
~Linux C_21_ELF文件解析
Outline
- ELF文件解剖
- ~Linux C_5/6/7/12_ELF链接
- 段和节的理解
一、text段、data段和bss段知识介绍(初步了解)
三个段
1、bss(可读可写)
bss是英文Block Started by Symbol的简称,通常是指用来存放程序中未初始化的全局变量的一块内存区域,在程序载入时由内核清0。BSS段属于静态内存分配。它的初始值也是由用户自己定义的连接定位文件所确定,用户应该将它定义在可读写的RAM区内,
源程序中使用malloc分配的内存就是这一块,它不是根据data大小确定,主要由程序中同时分配内存最大值所确定,不过如果超出了范围,也就是分配失败,可以等空间释放之后再分配。
2、text(只读)
text段是程序代码段,在AT91库中是表示程序段的大小,它是由编译器在编译连接时自动计算的,当你在链接定位文件中将该符号放置在代码段后,那么该符号表示的值就是代码段大小,编译连接时,该符号所代表的值会自动代入到源程序中。
3、data(可读可写)
data包含静态初始化的数据,所以有初值的全局变量和static变量在data区。段的起始位置也是由连接定位文件所确定,大小在编译连接时自动分配,它和你的程序大小没有关系,但和程序使用到的全局变量,常量数量相关。
若干节
From: https://www.cnblogs.com/paperfish/p/5341134.html
1.一个典型的ELF可重定位目标文件的格式P451。ELF头(ELF header)以一个16字节的序列开始,这个序列描述了生成该文件的系统的字的大小和字节顺序。ELF头剩下的部分包含帮助链接器语法分析和解释目标文件的信息。
其中包括ELF头的大小、目标文件的类型(如可重定位、可执行或是共享的)、机器类型(如IA32)、节头部表的文件偏移,以及节头部表中的条目大小和数量。不同的节的位置和大小是由节头部表描述的,其中目标文件中每个节都有一个固定大小的条目。
2.夹在ELF头和节头部表之间的都是节。一个典型的ELF可重定位目标文件包含下面几个节:
-
- .text 已编译程序的机器代码
- .rodata 只读数据
- .data 已初始化的全局C变量。局部C变量在运行时保存在栈中,既不出现在.data节中 ,也不出现在.bss节中。
- .bass 未初始化的全局C变量。在目标文件中这个节不占据实际的空间,它仅仅是一个占位符。目标文件格式区分初始化和未初始化变量是为了空间效率:在目标文件中,未初始化变量不需要占据任何实际的磁盘空间。
- .symtab 一个符号表,它存放在程序中定义和引用的函数和全局变量的信息。每个可重定位目标文件在.symtab中都有一张符号表 。
- .rel.text 一个.text节中位置的列表,当链接器吧这个目标文件和其他文件结合时,需要修改这些位置。一般而言,任何调用外部函数或引用全局变量的指令都需要修改。另一方面,调用本地函数的指令则不需要修改。注意,可执行目标文件中并不需要重定位信息,因此通常省略,除非用户显示第指示链接器包含这些信息。
- .rel.data 被模块引用或定义的任何全局变量的重定位信息。一般而言,任何已初始化的全局变量,如果它的初始值是一个全局变量地址或者外部定义函数的地址,都需要被修改。
- .debug 一个调试符号表,其条目是程序总定义的局部变量和类型定义,程序中定义和引用的 全局变量,以及原始的C源文件。
- .line 原始C源文件中的行号和.text节中机器指令之间的映射。
- .strtab 一个字符串表,其内容包括.symtab和.debug节中的符号表,以及节头部中的节名字。
内存分配图
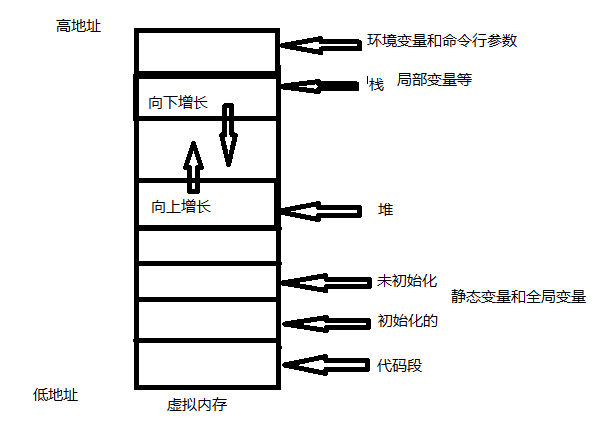
代码段上面应该有个
- .bss:未初始化的全局c变量,不占用实际空间,作占位符使用。
- .data:已初始化的全局c变量,可读可写
