
LANGUAGE TRANSLATION WITH TORCHTEXT
本节翻译在PYTORCH NLP系列最后一文。利用torchtext类来处理一个著名的数据集,包含了一些英文和德文句子。利用该数据处理sequence-to-sequence模型,通过注意力机制,可以将德语翻译成英语。基于 this tutorial from PyTorch community member Ben Trevett and was created by Seth Weidman with Ben’s permission.在文末你会用torchtext类:
Field and TranslationDataset
torchtext可用来实现语言翻译模型。一个主要的类是 Field, 是有关句子处理方式的。另一个是TranslationDataset 。torchtext有许多这样的数据集。在本文,我们利用 Multi30k dataset,其中包含了30000句子(平均长约13个单词)同时有英语和德语。
Note:the tokenization in this tutorial需要 Spacy,我们使用Spacy是因为它在英语以外的语言中为标记化提供了强大的支持。torchtext提供了一个基本的英语标记器,并支持其他英语标记器(例如Moses),但对于语言翻译(需要多种语言)来说,Spacy是最好的选择。
为了运行代码需要安装利用pip或者conda安装sapcy,然后下载数据:
python -m spacy download en
python -m spacy download de
安装好Spacy,以下的代码将基于Field中定义的TranslationDataset 标记每个句子:
from torchtext.datasets import Multi30k from torchtext.data import Field, BucketIterator SRC = Field(tokenize = "spacy", tokenizer_language="de", init_token = '<sos>', eos_token = '<eos>', lower = True) TRG = Field(tokenize = "spacy", tokenizer_language="en", init_token = '<sos>', eos_token = '<eos>', lower = True) train_data, valid_data, test_data = Multi30k.splits(exts = ('.de', '.en'), fields = (SRC, TRG))

定义train_data后,可以看到torchtext的Field的作用:build_vocab方法允许我们创建和每种语言相关的词汇表
SRC.build_vocab(train_data, min_freq = 2)
TRG.build_vocab(train_data, min_freq = 2)
运行这些后,SRC.vocab.stoi将会是一个字典:tokens为键,对应的indices为值。SRC.vocab.itos是同样的字典。
BucketIterator
最后利用BucketIterator,利用TranslationDataset 作为第一个参数。定义一个迭代器,用于将相似长度的示例批处理在一起。在为每个新epoch生产新的洗批量时,最小化所需的填充量。
import torch device = torch.device('cuda' if torch.cuda.is_available() else 'cpu') BATCH_SIZE = 128 train_iterator, valid_iterator, test_iterator = BucketIterator.splits( (train_data, valid_data, test_data), batch_size = BATCH_SIZE, device = device)
这些迭代器类似于DataLoader:
for i, batch in enumerate(iterator):
每个批量有两无属性:
src = batch.src
trg = batch.trg
Defining our nn.Module and Optimizer
这主要是来自torchtext的一个特性:随着数据集的构建和迭代器的定义,本教程的其余部分只是将我们的模型定义为nn.Module和优化器,然后对其进行训练。模型主要follow自: here (you can find a significantly more commented version here)。注意:该模型只是一个可用于语言翻译的示例模型;我们之所以选择它,是因为它是任务的标准模型,而不是因为它是推荐用于翻译的模型。总所周知,最先进的模型当前基于Transformer s;可以在here看到PyTorch实现Transformer层的能力;特别是,下面模型中使用的“注意”不同于Transformer模型中的multi-headed自注意机制。
