
视觉与语言领域年度进展概述

计算机视觉已经发展了五十多年。在此期间,视觉理解(visual understanding)这一领域取得了长足的进展。为了让机器像人类一样能够“看”懂周围的世界,计算机视觉研究人员设计了大量的人工特征去描述一件物体,并且提出了各种模型去识别这些人为设计的特征。几年前,当我们谈论图像或视频理解时,我们能做的只是给一幅图像或一段视频自动打上一些彼此相互独立的标签(tag)。而今天,我们已经可以借用深度学习的发展将视觉理解这一基础任务再往前推进一步,即将单个的标签变成一段和当前视觉内容相关并且通顺连贯的自然语言描述。
视觉和语言(Vision and Language)其实是一个交叉领域。想要建立视觉和自然语言的桥梁,不仅需要理解视觉,也要知道如何对自然语言进行建模。同时,这个桥梁也可以是双向的,既可以从视觉生成文字(如caption、sentiment、visual question answering等),也可以从文字到视觉(如generation、search)。
最早的一篇做图像语言描述的论文来自于ECCV 2010,此后随着深度学习在视觉任务中的普及,视觉和语言这一新兴领域越来越受到大家的关注,在 CVPR 2015和 CVPR 2016中分别收录了5篇和7篇相关论文。这个领域因为同时涉及了视觉和语言处理,所以CVPR/ICCV/ACL等视觉和语言处理会议中都收录了相关的高质量文章。
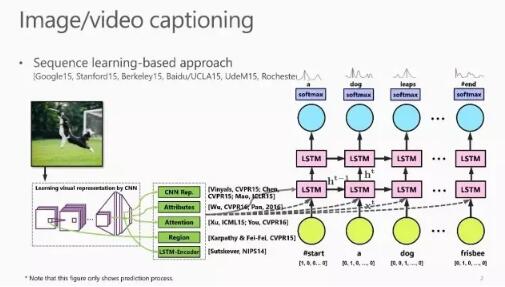
Image Captioning 的基本思路来源于语言翻译,其流程大体是先使用 CNN 对图片进行编码得到视觉特征表示,然后使用 RNN 对这个特征进行解码来生成图像描述。在提取视觉特征时,可以使用高级语义特征和注意力机制等计算机视觉领域常用的方法,也可以直接使用自动编码器进行处理。
Image Captioning方面的工作可以总结为“Image Captioning with X”,其中的 X 可以是 Visual Attention, Visual Attributes, Entity Recognition, Dense Caption 和 Reinforcement Learning等模块。IBM 最近的一篇 CVPR2017文章就在 Image Captioning 任务中使用了增强学习,通过在目标函数中加入 reward optimize function 来实现这一功能。
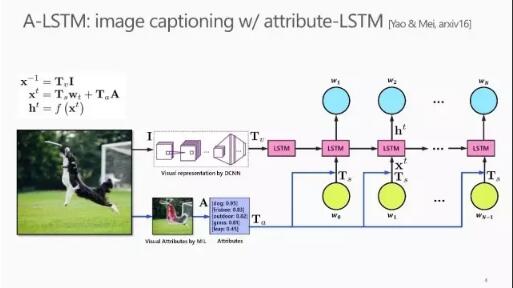
在微软亚洲研究院最新的论文中,我们在现有的CNN-LSTM Translation Model(如图中黑色流程线所示)基础上使用 Multiple Instance Learning 学习图片中一些内在的概念,并将这个语义信息作为 LSTM 的输入对其进行约束以提升性能(如图中蓝色流程线所示)。

Video Captioning 与 Image Captioning 有所不同,当我们要理解视频时,我们不仅要理解每一帧中的物体,也要理解物体在多帧之间的运动。所以,视频理解往往比图像理解更为复杂。主要表现为如下几点:
视频既可以被视为帧流,亦可以视为trimmed video clip: 当被视为帧流的时候,首先将视频帧作为图片,最后对其进行池化操作; 对于trimmed video clip的情况,可以使用时域频域模型来学习视频中的一些行为。视频中还存在音频流和字符流,都可以作为 Video Captioning 的输入特征。例如我们组今年被ACM Multimedia大会接收为ORAL的一篇长文就是设计一个multi-stream LSTM网络对视频的多个模态综合处理产生caption。 在Video Captioning中可以使用不同的池化方式,如基于时间轴的均值池化和最大值池化,还可以使用注意力机制,比如Hard-Attention和Soft-Attention,或者使用编解码的方法对其进行处理。

