
2.描述统计详解
详解
2023-09-27 14:23:04 时间
1.描述统计概述
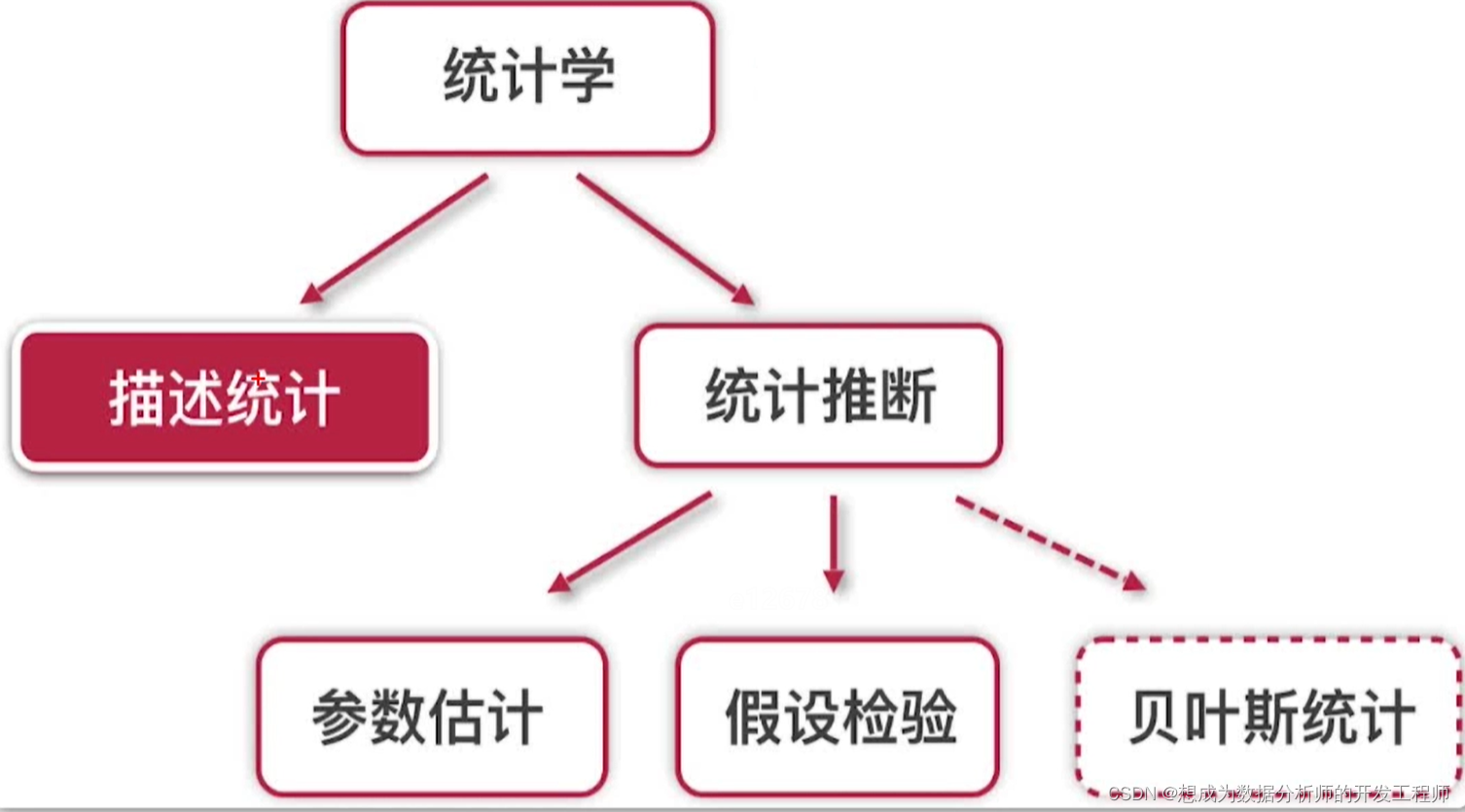
1.1 什么是描述性统计
描述统计是研究
- 如何取得反映客观现象的数据(数据的收集)
- 通过图表形式对数据进行加工处理和可视化
- 通过概括与分析得出反映客观现象的规律性数量特征
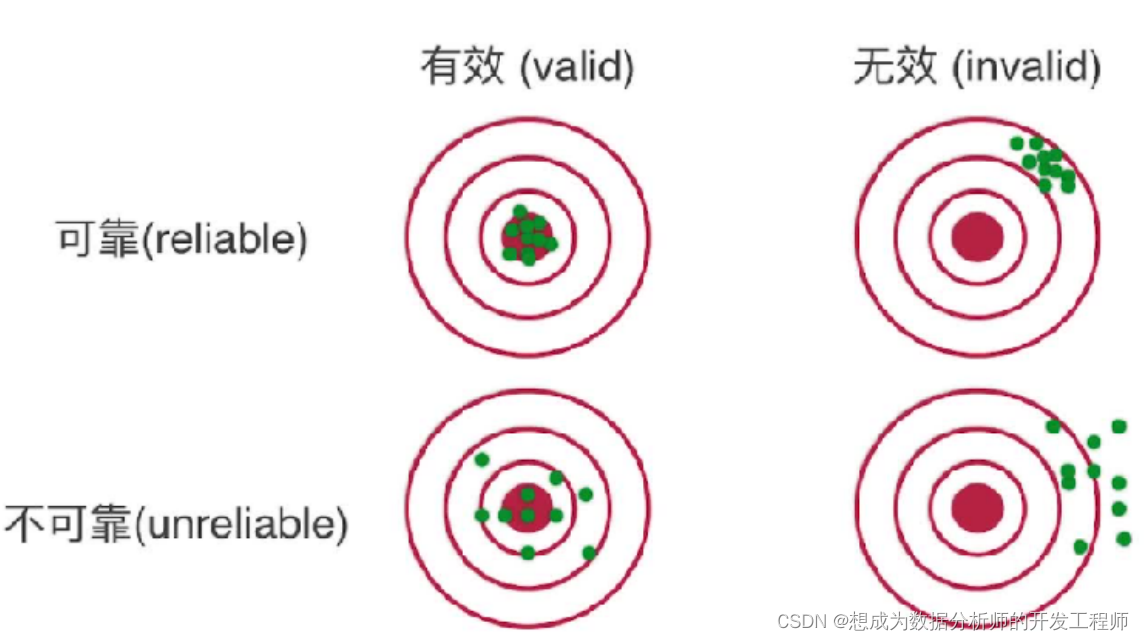
1.2 数据的有效性和可靠性
既然描述统计首先需要进行数据的收集,那么数据的有效性(valid)
和可靠性(reliable)就非常重要了
- 有效性
实际测量的对象=希望测量的对象 - 可靠性
多次测量得到的数据是否一致
2.分类变量的描述
2.1 无序分类变量的描述
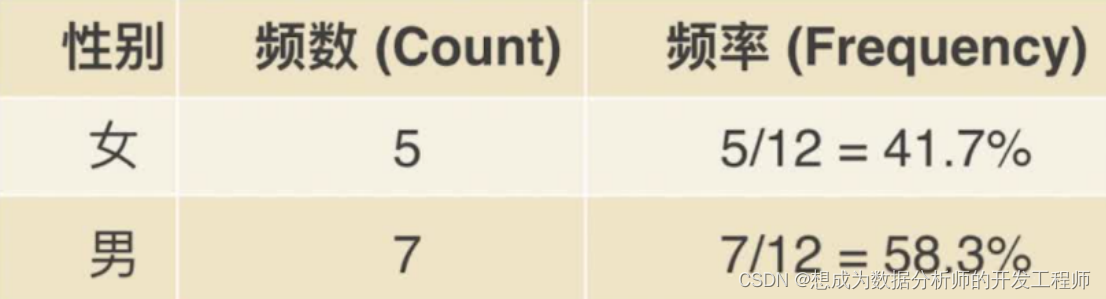
