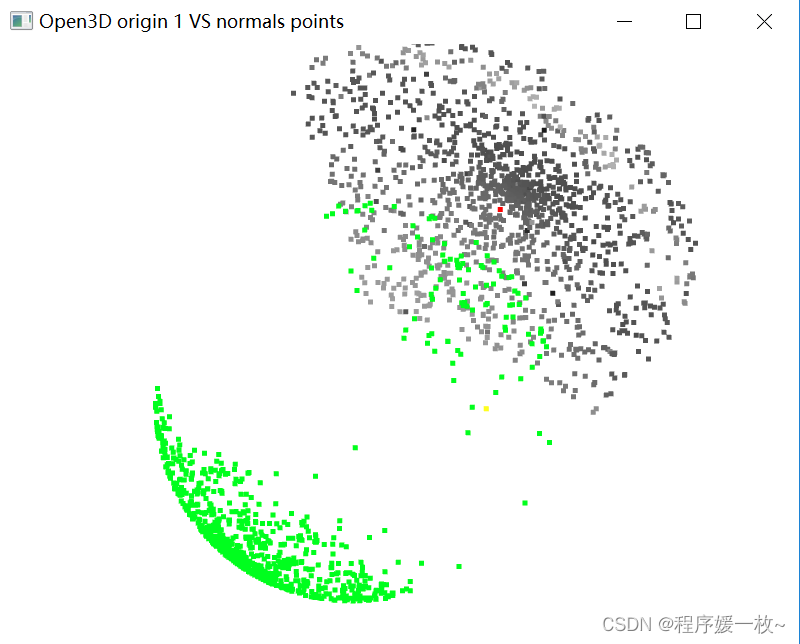 投影到第一个面上的原始点渲染为灰色,均值点渲染为红色;
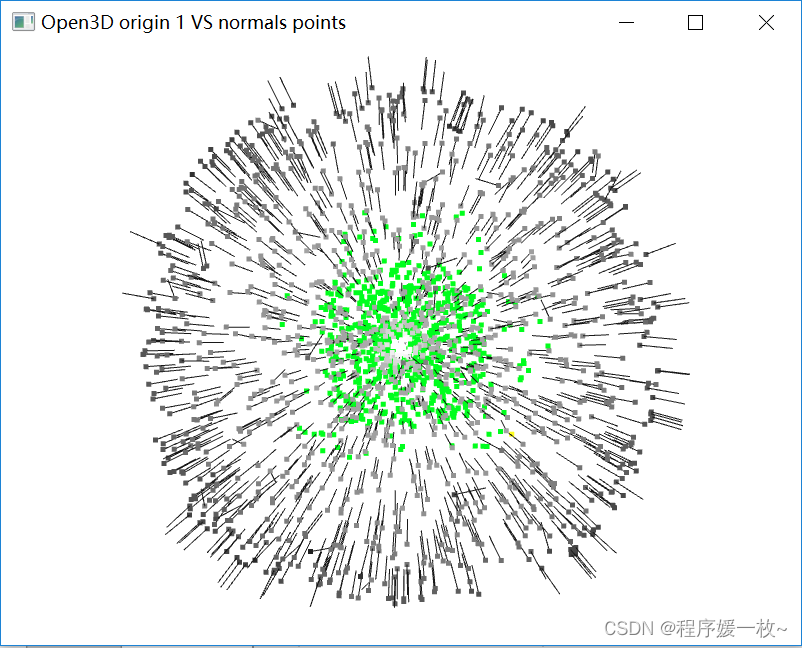
投影到第一个面上的原始点渲染为灰色,均值点渲染为红色;
法向量点渲染为绿色,法向量均值点渲染为黄色,同时可视化法向量点 如下图
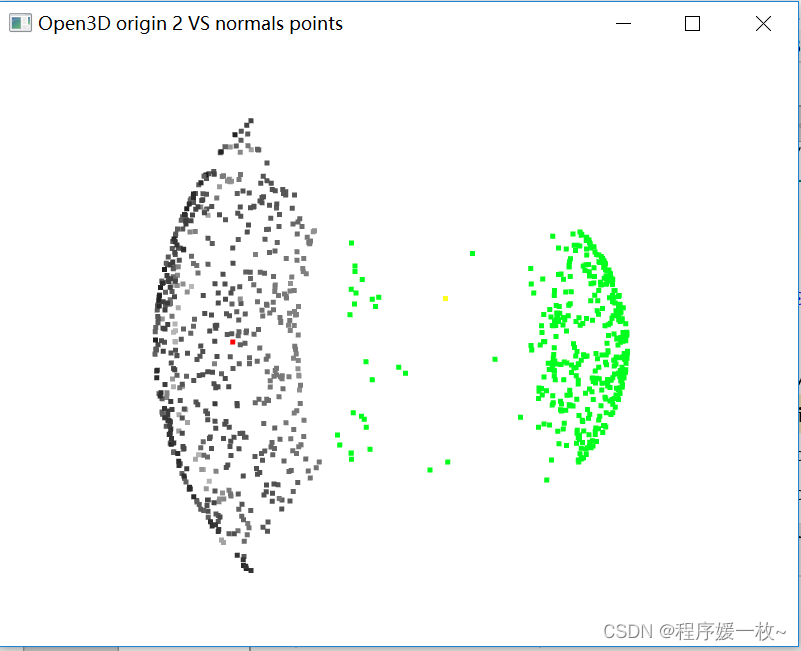
投影到第2个面上的原始点渲染为灰色,均值点渲染为红色;
法向量点渲染为绿色,法向量均值点渲染为黄色,如下图
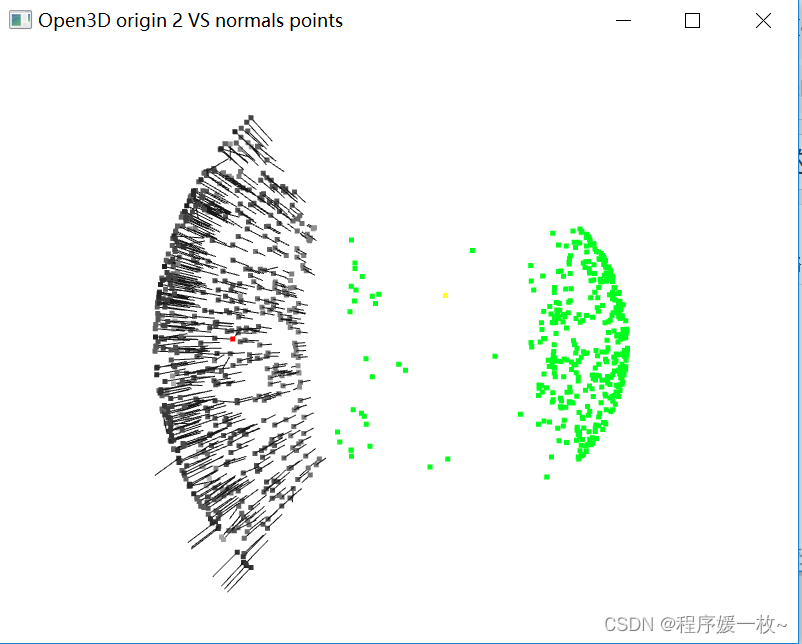
投影到第2个面上的原始点渲染为灰色,均值点渲染为红色;
法向量点渲染为绿色,法向量均值点渲染为黄色,同时渲染法向量 如下图
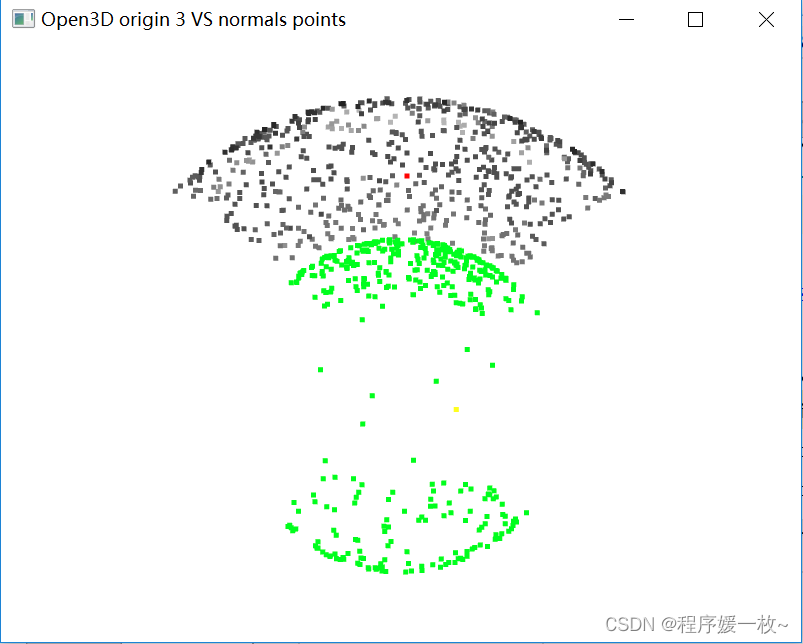
投影到第3个面上的原始点渲染为灰色,均值点渲染为红色;
法向量点渲染为绿色,法向量均值点渲染为黄色,如下图
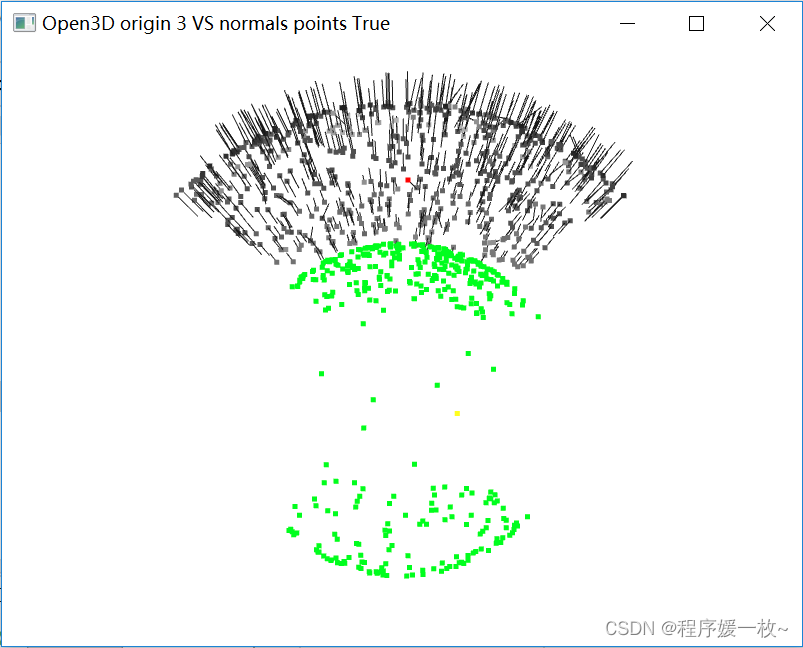
投影到第3个面上的原始点渲染为灰色,均值点渲染为红色;
法向量点渲染为绿色,法向量均值点渲染为黄色,同时渲染法向量 如下图
投影到第4个面上的原始点渲染为灰色,均值点渲染为红色;
法向量点渲染为绿色,法向量均值点渲染为黄色,如下图
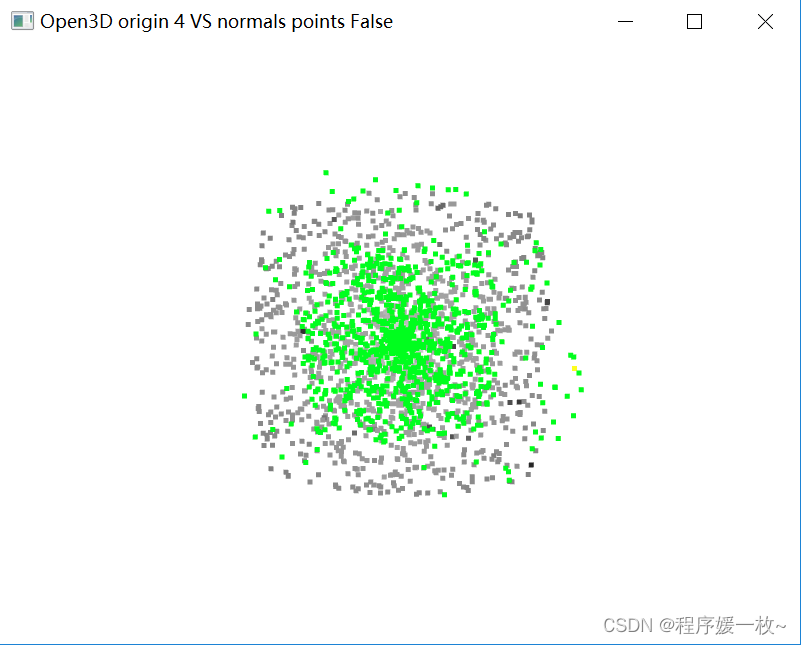
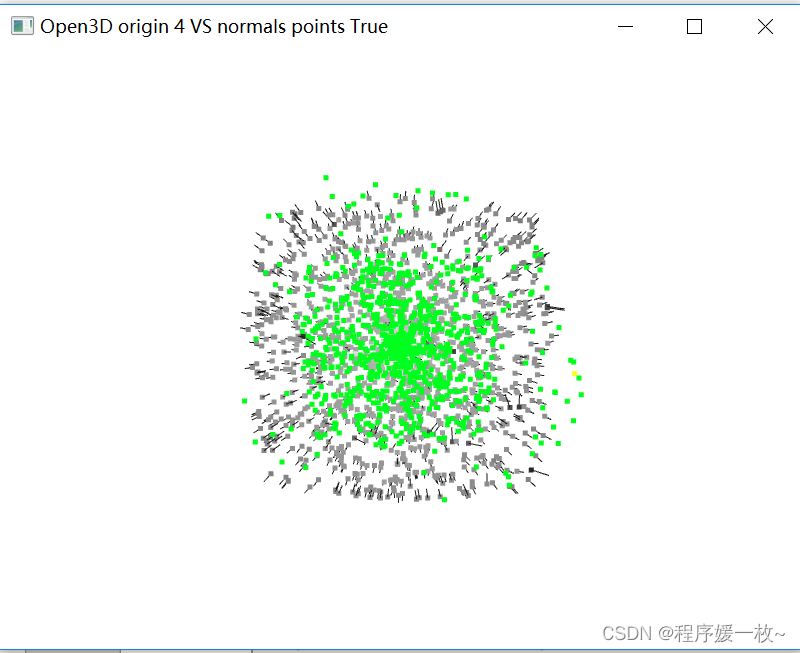
投影到第4个面上的原始点渲染为灰色,均值点渲染为红色;
法向量点渲染为绿色,法向量均值点渲染为黄色,同时渲染法向量 如下图
投影到第5个面上的原始点渲染为灰色,均值点渲染为红色;
法向量点渲染为绿色,法向量均值点渲染为黄色,如下图
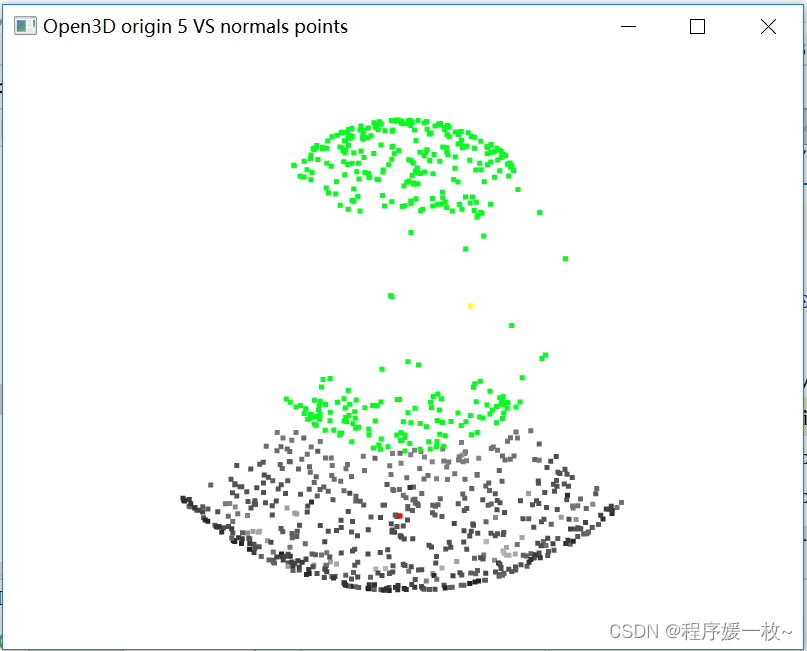
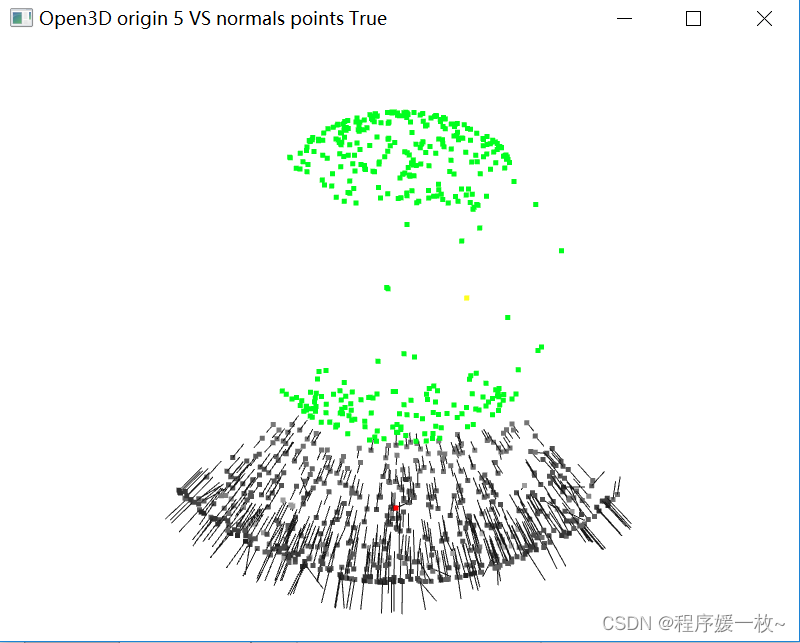
投影到第5个面上的原始点渲染为灰色,均值点渲染为红色;
法向量点渲染为绿色,法向量均值点渲染为黄色,同时渲染法向量 如下图
投影到第6个面上的原始点渲染为灰色,均值点渲染为红色;
法向量点渲染为绿色,法向量均值点渲染为黄色,如下图
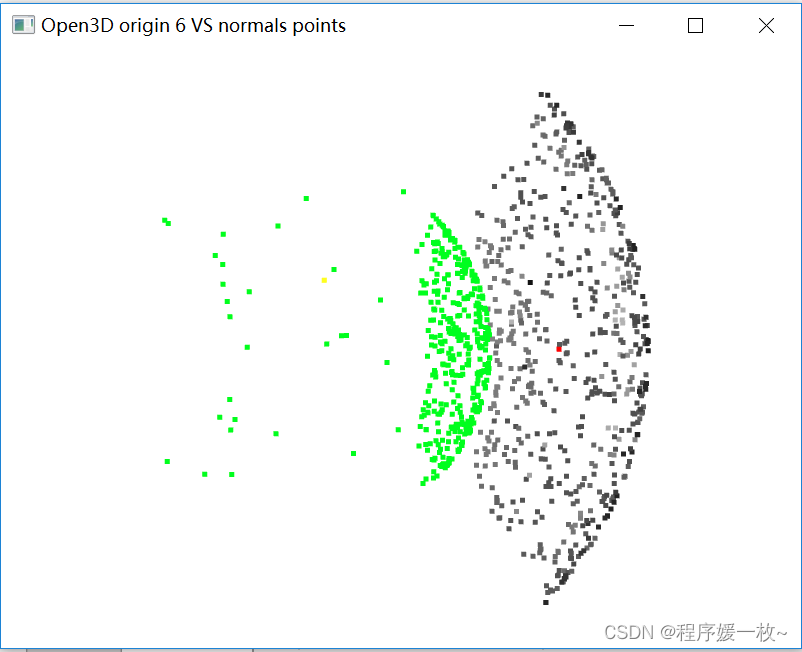
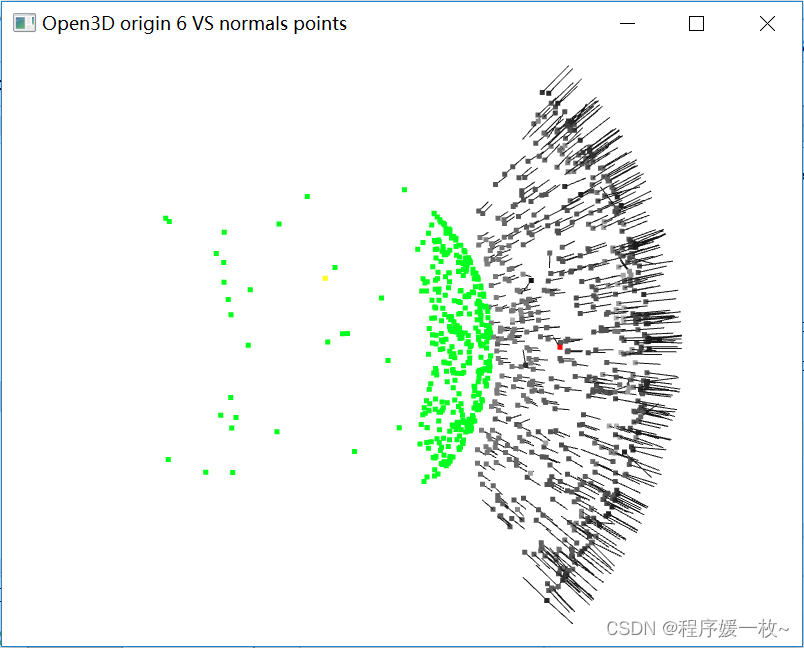
投影到第6个面上的原始点渲染为灰色,均值点渲染为红色;
法向量点渲染为绿色,法向量均值点渲染为黄色,同时渲染法向量 如下图
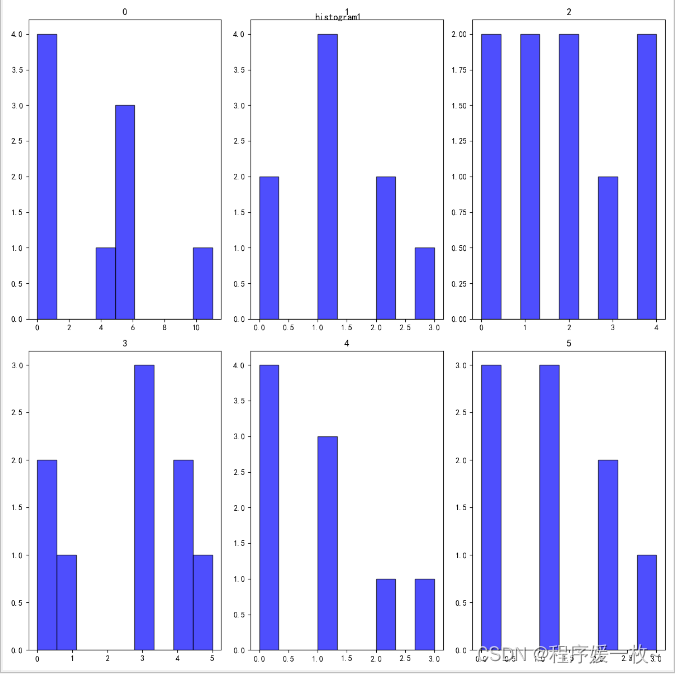
直接按bins=9,将每一个面的角度分为9个块进行绘制,效果图如下:
这个时候不太好的一点是不能根据每个区间看,可以指定bins为数组,一段一段的统计见下一张效果图;
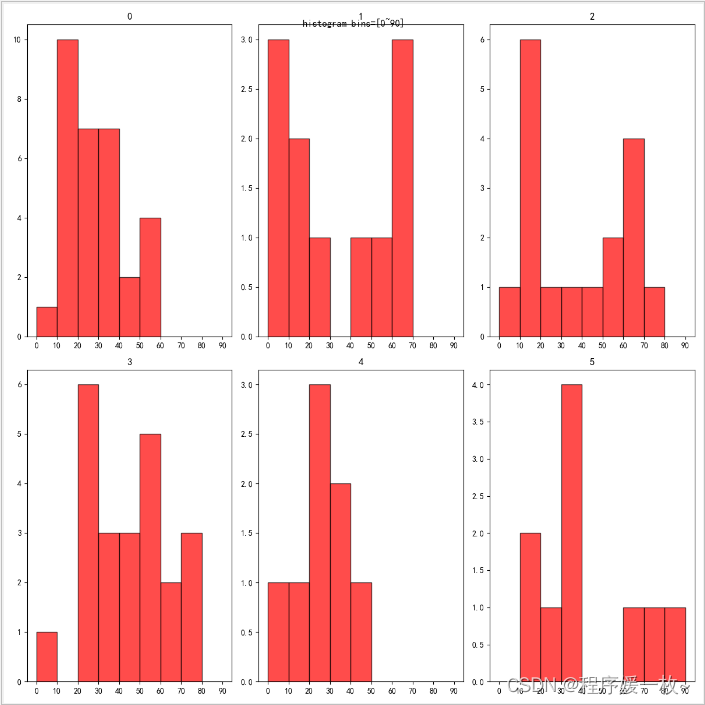
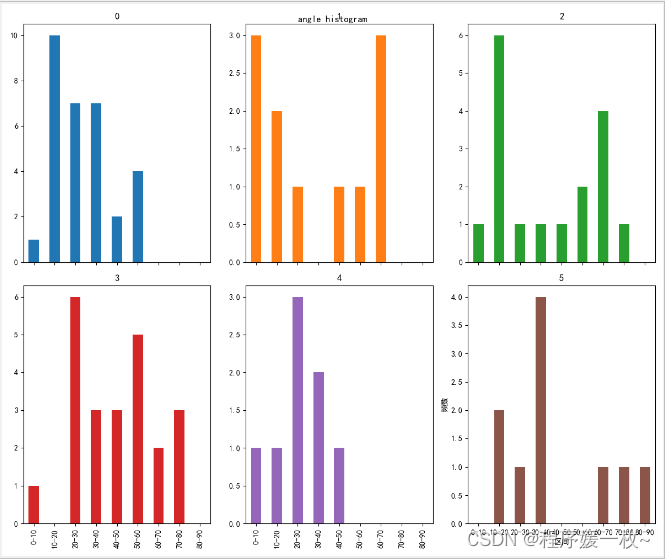
 优化bins=[0,10,20,30,40.50,60,70,80,90],将每一个面的角度分为9个区间进行统计绘制,效果图如下:
优化bins=[0,10,20,30,40.50,60,70,80,90],将每一个面的角度分为9个区间进行统计绘制,效果图如下:
pandas dataFrame df.plot绘制子图角度分布图如下:
6行1列,或者2行3列
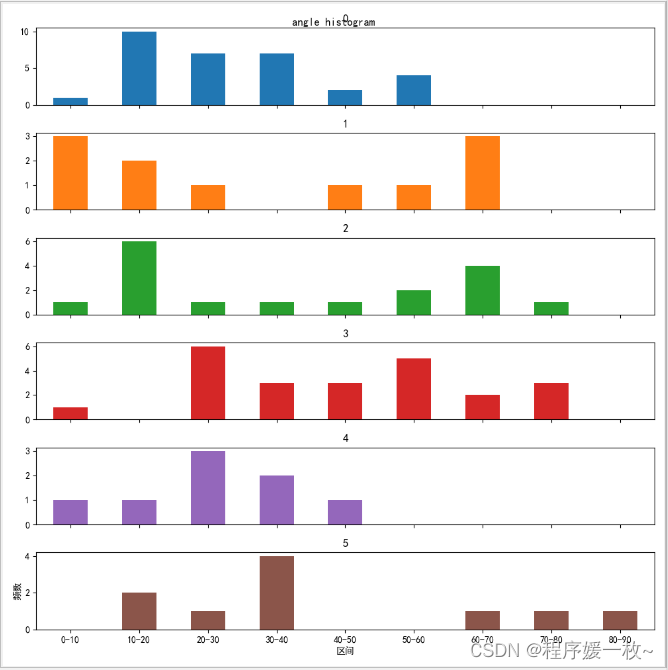
6个面的角度,按区间绘制在一个图中,共享xy轴,效果图如下:
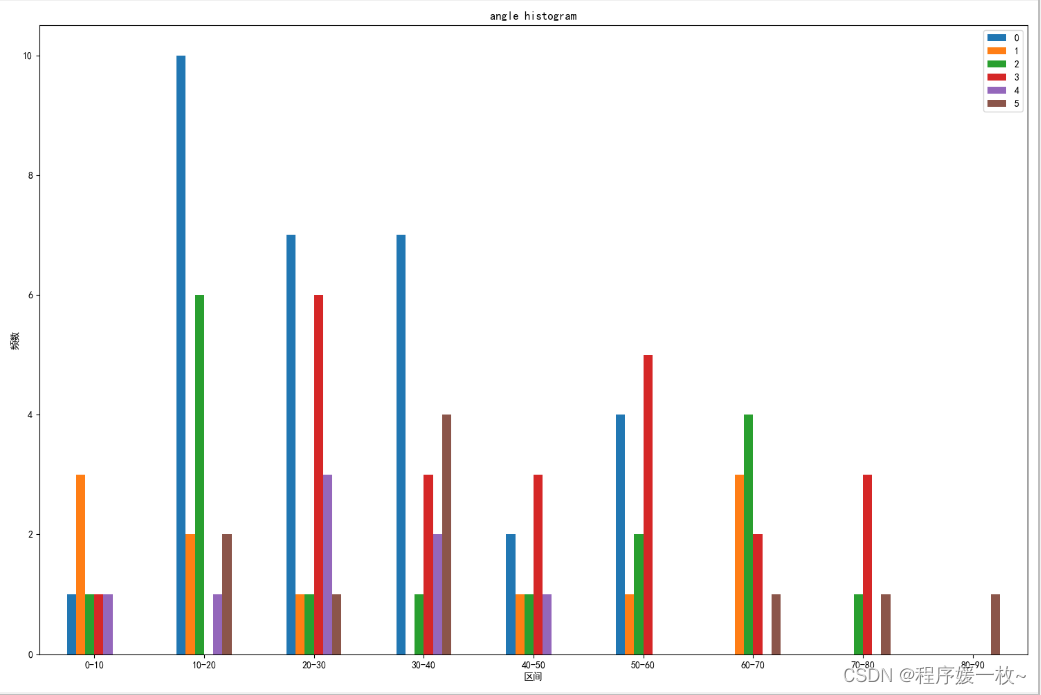
2. 源码
# 随机生成点
# 投影到面上,(给出了6个面的中心点,离哪个中心点距离近就投影到哪个面)
# 对投影到每个面的点云计算法向量点(3种方法 KNN 半径近邻 混合近邻)
# 对每个面上的法向量求均值及与平均法向量的夹角
# 并可视化原始点灰色,法向量点绿色,均值点红色,均值法向量点黄色
# 对每个面角度进行简单统计并绘制直方图(hist)
# 对每个面角度进行分区间统计并绘制直方图(俩种方法 hist df.plot)
# df.plot 支持中文,绘制多行列子图,及共享xy轴,支持图例,图形大小等设置
import random
import numpy as np
import open3d as o3d
# 随机种子,以便复现结果
random.seed(123)
# 支持中文
plt.rcParams['font.sans-serif'] = ['SimHei']
# 解决保存图像是负号'-'显示为方块的问题
plt.rcParams['axes.unicode_minus'] = False
# 假设立方体是2*2*2,立方体的质心是笛卡尔坐标的原点,立方体外接球的半径为sqrt(3)
d = {} # 存储面的中心点及投影到每个面上的点云点,key中心 values投影到该面的点云点
def add_dict(dictionary, loc, centroid):
# loc is the point's location on sphere,
# centroid is the center(s) of cube's face(s) that is nearest to the loc
if tuple(loc) in dictionary.keys():
dictionary[tuple(loc)].append(list(centroid))
else:
dictionary[tuple(loc)] = [list(centroid)]
def point_generator(npoints, r):
result = []
# 0 < theta < 2*np.pi
# 0 < phi < np.pi
for i in range(npoints):
theta = random.random() * 2 * np.pi
phi = random.random() * np.pi
x = r * np.cos(theta) * np.sin(phi)
y = r * np.sin(theta) * np.sin(phi)
z = r * np.cos(phi)
result.append([x, y, z])
return result
npoints = 5000
r = np.sqrt(3)
centroids = [[1, 0, 0], [0, 1, 0], [0, 0, 1], [-1, 0, 0], [0, -1, 0], [0, 0, -1]]