- .rodata(read only data):只读数据
- .text: 已编译程序的机器代码
程序的内存分配
一个由C/C++编译的程序占用的内存分为以下几个部分
1、栈区(stack)— 由编译器自动分配释放 ,存放函数的参数值,局部变量的值等。其操作方式类似于数据结构中的栈。
2、堆区(heap) — 一般由程序员分配释放,若程序员不释放,程序结束时可能由OS回收。注意它与数据结构中的堆是两回事,分配方式倒是类似于链表。
3. 全局区(静态区)(static)—,全局变量和静态变量的存储是放在一块的,
初始化的全局变量和静态变量在一块区域(.data段),
未初始化的全局变量和未初始化的静态变量在相邻的另一块区域(.bss段)。 - 程序结束后有系统释放。
注:在采用段式内存管理的架构中(比如intel的80x86系统),.bss段(Block Started by Symbol segment)通常是指用来存放程序中未初始化的全局变量的一块内存区域,一般在初始化时bss段部分将会清零。
bss段属于静态内存分配,即程序一开始就将其清零了。在C语言之类的程序编译完成之后,已初始化的全局变量保存在.data 段中。
4、文字常量区 — 常量字符串就是放在这里的。 程序结束后由系统释放
5、程序代码区 (.text)— 存放函数体的二进制代码。
int a = 0; 全局初始化区 char *p1; 全局未初始化区
main() { int b; 栈 char s[] = "abc"; 栈 char *p2; 栈 char *p3 = "123456"; 123456/0在常量区,p3在栈上 static int c =0; 全局(静态)初始化区 p1 = (char *)malloc(10); p2 = (char *)malloc(20); 分配得来得10和20字节的区域就在堆区。 strcpy(p1, "123456"); 123456/0放在常量区,编译器可能会将它与p3所指向的"123456"优化成一个地方。 }
Heap 和 Stack 的区别
2.1 申请方式
stack:
由系统自动分配。 例如,声明在函数中一个局部变量 int b; 系统自动在栈中为b开辟空间
heap:
需要程序员自己申请,并指明大小,在c中malloc函数
如p1 = (char *)malloc(10);
在C++中用new运算符
如p2 = (char *)malloc(10);
但是注意p1、p2本身是在栈中的。
2.2 申请后系统的响应
栈:只要栈的剩余空间大于所申请空间,系统将为程序提供内存,否则将报异常提示栈溢出。
堆:首先应该知道操作系统有一个记录空闲内存地址的链表,当系统收到程序的申请时,会遍历该链表,寻找第一个空间大于所申请空间的堆结点,然后将该结点从空闲结点链表中删除,并将该结点的空间分配给程序,另外,对于大多数系统,会在这块内存空间中的首地址处记录本次分配的大小,这样,代码中的delete语句才能正确的释放本内存空间。另外,由于找到的堆结点的大小不一定正好等于申请的大小,系统会自动的将多余的那部分重新放入空闲链表中。
2.3申请大小的限制
栈:在Windows下,栈是向低地址扩展的数据结构,是一块连续的内存的区域。这句话的意思是栈顶的地址和栈的最大容量是系统预先规定好的,在 WINDOWS下,栈的大小是2M(也有的说是1M,总之是一个编译时就确定的常数),如果申请的空间超过栈的剩余空间时,将提示overflow。因此,能从栈获得的空间较小。
堆:堆是向高地址扩展的数据结构,是不连续的内存区域。这是由于系统是用链表来存储的空闲内存地址的,自然是不连续的,而链表的遍历方向是由低地址向高地址。堆的大小受限于计算机系统中有效的虚拟内存。由此可见,堆获得的空间比较灵活,也比较大。
2.4申请效率的比较:
栈:由系统自动分配,速度较快。但程序员是无法控制的。
堆:是由new分配的内存,一般速度比较慢,而且容易产生内存碎片,不过用起来最方便.
