
JVM内存模型

一、初识JVM
JVM是Java Virtual Machine的简称,Java虚拟机,虚拟机是指通过软件模拟的具有完整硬件功能的,运行在一个完全隔离的环境中的完整计算机系统,常见的虚拟机有:JVM、VMwave、Virtual Box,目前最主流使用的JVM是HotSpot VM
JVM执行流程
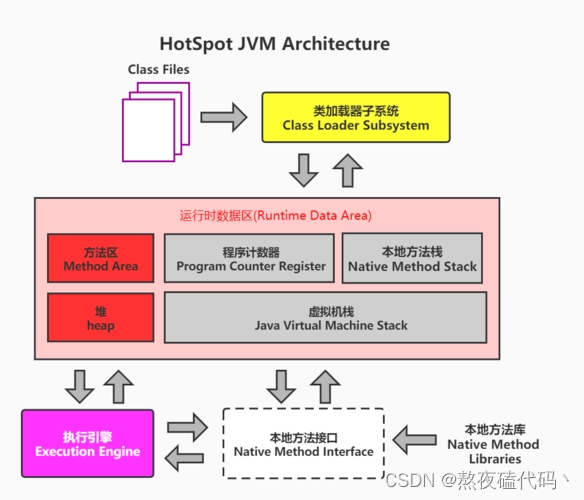
程序在执行之前先要把java代码编译成字节码(class文件),JVM首先需要把字节码按照一定方式,类加载器(ClassLoader) 将文件加载到内存运行时数据区(Runtime Data Area) ,而字节码文件是JVM的一套指令集规范,并不能直接交给底层操作系统去执行,因此需要命令解析器执行引擎(Execution Engine) 将字节码翻译成底层系统执行再交给CPU去执行,而这个过程需要调用其他语言的接口 本地库接口(Native Interface) 来实现程序的整个功能
二、JVM内存划分
JVM运行时数据区域也叫内存布局,由以下5大部分组成:
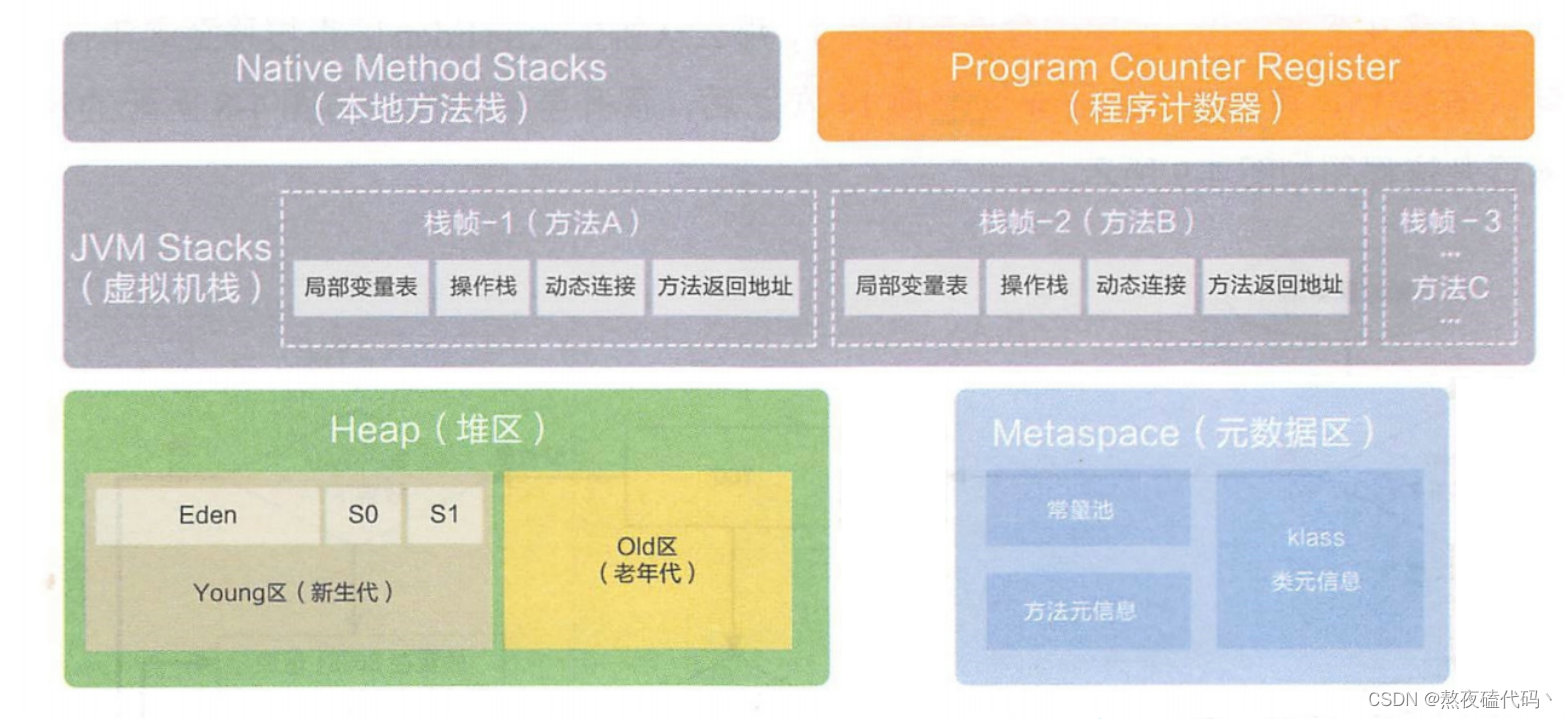
Java虚拟机栈(线程私有)
Java虚拟机栈的生命周期和线程相同,Java虚拟机栈描述的是Java方法与方法之间关系:每个方法在执行的同时都会创建一个栈帧(Stack Frame) 用于存储局部变量表,方法入口地址,方法参数,方法返回地址((PC寄存器的引用)
什么是线程私有?
简单的来说,就是每个线程都有自己的Java虚拟机栈
本地方法栈(线程私有)