在我们CVPR2017的一个工作中,我们发现,图片数据集比视频数据集的数量多,内容和语意信息更加丰富。所以我们思考了两个问题:
其一是图像和视频的内容是否互补,我们能否以多任务的形式对 Image captioning 和 Video captioning 这两个任务同时进行处理; 另外一个问题是如何将 Image Captioning 迁移到 Video Captioning 中,在论文中我们使用两个MIL模型分别获取图像和视频的信息,并使用Transfer Unit 进行迁移学习。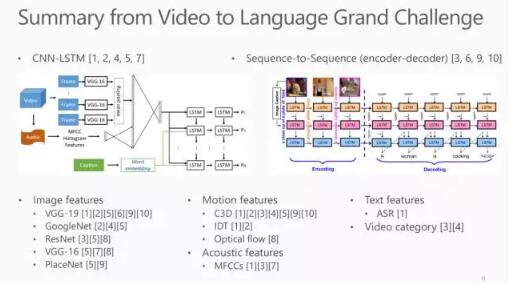
为了更好的促进视觉和语言这一领域的研究,我们在ACM Multimedia 2016和2017举行了微软研究院 ”Video to Language” 挑战赛,并且在今年的CVPR大会上举办了Vision and Language Workshop。
在“Video to Language“挑战赛中,Sequence Learning 是竞赛中最主流的方法。
其中的一个思路是 CNN-LSTM 框架:先使用 CNN 学习图片特征并对其进行不同的处理,最后输入到 LSTM 中得到最终的结果。 另一个思路是编解码框架,其优点是LSTM 模块可以在视频标注上进行端到端的学习。可以使用不同的方法来提取不同的特征:
如可以使用 VGG, GoogLeNet和 ResNet 等深度学习框架提取图片特征; 使用C3D、 IDT 和 Optical Flow来提取动态特征;其他的还有 acoustic features, text features 和 video category 等特征都有助于 Video Captioning 这一任务。

Vision and Language领域中有一个新的问题--Visual Question Answering:给定一张图片,并对图片中的内容进行提问,我们希望计算机能根据图片中的内容对问题给出合理的回答。虽然这个问题有很多人在研究,但是依然不够成熟,还不能应用到真实场景中。

这个问题的处理方法与 Image Captioning相似,如ICCV2015中提出的 baseline 使用的就是LSTM + Image的框架:
先使用 CNN 学习图片蕴含的特征,同时使用 RNN 学习描述问题的句子中包含的特征,然后将这两个特征进行融合,并对使用 Softmax 等方法对其进行处理来得到最终结果。
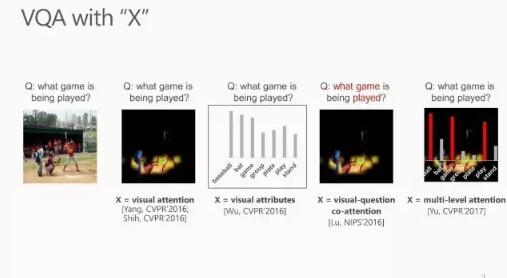
与 Image Captioning 一样,VQA 中的方法也可以总结为 ”VQA with X”。
当 X 是 visual attention 模块时,这个 visual attention 可以从图像中学习,同时也可以从描述问题的句子中学习,这就是 visual-question co-attention。
我们今年被CVPR 2017接收的一篇论文中还提出了 multi-level attention:即先学习一个初始的 attention,然后通过image 中不同 region 之间的关系以及问题中不同词素之间的关系来学习 multi-level attention。
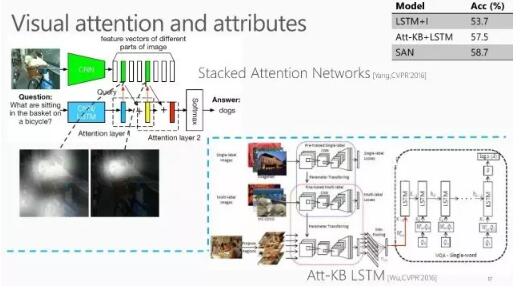
该方法是先使用CNN学习图像的特征表示,然后以迭代的方式使用LSTM对问题进行学习,使得注意力逐步集中到问题关注的方面。他们在VQA 网络中加入Stack Attention这个模块之后,准确率可以从53.7%提升到58%。

过程如下:
1. 首先将描述问题的句子分解为单词;
2. 然后将单词组合为短语;
3. 最后将短语重新组合为句子;
4. 并通过这三个不同尺度的元素来构建问题的特征表示。
结果:
这种通过三个不同尺度的Text Attention和Image Attention学习特征的方法,能逐步将问题的关注点聚集到图像相应区域,最终可以将准确率从58.7%提高到61.8%。

