
7.Python(pandas)处理数据集的分组、聚合、合并数据集、生成虚拟变量、数值变量分段等操作
2023-09-27 14:23:04 时间
1.Pandas生成虚拟变量
虚拟变量,也叫哑变量和离散特征编码,可用来表示分类变量、非数量因素可能产生的影响。
pd.get_dummies(
data :希望转换的数据框/变量列
prefix = None :哑变量名称前缀
prefix_sep = 11 :前缀和序号之间的连接字符,设定有
prefix 或列名时生效
dummy_na = False :是否为 NaNs 专门设定一个哑变量列
columns = None :希望转换的原始列名,如果不设定,则转换
所有符合条件的列
drop_first = False :是否返回 k-l 个哑变量,而不是 k 个哑变量
)#返回值为数据框
import pandas as pd
df = pd.read_excel('stu_data.xlsx')
# 生成单独的虚拟变量
pd.get_dummies(df.软件,'pre')
# 在数据表中添加虚拟变量
pd.get_dummies(df,columns=['课程'])
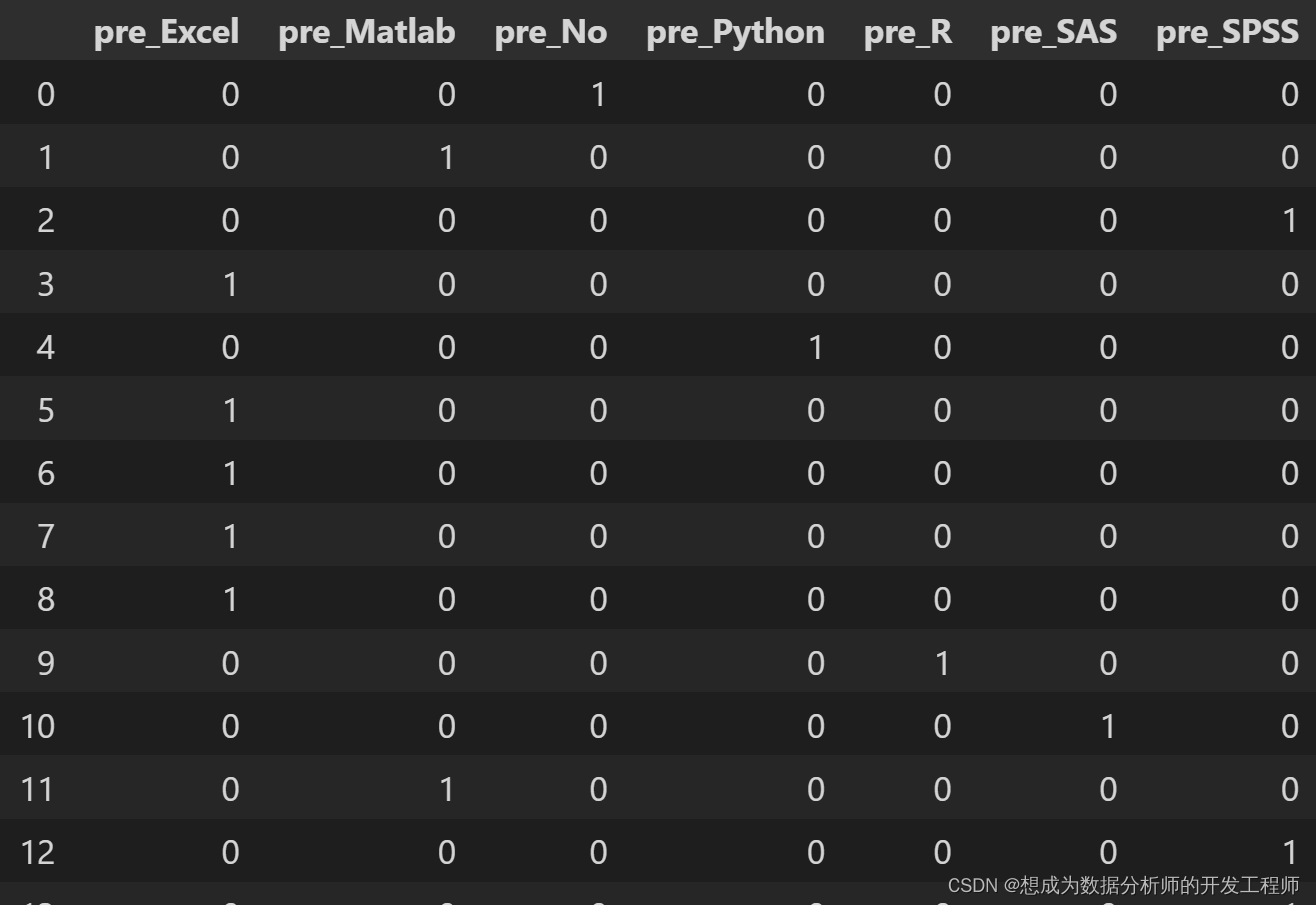
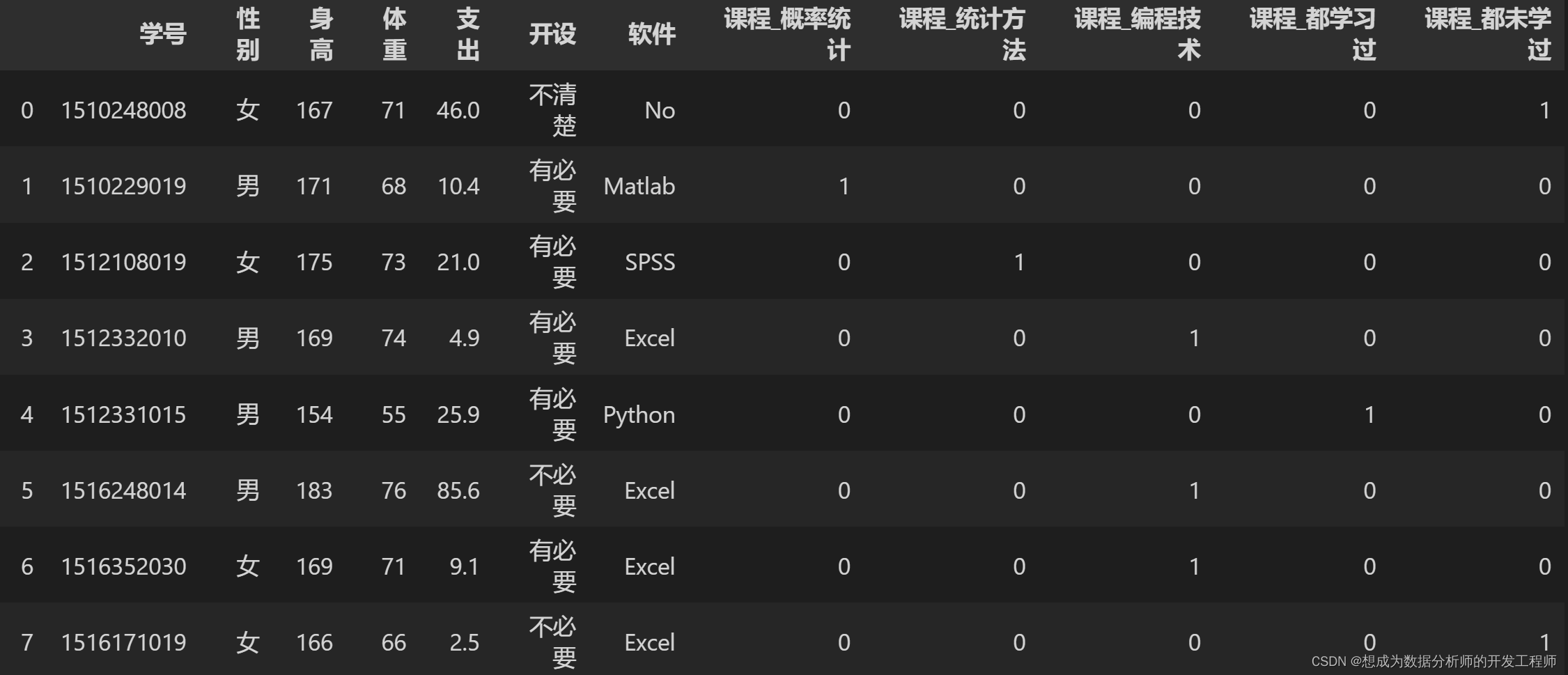
2.Pandas数值变量分段
pd.cut(
X :希望逬行分段的变量列名称
bins :具体的分段设定
int :被等距等分的段数
sequence of scalars :具体的每一个分段起点,必须包括最值,可不等距
right = True :每段是否包括右侧界值
labels = None :为每个分段提供自定义标签
include_lowest = False :第一段是否包括最左侧界值,需要和
right 参数配合
)#分段结果是数值类型为 Categories 的序列
pd.qcut # 按均值取值范围进行等分
import pandas as pd
df = pd.read_excel('stu_data.xlsx')
# qcut 指定列,平均分几段
pd.qcut(df.身高, q=3) # 这样的方式,显示出每一行的数据属于哪个区间中,共分3个区间