本地方法栈描述的是本地方法的调用,也是线程私有的,如果线程请求分配的栈容量超过本地方法栈允许的最大容量,Java虚拟机将会抛出一个stackoverflowError 异常
程序计数器(线程私有)
程序计数器:用来记录当前线程执行的行号的,程序计数器是一块比较小的内存空间,可以看作是当前线程所执行的字节码的行号指示器,如果执行的是Java方法,计数器记录的是虚拟机字节码执行的地址,如果执行的是Native方法,这个计算器的值为空
堆(线程共享)
一个JVM实例只存在一个堆内存,堆也是Java内存管理的核心区域。
Java堆区在JVM启动的时候即被创建,其空间大小也就确定了。是JVM管理的最大一块内存空间。堆内存的大小是可以调节的。
《Java虚拟机规范》规定,堆可以处于物理上不连续的内存空间中,但在逻辑上它应该被视为连续的。
所有的线程共享Java堆,在这里还可以划分线程私有的缓冲区(Thread Local Allocation Buffer, TLAB) 。
数组和对象可能永远不会存储在栈上,因为栈帧中保存引用,这个引用指向对象或者数组在堆中的位置。
在方法结束后,堆中的对象不会马上被移除,仅仅在垃圾收集的时候才会被移除。
堆,是GC ( Garbage Collection, 垃圾收集器)执行垃圾回收的重点区域。
方法区(线程共享)

JDK1.8中该区域叫做元空间(Metaspace),所有线程共用这一块,用来存储虚拟机加载的类信息、常量、静态变量、及编译器编译后的代码等数据
我们在判断某个变量再那个区域上时,我们需要把握以下原则:
1.局部变量在栈
2.普通成员变量在堆
3.静态成员变量再方法区/元数据区
三、类加载
类加载我们可以这样理解:类加载就是将.clss文件(字节码)从文件(硬盘)加载到内存中(元数据区)的这样一过程
