
【Java 线程】线程池 总结
一、什么是线程池?
为避免频繁地创建和销毁线程,我们可以复用创建的线程,具体操作为:
- 维护一些线程(数量固定),让他们处于活跃状态,当需要使用线程时,直接获取一个连接即可。
- 使用线程池后,创建线程变成了从线程池中获得空闲线程,关闭线程变成了向线程池归还线程,方便下次使用。

二、为什么要使用线程池?
创建线程池的目的:避免频繁地创建和销毁线程
为什么要避免频繁地创建和销毁线程?减少开销!
- 线程创建、关闭需要 花费时间:使用过多线程可能会出现:创建、销毁线程占用时间>真实工作时间,得不偿失。
- 线程本身 占用内存空间:大量线程会抢占内存,处理不当,会导致以下后果:
- ① Out of Memory 异常
- ② 回收大量线程,GC增压,延长GC停顿时间(若同时回收海量线程则问题更加严重)
- 便于管理:使用线程池可以进行统一的分配、调优和监控。
所以我们必须对线程数量、使用过程加以管控,线程池技术就这样应运而生了。
三、线程池配置参数
线程池位于 JUCjava.util.concurrent包
线程池概念图

1、核心线程池的实现
核心线程池 ThreadPoolExecutor 拥有许多关键属性、方法,理解它们对我们学习线程池十分重要,甚至可以尝试设计自己的线程池。
① 核心属性

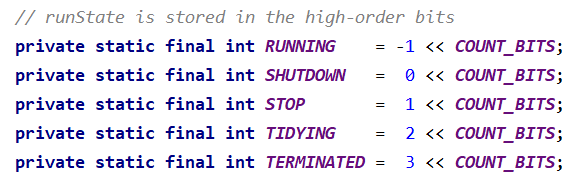
变量ctl:一个32位的AtomicInteger类型的原子对象,记录两个关键信息:
- 高 3 位:线程池运行状态
- 低 29 位:线程池任务 (工作) 数量
主锁 - mainLock
主锁(mainLock),对关键方法提供 “锁” 支持,避免自身操作线程不安全

③ 线程池运行状态 - 生命周期控制
源码注释:
The runState provides the main lifecycle control, taking on values:
RUNNING: Accept new tasks and process queued tasks
SHUTDOWN: Don’t accept new tasks, but process queued tasks
STOP: Don’t accept new tasks, don’t process queued tasks, and interrupt in-progress tasks
TIDYING: All tasks have terminated, workerCount is zero, the thread transitioning to state TIDYING will run the terminated() hook method
TERMINATED: terminated() has completed
翻译注释:
| 英文名 | 中文译名 | 状态解释说明 |
|---|---|---|
| RUNNING | 【运行态】 | 可接收新任务,且可处理队列中的任务 |
| SHUTDOWN | 【关闭态】 | 不再接受新提交的任务,但可以继续处理正在执行的任务和队列中的任务 |
| STOP | 【停止态】 | 不再接受新提交的任务,也不处理队列中的任务,中断当前正在执行任务的线程 |
| TIDYING | 【休整态 / 等待态】 | 表示所有的任务已执行完毕,workerCount (有效线程数) 为0,但线程池仍未终止 |
| TERMINATED | 【终止态】 | 线程池彻底终止运行。 |
状态转换:

| 线程状态 | 转换描述 | 解释说明 |
|---|---|---|
| RUNNING (运行态) | - | 初始线程池处于RUNNING状态,此时线程池中的任务为0 |
| RUNNING (运行态) → SHUTDOWN (关闭态) | On invocationi of shutdown() | 调用shutdown()方法 |
| RUNNING (运行态) / SHUTDOWN (关闭态) → STOP (停止态) | On invocation of shutdownNow() | 调用shutdownNow()方法 |
| SHUTDOWN (关闭态) → TIDYING (休整态) | When both queue and pool are empty | 任务队列、线程池均为空 |
| STOP (停止态) → TIDYING (休整态) | When pool is empty | 线程池为空 |
| TIDYING (休整态) → TERMINATED (终止态) | When the terminated() hook method has completed | terminated方法执行完毕 |
④ 全参构造方法
核心线程池的全参数构造方法:

构造方法参数含义、对应属性:
-
corePoolSize:指定线程池中的 核心线程 数量。

-
maximumPoolSize:指定线程池中的最大线程数量(核心线程 + 非核心线程 数量)。

-
keepAliveTime:线程池线程数量超过corePoolSize时,额外新创建线程(非核心线程)的存活时间(即多长时间会被销毁)
-
unit:keepAliveTime的时间单位,可从枚举类 TimeUnit 中取出相应值。