# 分类数据加入DataFrame中
df['cut1'] = pd.qcut(df.身高,q=3)
df
# 按照指定区间进行分类,返回每个行属于哪个区间, right:右边是开区间
pd.cut(df.身高, bins=[150,160,170,180,190],right=False)
df["cut2"] = pd.cut(df.身高, bins=[150,160,170,180,190],right=False)
df

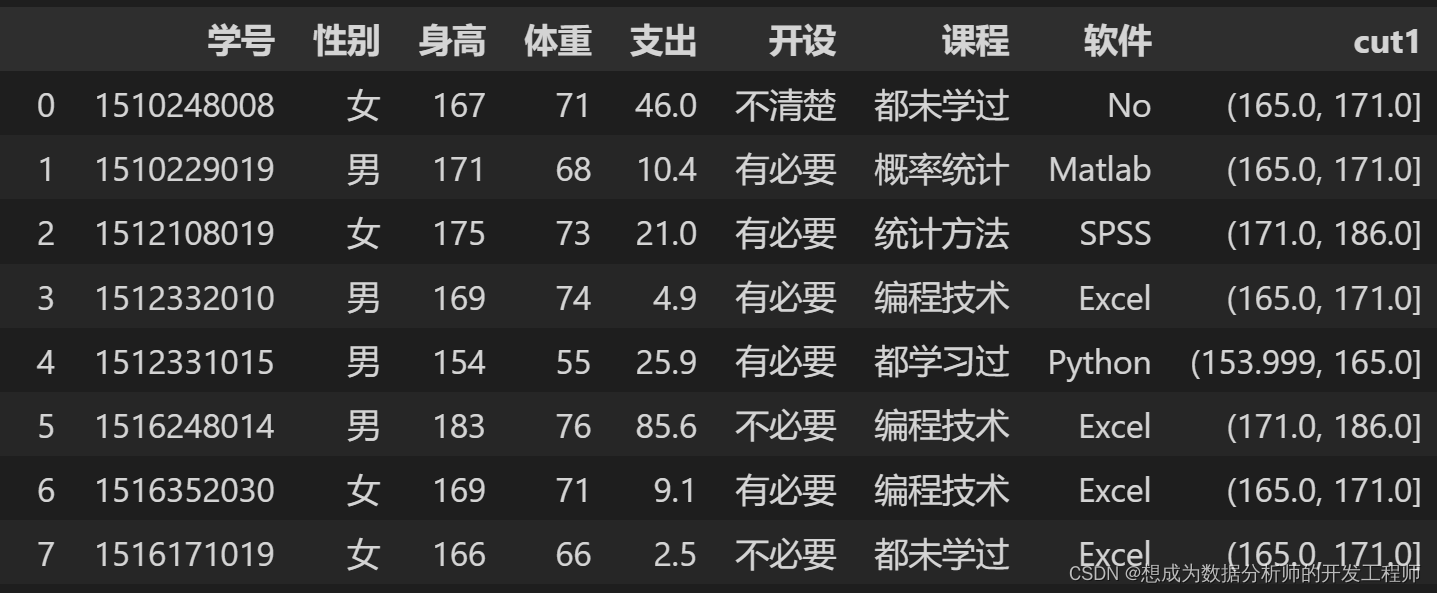

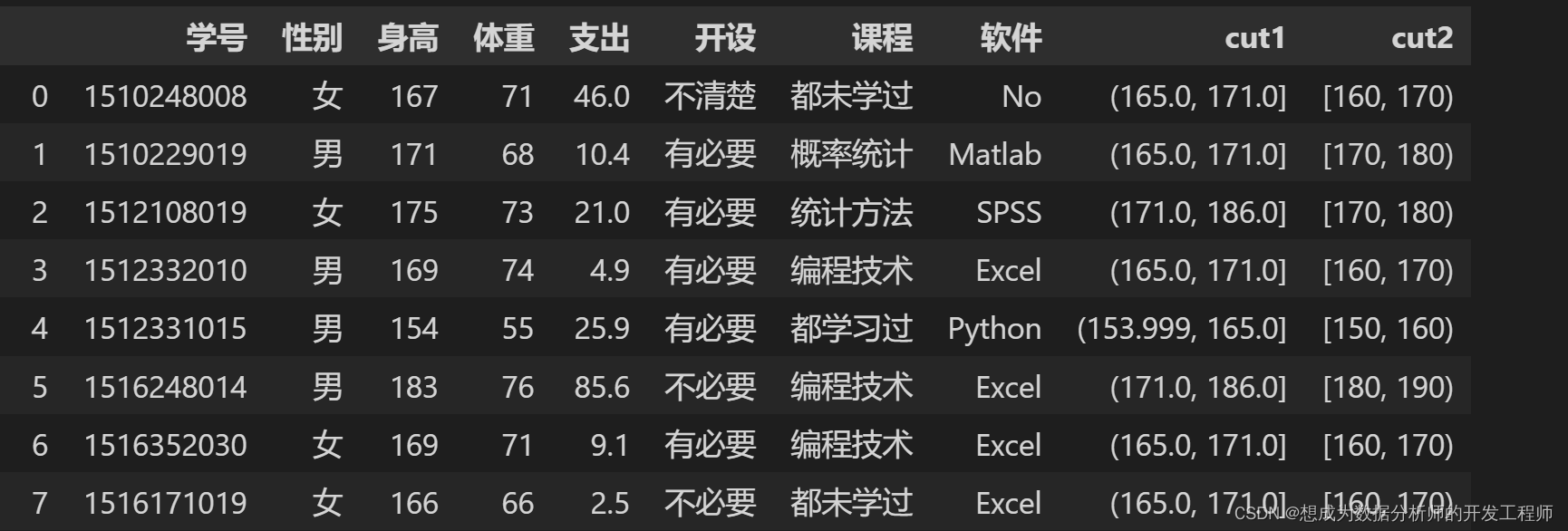
3.Pandas数据分组
df.groupby(
by :用于分组的变量名/函数
level = None :相应的轴存在多重索引时,指定用于分组的级别
as_index = True :在结果中将组标签作为索引
sort = True :结果是否按照分组关键字逬行排序
)#生成的是分组索引标记,而不是新的 df
筛选出其中一组
dfgroup.get_group()
import pandas as pd
df = pd.read_excel('stu_data.xlsx')
# 分组 groupby
dfg = df.groupby('课程') # 返回一个DataFrameGroup分组对象
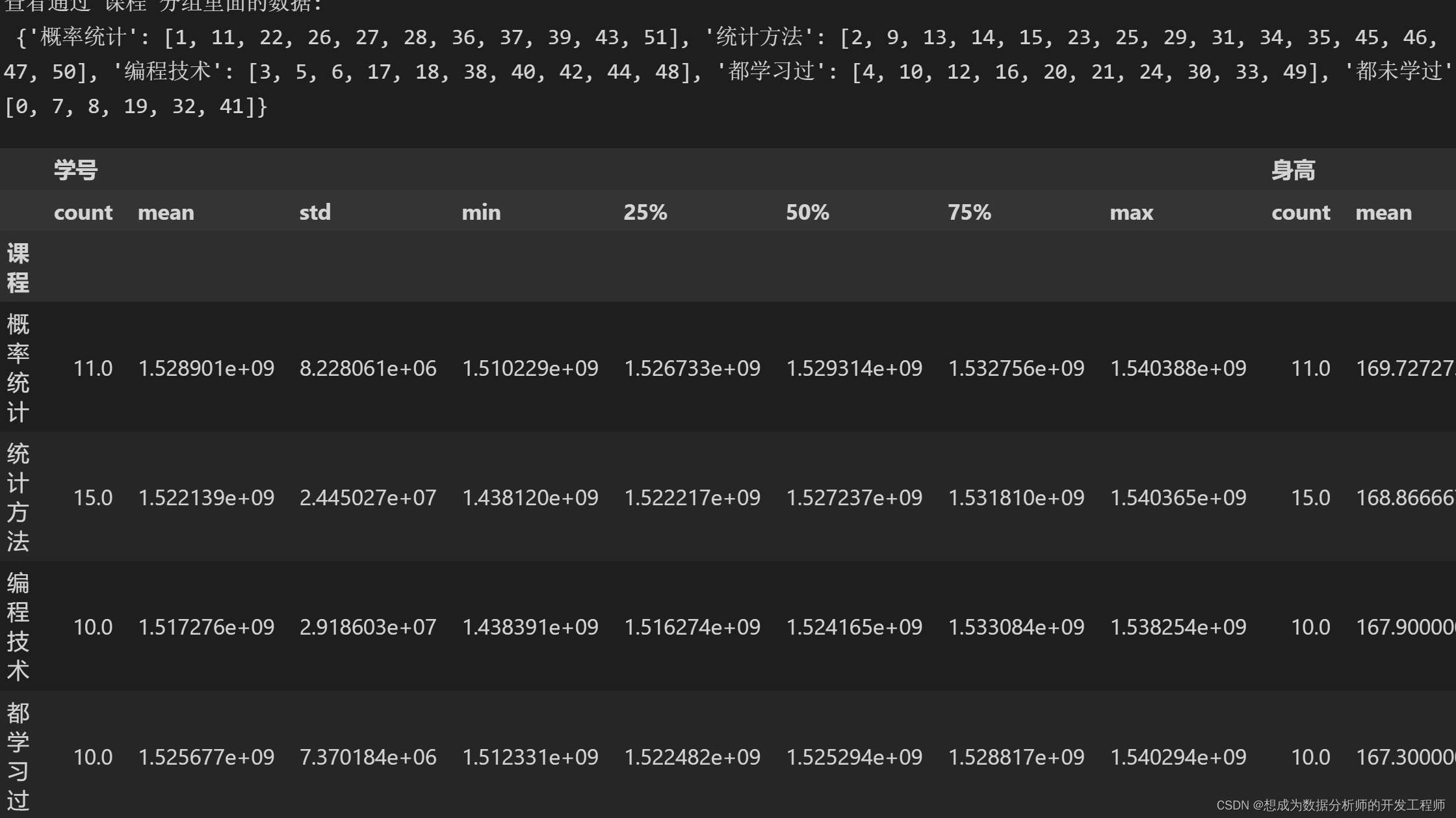
# 查看分组里面的数据
print('查看通过 课程 分组里面的数据:\n',dfg.groups)
# 查看分组描述
dfg.describe()
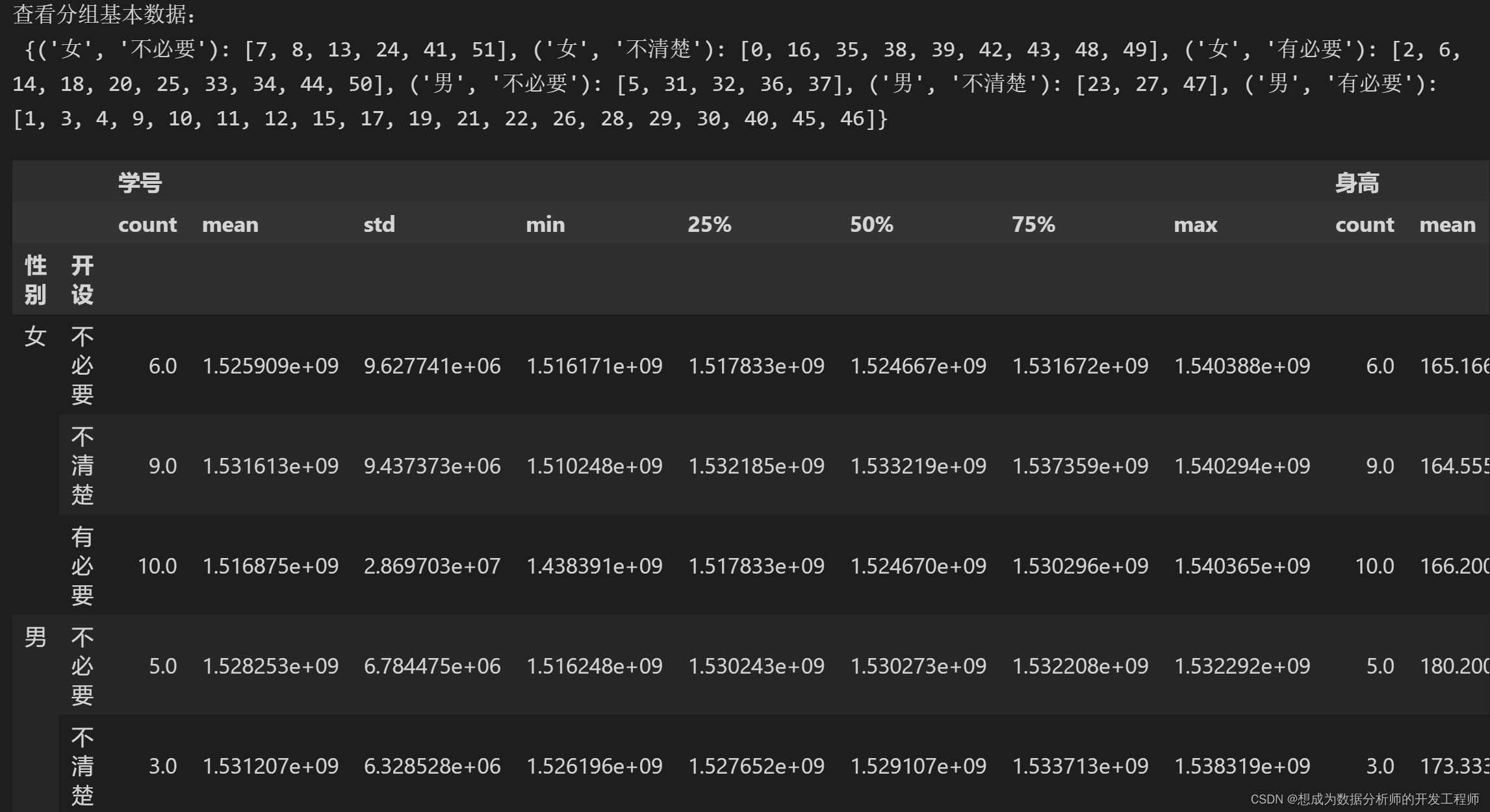
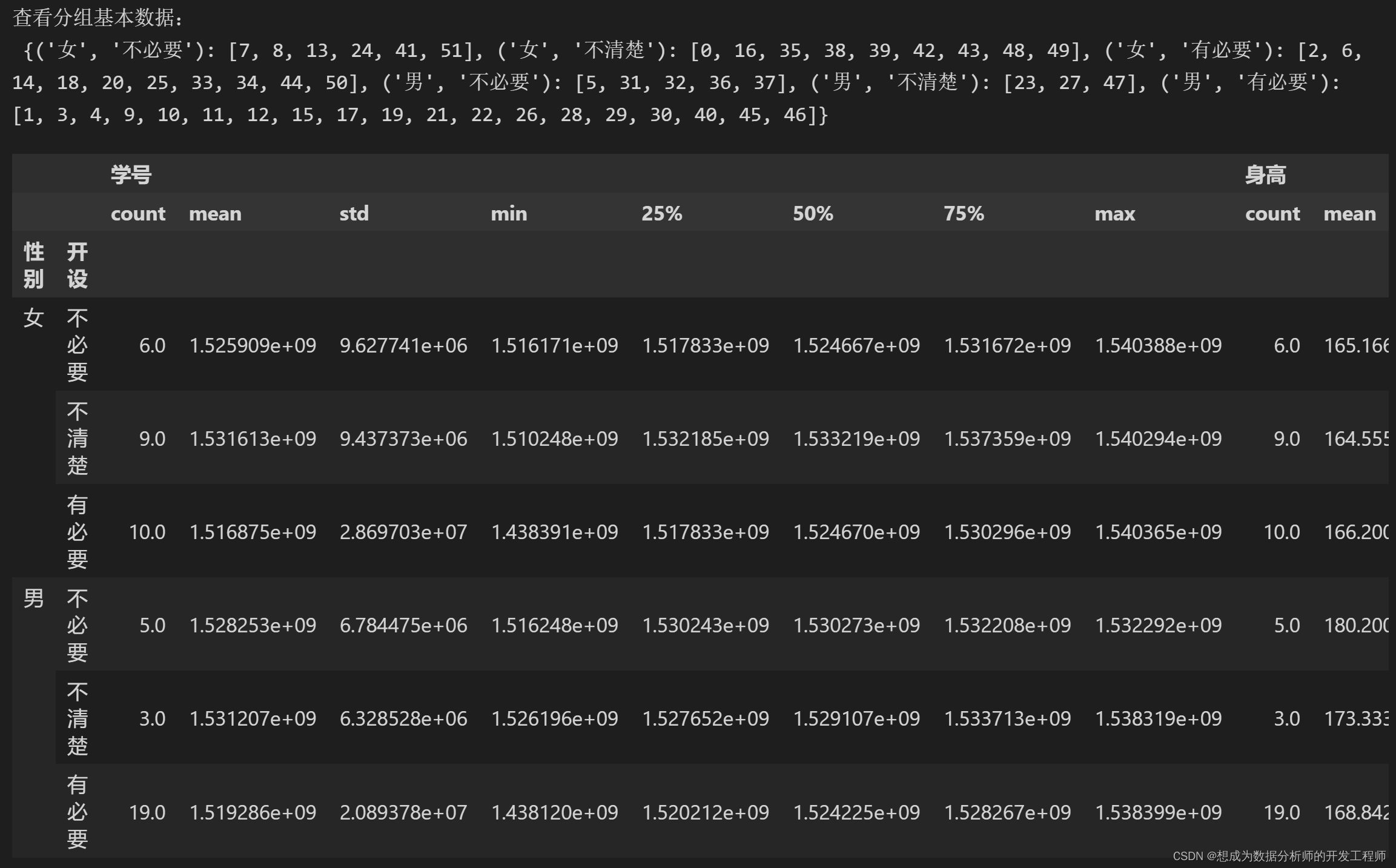
# 按照多列分组
dfg1 = df.groupby(['性别','开设'])
print('查看分组基本数据:\n',dfg1.groups)
# 查看分组具体描述
dfg1.describe()
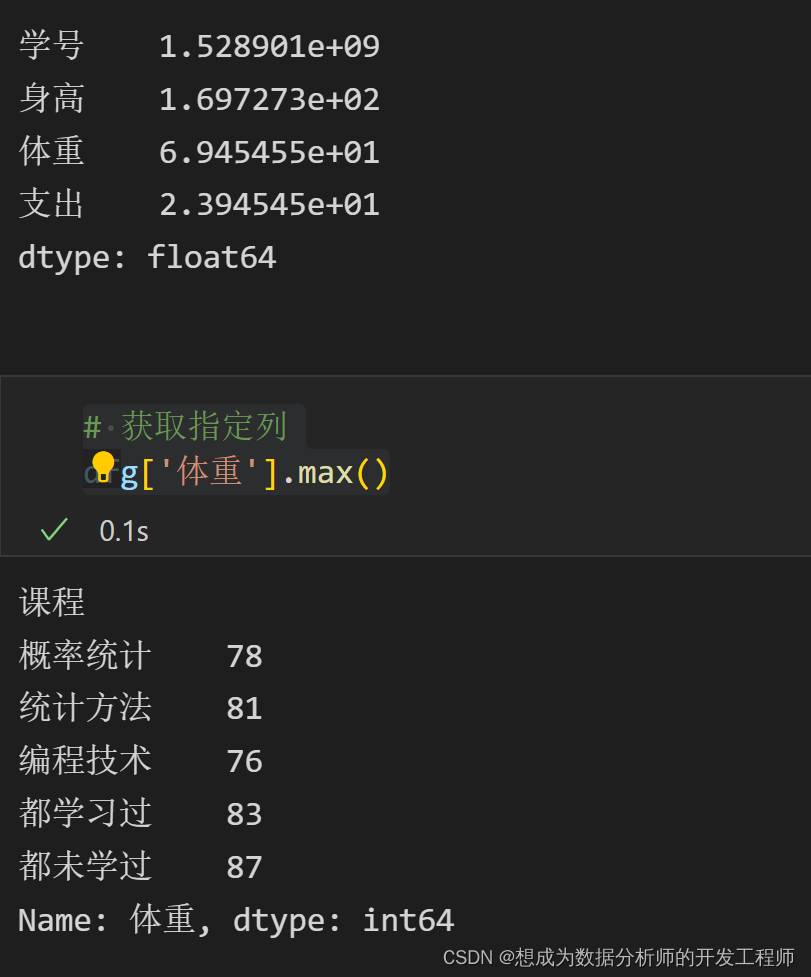
# 筛选分组
dfg.describe()
dfg.get_group('概率统计').mean()