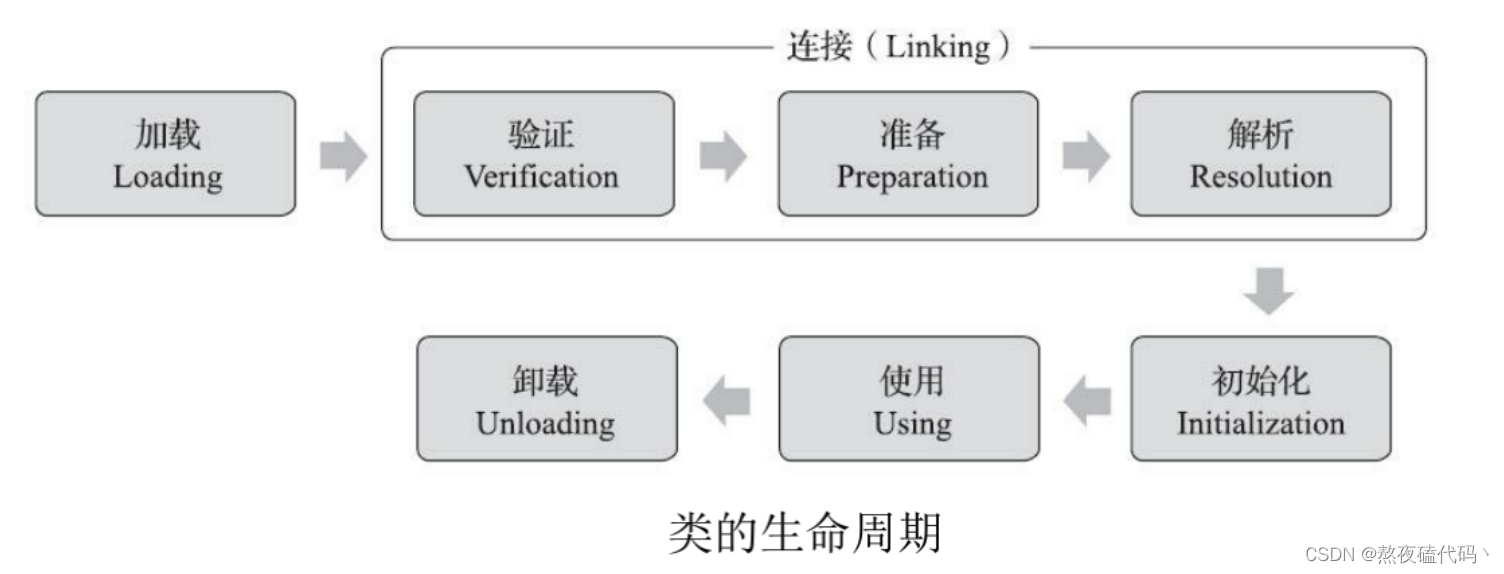
加载:就是将.class文件找到,打开文件,读文件,将文件读到内存中,在内存中生成一个代表这个类的Class对象,作为方法区这个类的各种数据的访问入口
验证:检查下.class文件格式对不对,确保.class文件所包含的信息是否符合《Java虚拟机规范》的全部约束要求

准备:给类对象分配内存空间(先在元数据区占个位置),为类中定义的静态变量分配内存并设置类变量初始值(0值)
解析:针对字符串常量初始化,将符号引用转为直接引用。
字符串常量,得有一块内存空间,存这个字符的实际内容,还有一个引用来保存这个内存空间的起始地址。在类加载之前,字符串常量是在.class文件中的,此时这个引用记录的并非是字符串常量真正的地址,而是它在文件的偏移量/占位符 ,在类加载之后,才会真正的把这个字符串常量给放到内存中,此时才有内存地址,这个引用才能被真正赋值成指定内存地址
初始化:初始化阶段,Java虚拟机才真正开始执行类中编写的Java代码,加载父类,执行静态代码块的代码
一个类什么时候会被加载呢?
类加载并不是Java程序一运行就把所有类加载了,而是在真正用到时才会加载。
1.构造类的实例
2.调用这个类的静态方法/使用静态属性
3.加载子类就会先加载父类
双亲委派模型
站在Java虚拟机的角度,只有两种不同的类加载器:一种是启动类加载器(Bootstrap
ClassLoader),这个类加载器使用C++实现,是虚拟机自身的一部分;另一种就是其他类加载器,这些类加载器都由Java语言实现,独立于虚拟机外部,都继承于java.lang.ClassLoader.