import random from typing import Tuple import torch.nn as nn import torch.optim as optim import torch.nn.functional as F from torch import Tensor class Encoder(nn.Module): def __init__(self, input_dim: int, emb_dim: int, enc_hid_dim: int, dec_hid_dim: int, dropout: float): super().__init__() self.input_dim = input_dim self.emb_dim = emb_dim self.enc_hid_dim = enc_hid_dim self.dec_hid_dim = dec_hid_dim self.dropout = dropout self.embedding = nn.Embedding(input_dim, emb_dim) self.rnn = nn.GRU(emb_dim, enc_hid_dim, bidirectional = True) self.fc = nn.Linear(enc_hid_dim * 2, dec_hid_dim) self.dropout = nn.Dropout(dropout) def forward(self, src: Tensor) -> Tuple[Tensor]: embedded = self.dropout(self.embedding(src)) outputs, hidden = self.rnn(embedded) hidden = torch.tanh(self.fc(torch.cat((hidden[-2,:,:], hidden[-1,:,:]), dim = 1))) return outputs, hidden class Attention(nn.Module): def __init__(self, enc_hid_dim: int, dec_hid_dim: int, attn_dim: int): super().__init__() self.enc_hid_dim = enc_hid_dim self.dec_hid_dim = dec_hid_dim self.attn_in = (enc_hid_dim * 2) + dec_hid_dim self.attn = nn.Linear(self.attn_in, attn_dim) def forward(self, decoder_hidden: Tensor, encoder_outputs: Tensor) -> Tensor: src_len = encoder_outputs.shape[0] repeated_decoder_hidden = decoder_hidden.unsqueeze(1).repeat(1, src_len, 1) encoder_outputs = encoder_outputs.permute(1, 0, 2) energy = torch.tanh(self.attn(torch.cat(( repeated_decoder_hidden, encoder_outputs), dim = 2))) attention = torch.sum(energy, dim=2) return F.softmax(attention, dim=1) class Decoder(nn.Module): def __init__(self, output_dim: int, emb_dim: int, enc_hid_dim: int, dec_hid_dim: int, dropout: int, attention: nn.Module): super().__init__() self.emb_dim = emb_dim self.enc_hid_dim = enc_hid_dim self.dec_hid_dim = dec_hid_dim self.output_dim = output_dim self.dropout = dropout self.attention = attention self.embedding = nn.Embedding(output_dim, emb_dim) self.rnn = nn.GRU((enc_hid_dim * 2) + emb_dim, dec_hid_dim) self.out = nn.Linear(self.attention.attn_in + emb_dim, output_dim) self.dropout = nn.Dropout(dropout) def _weighted_encoder_rep(self, decoder_hidden: Tensor, encoder_outputs: Tensor) -> Tensor: a = self.attention(decoder_hidden, encoder_outputs) a = a.unsqueeze(1) encoder_outputs = encoder_outputs.permute(1, 0, 2) weighted_encoder_rep = torch.bmm(a, encoder_outputs) weighted_encoder_rep = weighted_encoder_rep.permute(1, 0, 2) return weighted_encoder_rep def forward(self, input: Tensor, decoder_hidden: Tensor, encoder_outputs: Tensor) -> Tuple[Tensor]: input = input.unsqueeze(0) embedded = self.dropout(self.embedding(input)) weighted_encoder_rep = self._weighted_encoder_rep(decoder_hidden, encoder_outputs) rnn_input = torch.cat((embedded, weighted_encoder_rep), dim = 2) output, decoder_hidden = self.rnn(rnn_input, decoder_hidden.unsqueeze(0)) embedded = embedded.squeeze(0) output = output.squeeze(0) weighted_encoder_rep = weighted_encoder_rep.squeeze(0) output = self.out(torch.cat((output, weighted_encoder_rep, embedded), dim = 1)) return output, decoder_hidden.squeeze(0) class Seq2Seq(nn.Module): def __init__(self, encoder: nn.Module, decoder: nn.Module, device: torch.device): super().