# 获取指定列
dfg['体重'].max()
4.Pandas分组汇总
分组汇总的意义:在于按照指定得条件把表数据分为几类,再去查看每一类数据之间的关系(例如每一类中的最大值、方差等)
在使用 groupby 完成数据分组后,就可以按照需求进行分组信息汇总,此时可以使用其它专门的汇总命令,如 agg 来完成汇总操作。
使用 agg 函数进行汇总
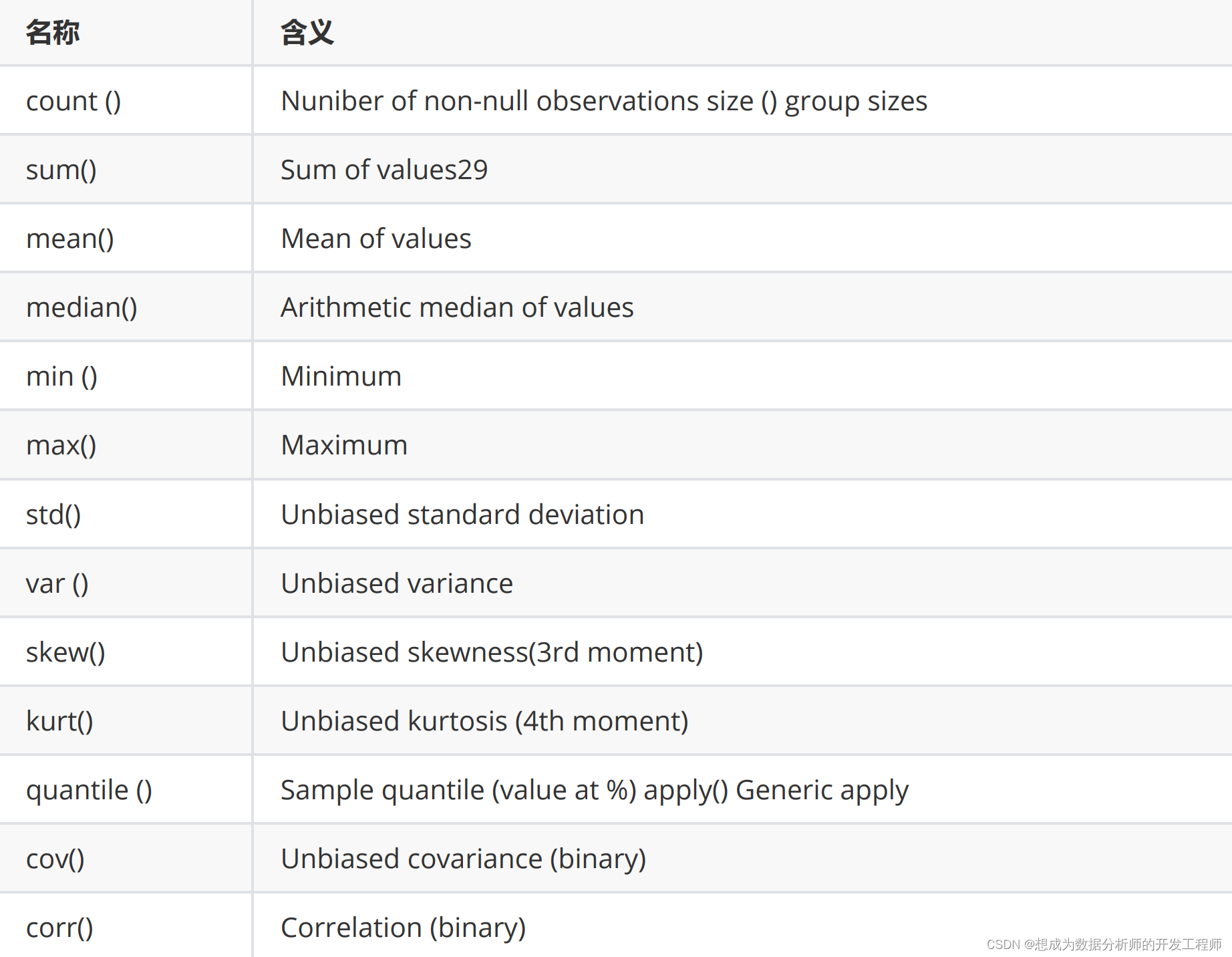
df.aggregate( )
名称可以直接简写为 agg可以用 axis 指定汇总维度
可以直接使用的汇总函数
import pandas as pd
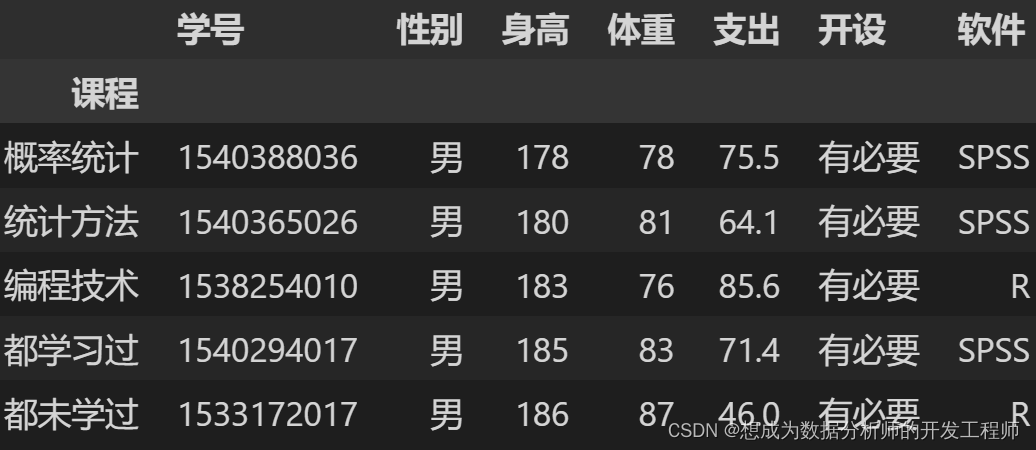
df = pd.read_excel('stu_data.xlsx')
# 1.分组(一类)
dfg = df.groupby('课程')
# 分组汇总
dfg.agg(max)
# 对分组后某列进行汇总
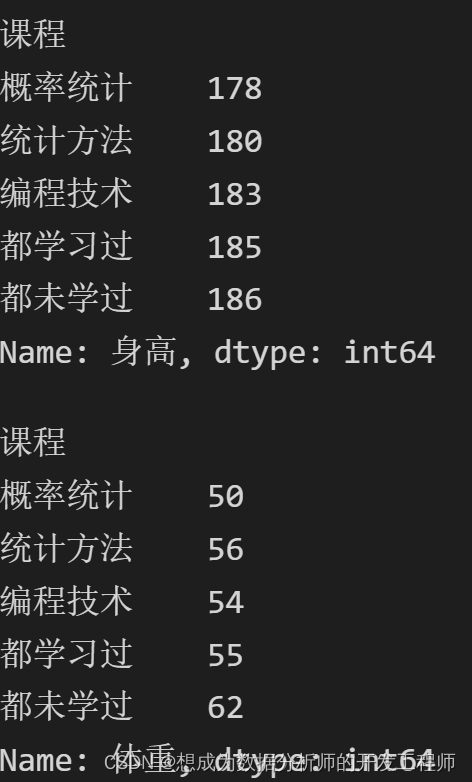
# 获取分组后身高最高(求在分类后的最值问题)
print(dfg.身高.agg(max))
# 获取分组后体重最低(求在分类后的最值问题)
dfg.体重.agg(min)
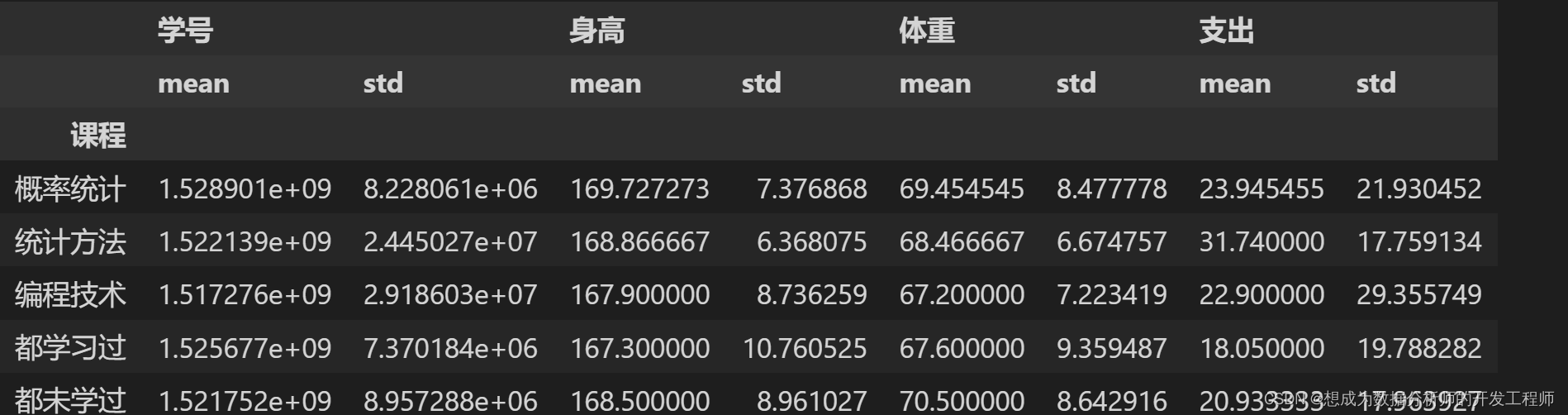
# 2.获取多个汇总信息 均值 方差
dfg.agg(['mean','std'])
# agg使用numpy中函数
import numpy as np
dfg.agg(np.min)
# agg使用自定义函数
def get_func(n:int)->int:
return n.min()
dfg.体重.agg(get_func)
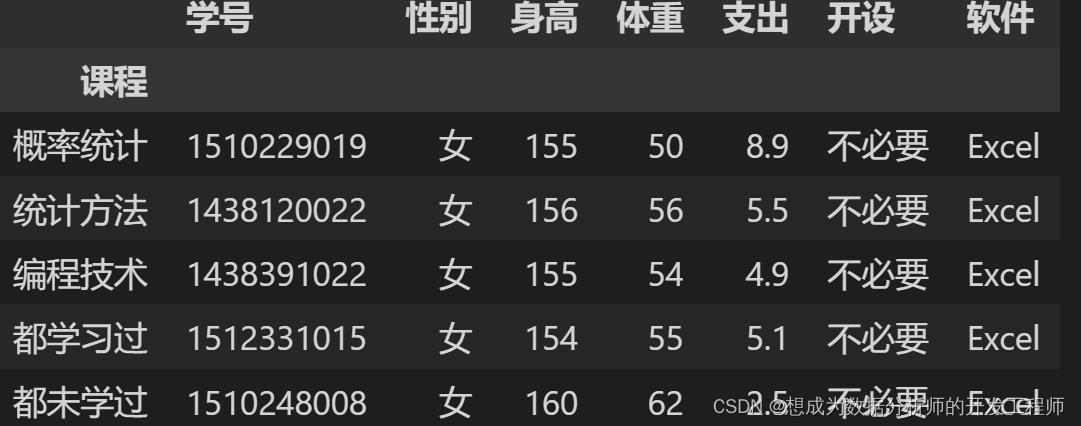

5.Pandas长宽格式转换
长宽格式转换
基于多重索引,Pandas 可以很容易地完成长型、宽型数据格式的相互转换。
长形数据格式
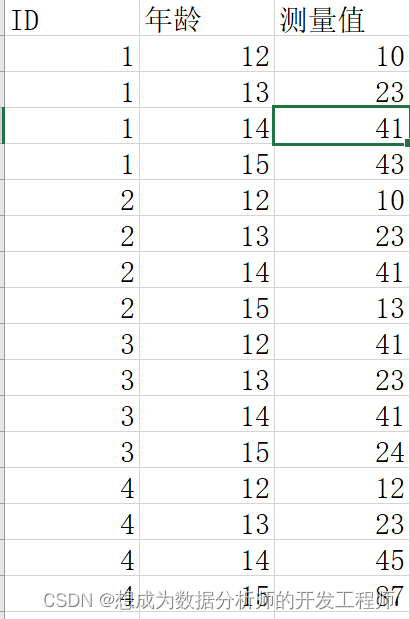
宽形数据格式
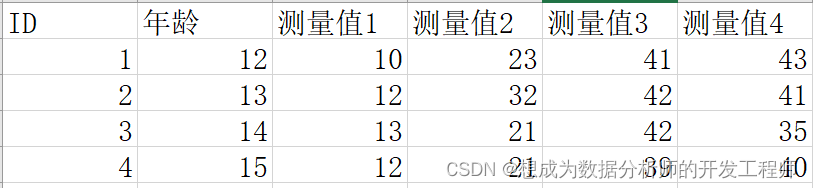
转换为最简格式