points = point_generator(npoints, r)
# print(points)
# 计算俩个点的距离
def distance(p, q):
if len(p) == len(q):
result = 0
for i in range(len(p)):
result += (p[i] - q[i]) ** 2
return result ** 0.5
else:
print('cannot calculate distance of points from different dimensions')
# 寻找离点最近的面(中心点),并投影到对应的面上
def archive_nearest_pc_pairs(dictionary, centroids, points):
for p in points:
dist = []
for q in centroids:
dist.append(distance(p, q))
nearest_centroid = centroids[dist.index(min(dist))] # 寻找最近的立方体面中心的点距离
add_dict(dictionary, nearest_centroid, p)
archive_nearest_pc_pairs(d, centroids, points)
print(centroids)
# 3种方法计算法向量
def compute_normals(pcd, flag=1):
# 混合搜索 KNN搜索 半径搜索
if (flag == 1):
pcd.estimate_normals(
search_param=o3d.geometry.KDTreeSearchParamHybrid(radius=0.01, max_nn=20)) # 计算法线,搜索半径1cm,只考虑邻域内的20个点
elif (flag == 2):
pcd.estimate_normals(search_param=o3d.geometry.KDTreeSearchParamKNN(knn=3)) # 计算法线,只考虑邻域内的20个点
else:
pcd.estimate_normals(search_param=o3d.geometry.KDTreeSearchParamRadius(radius=0.01)) # 计算法线,搜索半径1cm,只考虑邻域内的20个点
# 计算俩个法向量的夹角可参考 http://mp.ofweek.com/it/a456714148137
# x为第一个法向量,y为第二个法向量
def cal_angle(x, y):
# 分别计算两个向量的模:
l_x = np.sqrt(x.dot(x))
l_y = np.sqrt(y.dot(y))
# print('向量的模=', l_x, l_y)
# 计算两个向量的点积
dian = x.dot(y)
# print('向量的点积=', dian)
# 计算夹角的cos值:
cos_ = dian / (l_x * l_y)
# print('夹角的cos值=', cos_)
# 求得夹角(弧度制):
angle_hu = np.arccos(cos_)
# print('夹角(弧度制)=', angle_hu)
# 转换为角度值:
angle_d = angle_hu * 180 / np.pi