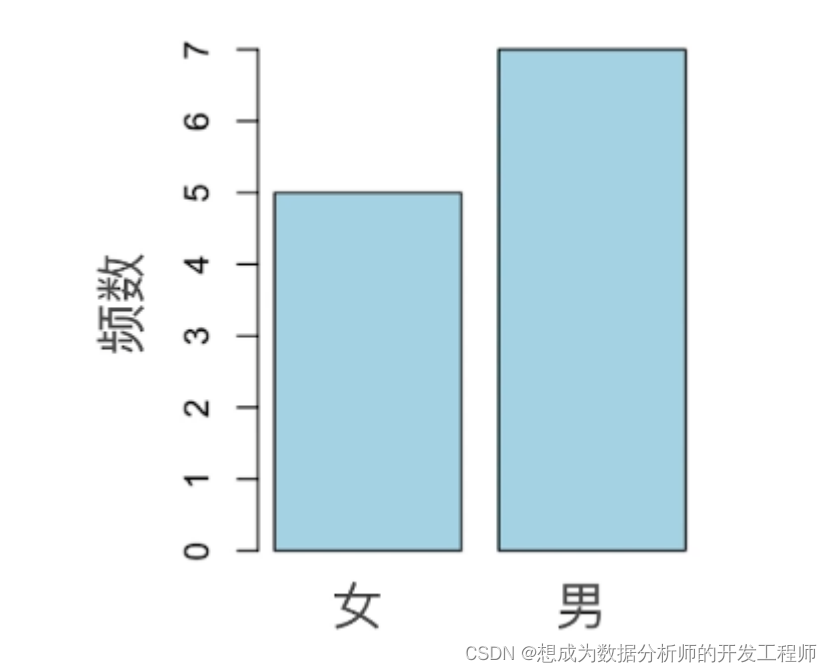
以性别为例:
现在有12个新生儿,他们的性别是:女,男,女,女,男,男,
男,男,女,男,男,女
-
频率表
-
条形图
-
集中趋势描述
众数:一组观测值中出现次数最多的数
例如:
颜色数据:赤1,橙1,黄1,绿1,青1,蓝1,紫1 不存在众数
颜色数据:赤2,橙6,黄1,绿10,青3,蓝10,紫4 存在多个众数
注意:
一组观测值中,可能存在一个或多个众数,也可能不存在众数
2.2 有序分类变量的描述
以教育程度为例:
小学(1),初中(2),高中(3),本科(4),研究生(5)
观测19个人的教育程度(n=19)
3,3,4,1,5,4,2,1,5,4,4,4,5,3,2,1,4,5,5
-
频率表

-
条形图
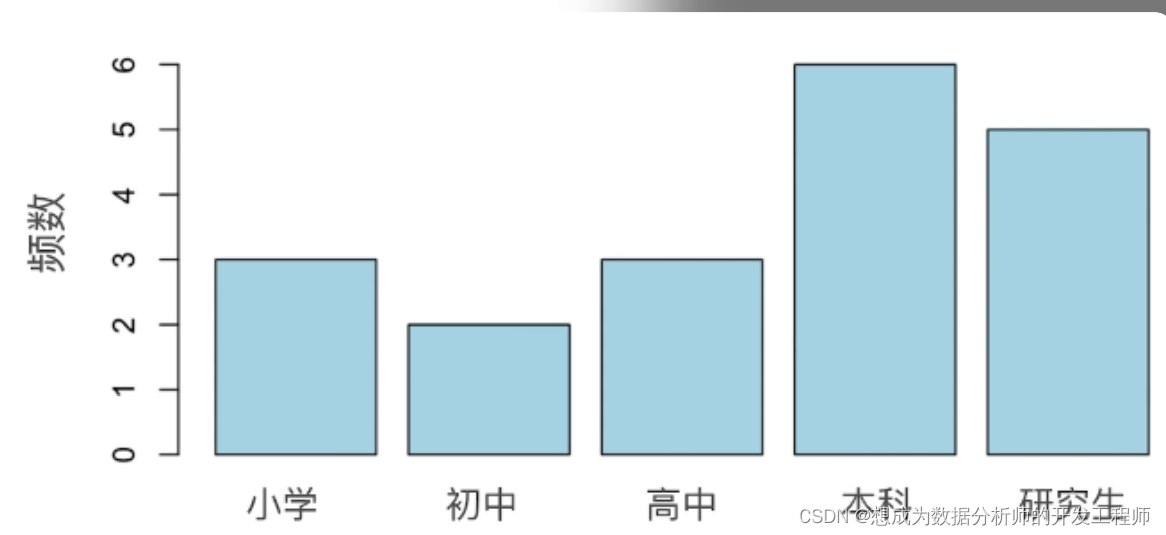
-
集中趋势
众数 ——>本科
