
数据分析-day06-pandas-dataFrame案例分析1(方法一):获取title字段中包含物流运输业名称作为分类,统计各个分类的条数
数据格式:
目的数据:
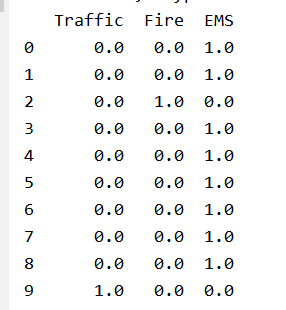
目的:获取title字段中包含物流运输业名称作为分类,统计各个分类的条数
# -*- coding: utf-8 -*-
# @File : pandas_dataframe_classs_sum_demo.py
# @Date : 2020-01-06 16:38
# @Author : admin
'''
获取title字段中包含物流运输业名称作为分类,统计各个分类的条数
'''
import pandas as pd
from matplotlib import pyplot as plt
import numpy as np;
df=pd.read_csv("../../data/911.csv");
df=df.head(10);
print(df.head(5))
#前5行的title列的数据
#print(df[:5]["title"])
###########################################################截取字符串,获取分类#################################
print("##################step1:截取字符串,获取分类############:")
jieque_array= df["title"].str.split(": ").tolist();
distinct_list=list(set([m[0] for m in jieque_array]));
print(jieque_array)
print(distinct_list)
###########################################################构建全0的矩阵#############################
print("##################step2:构建全0的矩阵####################:");
zeroes_array=pd.DataFrame(np.zeros((df.shape[0],len(distinct_list))),columns=distinct_list);
print(zeroes_array)
###########################################################修改赋值#############################
print("##################step3: 修改赋值####################:");
#方法一
for cat in distinct_list:
print(cat)
#zeroes_array[cat] 遍历的是列,相当于zeroes_array['EMS'],
print(df["title"].str.contains(cat)) #boolean 索引
zeroes_array[cat][df["title"].str.contains(cat)]=1;#表达的意思是:构建的全0矩阵中的某列,df原数据的每一行,的title列包含这个列名称,则赋值为1
print(zeroes_array)
'''
#方法二
for m in range(df.shape[0]):
zeroes_array.loc[m,jieque_array[m][0]]=1 #m行的jieque_array[m][0]列,在jieque_array中存在,赋值为1
print(zeroes_array)
'''
###########################################################按列即按类别求和#############################
print("####################step4:按列即按类别求和####################:");
df_sum=zeroes_array.sum(axis=0) #axis=0 按列
print(df_sum)结果:
lat lng ... addr e
0 40.297876 -75.581294 ... REINDEER CT & DEAD END 1
1 40.258061 -75.264680 ... BRIAR PATH & WHITEMARSH LN 1
2 40.121182 -75.351975 ... HAWS AVE 1
3 40.116153 -75.343513 ... AIRY ST & SWEDE ST 1
4 40.251492 -75.603350 ... CHERRYWOOD CT & DEAD END 1
[5 rows x 9 columns]
##################step1:截取字符串,获取分类############:
[['EMS', 'BACK PAINS/INJURY'], ['EMS', 'DIABETIC EMERGENCY'], ['Fire', 'GAS-ODOR/LEAK'], ['EMS', 'CARDIAC EMERGENCY'], ['EMS', 'DIZZINESS'], ['EMS', 'HEAD INJURY'], ['EMS', 'NAUSEA/VOMITING'], ['EMS', 'RESPIRATORY EMERGENCY'], ['EMS', 'SYNCOPAL EPISODE'], ['Traffic', 'VEHICLE ACCIDENT -']]
['Traffic', 'Fire', 'EMS']
##################step2:构建全0的矩阵####################:
Traffic Fire EMS
0 0.0 0.0 0.0
1 0.0 0.0 0.0
2 0.0 0.0 0.0
3 0.0 0.0 0.0
4 0.0 0.0 0.0
5 0.0 0.0 0.0
6 0.0 0.0 0.0
7 0.0 0.0 0.0
8 0.0 0.0 0.0
9 0.0 0.0 0.0
##################step3: 修改赋值####################:
Traffic
0 False
1 False
2 False
3 False
4 False
5 False
6 False
7 False
8 False
9 True
Name: title, dtype: bool
Fire
0 False
1 False
2 True
3 False
4 False
5 False
6 False
7 False
8 False
9 False
Name: title, dtype: bool
EMS
0 True
1 True
2 False
3 True
4 True
5 True
6 True
7 True
8 True
9 False
Name: title, dtype: bool
Traffic Fire EMS
0 0.0 0.0 1.0
1 0.0 0.0 1.0
2 0.0 1.0 0.0
3 0.0 0.0 1.0
4 0.0 0.0 1.0
5 0.0 0.0 1.0
6 0.0 0.0 1.0
7 0.0 0.0 1.0
8 0.0 0.0 1.0
9 1.0 0.0 0.0
####################step4:按列即按类别求和####################:
Traffic 1.0
Fire 1.0
EMS 8.0
dtype: float64
相关文章
- 案例 惯导的粗对准过程
- Google Earth Engine(GEE)——乌干达的地表温度案例分析(时序分析和结果导出)
- 【MATLAB教程案例31】基于matlab的人脸检测相关算法的仿真与分析——肤色模型与形态学图像处理方法
- 【FPGA教程案例38】通信案例8——基于FPGA的串并-并串数据传输
- 【FPGA教程案例12】基于vivado核的复数乘法器设计与实现
- 【FPGA教程案例2】基于vivado核的NCO正弦余弦发生器设计与实现
- 商汤科技面试——实习面试案例总结
- 渗透测试-SQL注入之sqlmap的使用方法及实战案例
- 图解css6:核心技术与案例实战. 1.3 渐进增强
- 大数据与机器学习:实践方法与行业案例.1.1 数据的基本形态
- 大数据与机器学习:实践方法与行业案例.2.1 数据闭环
- 大数据与机器学习:实践方法与行业案例.3.5 本章小结
- 《AR与VR开发实战》——2.2 创建Vuforia案例
- FlinkCEP模式API介绍及入门案例
- Flume+Kafka整合案例实现
- Python 类方法综合案例
- 【快应用】任意拖动图标实现案例
- Flink性能测试case案例
- No.045<软考>《(高项)备考大全》【专项1】《案例分析 - 简介、方法、技巧、理论》
- 《数据科学R语言实践:面向计算推理与问题求解的案例研究法》一一1.5 预测位置的最近邻方法
- 大数据与机器学习:实践方法与行业案例.2.4 作业调度
- 大数据与机器学习:实践方法与行业案例.2.5 监控和预警
- 4个错误使用JavaScript数组方法的案例
- JS学习第3天——Web API之DOM(获取元素、操作元素、节点操作、insertAjacentHtml()方法、双击禁止选中文字、添加删除留言案例)
- final修饰和StringBuffer的几个案例(拼接,反转,对称操作)