# print('夹角=%f°' % angle_d)
return angle_d
# 初始化法向量dict,key中心点 values法向量点
normals_dict = {}
pcds = []
for i, (key, value) in enumerate(d.items()):
# print(value)
val = np.array(value)
# 计算点云均值点,并插入到原点云点的第一个点
avg_point = np.mean(val, axis=0) # axis=0,计算每一列的均值
origin_points = np.row_stack((avg_point, val))
# 构造点云数据
pcd = o3d.geometry.PointCloud()
points = o3d.utility.Vector3dVector(origin_points)
pcd.points = points
# 计算法向量,可选择3种方法计算法向量,传值1/2/其他
compute_normals(pcd, 2)
normals = o3d.np.asarray(pcd.normals)
# print('pcd-normals: ', normals)
normals_dict[key] = normals
print('第', str(i + 1), '个面, center:', key, len(pcd.normals), '个点')
# print(np.sum(normals) / len(normals))
# 均值点法向量点
avg_normal = normals[0]
# 遍历计算平均向量与点云向量的夹角(由于第一个点是均值点,所以去除)
for j, (point, point_normal) in enumerate(zip(origin_points[1:], normals[1:])):
# 计算均值点法向量 与 点云点法向量的夹角
print('\t第 %s 个点, angle: %s' % (
str(j + 1),
cal_angle(np.array(avg_point) - np.array(avg_normal), np.array(point) - np.array(point_normal))))
print("--------------------------------------------------------")
# 可视化法向量点和原始点
pcd.paint_uniform_color([0.5, 0.5, 0.5]) # 把原始点渲染为灰色
pcd.colors[0] = [1, 0, 0] # 原始点云均值点渲染为红色
normal_point = o3d.utility.Vector3dVector(pcd.normals)
normals = o3d.geometry.PointCloud()
normals.points = normal_point
normals.paint_uniform_color((0, 1, 0)) # 点云法向量的点都以绿色显示
normals.colors[0] = [1, 1, 0] # 均值点法向量点渲染为黄色
o3d.visualization.draw_geometries([pcd, normals], "Open3D origin " + str(i + 1) + " VS normals points True",