中位数:对于有限的数集,把所有观测值按大小排序后,位于正中间的观测值即为中位数
2.3 总结

3.等距数值变量的描述
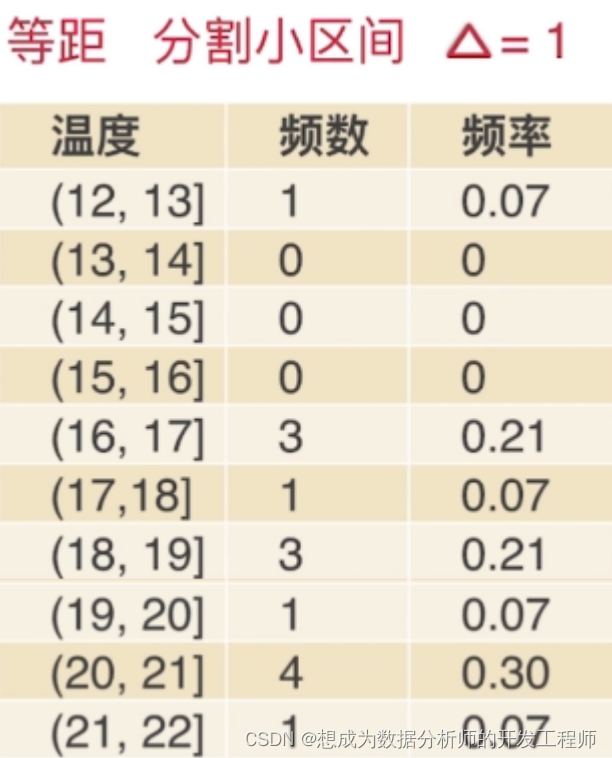
以一组摄氏温度数据(等距数值变量)为例:19,22,21,17,13,19,18,17,17,21,21,21,19,20 (n=14)
- 频率表
可以对数值变量进行小区间的分割,从而制作频率表
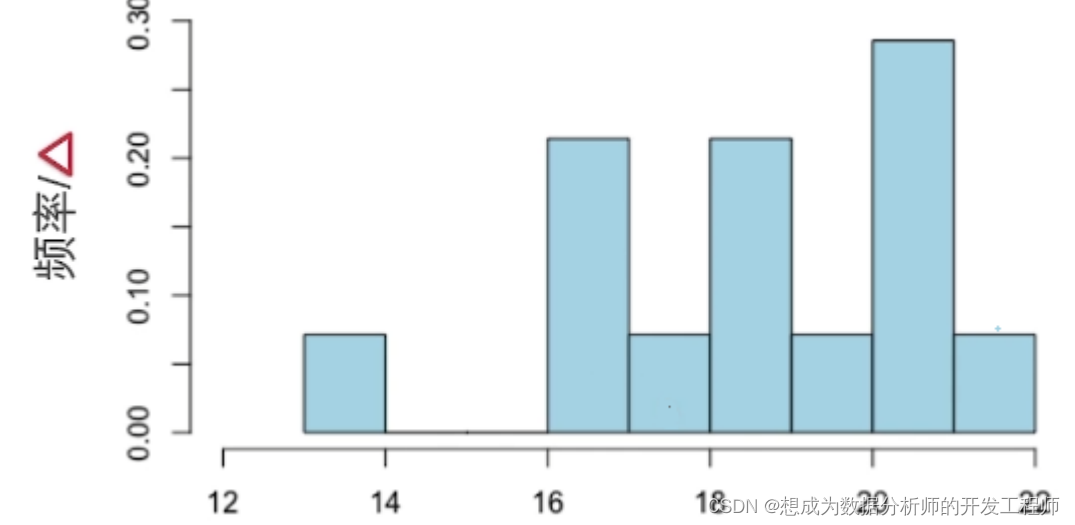
- 频率直方图
数值变量的频率直方图的纵坐标为"频率/间距",横轴为"间距",这样每个长方形的面积就是频率,所有长方形的面积和为1
- 集中趋势
中位数:是将全体数据按大小顺序排列,在整个数列中处于中间位置的那个值均值:在一组数据中,所有数据之和再除以这组数据的个数,所得即为这组数据的均值
