
【开源】PaddleOCR一键识别万物
介绍
光学字符识别(Optical Character Recognition, OCR)是指对文本材料的图像文件进行分析识别处理,以获取文字和版本信息的过程。也就是说将图象中的文字进行识别,并返回文本形式的内容。例如(该预测效果基于PaddleHub一键OCR中文识别效果展示):
(6)

PaddleHub现已开源OCR文字识别的预训练模型(超轻量ppocrmobile系列和通用ppocrserver系列中英文ocr模型,媲美商业效果。)
移动端的超轻量模型:超轻量ppocr_mobile移动端系列:检测(2.6M)+方向分类器(0.9M)+ 识别(4.6M)= 8.1M,仅有8.1M。chinese_ocr_db_crnn_mobile(1.1.0最新版)。
服务器端的精度更高模型:识别精度更高,chinese_ocr_db_crnn_server。
前要
OCR的应用场景
根据OCR的应用场景而言,我们可以大致分成识别特定场景下的专用OCR以及识别多种场景下的通用OCR。就前者而言,证件识别以及车牌识别就是专用OCR的典型案例。针对特定场景进行设计、优化以达到最好的特定场景下的效果展示。那通用的OCR就是使用在更多、更复杂的场景下,拥有比较好的泛性。在这个过程中由于场景的不确定性,比如:图片背景极其丰富、亮度不均衡、光照不均衡、残缺遮挡、文字扭曲、字体多样等等问题,会带来极大的挑战。现PaddleHub为大家提供的是超轻量级中文OCR模型,聚焦特定的场景,支持中英文数字组合式别、竖排文字识别、长文本识别场景。
OCR的技术路线
典型的OCR技术路线如下图所示:

其中OCR识别的关键路径在于文字检测和文本识别部分,这也是深度学习技术可以充分发挥功效的地方。PaddleHub为大家开源的预训练模型的网络结构是Differentiable Binarization+ CRNN,基于icdar2015数据集下进行的训练。
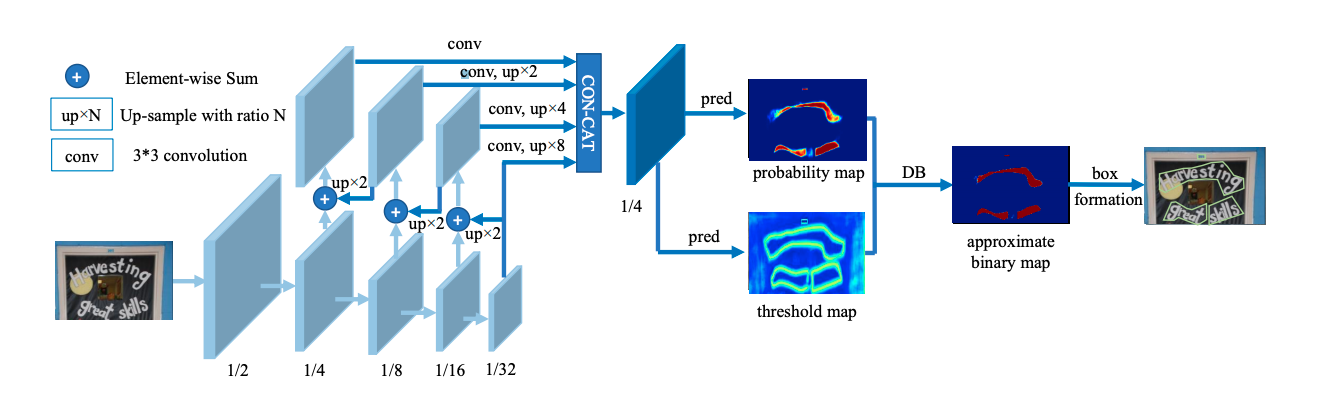
首先,DB是一种基于分割的文本检测算法。在各种文本检测算法中,基于分割的检测算法可以更好地处理弯曲等不规则形状文本,因此往往能取得更好的检测效果。但分割法后处理步骤中将分割结果转化为检测框的流程复杂,耗时严重。因此作者提出一个可微的二值化模块(Differentiable Binarization,简称DB),将二值化阈值加入训练中学习,可以获得更准确的检测边界,从而简化后处理流程。DB算法最终在5个数据集上达到了state-of-art的效果和性能。参考论文:Real-time Scene Text Detection with Differentiable Binarization
下图是DB算法的结构图:
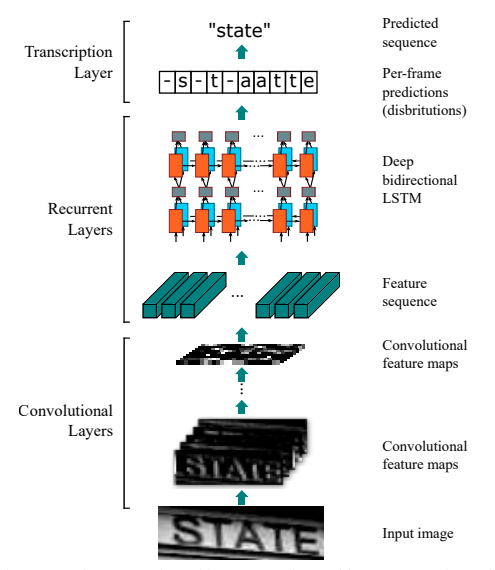
接着,我们使用 CRNN(Convolutional Recurrent Neural Network)即卷积递归神经网络,是DCNN和RNN的组合,专门用于识别图像中的序列式对象。与CTC loss配合使用,进行文字识别,可以直接从文本词级或行级的标注中学习,不需要详细的字符级的标注。参考论文:An end-to-end trainable neural network for image-based sequence recognition and its application to scene text recognition
下图是CRNN的网络结构图:
一、定义待预测数据
以本示例中文件夹下图片为待预测图片。本教程为大家总共提供了5个具体场景下的ocr识别,分别是「身份证识别」、「火车票识别」、「快递单识别」、「广告信息识别」、「网络图片文字识别」。
注:该 Moudle 目前只支持一键预测,这五个场景是预测效果比较好的应用场景,大家也可以自己去尝试在感兴趣的场景下使用
#需要将PaddleHub和PaddlePaddle统一升级到2.0版本
!pip install paddlehub==2.1.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install paddlepaddle==2.2.0 -i https://pypi.tuna.tsinghua.edu.cn/simple
#该Module依赖于第三方库shapely、pyclipper,使用该Module之前,请先安装shapely、pyclipper
!pip install shapely -i https://pypi.tuna.tsinghua.edu.cn/simple
!pip install pyclipper -i https://pypi.tuna.tsinghua.edu.cn/simple
import matplotlib.pyplot as plt
import matplotlib.image as mpimg
# 待预测图片
test_img_path = ["./advertisement.jpg", "./pics.jpg", "./identity_card.jpg", "./express.jpg", "./railway_ticket.jpg"]
# 展示其中广告信息图片
img1 = mpimg.imread(test_img_path[0])
plt.figure(figsize=(10,10))
plt.imshow(img1)