JVM默认提供三个类加载器:
启动类加载器(BootstrapClassLoader):负责加载标准库中的类
扩展类加载器(ExtensionClassLoader):负责加载JVM扩展库中的类
应用程序类加载器(ApplicationClassLoader):负责加载用户提供的第三方库/代码中的类
上述三各类,存在特殊的父子关系(不是父类 子类,相当于每个class loader有一个parent属性 指向自己的父类加载器)
上述类加载器如何配合工作?
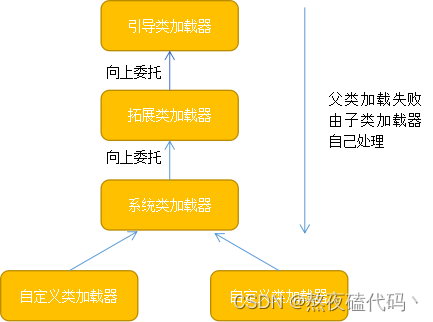
一个类加载器收到了类加载的请求,它首先不会自己去尝试加载这个类,而是把这个请求委派给父类加载器去完成,每一个层次的类加载器都是如此,所有的加载请求最终都应该传送到顶层的启动类加载器中,只有当父加载器反馈自己无法完成这个加载请求(它的搜索范围中没有找到所需的类)时,子加载器才会尝试自己去加载
注: 双亲委派模型不是一种强制性约束,也就是你不这么做也不会报错怎样的,它是一种JAVA设计者推荐使用类加载器的方式。
优点:
1.避免重复加载类:比如A类和B类都有一个父类C类,那么当A启动时就会将C类加载,加载B类时就能避免加载C类了
2.安全性:使用双亲委派模型可以保证Java核心的API不被篡改。如果不使用双亲委派模型,而是我们每个类加载器加载自己就会出现问题,比如我们自己写了一个Integer类,但是我们使用双亲委派模型加载了Java.lang.Integer类就不会加载我峨嵋你自己写的了
四、垃圾回收机制 GC
垃圾指的是我们不再使用的内存,垃圾回收就是把我们不用的内存自动释放了。如果是手动释放的话,如果我们没有释放那么这块内存空间就会持续存在,并且堆的内存生命周期比较长,不像栈随着方法执行结束自动销毁释放,堆默认不能手动释放,因此Java引入了 GC。
GC的好处:使程序员写代码更简单一些,不容易出错
GC的坏处:需要消耗额外的系统资源,也有额外的性能开销
此外,GC还有一个比较关键的问题:STW问题(stop the world),当内存中的垃圾已经很多了,此时触发一次GC操作开销可能非常大,大到可能将系统资源吃到很多,导致其他业务代码无法正常执行,这样的卡顿在极端情况下,可能出现几十毫秒甚至上百毫秒
JVM中有好多内存区域:这里主要是针对堆和元数据区,GC回收是以"对象"为单位进行回收的。
GC时机的工作步骤:
1.找到垃圾/判定是否为垃圾
2.对对象进行释放
死亡对象判断算法
如何判断是否为垃圾:主要看有没有"引用"指向它
1.引用计数(不是Java,而是python/php)
给每个对象分配一个计数器,每创建一个引用指向该对象,计数器+1,每次销毁一个指向该对象的引用,计数器就-1.