width=800,
height=600, left=50,
top=50,
point_show_normal=True, mesh_show_wireframe=False,
mesh_show_back_face=False)
o3d.visualization.draw_geometries([pcd, normals], "Open3D origin " + str(i + 1) + " VS normals points False",
width=800,
height=600, left=50,
top=50,
point_show_normal=False, mesh_show_wireframe=False,
mesh_show_back_face=False)
# 加入list以便全量渲染
pcds.append(pcd)
pcds.append(normals)
print(pcds[0], pcds[1], pcds[2], pcds[3], pcds[4], pcds[5],
pcds[6], pcds[7], pcds[8], pcds[9], pcds[10], pcds[11],
len(pcds))
# 同时可视化法向量
o3d.visualization.draw_geometries([pcds[0], pcds[1], pcds[2], pcds[3], pcds[4],
pcds[5], pcds[6], pcds[7], pcds[8], pcds[9], pcds[10], pcds[11]
], "Open3D originAll VS normals points True",
width=800,
height=600, left=50,
top=50,
point_show_normal=True, mesh_show_wireframe=False,
mesh_show_back_face=False)
# 不可视化法向量
o3d.visualization.draw_geometries([pcds[0], pcds[1], pcds[2], pcds[3], pcds[4],
pcds[5], pcds[6], pcds[7], pcds[8], pcds[9],
pcds[10], pcds[11]], "Open3D originAll VS normals points False",
width=800,
height=600, left=50,
top=50,
point_show_normal=False, mesh_show_wireframe=False,
mesh_show_back_face=False)
# 画角度分布直方图
def get_normal_angle_histogram(dict):
"""
:param dict:
:return:
"""
dict_angle_histogram = {}
min_angle = 0
max_angle = 90
partition = (max_angle - min_angle) / 9
data_list = []
for centroid in dict.keys():
v1 = {}
# data_tri_list = []
for l in range(9):