plt.axis('off')
plt.show()
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-SdXz4fxY-1652865775526)(output_4_0.png)]
若是待预测图片存放在一个文件中,如左侧文件夹所示的test.txt。每一行是待预测图片的存放路径。
!cat test.txt
advertisement.jpg
pics.jpg
identity_card.jpg
express.jpg
railway_ticket.jpg
用户想要利用ocr模型识别图片中的文字,只需读入该文件,将文件内容存成list,list中每个元素是待预测图片的存放路径。
with open('test.txt', 'r') as f:
test_img_path=[]
for line in f:
test_img_path.append(line.strip())
print(test_img_path)
['advertisement.jpg', 'pics.jpg', 'identity_card.jpg', 'express.jpg', 'railway_ticket.jpg']
二、加载预训练模型
PaddleHub提供了以下文字识别模型:
移动端的超轻量模型:仅有8.1M,chinese_ocr_db_crnn_mobile。
服务器端的精度更高模型:识别精度更高,chinese_ocr_db_crnn_server。
识别文字算法均采用CRNN(Convolutional Recurrent Neural Network)即卷积递归神经网络。其是DCNN和RNN的组合,专门用于识别图像中的序列式对象。与CTC loss配合使用,进行文字识别,可以直接从文本词级或行级的标注中学习,不需要详细的字符级的标注。该Module支持直接预测。
移动端与服务器端主要在于骨干网络的差异性,移动端采用MobileNetV3,服务器端采用ResNet50_vd。
import paddlehub as hub
# 加载移动端预训练模型
ocr = hub.Module(name="chinese_ocr_db_crnn_mobile")
# 服务端可以加载大模型,效果更好
# ocr = hub.Module(name="chinese_ocr_db_crnn_server")
三、预测
PaddleHub对于支持一键预测的module,可以调用module的相应预测API,完成预测功能。
import cv2
# 读取测试文件夹test.txt中的照片路径
np_images =[cv2.imread(image_path) for image_path in test_img_path]
results = ocr.recognize_text(
images=np_images, # 图片数据,ndarray.shape 为 [H, W, C],BGR格式;
use_gpu=False, # 是否使用 GPU;若使用GPU,请先设置CUDA_VISIBLE_DEVICES环境变量
output_dir='ocr_result', # 图片的保存路径,默认设为 ocr_result;
visualization=True, # 是否将识别结果保存为图片文件;
box_thresh=0.5, # 检测文本框置信度的阈值;
text_thresh=0.5) # 识别中文文本置信度的阈值;
for result in results:
data = result['data']
save_path = result['save_path']
for infomation in data:
print('text: ', infomation['text'], '\nconfidence: ', infomation['confidence'], '\ntext_box_position: ', infomation['text_box_position'])
Download https://bj.bcebos.com/paddlehub/paddlehub_dev/chinese_text_detection_db_mobile-1.0.4.tar.gz
[##################################################] 100.00%
Decompress /home/aistudio/.paddlehub/tmp/tmp19kgu3xv/chinese_text_detection_db_mobile-1.0.4.tar.gz
[##################################################] 100.00%
text: 小度在家1S
confidence: 0.9992504715919495
text_box_position: [[35, 25], [325, 25], [325, 76], [35, 76]]
text: 多功能专属儿童空间一高IQ流畅语音交互
confidence: 0.9422831535339355
text_box_position: [[31, 90], [455, 90], [455, 110], [31, 110]]
text: 2614:53
confidence: 0.9164754748344421