该方法的问题:
1.内存空间浪费大(利用率低)
每个对象都要分配一个计数器,如果按4各字节算的,如果你对象比较少不要紧,要是对象特别多,那么占用额外的空间就会很多
2.存在循环引用的问题
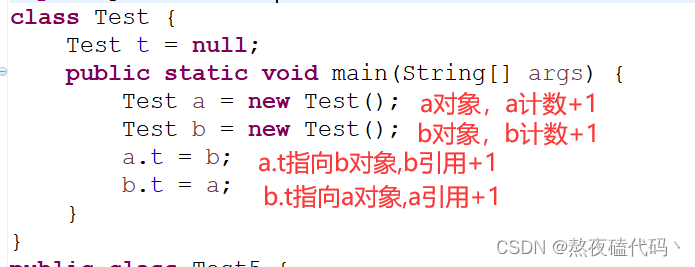
接下来,a和b引用销毁,此时a和b计数-1,但结果还都是1,不能释放资源,但实际这两对象已经无法访问了。python/php使用引用计数,需要搭配其他机制来避免循环引用
2.可达性分析(java做法)
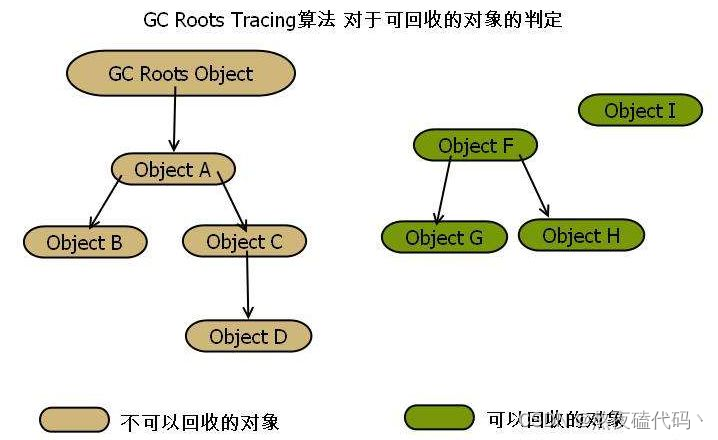
Java中的对象都是通过引用来指向并访问的,一个引用指向一个对象,对象里的成员又指向别的对象。
可达性分析:就是将这些对象被组织的结构视为树,从根节点出发遍历树,所有能访问到的对象,标记成可达,不能访问到的,就是不可达,JVM有一个所有对象的名单(每new一个对象,JVM都会记录下来,JVM就会知道一共有哪些对象,每个对象的地址是什么),通过上述遍历,将可达的标记出来,剩下的不可达的就可以作为垃圾进行回收了。
进行可达性分析的起点称之为GCroots ,可以为以下几种:
1.虚拟机栈中引用的对象
2.方法区中类静态属性引用的对象
3.方法区中常量引用的对象
4.本地方法栈Native方法引用的对象
垃圾回收算法
1.标记清除

简答粗暴,标记和清除的这两个过程的效率都不高、标记清除后会产生大量不连续的内存碎片,导致我们总的空闲空间很大,但是每个具体的空间都很小,导致申请大一点的内存空间时就会导致失败