__init__() self.encoder = encoder self.decoder = decoder self.device = device def forward(self, src: Tensor, trg: Tensor, teacher_forcing_ratio: float = 0.5) -> Tensor: batch_size = src.shape[1] max_len = trg.shape[0] trg_vocab_size = self.decoder.output_dim outputs = torch.zeros(max_len, batch_size, trg_vocab_size).to(self.device) encoder_outputs, hidden = self.encoder(src) # first input to the decoder is the <sos> token output = trg[0,:] for t in range(1, max_len): output, hidden = self.decoder(output, hidden, encoder_outputs) outputs[t] = output teacher_force = random.random() < teacher_forcing_ratio top1 = output.max(1)[1] output = (trg[t] if teacher_force else top1) return outputs INPUT_DIM = len(SRC.vocab) OUTPUT_DIM = len(TRG.vocab) # ENC_EMB_DIM = 256 # DEC_EMB_DIM = 256 # ENC_HID_DIM = 512 # DEC_HID_DIM = 512 # ATTN_DIM = 64 # ENC_DROPOUT = 0.5 # DEC_DROPOUT = 0.5 ENC_EMB_DIM = 32 DEC_EMB_DIM = 32 ENC_HID_DIM = 64 DEC_HID_DIM = 64 ATTN_DIM = 8 ENC_DROPOUT = 0.5 DEC_DROPOUT = 0.5 enc = Encoder(INPUT_DIM, ENC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, ENC_DROPOUT) attn = Attention(ENC_HID_DIM, DEC_HID_DIM, ATTN_DIM) dec = Decoder(OUTPUT_DIM, DEC_EMB_DIM, ENC_HID_DIM, DEC_HID_DIM, DEC_DROPOUT, attn) model = Seq2Seq(enc, dec, device).to(device) def init_weights(m: nn.Module): for name, param in m.named_parameters(): if 'weight' in name: nn.init.normal_(param.data, mean=0, std=0.01) else: nn.init.constant_(param.data, 0) model.apply(init_weights) optimizer = optim.Adam(model.parameters()) def count_parameters(model: nn.Module): return sum(p.numel() for p in model.parameters() if p.requires_grad) print(f'The model has {count_parameters(model):,} trainable parameters')

注意:在对语言翻译模型的性能进行评分时,必须告诉nn.CrossEntropyLoss函数忽略目标只是填充的索引。
PAD_IDX = TRG.vocab.stoi['<pad>'] criterion = nn.CrossEntropyLoss(ignore_index=PAD_IDX)
最后训练和评估:
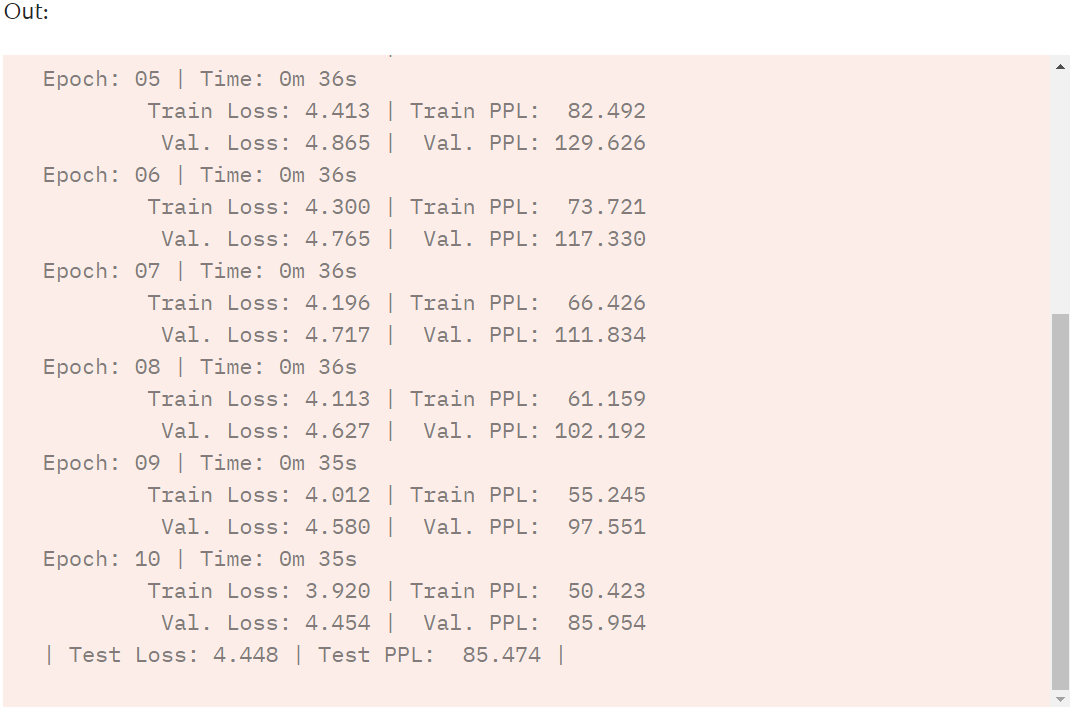