text_box_position: [[362, 173], [423, 170], [423, 189], [362, 192]]
text: 到手价
confidence: 0.9977054595947266
text_box_position: [[65, 226], [153, 226], [153, 258], [65, 258]]
text: 最热音乐专辑,春风十里不如你
confidence: 0.99140465259552
text_box_position: [[232, 226], [418, 226], [418, 246], [232, 246]]
text: ¥329
confidence: 0.9104053974151611
text_box_position: [[31, 247], [163, 258], [158, 326], [27, 315]]
text: 小小这个
confidence: 0.8271657228469849
text_box_position: [[236, 249], [316, 249], [316, 261], [236, 261]]
text: 你好啊夏天
confidence: 0.9979197382926941
text_box_position: [[1081, 150], [1550, 321], [1520, 418], [1051, 246]]
text: 喝一杯压压惊
confidence: 0.9926337599754333
text: EXPRESS
confidence: 0.9935702681541443
text_box_position: [[256, 26], [575, 6], [582, 84], [263, 104]]
text: S
confidence: 0.9705745577812195
text_box_position: [[113, 80], [190, 80], [190, 134], [113, 134]]
text: 顺丰速运
confidence: 0.9733323454856873
text_box_position: [[256, 90], [685, 90], [685, 168], [256, 168]]
text: 第1次打印打印时间01月03日23:43
confidence: 0.9773504137992859
text_box_position: [[641, 90], [1846, 74], [1846, 151], [641, 168]]
text: 运单号:SF101569720
confidence: 0.9985542297363281
text_box_position: [[435, 569], [1479, 545], [1479, 633], [435, 656]]
text: 010WB-01
confidence: 0.9167248010635376
text_box_position: [[102, 788], [1710, 764], [1714, 987], [106, 1010]]
text: 218/250
confidence: 0.9959296584129333
text_box_position: [[2095, 781], [2432, 781], [2432, 862], [2095, 862]]
text: 8个人
confidence: 0.8153955936431885
text_box_position: [[1131, 1047], [1384, 1047], [1384, 1128], [1131, 1128]]
text: 张翔宇157****8458
confidence: 0.9611821174621582
text_box_position: [[326, 1057], [1175, 1047], [1175, 1135], [326, 1145]]
text: 北京市北京市
confidence: 0.9994738101959229
text_box_position: [[322, 1253], [868, 1246], [868, 1347], [322, 1354]]
text: 西里小区6号楼4单元
confidence: 0.9987850189208984
text_box_position: [[1425, 1249], [2282, 1226], [2285, 1313], [1428, 1337]]
text: 寄付月结
confidence: 0.9827804565429688
text_box_position: [[223, 1539], [597, 1539], [597, 1643], [223, 1643]]
text: I1B
confidence: 0.956909716129303
text_box_position: [[223, 1667], [754, 1667], [754, 1926], [223, 1926]]
text: 任艳蕊税务********9529自如
confidence: 0.9822853207588196
text_box_position: [[300, 2344], [1512, 2337], [1512, 2418], [300, 2425]]
text: 北京市朝阳区酒仙桥将台路5号院******
confidence: 0.9899845719337463