df.stack(
level = -1 :需要处理的索引级别,默认为全部,
int/string/list
dropna = True :是否删除为缺失值的行
)#转换后的结果可能为 Series
长宽型格式的自由互转
df.unstack(
level = -1 :需要处理的索引级别,默认为全部,
int/string/list
fill_value :用于填充缺失值的数值
)
import pandas as pd
df = pd.read_excel('person.xlsx')
pd.options.display.max_rows=100
# 原数据格式
df
# 转为最简格式
dfs = df.stack()
dfs
# 转换
dfs.unstack()
# 读取文件,指定索引
df2 = pd.read_excel('person.xlsx', index_col=[0,1])
df2
dfs2 = df2.stack()
dfs2
dfs3 = df2.stack(0)
dfs3
dfs3.unstack()
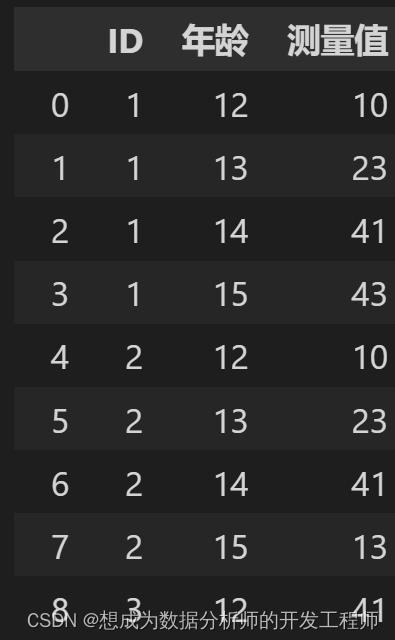

6.DataFrame多个数据源合并
append只能用于合并DataFrame,而concat可以合并Series和DataFrame
6.1Pandas数据纵向合并append用法
import pandas as pd
# 自定义函数创建DataFrame
def make_df(cols, index):
data = {c:[str(c)+str(i) for i in index]for c in cols}
return pd.DataFrame(data,index=index)
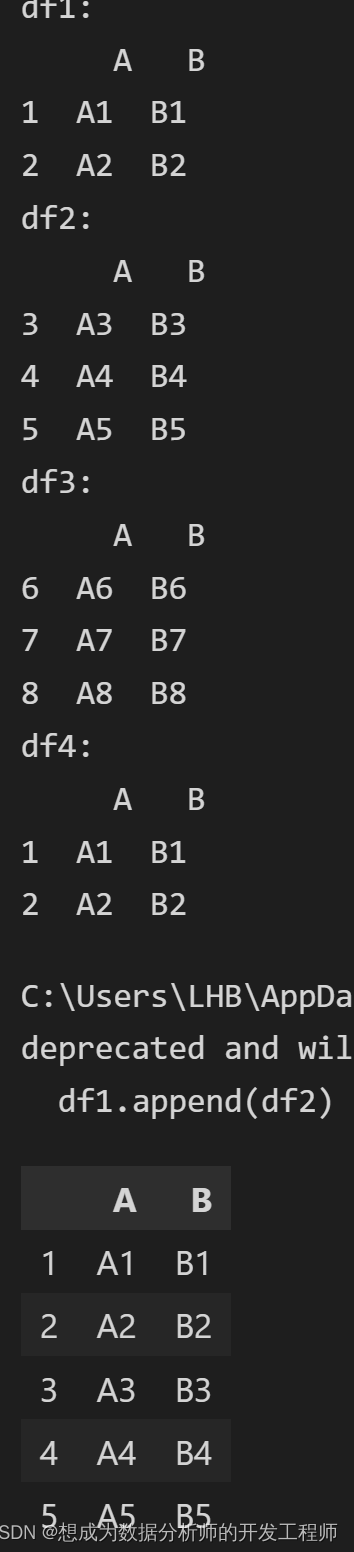
df1 = make_df('AB',[1,2])
print('df1:\n',df1)
df2 = make_df('AB',[3,4,5])
print('df2:\n',df2)
df3 = make_df('AB',[6,7,8])
print('df3:\n',df3)
df4 = make_df('AB',[1,2])
print('df4:\n',df4)