另外,在WINDOWS下,最好的方式是用VirtualAlloc分配内存,他不是在堆,也不是在栈是直接在进程的地址空间中保留一快内存,虽然用起来最不方便。但是速度快,也最灵活
2.5堆和栈中的存储内容
栈:在函数调用时,第一个进栈的是主函数中后的下一条指令(函数调用语句的下一条可执行语句)的地址,然后是函数的各个参数,在大多数的C编译器中,参数是由右往左入栈的,然后是函数中的局部变量。注意静态变量是不入栈的。
当本次函数调用结束后,局部变量先出栈,然后是参数,最后栈顶指针指向最开始存的地址,也就是主函数中的下一条指令,程序由该点继续运行。
堆:一般是在堆的头部用一个字节存放堆的大小。堆中的具体内容有程序员安排。
2.6存取效率的比较
char s1[] = "aaaaaaaaaaaaaaa";
char *s2 = "bbbbbbbbbbbbbbbbb";
aaaaaaaaaaa是在运行时刻赋值的;
而bbbbbbbbbbb是在编译时就确定的;
但是,在以后的存取中,在栈上的数组比指针所指向的字符串(例如堆)快。
二、elf文件格式与动态链接库(非常之好)-----不可不看(例子说明)
Unix系统里的两种重要的格式:a.out和elf(Executable and Linking Format)。
这两种格式中都有符号表(symbol table),其中包括所有的符号(程序的入口点还有变量的地址等等)。在elf格式中符号表的内容会比a.out格式的丰富的多。但是这些符号表可以用 strip工具去除,这样的话这个文件就无法让debug程序跟踪了,但是会生成比较小的可执行文件。a.out文件中的符号表可以被完全去除,但是 elf中的在加载运行是起着重要的作用,所以用strip永远不可能完全去除elf格式文件中的符号表。但是用strip命令不是完全安全的,比如对未连接的目标文件来说如果用strip去掉符号表的话,会导致连接器无法连接。
列出ELF文件的头信息
$:readelf -h hello.o
ELF Header:
Magic: 7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00
Class: ELF32 Data: 2's complement, little endian
Version: 1 (current)
OS/ABI: UNIX - System V ABI Version: 0
Type: REL (Relocatable file)
Machine: Intel 80386
Version: 0x1
Entry point address: 0x0
Start of program headers: 0 (bytes into file)
Start of section headers: 256 (bytes into file)
Flags: 0x0
Size of this header: 52 (bytes)
Size of program headers: 0 (bytes)
Number of program headers: 0
Size of section headers: 40 (bytes)
Number of section headers: 11
Section header string table index: 8
Magic:字段是一个标识符,只要Magic字段是7f 45 4c 46 01 01 01 00 00 00 00 00 00 00 00 00的文件都是elf文件。
Class:字段是表示elf的版本,这是一个32位的elf。
Machine:字段是指出目标文件的平台信息,这里是 I386兼容平台。
其他的字段可以从其字面上看出它的意义,这里就不一一解释了。
列出段的头信息
$:readelf -S hello.o
There are 11 section headers, starting at offset 0x100:
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 0] NULL 00000000 000000 000000 00 0 0 0
[ 1] .text PROGBITS 00000000 000034 00002a 00 AX 0 0 4
[ 2] .rel.text REL 00000000 000370 000010 08 9 1 4
[ 3] .data PROGBITS 00000000 000060 000000 00 WA 0 0 4
[ 4] .bss NOBITS 00000000 000060 000000 00 WA 0 0 4
[ 5] .rodata PROGBITS 00000000 000060 00000e 00 A 0 0 1
[ 6] .note.GNU-stack PROGBITS 00000000 00006e 000000 00 0 0 1
[ 7] .comment PROGBITS 00000000 00006e 00003e 00 0 0 1
[ 8] .shstrtab STRTAB 00000000 0000ac 000051 00 0 0 1
[ 9] .symtab SYMTAB 00000000 0002b8 0000a0 10 10 8 4
[10] .strtab STRTAB 00000000 000358 000015 00 0 0 1