text_box_position: [[300, 2445], [1813, 2438], [1813, 2519], [300, 2526]]
text: 增值服务:
confidence: 0.9856716394424438
text_box_position: [[25, 2637], [355, 2637], [355, 2708], [25, 2708]]
text: 件数:1
confidence: 0.9932925701141357
text_box_position: [[25, 2732], [311, 2732], [311, 2812], [25, 2812]]
text: 月结卡号:01******92
confidence: 0.9528482556343079
text_box_position: [[886, 2735], [1615, 2738], [1615, 2809], [886, 2806]]
text: 实际重量:1kg
confidence: 0.975562334060669
text_box_position: [[1740, 2732], [2219, 2738], [2219, 2819], [1740, 2812]]
text: 运费:13(不作结算依据)
confidence: 0.9940875172615051
text_box_position: [[21, 2823], [805, 2816], [805, 2897], [21, 2903]]
text: 费用合计:
confidence: 0.9783260226249695
text_box_position: [[882, 2829], [1216, 2829], [1216, 2900], [882, 2900]]
text: 托寄物:发票数量:1
confidence: 0.9290561676025391
text_box_position: [[10, 2910], [736, 2913], [736, 2991], [10, 2988]]
text: 备注:25254657
confidence: 0.9962103366851807
text_box_position: [[25, 3011], [509, 3011], [509, 3079], [25, 3079]]
text: F067846
confidence: 0.9714171290397644
text_box_position: [[1111, 513], [1760, 524], [1760, 666], [1111, 655]]
text: 检票:22
confidence: 0.995017409324646
text_box_position: [[3189, 540], [3680, 540], [3680, 688], [3189, 688]]
text: 北京南站
confidence: 0.9998739361763
text_box_position: [[1274, 704], [1989, 704], [1989, 873], [1274, 873]]
text: 天津站
confidence: 0.9992415308952332
text_box_position: [[2837, 715], [3566, 715], [3566, 879], [2837, 879]]
text: C2565
confidence: 0.9960814714431763
text_box_position: [[2162, 748], [2673, 737], [2673, 884], [2162, 895]]
text: Beijingnan
confidence: 0.990975558757782
text_box_position: [[1329, 890], [1875, 912], [1870, 1026], [1324, 1004]]
text: Tianjin
confidence: 0.9906495809555054
text_box_position: [[2976, 901], [3363, 912], [3363, 1026], [2976, 1015]]
text: 2019年04月03日09:36开
confidence: 0.9782440066337585
text_box_position: [[1165, 1026], [2509, 1043], [2509, 1157], [1165, 1141]]
text: 02车03C号
confidence: 0.993168830871582
text_box_position: [[2777, 1043], [3343, 1043], [3343, 1168], [2777, 1168]]
text: ¥54.5元
confidence: 0.9769668579101562
text_box_position: [[1185, 1190], [1617, 1190], [1617, 1305], [1185, 1305]]
text: 网
confidence: 0.9998763799667358
text_box_position: [[2197, 1190], [2321, 1190], [2321, 1310], [2197, 1310]]
text: 二等座
confidence: 0.9954232573509216