# 纵向合并 append
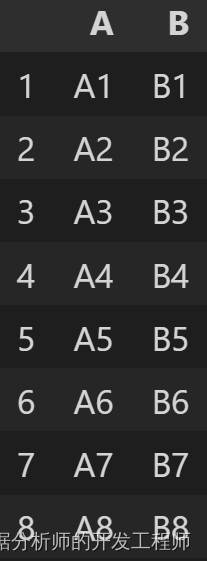
df1.append(df2)
# 多个DataFrame纵向合并
df1.append([df2,df3])
# 当索引值重复时,可以使用ignore_index忽略
df1.append(df4,ignore_index=True)
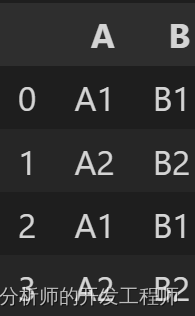
6.2Pandas数据横向合并merge用法
merge 命令使用像 SQL 的连接方式
pd.merge(
需要合并的 DF
left :需要合并的左侧 DF
right :需要合并的右侧 DF
how = ’ inner’:具体的连接类型
{left、right 、outer 、 inner、)
两个 DF 的连接方式
on :用于连接两个 DF 的关键变量(多个时为列表),必须在
两侧都出现
left_on :左侧 DF 用于连接的关键变量(多个时为列表)
right_on :右侧 DF 用于连接的关键变量(多个时为列表)
left_index = False :是否将左侧 DF 的索引用于连接
right_index = False :是否将右侧 DF 的索引用于连接
)
import pandas as pd
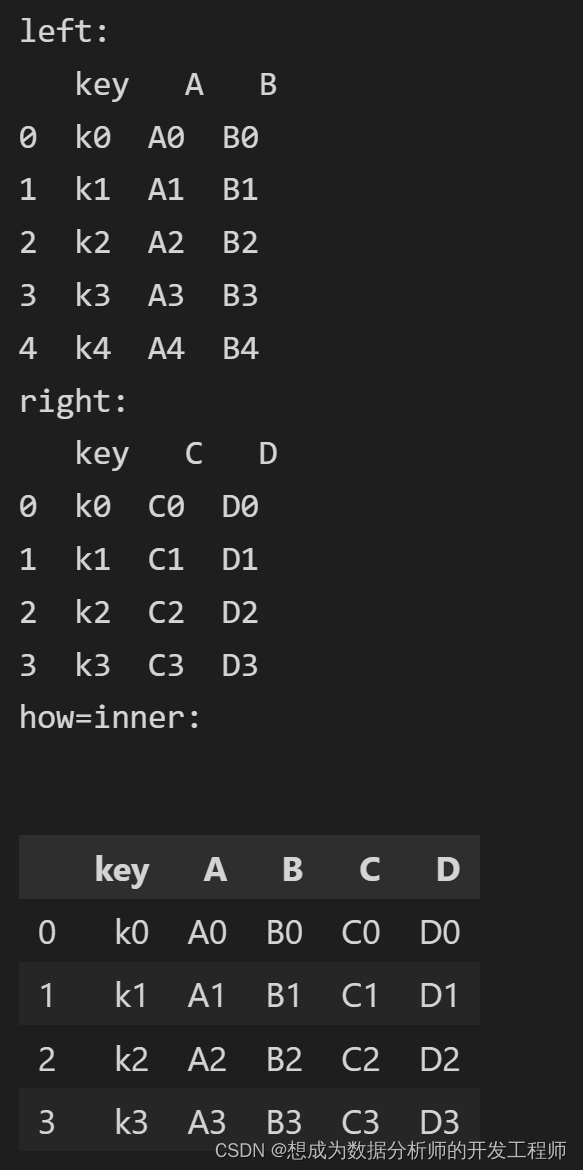
left = pd.DataFrame({'key':['k0','k1','k2','k3','k4'],
'A':['A0','A1','A2','A3','A4'],
'B':['B0','B1','B2','B3','B4']})
print('left:\n',left)
right = pd.DataFrame({'key':['k0','k1','k2','k3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
print('right:\n',right)
# merge默认是等值连接,找到值相等how=inner的那一列进行连接(若其中一个值不相等,直接掠过)
print('how=inner:\n')
pd.merge(left,right)
