
阿里P8:你们公司就这水平?看看这份Python接口自动化测试手册
前阵子有幸参加了个2021英雄技术会,与会了一个阿里P8技术大佬,我兴致勃勃地把我们公司的整套测试流程展示给大佬看,并重点介绍了我司自动化测试,谁知道大佬看完后来了句:就这?就这水平?随后丢给我一份Python接口自动化测试手册并说道,回去好好看看吧
果然如获至宝,大伙学习后果然水平有很大提升,现在把这份Python接口自动化测试手册展示给大家看看,点击下面即可免费获取哈
以下是部分内容展示
目录
第 1 章 Fiddler

1.1 抓 firefox 上 https 请求
前言
fiddler 是一个很好的抓包工具,默认是抓 http 请求的,对于 pc 上的 https 请求,会提示网页不安全,这时候需要在浏览器上安装证书。
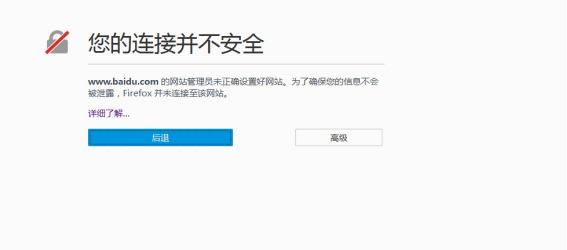
1.1.1 网页不安全
1.用 fiddler 抓包时候,打开百度网页:https://www.baidu.com
2.提示:网页不安全
1.1.2 fiddler 设置
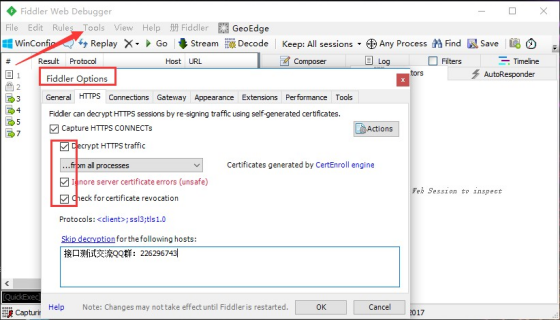
1. 打开菜单栏:Tools>Fiddler Options>HTTPS
勾选 Decrypt HTTPS traffic,里面的两个子菜单也一起勾选了
1.1.3 导出证书
1. 点右上角 Actions 按钮
2. 选第二个选项,导出到桌面,此时桌面上会多一个文件:FiddlerRoot.cer,如下图。

1.1.4 导入到 firefox 浏览器
1. 打开右上角浏览器设置》选项》高级》证书》查看证书》证书机构》导入

2. 勾选文件导入
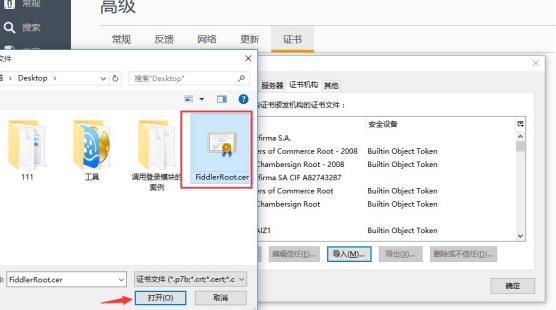
3. 打开文件后,会弹出个框,勾选三个选项就完成操作啦。

如果还不能成功,那就重启浏览器,重启电脑了。
第 2 章 requests

2.1 发 get 请求
前言
requests 模块,也就是老污龟,为啥叫它老污龟呢,因为这个官网上的 logo 就是这只污龟, 接下来就是学习它了。
2.1.1 环境安装
1.用 pip 安装 requests 模块
>>pip install requests