v1[l] = 0
for i in range(len(dict[centroid])):
k = round(float((float(dict[centroid][i]) - min_angle) / partition))
if k == 9:
k = 8
print('---------------------------')
print(dict[centroid][i])
v1[k] = v1.get(k, 0) + 1
# https://stackoverflow.com/questions/4674473/valueerror-setting-an-array-element-with-a-sequence
# 避免数组长度不一致
# norm = np.linalg.norm(dict[centroid][i])
# # data_tri_list.append(norm)
v1_list = list(v1.values())
print('v1_list', v1_list)
# total = sum(v1.values(), 0.0)
# a = {j: v / total for j, v in v1.items()}
dict_angle_histogram[centroid] = v1_list
data_tri_list = list(v1.values())
data_list.append(data_tri_list)
return dict_angle_histogram, data_list
dict_angle_histogram_1, data_list_1 = get_normal_angle_histogram(normals_angle_dict)
print('------------------------------')
print(dict_angle_histogram_1)
"""
绘制直方图
data:必选参数,绘图数据
bins:直方图的长条形数目,可选项,默认为10
normed:是否将得到的直方图向量归一化,可选项,默认为0,代表不归一化,显示频数。normed=1,表示归一化,显示频率。
facecolor:长条形的颜色
edgecolor:长条形边框的颜色
alpha:透明度
"""
# 将bins=9,按9块对角度进行统计绘制直方图
fig1 = plt.figure(figsize=(12, 12))
for i, angle_histogram_list in enumerate(dict_angle_histogram_1.values()):
plt.subplot(2, 3, i + 1)
plt.hist(angle_histogram_list, bins=9, normed=0, density=None, facecolor="blue", edgecolor="black", alpha=0.7)
# x_major_locator = MultipleLocator(2)
# # 把x轴的刻度间隔设置为1,并存在变量里
# y_major_locator = MultipleLocator(10)
# 把y轴的刻度间隔设置为10,并存在变量里
ax = plt.gca()