# 左连接时:只要左边值存在一定要显示,右边不存在时用NaN
pd.merge(left,right,how='left')
# 右连接时:只要右边值存在一定要显示,左边不存在时用NaN
pd.merge(left,right,how='right')
# 右连接时:只要右边值存在一定要显示,左边不存在时用NaN
right = pd.DataFrame({'key':['k0','k1','k2','k3','k5'],
'C':['C0','C1','C2','C3','C5'],
'D':['D0','D1','D2','D3','D5']})
pd.merge(left,right,how='right')
# 外连接outer:不管左右是否满足条件,只要存在,都显示
pd.merge(left,right,how='outer')
left = pd.DataFrame({'key1':['k0','k1','k2','k3','k4'],
'A':['A0','A1','A2','A3','A4'],
'B':['B0','B1','B2','B3','B4']})
right = pd.DataFrame({'key2':['k0','k1','k2','k3'],
'C':['C0','C1','C2','C3'],
'D':['D0','D1','D2','D3']})
# on的使用:必须在左右两边都出现此关键词,才可以进行连接
# left_on right_on:左右两侧的索引名称不相同时,可以用此来指定,否则报错
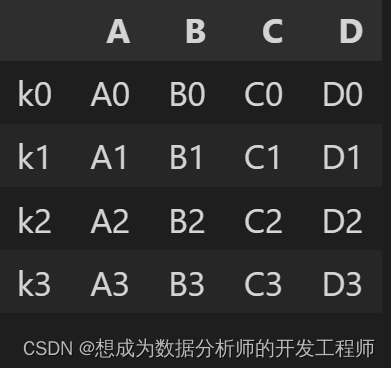
pd.merge(left,right,left_on='key1',right_on='key2')
left.set_index(keys='key1',inplace=True)
right.set_index(keys='key2',inplace=True)
# left_index,right_index:是否使用左右侧DF的索引值进行连接
pd.merge(left,right,left_index=True,right_index=True)





7.Pandas中concat命令
concat 命令