-
workQueue:任务队列 / 等待队列(workQueue),用于存储被提交但尚未被执行(未被分配线程,如:任务数 > 最大线程数)的任务,方便向任务第一时间分配线程,执行的是FIFIO原则(先进先出)。

-
threadFactory:线程工厂,用于创建线程(可通过对应的set、get方法指定相应规则的工厂对象)

-
handler:拒绝策略,定义任务过多难以应对时,拒绝(处理)任务的方式。

2、超负载:拒绝策略
ThreadPoolExecutor类最后一个参数指定了拒绝策略,而 RejectedExecutionHandler 是拒绝策略的相关接口,通过实现本接口,可以创建自己的拒绝策略。
拒绝策略,即当任务数量超过系统实际承载能力时,采取的补救措施。
- 通常由于压力太大而引起,线程池中的线程全部被占用,无法接纳新任务,同时等待队列也已经排满了,此时,引入一套解决问题的合理机制就显得尤为重要:
JDK内置四种拒绝策略:
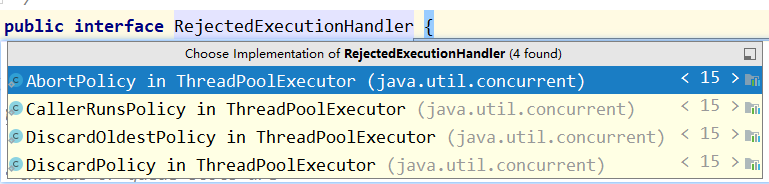
- AboutPolicy:不执行新任务,直接抛出异常,提示线程池已满,默认方式。
- CallRunsPolicy:直接调用execute()方法来执行当前任务。
- DiscardPolicy:丢弃任务,但不抛出异常,也不予以任何处理。
- DiscardOldestPolicy:丢弃最老(最先加入队列)的任务,再调用execute()将新任务添加进去。

3、线程池任务分配方案 - execute()方法
execute方法负责任务的分配工作:
- 判断核心线程池是否为空
- 判断任务队列是否有剩余空间
- 判断最大线程池是否有剩余线程数

以上代码的 任务处理流程 :

四、创建 ThreadPoolExecutor 线程池 相关方法
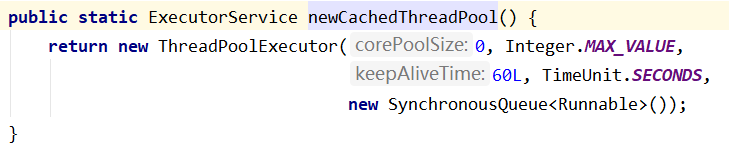
1、newCachedThreadPool() - 缓存线程池
创建一个可缓存线程池,如有需要,可灵活回收空闲线程,若无可回收,则新建线程。
先查看池中有没有以前建立的线程,如果有,就直接使用。如果没有,就建一个新的线程加入池中,缓存型池子通常用于执行一些生存期很短的异步型任务
| 参数 | 解释说明 |
|---|---|
| corePoolSize(核心线程数) | 0 |
| maximumPoolSize(最大线程数) | Integer.MAX_VALUE(过量创建可能会导致 Out of Memory) |
| keepAliveTime(非核心线程结束后存活时间)、unit(时间单位) | 60秒 |
| workQueue(任务队列) | SynchronousQueue<Runnable> 无缓冲等待队列 |
无参数方法:
可指定工厂的方法:

测试缓存线程池:
public static void main(String[] args) {
// 创建一个可缓存线程池
ExecutorService cachedThreadPool = Executors.newCachedThreadPool();
for (int i = 0; i < 10; i++) {
try {
// sleep可明显看到使用的是线程池里面以前的线程,没有创建新的线程
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
cachedThreadPool.execute(new Runnable() {
public void run() {
// 打印正在执行的缓存线程信息
System.out.println(Thread.currentThread().getName() + "正在被执行");
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}

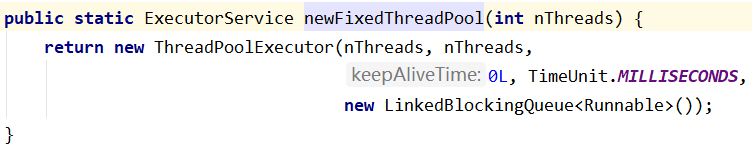
2、newFixedThreadPool() - 定长线程池
创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
| 参数 | 解释说明 |
|---|---|
| corePoolSize(核心线程数) | 传入参数 |
| maximumPoolSize(最大线程数) | 传入参数 |
| keepAliveTime(非核心线程结束后存活时间)、unit(时间单位) | 0毫秒 |
| workQueue(任务队列) | LinkedBlockQueue<Runnable> 无界缓存任务队列 |
单参数方法:
可指定工厂的方法:

测试定长线程池:
public static void main(String[] args) {
// 创建一个可重用固定个数的线程池(定长为3)
ExecutorService fixedThreadPool = Executors.newFixedThreadPool(3);
for (int i = 0; i < 10; i++) {
fixedThreadPool.execute(new Runnable() {
public void run() {
try {
// 打印正在执行的缓存线程信息
System.out.println(Thread.currentThread().getName() + "正在被执行");
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}

3、newScheduledThreadPool() - 周期性定长线程池
创建一个定长线程池,支持定时及周期性任务执行。
| 参数 | 解释说明 |
|---|---|
| corePoolSize(核心线程数) | 传入参数 |
| maximumPoolSize(最大线程数) | Integer.MAX_VALUE(过量创建可能会导致 Out of Memory) |
| keepAliveTime(非核心线程结束后存活时间)、unit(时间单位) | 0毫秒 |
| workQueue(任务队列) | DelayedWorkQueue<Runnable> 迟滞任务队列 |
单参数方法:

可指定工厂的方法:

测试周期定长线程池:
public static void main(String[] args) {
//创建一个定长线程池,支持定时及周期性任务执行——延迟执行
ScheduledExecutorService scheduledThreadPool = Executors.newScheduledThreadPool(5);
//延迟1秒后每3秒执行一次
scheduledThreadPool.scheduleAtFixedRate(new Runnable() {
public void run() {
System.out.println("延迟1秒后每3秒执行一次");
}
}, 1, 3, TimeUnit.SECONDS);
}

4、newSingleThreadExecutor() - 单任务线程池
创建一个单线程化的线程池,它只会用唯一的工作线程(串行)来执行任务,保证所有任务按照指定顺序(FIFO, LIFO, 优先级)执行。
| 参数 | 解释说明 |
|---|---|
| corePoolSize(核心线程数) | 1 |
| maximumPoolSize(最大线程数) | 1 |
| keepAliveTime(非核心线程结束后存活时间)、unit(时间单位) | 0毫秒 |
| workQueue(任务队列) | LinkedBlockQueue<Runnable> 无界缓存任务队列 |
无参数方法:
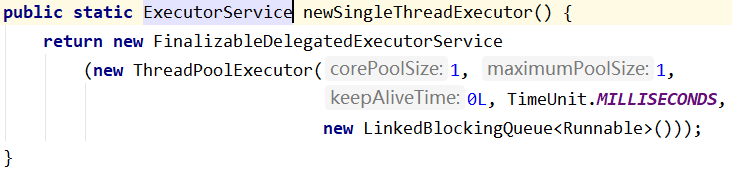
可指定工厂的方法:

测试单任务线程池:
public static void main(String[] args) {
//创建一个单线程化的线程池
ExecutorService singleThreadExecutor = Executors.newSingleThreadExecutor();
for (int i = 0; i < 10; i++) {
final int index = i;
singleThreadExecutor.execute(new Runnable() {
public void run() {
try {
//结果依次输出,相当于顺序执行各个任务
System.out.println(Thread.currentThread().getName() + "正在被执行,打印的值是:" + index);
Thread.sleep(500);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
}

5、newSingleThreadScheduledExecutor() - 周期性单任务线程池
创建一个单线程化的线程池,它只会用唯一的工作线程(串行)来执行任务,支持定时及周期性任务执行。
| 参数 | 解释说明 |
|---|---|
| corePoolSize(核心线程数) | 1 |
| maximumPoolSize(最大线程数) | 1 |
| keepAliveTime(非核心线程结束后存活时间)、unit(时间单位) | 0毫秒 |
| workQueue(任务队列) | DelayedWorkQueue<Runnable> 迟滞任务队列 |
无参数方法:
 可指定工厂的方法:
可指定工厂的方法:

周期性单任务线程池即定长为1的周期性定长线程池,这里我们不做测试。
五、合理的线程池大小
Java中获取CPU数量的代码:
Runtime.getRuntime().availableProcessors();
优化线程池大小所需要考虑的因素:
- CPU数量
- 内存大小
- 避免极端情况
估算线程池大小公式:
Ncpu = CPU数量
Ucpu = 目标CPU的使用率(0 ≤ Ucpu ≤ 1)
W/C = 等待时间 / 计算时间
最优线程池大小:
Nthread = Ncpu × Ucpu × (1 + W/C)
六、分治:Fork / Join 框架
“分而治之” 一直是一个非常有效地处理大量数据的方法。
假设我们需处理1000个数据,但并不具备这种能力,我们可以只处理10个,再分阶段处理100次,最终合成即可得到想要的结果。
在 Linux 中,方法 fork() 用来创建子进程,使得系统进程可以多执行一个分支。Java线程也采取了类似的命名。
| 方法 | 作用 |
|---|---|
| fork | 开启线程 |
| join | 等待 |
我们不能毫无顾忌地使用 fork() 方法开启线程进行处理,可能会因开启过多的线程而严重影响性能。
※ ForkJoinPool线程池
在JDK中,给出了ForkJoinPool线程池,我们可以将线程提交给它进行处理,节省资源。