# ax.xaxis.set_major_locator(x_major_locator)
# ax.xaxis.set_major_locator(ticker.MultipleLocator(base=5))
# ax.yaxis.set_major_locator(y_major_locator)
# ax.yaxis.set_major_locator(ticker.MultipleLocator(base=40))
# plt.xlim(29, 51)
# plt.ylim(0, 80)
plt.title(i)
plt.suptitle("histogram1")
plt.show()
# 优化上边的绘制,bins=[ 0 10 20 30 40 50 60 70 80 90],按区间对角度进行统计绘制
fig1 = plt.figure(figsize=(12, 12))
for i, angle_list in enumerate(normals_angle_dict.values()):
plt.subplot(2, 3, i + 1)
bins = np.arange(0, 91, 10) # 设置连续的边界值,即直方图的分布区间[0,10],[10,20]...
# 直方图会进行统计各个区间的数值
plt.hist(angle_list, bins=bins, normed=0, density=None, facecolor="red", edgecolor="black", alpha=0.7)
ax = plt.gca()
plt.xticks(bins)
plt.title(i)
plt.suptitle("histogram bins=[0~90]")
plt.show()
print('test data')
print(normals_angle_dict[(0, 0, 1)])
# for centroids in normals_angle_dict.keys():
# s = pd.cut(normals_angle_dict[centroids], bins=[x for x in np.arange(0, 100, 10)])
# print(s.value_counts())
# values = s.value_counts().values
#
# print('pandas values', centroids, values)
# labels = [str(i) + '-' + str(i + 10) for i in np.arange(0, 90, 10)]
# # print(labels)
# # ['0-1', '1-2', '2-3', '3-4', '4-5', '5-6', '6-7', '7-8', '8-9', '9-10']
# df = pd.DataFrame(values, index=labels)
# df.plot(kind='bar', legend=False)
# plt.xticks(rotation=0)
# plt.ylabel('频数')
# plt.xlabel('区间')
# plt.show()
# 构建pandas DataFrame需要的字典
dict_angles = {}
for i, centroids in enumerate(normals_angle_dict.keys()):