同时支持横向合并与纵向合并
pd.concat(
objs :需要合并的对象,列表形式提供
axis = 0 :对行还是对列方向逬行合并
(0 index 、 1 columns )
join = outer :对另一个轴向的索引值如何逬行处理
(inner 、outer )
ignore_index = False
keys = None :为不同数据源的提供合并后的索引值
verify_integrity = False 是否检查索引值的唯一性,有重复时报
错
copy = True
)
import pandas as pd
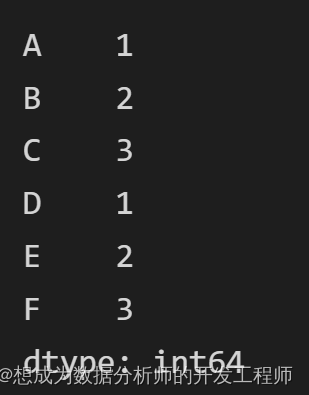
ser1 = pd.Series([1,2,3],index=list('ABC'))
ser2 = pd.Series([1,2,3],index=list('DEF'))
# 一维的Series使用Concat拼接
pd.concat([ser1,ser2])
# 二维的DtaFrame对象拼接
def make_df(cols, index):
data = {c:[str(c)+str(i) for i in index] for c in cols}
return pd.DataFrame(data,index=index)
df1 = make_df('AB',[1,2])
df2 = make_df('AB',[3,4])
# 1.按照默认竖直axis=0进行拼接
pd.concat([df1,df2])
# 2.指定按行或者列进行拼接
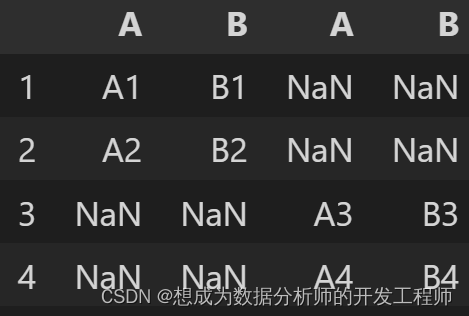
pd.concat([df1,df2],axis=1)# 或者axis='columns'
# 3.当两个索引重复,两个df对象。
x = make_df('AB',[1,2])
y = make_df('AB',[1,2])
pd.concat([x,y])
# 解决索引重复问题1:加ignore_index属性
pd.concat([x,y],ignore_index=True)
# 解决索引重复问题2:,加keys属性,建立双重索引
pd.concat([x,y],keys=list('xy'))