Key to Flags: W (write), A (alloc), X (execute), M (merge), S (strings) I (info), L (link order), G (group), x (unknown) O (extra OS processing required) o (OS specific), p (processor specific)
Name字段显示的是各个段的名字,
Type显示段的属性,
Addr是每个段载入虚拟内存的位置,
Off是每个段在目标文件中的偏移位置,
Size是每个段的大小,后面的一些字段是表示段的可写,可读,或者可执行。
列出ELF文件中的 Relocation
$:readelf -r hello.o
Relocation section '.rel.text' at offset 0x370 contains 2 entries: Offset Info Type Sym.Value Sym. Name 0000001f 00000501 R_386_32 00000000 .rodata 00000024 00000902 R_386_PC32 00000000 printf
在.text段中有两个relocation,其中之一就是printf函数的relcation。
Offset指出当relocation时要把 printf函数的入口地址贴到离.text段开头00000024处。
列出链接后的可执行文件
$:gcc hello.o
$:readelf -S a.out
There are 32 section headers, starting at offset 0xbc4:
Section Headers:
[Nr] Name Type Addr Off Size ES Flg Lk Inf Al
[ 0] NULL 00000000 000000 000000 00 0 0 0
[ 1] .interp PROGBITS 08048134 000134 000013 00 A 0 0 1
[ 2] .note.ABI-tag NOTE 08048148 000148 000020 00 A 0 0 4
[ 3] .hash HASH 08048168 000168 00002c 04 A 4 0 4
[ 4] .dynsym DYNSYM 08048194 000194 000060 10 A 5 1 4
[ 5] .dynstr STRTAB 080481f4 0001f4 000060 00 A 0 0 1
[ 6] .gnu.version VERSYM 08048254 000254 00000c 02 A 4 0 2
[ 7] .gnu.version_r VERNEED 08048260 000260 000020 00 A 5 1 4
[ 8] .rel.dyn REL 08048280 000280 000008 08 A 4 0 4
[ 9] .rel.plt REL 08048288 000288 000010 08 A 4 11 4
[10] .init PROGBITS 08048298 000298 000017 00 AX 0 0 4
[11] .plt PROGBITS 080482b0 0002b0 000030 04 AX 0 0 4
[12] .text PROGBITS 080482e0 0002e0 0001b4 00 AX 0 0 16
[13] .fini PROGBITS 08048494 000494 00001a 00 AX 0 0 4
[14] .rodata PROGBITS 080484b0 0004b0 000016 00 A 0 0 4
[15] .eh_frame PROGBITS 080484c8 0004c8 000004 00 A 0 0 4
[16] .ctors PROGBITS 080494cc 0004cc 000008 00 WA 0 0 4
[17] .dtors PROGBITS 080494d4 0004d4 000008 00 WA 0 0 4
[18] .jcr PROGBITS 080494dc 0004dc 000004 00 WA 0 0 4
[19] .dynamic DYNAMIC 080494e0 0004e0 0000c8 08 WA 5 0 4
[20] .got PROGBITS 080495a8 0005a8 000004 04 WA 0 0 4
[21] .got.plt PROGBITS 080495ac 0005ac 000014 04 WA 0 0 4
[22] .data PROGBITS 080495c0 0005c0 00000c 00 WA 0 0 4
[23] .bss NOBITS 080495cc 0005cc 000004 00 WA 0 0 4
[24] .comment PROGBITS 00000000 0005cc 0001b2 00 0 0 1
[25] .debug_aranges PROGBITS 00000000 000780 000058 00 0 0 8
[26] .debug_info PROGBITS 00000000 0007d8 000164 00 0 0 1
[27] .debug_abbrev PROGBITS 00000000 00093c 000020 00 0 0 1