Multi-level Attention是在传统的 Image Attention 框架上,使用 RNN 来学习图片中不同区域之间的关系,并将准确率提高到了65.4%,是所有公开方法中最好的结果。
写在最后:
对图像及视频的理解,从简单的独立标签到连贯的自然语言描述,深度学习只用了几年的时间。可以说,深度学习这项技术,赋予了计算机对单一维度图片数据、以及二维视频数据更强的识别理解能力,在某些方面已逼近人类、甚至超过人类的水平。
近年来,随着大量的视频数据库的开放,如"MSR Video Decription Corpus", "MSR Video to Language (MSR-VTT)", “ActivityNet”等,为这一领域的学术研究带来了长足的进步,同时也衍生出了一些新的研究方向,如VQA等。
然而,相较于学术界的进展,在真实的应用场景中,我们仍面临着技术不够成熟、鲁棒性不足等问题,离真正落地仍有很长的路要走。
今天,深度学习技术为视觉和语言之间搭建了一座桥梁,这将只是一个开始,随着更多维度信息的加入(如语音、文本等),计算机将能够更好地理解这个多维的世界,为人工智能全方位服务人类提供可能。
原文发布时间为: 2017-09-13
本文作者:梅涛
本文来自云栖社区合作伙伴极市网,了解相关信息可以关注极市网。
计算机视觉概述:视觉任务+场景领域+发展历程+典型任务 比如下图,做到的不仅仅是检测到图像前景中有四个⼈、⼀条街道和⼏辆⻋。除了这些基本信息,⼈类还能够看出图像前景中的⼈正在⾛路,其中⼀⼈⾚脚,我们甚⾄知道他们是谁。我们可以理性地推断出图中⼈物没有被⻋撞击的危险,⽩⾊的⼤众汽⻋没有停好。⼈类还可以描述图中⼈物的穿着,不⽌是⾐服颜⾊,还有材质与纹理。⼈类能够理解和描述图像中的场景。
简述智能对话系统 对话系统(Dialogue System,简称DS),是使人与机器可以通过自然语言进行对话交互的系统。DS除了用准确、简洁的自然语言回答用户用自然语言提出的问题外,更注重与人的交互、对人意图的理解、对对话氛围的感知,以及回答的多样性和个性化。
【翻译】开源机器学习流水线工具调研(MLOps)(下) 实施数据科学项目不是一件简单的任务。至少,数据分析工作流程必须定期运行,以产生最新的结果。比如,一份上周数据的报告,或者由于概念发生变化而重新训练机器学习模型。在某些情况下,这类工作流的输出需要作为API公开,例如,一个经过训练的机器学习模型,通过点击REST端点来生成预测结果。 这就需要开发实践允许工作流(也称为pipeline)是可重现、可重复,并且可以很容易地部署。近年来,涌现了大量开源工作流管理工具。由于有太多的选择,团队很难选择最适合他们需求的工具,本文回顾了13种开源工作流管理工具。
机器学习建模高级用法!构建企业级AI建模流水线 ⛵ 机器学习建模高级用法!构建企业级AI建模流水线,不同环节有序地构建成工作流(pipeline)。本文以『客户流失』为例,讲解如何构建 SKLearn 流水线。
BERT是如何理解语言的?谷歌发布交互式平台LIT,解决模型可视化难题 谷歌之前发布的 What-If 工具就是为了应对这一挑战而构建的,它支持对分类和回归模型的黑盒探测,从而使研究人员能够更容易地调试性能,并通过交互和可视化分析机器学习模型的公平性,但是仍然需要一个工具包来解决 NLP 模型特有的挑战。
阿里云机器学习平台PAI-AI行业插件-视觉模拟平台图像分类使用简明教程 AI行业插件提供视觉模型训练插件和通用模型训练插件,他们支持在线标注、自动模型训练、超参优化及模型评估。您只需要准备少量标注数据,并设置训练时长,就可以得到深度优化的模型。同时,插件平台与PAI-EAS高效对接,可以快速将训练模型部署为RESTful服务。视觉模型训练插件支持视觉领域常用模型的标注、训练及发布,并针对移动端场景进行了模型深度优化,您可以通过手机扫码快速体验模型效果,也可以将模型进行服务端部署。本文着重讲述图像分类使用简明教程
Facebook AI 用深度学习实现编程语言转换,代码库迁移不再困难! 从旧式编程语言(例如COBOL)到现代替代语言(例如Java或C ++)的代码库迁移是一项艰巨的任务,Facebook AI开发了Transcoder,这是一个完全自监督的神经转编译器系统,可以使代码迁移变得更加轻松和高效。
相关文章
- AI-蛋白质-序列设计-从头设计-基于AI-2023:ProGen【基于大语言模型】【生物界的ChatGPT】【从功能到氨基酸序列的预测】【训练数据:2.8亿条蛋白质序列】【参数量:12亿】
- 23 DesignPatterns学习笔记:C++语言实现 --- 1.2 AbstractFactory
- 视觉与语言领域年度进展概述
- 《R语言游戏数据分析与挖掘》一1.1 为什么要对游戏进行分析
- 如何使用Java语言实现一个网页爬虫
- 【编程实践】Go 语言中的指针
- day04<Java语言基础+>
- 看懂项目代码需要掌握的技能 (java语言)
- zerglurker的c语言教程006——第一功能
- JP Software CMDebug v27.00.21多语言