s = pd.cut(normals_angle_dict[centroids], bins=[x for x in np.arange(0, 100, 10)])
print(s.value_counts())
values = s.value_counts().values
print('pandas values', centroids, values)
labels = [str(i) + '-' + str(i + 10) for i in np.arange(0, 90, 10)]
dict_angles[i] = values
# 以dict构建DataFrame
list = [i for i in range(len(dict_angles))]
labels = [str(i) + '-' + str(i + 10) for i in np.arange(0, 90, 10)]
df = pd.DataFrame(dict_angles, index=labels, columns=list)
df.plot(kind='bar',
y=list, # 6个变量可视化
# subplots=True, # 多子图并存
# layout=(2, 3), # 子图排列2行3列
title='angle histogram',
sharex=True, # 共享xy轴
sharey=True, # 共享xy轴
figsize=(15, 10),
legend=True)
plt.tight_layout()
plt.xticks(rotation=0)
plt.ylabel('频数')
plt.xlabel('区间')
plt.show()
参考
相关文章
- Python 3.7 安装教程
- Python mplfinance库④ 如何自定义style样式
- Python __missing__ 魔法方法
- 史上最详细 Python第三方库添加方法 and 错误解决方法
- Python__repr__()方法:显示属性
- 最适合学Python的几类人,有你吗?
- Python中的海象运算符“:=”使用方法详解
- python中super的使用方法
- 《Python面向对象编程指南》——1.4 使用__init()__方法创建常量清单
- 《Python和Pygame游戏开发指南》——2.8 关于函数、方法、构造函数和模块中的函数(及其差别)的一些提示
- 《Python高手之路》——1.3 版本编号
- python 对象(object)
- Python基础必掌握的while无限迭代循环方法详解
- 使用 Python 拆分文本文件的最快方法是什么?
- Python Manim 问题解决大全之 如何解决 latex failed but did not produce a log file
- 标准遗传算法(二进制编码 python实现)
- 非常实用的python字符串处理方法
- 初试selenium用python做自动化测试
- Python-05:文件操作
- python:封装连接数据库方法
- python中list的sort方法
- crontab开机创建screen会话+启动pyenv+激活虚拟环境+自动运行python脚本
- python爬虫学习(一):BeautifulSoup库基础及一般元素提取方法
- 【python】dict多种方法实现去除字典value为0 的元素