2.复制算法
复制算法为了解决内存碎片的问题,将整个内存分成两半,用一半清一半
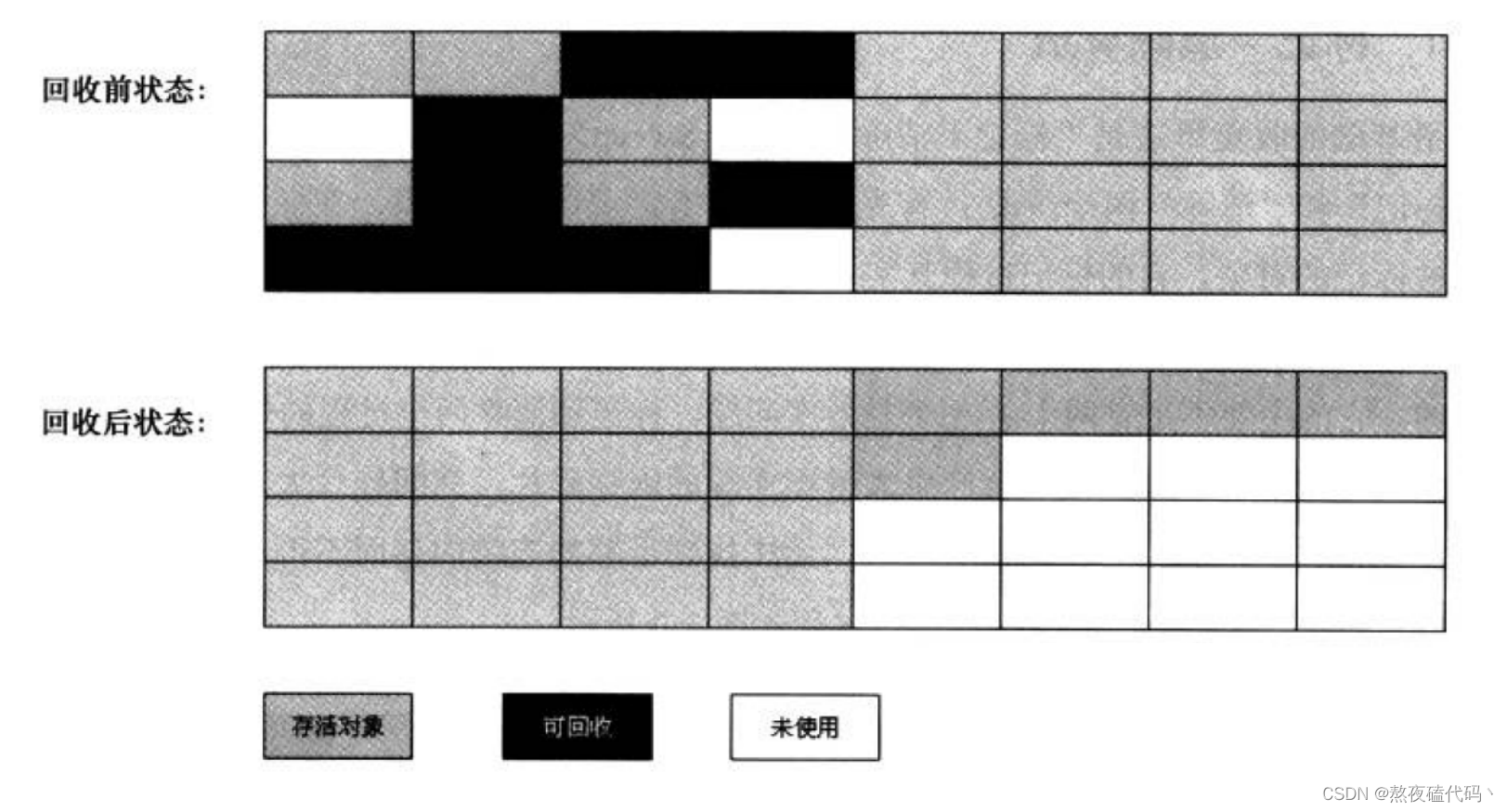
简单的来说就是将不是垃圾的对象复制到另一半,然后将整个空间删除掉
缺点:
1.空间利用率低
2.如果垃圾少,有效对象多,复制成本就比较大
3.标记整理
标记整理类似与顺序表的删除操作,会将后面的元素搬运到前面
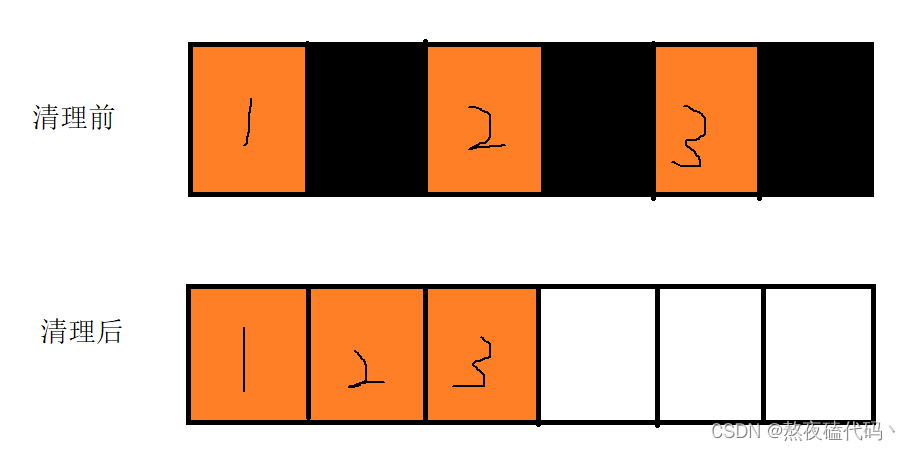
保证了空间利用率,也解决了内存碎片问题,但是这种算法效率也不够高,如果搬运的空间比较大此时的开销也是比较大的
4.分代回收
分代回收是基于上面几种算法的,将垃圾回收分成了不同的场景,不同的场景应用不同的算法,这个算法根据对象存活的周期的不同将内存划分为几块,一般将Java堆分为新生代和老年代。
在新生代,每次垃圾回收都会有大批对象死去,只有少量存活,因此我们使用复制算法;而老年代中的对象存活率高、没有额外空间对它分配担保,必须使用标记整理算法
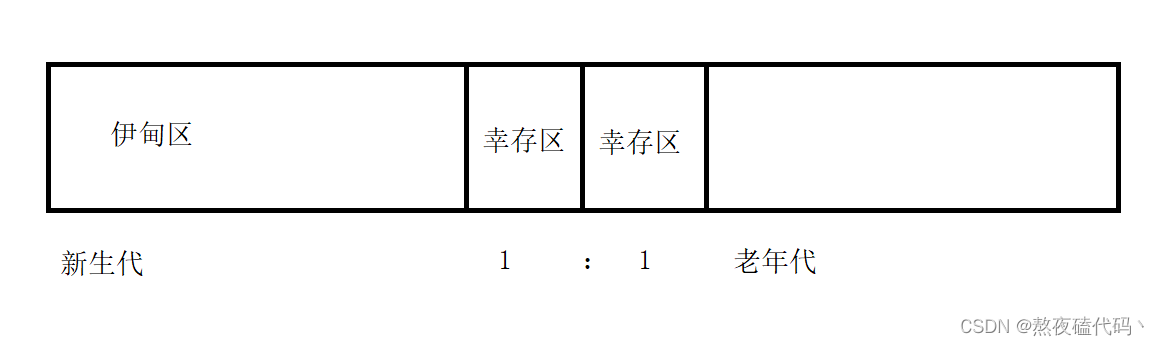
哪些对象会进行新生代?哪些对象会进入老年代?
新生代(Minor GC): 刚new出来的对象先放到伊甸区,经过一轮的GC就会被放到幸存区。伊甸区 -> 幸存区 使用复制算法,在幸存区也要周期性的接受GC的考验,如果变成垃圾就释放,如果不是垃圾拷贝到另一个幸存区,此处使用复制算法,如果该对象在两个幸存区已经来回拷贝很多次(一般默认是15次)就会进入老年代