我们向ForkJoinPool 线程池提交 ForkJoinTask 任务,它支持 fork() 方法分解、 join() 方法等待的任务。ForkJoinTask为模板类,它实现了 Future接口,其下辖两个子类RecursiveTask(返回V类型)、RecursiveAction(无返回值),这三个类均为抽象类。
无参数构造方法:

全参数构造方法:

对于两种构造方法,无特殊需求,一般使用无参构造方法,全参数构造方法作为了解即可。
利用 Fork/Join 框架计算数列(等差数列:差值为1)求和:
public class CountTask extends RecursiveTask<Long> {
private static final int THRESHOLD = 10000; //任务不分割阈值
private long start; //起点
private long end; //终点
/**
* 构造方法初始化变量
* @param start 起点
* @param end 终点
*/
public CountTask(long start, long end) {
this.start = start;
this.end = end;
}
/**
* 重写 compute()方法
* @return 返回子任务结果
*/
@Override
protected Long compute() {
long sum = 0; //记录总结果
boolean canCompute = (end - start) < THRESHOLD; //小于阈值可以直接运算,否则分割任务
if (canCompute) {
for (long i = start; i <= end; i++) {
sum += i;
}
} else {
long step = (start + end) / 100; //分割为100个子任务
ArrayList<CountTask> subTasks = new ArrayList<>(); //存储各个子任务
long pos = start;
for (int i = 0; i < 100; i++) {
long lastOne = pos + step;
if (lastOne > end) lastOne = end;
CountTask subTask = new CountTask(pos, lastOne);
pos += step + 1;
subTasks.add(subTask); //添加子任务
subTask.fork(); //执行子任务
}
for (CountTask task : subTasks) {
sum += task.join(); //将子任务结果并入总结果
}
}
return sum; //返回总结果
}
}
在main方法中创建对象并调用函数,计算0~300000等差数列的和:
//在main方法中创建对象并调用函数,计算0~300000等差数列的和
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
CountTask task = new CountTask(0, 300000L);
ForkJoinTask<Long> result = forkJoinPool.submit(task);
try {
long res = result.get();
System.out.println("总和:" + res);
} catch (Exception e) {
e.printStackTrace();
}
}
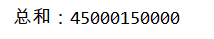
※ newWorkStealingPool()
newWorkStealingPool适合使用用于解决耗时操作的问题,newWorkStealingPool不是ThreadPoolExecutor的扩展,它是新的线程池类ForkJoinPool的扩展,能够较为合理地分配CPU资源,它是一种具有抢占式操作的线程池。
//获取可用CPU数量
Runtime.getRuntime().availableProcessors();
以上代码可获取可用CPU数量,而全参数
无参数方法:
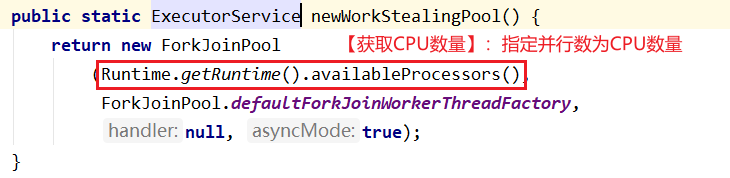
可指定并行数量的方法:

相关文章
- Java并发编程(02):线程核心机制,基础概念扩展
- java线程共享受限资源 解决资源竞争 thinking in java4 21.3
- 【转】Java并发编程:如何创建线程?
- JAVA线程池代码浅析
- 遇见AI,从Java到数据挖掘。
- java线程池讲解面试
- Java线程中yield与join方法的区别
- Core Java-多线程-线程的生命周期
- 【转载】java实现的局域网聊天软件
- 《Java线程与并发编程实践》- 第1章 Thread和Runnable
- 《21天学通Java(第6版)》—— 1.5 组织类和类行为
- java 线程间的通信 (wait / notify / notifyAll)
- java中volatile关键字的含义--volatile并不能做到线程安全
- Java Efficient data transfer through zero copy
- Java线程锁,synchronized、wait、notify详解--java 管程
- Java学习-081-多线程14:线程状态示例
- Java学习-077-多线程10:线程资源同步问题实例演示
- java中的类型擦除type erasure
- Java学习路线:day13 面向对象(中)2
- Five ways to maximize Java NIO and NIO.2--转
- JAVA中取整数的四种方法有哪些?面试篇(第五天)
- Java 线程同步(wait、notify、notifyAll)
- Java synchronized关键字实现线程同步