# 4.两个DataFrame对象拼接,join参数的使用:inner内连接是只找出交集部分其余不显示;outer外连接全部显示,其余用nan代替
a = make_df('ABC',[1,2])
b = make_df('BCD',[3,4])
pd.concat([a,b], join='inner')
a = make_df('ABC',[1,2,3,4])
b = make_df('BCD',[3,4,5])
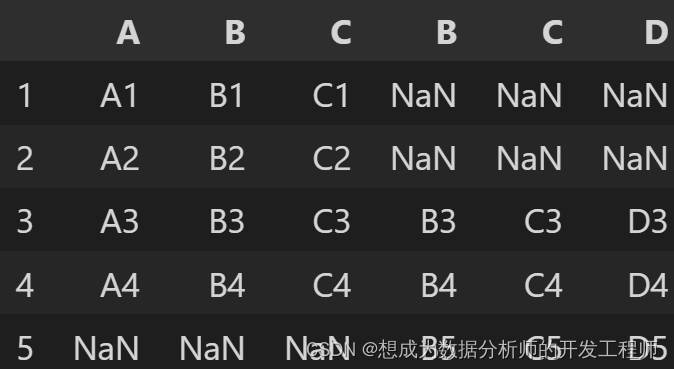
pd.concat([a,b],join='outer',axis=1)





相关文章
- Python开源机器学习框架:Scikit-learn六大功能,安装和运行Scikit-learn
- python pandas ---Series,DataFrame 创建方法,操作运算操作(赋值,sort,get,del,pop,insert,+,-,*,/)
- 简述 Python 的 Numpy、SciPy、Pandas、Matplotlib 的区别
- Python中的Pandas模块
- 【华为OD机试真题 python】污染水域【2022 Q4 | 200分】
- The Hacker's Guide To Python 单元测试
- Google Earth Engine(python)——全球降水数据集转化为excel表利用Pandas
- 使用python读写xlsx格式中的数据【pandas】
- python基础——第三方模块
- Python入门之数据处理——12种有用的Pandas技巧
- 【Python】Pandas 操作Excel
- [爬虫]Python爬虫进阶
- python中stack在实际中的简单应用之平衡符号
- python 数据的读取
- 数据科学必备Python使用Pandas方法汇总
- Python教程之Python 中有效地存储 Pandas 数据帧
- Python 教程之SQL与pandas所有最受欢迎的查询(教程含源码)
- Python用Pandas读写Excel
- Python实现数据结构 图
- 【Python】pandas的使用——CSV文件、Excel文件、TXT文件之间的转换