text_box_position: [[2961, 1190], [3323, 1190], [3323, 1327], [2961, 1327]]
text: 限乘当日当次车
confidence: 0.9984740018844604
text_box_position: [[1155, 1321], [1959, 1338], [1959, 1469], [1155, 1452]]
text: 始发改签
confidence: 0.9992954730987549
text_box_position: [[1165, 1480], [1612, 1480], [1612, 1594], [1165, 1594]]
text: 2302051998****156X装瑜丽
confidence: 0.9665354490280151
text_box_position: [[1140, 1622], [2777, 1638], [2777, 1780], [1140, 1764]]
text: 买票请到12306发货请到95306
confidence: 0.9786145091056824
text_box_position: [[1448, 1813], [2797, 1824], [2797, 1933], [1448, 1922]]
text: 中国铁路祝您旅途愉快
confidence: 0.9993003606796265
text_box_position: [[1612, 1944], [2609, 1955], [2609, 2064], [1612, 2053]]
text: 10010301110403F067846北京南售
confidence: 0.9994041323661804
text_box_position: [[1160, 2113], [2777, 2129], [2777, 2239], [1160, 2222]]
recognize_text()接口返回结果results说明:
- results (list[dict]): 识别结果的列表,列表中每一个元素为 dict,各字段为:
- data (list[dict]): 识别文本结果,列表中每一个元素为 dict,各字段为:
- text(str): 识别得到的文本
- confidence(float): 识别文本结果置信度
- text_box_position(list): 文本框在原图中的像素坐标,4*2的矩阵,依次表示文本框左下、右下、右上、左上顶点的坐标 如果无识别结果则data为[]
- save_path (str, optional): 识别结果的保存路径,如不保存图片则save_path为’’
- data (list[dict]): 识别文本结果,列表中每一个元素为 dict,各字段为:
四、效果展示
PaddleHub对于支持一键预测的module,可以调用module的相应预测API,完成预测功能。在完成第三部分的一键OCR预测之后,由于我们设置了visualization=True,所以我们会自动将识别结果保存为图片文件,并默认保存在ocr_result文件夹中。刷新即可获取到新生成的ocr_result文件夹。
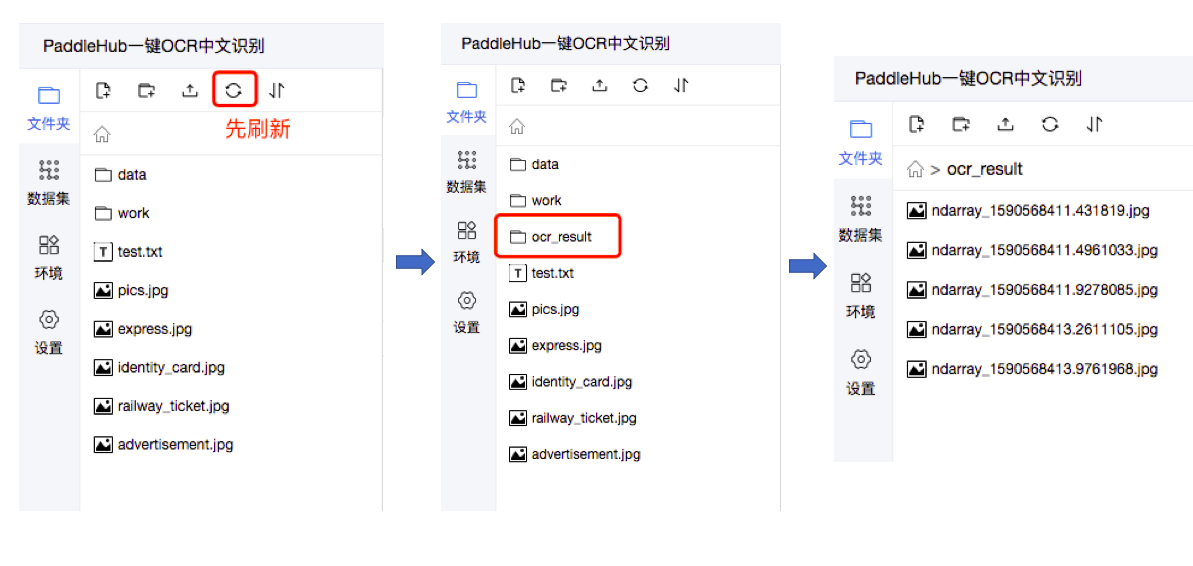
「身份证识别」、「火车票识别」、「快递单识别」、「广告信息识别」、「网络图片文字识别」五个场景下的效果展示


同时,作为一项完善的开源工作,除了本地推断以外,PaddleHub还支持将该预训练模型部署到服务器或移动设备中。
由于AIStudio不支持ip访问,以下代码仅做示例,如有需要,请在本地机器运行。
五、部署服务器
借助 PaddleHub,服务器端的部署也非常简单,直接用一条命令行在服务器启动文字识别OCR模型:
$ hub serving start -m chinese_ocr_db_crnn_mobile -p 8866
是的,在服务器端这就完全没问题了。相比手动配置各种参数或者调用各种框架,PaddleHub 部署服务器实在是太好用了。
只要在服务器端完成部署,剩下在客户端调用就不会有多大问题了。如下百度展示了调用服务器做推断的示例:制定要预测的图像列表、发出推断请求、返回并保存推断结果。
# coding: utf8
import requests
import json
import cv2
import base64
def cv2_to_base64(image):
data = cv2.imencode('.jpg', image)[1]
return base64.b64encode(data.tostring()).decode('utf8')
# 发送HTTP请求
data = {'images':[cv2_to_base64(cv2.imread("/PATH/TO/IMAGE"))]}
headers = {"Content-type": "application/json"}
url = "http://127.0.0.1:8866/predict/chinese_ocr_db_crnn_mobile"
r = requests.post(url=url, headers=headers, data=json.dumps(data))
# 打印预测结果
print(r.json()["results"])
相信只要有一些 Python 基础,在本地预测、以及部署到服务器端都是没问题的,飞桨的 PaddleHub 已经帮我们做好了各种处理过程。