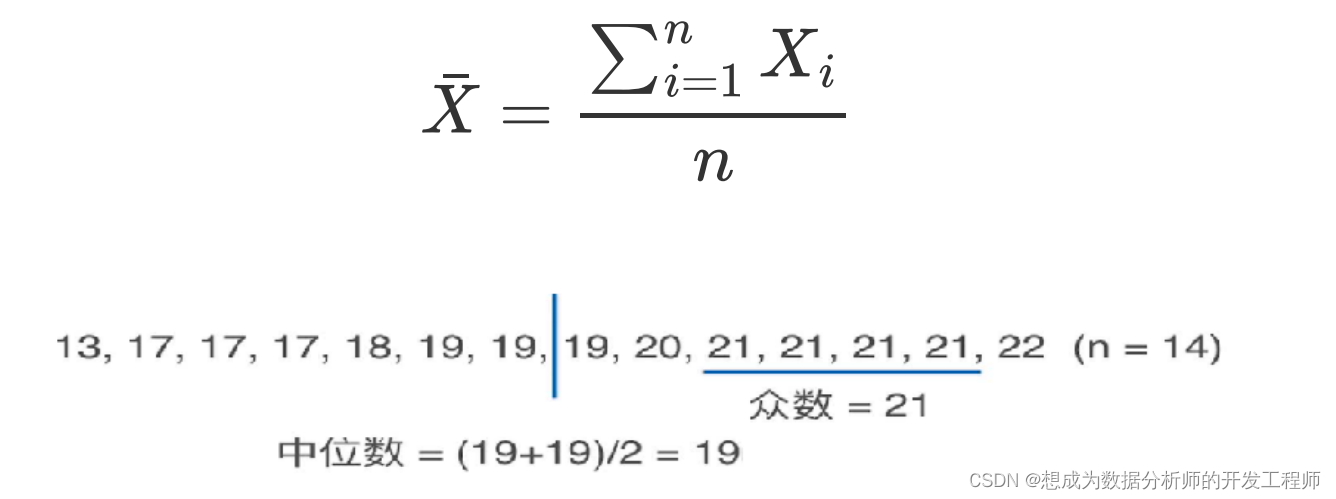
- 离散趋势:观测值偏离其中心的趋势
极差(全距): 最大值减去最小值,可以简单描述数据的范围
大小;
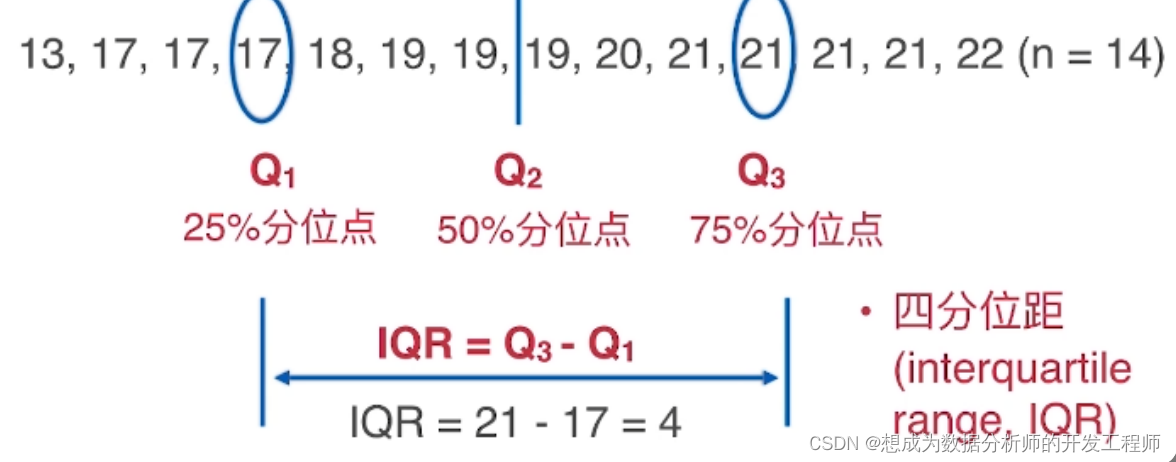
分位数(分位点):把数据n等分的分割点

四分位数:
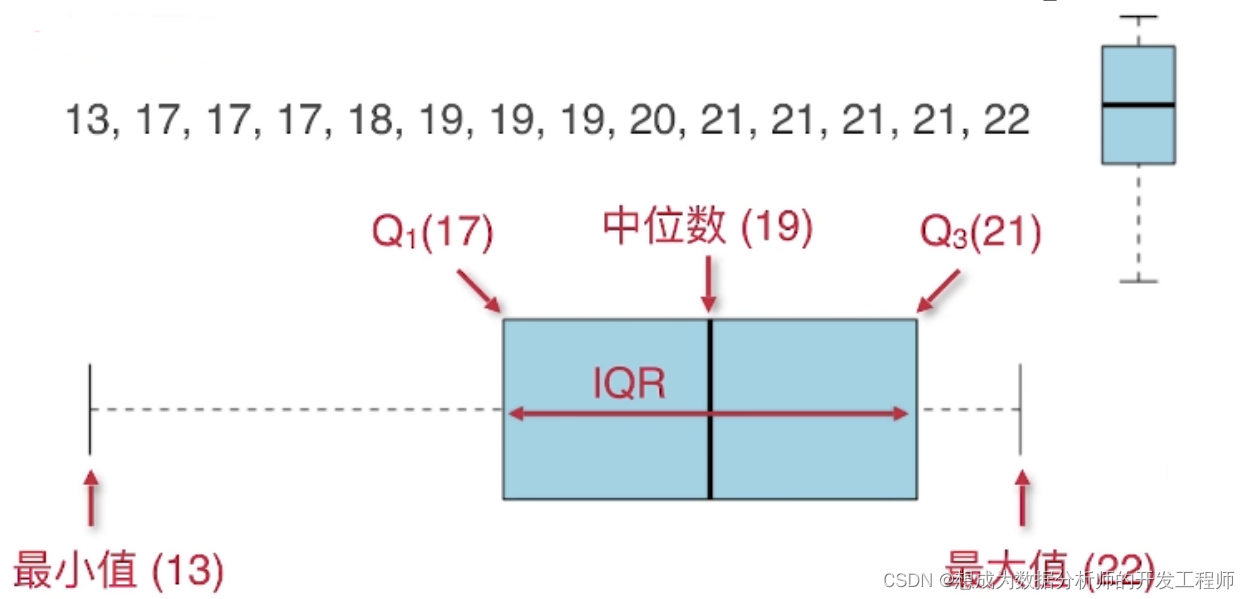
- 箱线图
4.等比数值变量的描述

- 方差
每一个观测值与均值之间的差异的平方和的平均数
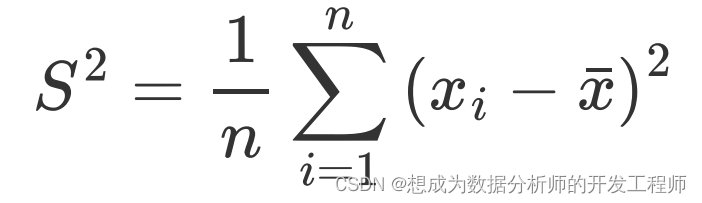
- 标准差
标准差是方差开根号的结果,标准差与原观测值具有相同的单位
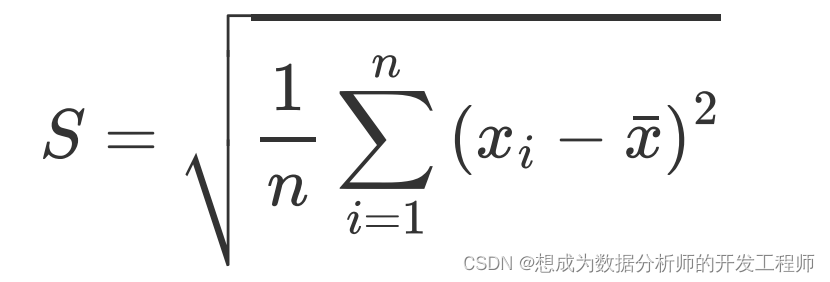
注意:
本节课学习的方差公式与后面章节(统计推断)学习的样本方差公式的分母不一样,样本方差的分母是n-1,具体知识后面介绍