[28] .debug_line PROGBITS 00000000 00095c 00015a 00 0 0 1
[29] .shstrtab STRTAB 00000000 000ab6 00010c 00 0 0 1
[30] .symtab SYMTAB 00000000 0010c4 000510 10 31 56 4
[31] .strtab STRTAB 00000000 0015d4 000322 00 0 0 1
Key to Flags: W (write), A (alloc), X (execute), M (merge), S (strings) I (info), L (link order), G (group), x (unknown) O (extra OS processing required) o (OS specific), p (processor specific)
这里的段比目标文件hello.o的段要多的多,这是因为这个程序需要elf的一个动态连接库libc.so.1。
在这里需要简单的介绍一下内核加载 elf可执行文件。内核先是把整个文件加载到用户的虚拟内存空间,如果程序是与动态连接库连接的,则程序中就会包含动态连接器的名称,可能是 /lib/elf/ld-linux.so.1。(动态连接器本身也是一个动态连接库)
在文件的尾部的一些段的Addr值是00000000,因为这些都是符号表,动态连接器并不把这些段的内容加载到内存中。
. interp段中只是储存这一个ASCII的字符串,它就是动态连接器的名字(路径)。
.hash, .dynsym, .dynstr 这三个段是用于动态连接器执行relocation时的符号表。
.hash是一个哈希表,可以让我们很快的从.dynsym中找到所需的符号。
.plt段中储存着我们调用动态连接库中的函数入口地址,在默认状态下,程序初始化时,.plt中的指针并不是指向正确的函数入口地址的而是指向动态连接器本身,当你在程序中调用某个动态连接库中的函数时,连接器会找到那个函数在动态连接库中的位置,再把这个位置连接到.plt段中。这样做的好处是如果在程序中调用了很多动态连接库中的函数,会花费掉连接器很长时间把每个函数的地址连接到.plt段中。所以就可以采用连接器只是把要用的函数地址连接进去,以后要用的再连接。但是也可以设置环境变量LD_BIND_NOW=1让连接器在程序执行前把所有的函数地址都连接好,这主要是方便调试程序。
一个简单的动态连接库的例子
一段代码
Dyn_hello.c
int main(void) { hi(); }
hi.c
#include hi() { printf("Hello world\n"); }
动态库文件
$:gcc -fPIC -c hi.c $:gcc -shared -o libhi.so hi.o
生成了 libhi.so 的文件。
第一种方法
主程序可执行文件
$:gcc -c Dyn_hello.c $:gcc -o Dyn_hello Dyn_hello.o -L. -lhi
生成了 Dyn_hello 文件
执行程序
$:LD_LIBRARY_PATH=. ./Dyn_hello
指出当前目录是连接器的搜索目录。
第二种方法
代码段
#include int main (int argc, char *argv[]) { void (*hi) (); void *m;
if (argc > 2) exit (0);
m = dlopen (argv[1], RTLD_LAZY); if (!m) exit (0); hi = dlsym (m, "hi"); if (hi) { (*hi) (); } dlclose (m); }
主程序可执行文件
$:gcc -c Dl_hello.c $:gcc -o Dl_hello Dl_hello.o -ldl
生成了 Dl_hello 文件
执行程序
$:./Dl_hello ./libhi.so
End.
相关文章
- linux查看CPU架构以及CPU架构介绍
- 网页瞬间转换成桌面应用级程序(IOS/Win/Linux)
- 如何在安装双启动后卸载 Windows 或者 Linux
- 如何在 Linux 和 Windows 之间共享 Steam 的游戏文件
- 解析Linux特殊文件【转】
- Linux expect介绍和用法
- Linux软件包管理基本操作与技巧
- Linux的桌面虚拟化技术KVM(四)——虚拟机镜像格式对比与转换
- Linux命令之groupadd
- Linux 内核/sbin/hotplug 工具
- linux统计当前路径下的文件数量
- Linux C 读取文件夹下所有文件(包括子文件夹)的文件名
- 【Linux篇<Day12>】——逻辑卷管理、VDO卷、RAID磁盘阵列、进程管理
- 【正点原子Linux连载】第六十六章 Linux CAN驱动实验 -摘自【正点原子】I.MX6U嵌入式Linux驱动开发指南V1.0
- Linux驱动开发中的中间件:设备树
- windows通过使用xShell远程linux上传文件
- Linux 目录和文件管理的命令
- Linux输入输出重定向和文件查找值grep命令
- 定时删除日志文件---linux定时清理日志
- Linux - 如何使用debugfs
- 记一次有惊无险的Linux数据恢复过程
- Linux(Centos7)安装tomcat8