2.1.2 get 请求
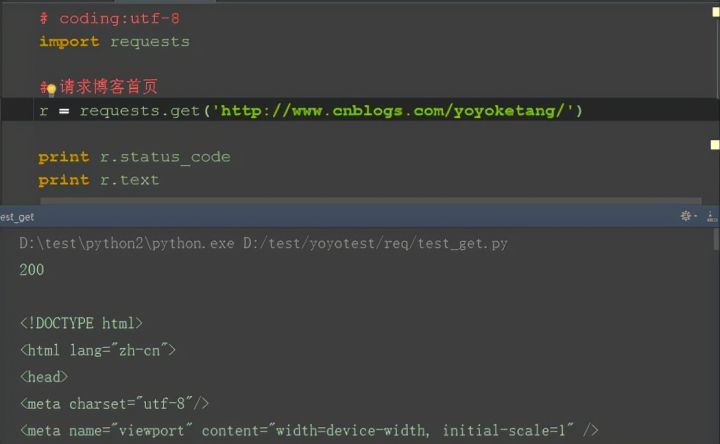
1. 导入 requests 后,用get 方法就能直接访问 url 地址,如: http://www.cnblogs.com/yoyoketang/,看起来是不是很酷
2. 这里的 r 也就是 response,请求后的返回值,可以调用 response 里的 status_code 方法查看状态码
3. 状态码 200 只能说明这个接口访问的服务器地址是对的,并不能说明功能 OK,一般要查看响应的内容,r.text 是返回文本信息
第 3 章 unitttest

3.1 unittest 简介
前言
熟悉 java 的应该都清楚常见的单元测试框架 Junit 和 TestNG,这个招聘的需求上也是经常见到的。python 里面也有单元测试框架-unittest,相当于是一个 python 版的 junit。
python 里面的单元测试框架除了 unittest,还有一个 pytest 框架,这个用的比较少,后面有空再继续分享。
3.1.1 unittest 简介
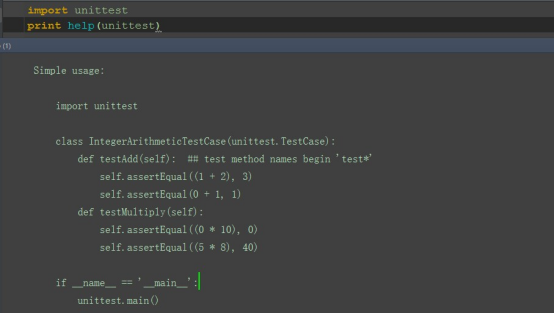
1. 先导入 unittest
2. 用 help 函数查看源码解析
3. 查看描述:
Python unit testing framework, based on Erich Gamma's JUnit and Kent Beck's Smalltalk testing framework.
翻译:python 的单元测试框架,是基于 java 的 junit 测试框架
第 4 章 封装与调用

4.1 函数与参数化
前言
前面实现了参数的关联,那种只是记流水账的完成功能,不便于维护,也没什么可读性,接下来这篇可以把每一个动作写成一个函数,这样更方便了。
参数化的思维只需记住一点:不要写死
4.1.1 登录函数
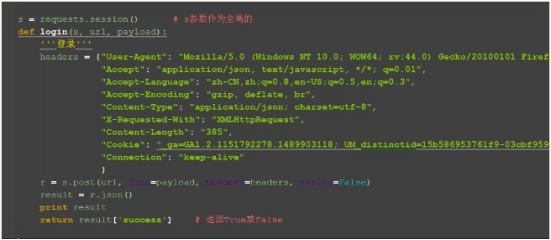
1.s 参数是 session 的一个实例类,先放这里,方便写后面代码
2.登录函数传三个参数,s 是需要调用前面的session 类,所以必传,可以传个登录的 url, 然后 payload 是账号和密码
4.1.2 保存草稿
1. 编辑内容的标题 title 和正文 body_data 参数化了,这样后面可以方便传不同值
2. 这里返回了获取到新的 url 地址,因为后面的 postid 参数需要在这里提取

第 5 章 爬虫利器 beautifulsoup4

5.1.1 安装
1.打开 cmd 用 pip 在线安装 beautifulsoup4
>pip install beautifulsoup4

5.1.2 解析器
1. 我们主要用第一个 html.parser,这个是 python 的标准库,可以直接用。其它几个需要安装对应解析器,下表列出了主要的解析器,以及它们的优缺点:

5.1.3 打印首页博客的时间
1.这里直接定位不好定位到,可以先定位它的父元素:class="dayTitle"
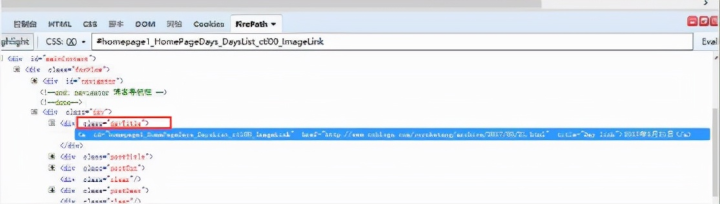
2. 用 requests 里的 get 方法打开博客首页,r.content 返回整个 html 内容,返回类型为string
3. 查找所有的 class 属性为 dayTitle 的 Tag 类
4. 获取当前 Tag 的标签为a 的 string 值

第 6 章 数据库读取

6.1 读 excel 数据 xlrd
前言
当登录的账号有多个的时候,我们一般用 excel 存放测试数据,本章介绍,python 读取excel 方法,并保存为字典格式。
6.1.1 环境准备
1.先安装 xlrd 模块,打开 cmd,输入 pip install xlrd 在线安装
>>pip install xlrd

6.1.2 基本操作
1.exlce 基本操作方法如下
# 打开 exlce 表格,参数是文件路径
data = xlrd.open_workbook('test.xlsx')
# table = data.sheets()[0] # 通 过 索 引 顺 序 获 取# table = data.sheet_by_index(0) # 通过索引顺序获取
table = data.sheet_by_name(u'Sheet1') # 通过名称获取
nrows = table.nrows # 获取总行数ncols = table.ncols # 获取总列数
# 获取一行或一列的值,参数是第几行 print table.row_values(0) # 获取第一行值print table.col_values(0) # 获取第一列值

6.1.3 excel 存放数据
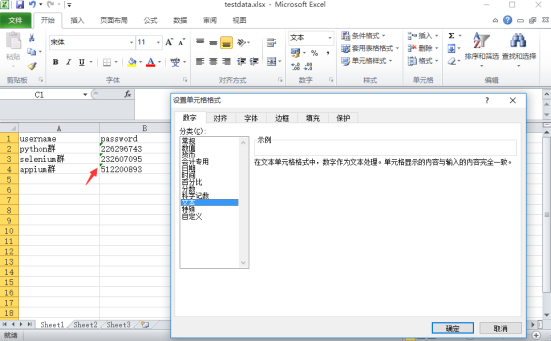
1. 在 excel 中存放数据,第一行为标题,也就是对应字典里面的 key 值,如:username, password
2. 如果 excel 数据中有纯数字的一定要右键》设置单元格格式》文本格式,要不然读取的数据是浮点数
(先设置单元格格式后编辑,编辑成功左上角有个小三角图标)
第 7 章 项目实战:git+jenkins 持续集成

7.1.1 项目结构
1. 新建一个工程(一定要创建工程),工程名称自己定义
2. 在工程的根目录新建一个脚本:run_main.py,用来执行全部用例
3. 在工程下创建以下几个 pakage:
--case:这个包放 test 开头的测试用例,也可以放一些封装接口的方法,如: loginblog(如果封装的接口比较多,也可以单独放一个包)
--common:这个包放一些公共的方法,如:读取 excel 文件方法,读取 mysql、oracle,logger.py 这个是封装日志的输入
--config:cfg.ini 这里是配置文件,如邮箱的一些参数:收件人,发件人,密码等,readConfig.py 用于读取配置文件
--logs:这里存放日志信息
--report:这里存放测试报告

福利
相关文章
- 74 python - 打飞机案例(显示控制玩具飞机-面向对象)
- Python 父类的 私有属性 和 私有方法
- Python 初始化方法
- 《Python编程快速上手——让繁琐工作自动化》——2.6 程序执行
- 《树莓派Python编程入门与实战》——3.7 创建Python脚本
- python pattern 类
- Python机器学习零基础理解DBSCAN聚类
- 《Python语言程序设计》——1.4 操作系统
- Google公司的python编码规范指南
- python 编程中的一个关于图片的库 imageio (读取照片RGB内容,转换照片格式)
- java的sha1加密,转化为python版本
- 【Python】:Python import导入上一级目录的文件和模块
- Python : 将字符串拆分为单个字母所组成的列表并合并单个字母
- [python]ModuleNotFoundError: No module named ‘paramiko‘