5.数值变量的描述统计
5.1 基于pandas的描述统计(pandas汇总函数)
- 常用的汇总函数(经常与分组数据一起使用)
count() Number of non-null observations
size() group sizes
sum() Sum of values
mean() Mean of values
median() Arithmetic median of values
min() Minimum
max() Maximum
std() Unbiased standard deviation
var() Unbiased variance
import pandas as pd
import scipy.stats as ss
import matplotlib
# 解决绘图的兼容问题
%matplotlib inline
matplotlib.rcParams['font.sans-serif'] =
['SimHei']
5.2 2. describe命令
df.describe( percentiles : 需要输出的百分位数,列表格式提供,如[.25, .5, .75]
include = 'None' : 要求纳入分析的变量类型白名单None (default) : 只纳入数值变量列A
list-like of dtypes :
列表格式提供希望纳入的类型
'all' : 全部纳入
exclude : 要求剔除出分析的变量类型黑名单,选项同上
)
6.常用软件包介绍
6.1 SciPy介绍
SciPy是什么
- SciPy是一个开源的Python算法库和数学工具包
- Scipy是基于Numpy的科学计算库,用于数学、课学、工程学等领域
SciPy官网地址
6.2 statsmodels介绍
statsmodels是什么
- statsmodels是一个Python软件包,为SciPy提供了补充,以进行统计计算,包括描述性统计以及统计模型的估计和推断
- statsmodels是擅长进行核心统计的库。这个多功能库混合了许多 Python 库的功能
statsmodels的使用方式
statsmodels有很多使用方式,这里仅举一例:
statsmodels的DescrStatsW类不仅可以用于进行变量的统计描述,更是进一步进行各种比较的基础对象。
class statsmodels.stats.weightstats.DescrStatsW(
data : 希望分析的一维数组或者二维数据框
weights = None : 案例权重,总和应当等于样本量
ddof = 0 : 用于计算第二统计量的校正自由度,罕用
)
6.3 Pandas介绍
这个可以查看博客:数据分析-数据管理
6.4 Anaconda介绍
同上