import math import time def train(model: nn.Module, iterator: BucketIterator, optimizer: optim.Optimizer, criterion: nn.Module, clip: float): model.train() epoch_loss = 0 for _, batch in enumerate(iterator): src = batch.src trg = batch.trg optimizer.zero_grad() output = model(src, trg) output = output[1:].view(-1, output.shape[-1]) trg = trg[1:].view(-1) loss = criterion(output, trg) loss.backward() torch.nn.utils.clip_grad_norm_(model.parameters(), clip) optimizer.step() epoch_loss += loss.item() return epoch_loss / len(iterator) def evaluate(model: nn.Module, iterator: BucketIterator, criterion: nn.Module): model.eval() epoch_loss = 0 with torch.no_grad(): for _, batch in enumerate(iterator): src = batch.src trg = batch.trg output = model(src, trg, 0) #turn off teacher forcing output = output[1:].view(-1, output.shape[-1]) trg = trg[1:].view(-1) loss = criterion(output, trg) epoch_loss += loss.item() return epoch_loss / len(iterator) def epoch_time(start_time: int, end_time: int): elapsed_time = end_time - start_time elapsed_mins = int(elapsed_time / 60) elapsed_secs = int(elapsed_time - (elapsed_mins * 60)) return elapsed_mins, elapsed_secs N_EPOCHS = 10 CLIP = 1 best_valid_loss = float('inf') for epoch in range(N_EPOCHS): start_time = time.time() train_loss = train(model, train_iterator, optimizer, criterion, CLIP) valid_loss = evaluate(model, valid_iterator, criterion) end_time = time.time() epoch_mins, epoch_secs = epoch_time(start_time, end_time) print(f'Epoch: {epoch+1:02} | Time: {epoch_mins}m {epoch_secs}s') print(f'\tTrain Loss: {train_loss:.3f} | Train PPL: {math.exp(train_loss):7.3f}') print(f'\t Val. Loss: {valid_loss:.3f} | Val. PPL: {math.exp(valid_loss):7.3f}') test_loss = evaluate(model, test_iterator, criterion) print(f'| Test Loss: {test_loss:.3f} | Test PPL: {math.exp(test_loss):7.3f} |')
Next steps
- Check out the rest of Ben Trevett’s tutorials using
torchtexthere - Stay tuned for a tutorial using other
torchtextfeatures along withnn.Transformerfor language modeling via next word prediction!
相关文章
- 【论文笔记】Street-View Change Detection with Deconvolutional Networks
- Matlab Simulink capabilities with baxter(显示机器人运动状态)
- DETR(Detection with Transformers) 学习笔记
- docker 报Error: docker-engine-selinux conflicts with docker-selinux-1.9.1-25.el7.centos.x86_64
- [JS] ECMAScript 6 - Array : compare with c#
- HOW TO: Synchronize changes when completing a P2V or V2V with VMware vCenter Converter Standalone 5.1
- .Net Core with 微服务 - Consul 配置中心
- 目标检测——detr源码复现【 End-to-End Object Detection with Transformers】
- 自然语言处理NLP星空智能对话机器人系列:深入理解Transformer自然语言处理 KantaiBERT Language modeling with FillMaskPipeline
- Visual studio debug—Process with an Id of 5616 is not running的解决方法
- 2019HDU多校第九场 Rikka with Quicksort —— 数学推导&&分段打表
- Building OpenSSL with Visual Studio
- [LeetCode] 138. Copy List with Random Pointer 拷贝带随机指针的链表