老年代(Full GC): 老年代都是年龄大的对象,生命周期普遍更长,也要进行周期性GC扫描,但是频率更低,如果老年代是垃圾,就会使用标记整理的方式释放
相关文章
- JVM内存结构学习
- JVM:常用的四种垃圾回收机制
- 面试官:new 关键字在 JVM 中是如何执行的?
- JVM 怎么判断对象已经死了?
- 【JVM】内存结构(下)
- JVM 中对象的内存布局以及如何计算对象和数组的大小
- 一个性能较好的JVM参数配置
- 转: Linux与JVM的内存关系分析
- JVM内存配置的再次思考
- 关于JVM堆外内存的一切
- 查看JVM运行时参数
- JVM 内存分配策略
- JVM之指针压缩&内存如何设置
- JVM调优02-内存对象分布与管理
- 记录一次索引未建立、继而引发一系列的问题、包含索引创建失败、虚拟机中JVM虚拟机内存满的情况
- 第5课:实战演示JVM三大性能调优参数:-Xms -Xmx -Xss
- Android性能调优篇之探索JVM内存分配
- JVM学习笔记-内存管理
- 【JVM】JVM系列之内存模型(六)
- jvm系列(一):java类的加载机制
- JVM内存最大能调多大分析【经典】
- 监控JVM内存使用情况,剩余空间小于2M时报警
- 深入理解JVM-内存模型(jmm)和GC
- 【并发编程003】局部变量,对象实例,jvm加载的类,常量及静态变量都存储在内存的什么部位?是线程私有的吗?
- 【jvm我能讲两小时014】验证阶段jvm主要做了什么?
- 【jvm我能讲两小时010】说说class文件中的属性表的理解,以及接触过的属性?