
干货|大数据Hadoop快速入门教程
1、Hadoop生态概况
Hadoop是一个由Apache基金会所开发的分布式系统集成架构,用户可以在不了解分布式底层细节情况下,开发分布式程序,充分利用集群的威力来进行高速运算与存储,具有可靠、高效、可伸缩的特点。
Hadoop的核心是YARN,HDFS,Mapreduce,常用模块架构如下
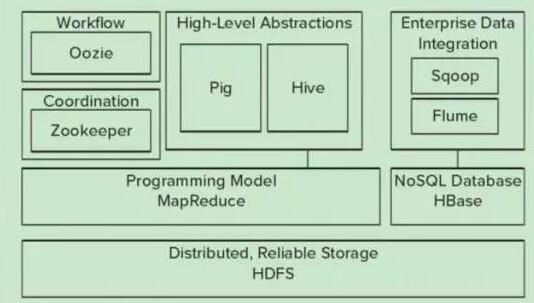
2、HDFS
源自谷歌的GFS论文,发表于2013年10月,HDFS是GFS的克隆版,HDFS是Hadoop体系中数据存储管理的基础,它是一个高度容错的系统,能检测和应对硬件故障
HDFS简化了文件一致性模型,通过流式数据访问,提供高吞吐量应用程序数据访问功能,适合带有大型数据集的应用程序,它提供了一次写入多次读取的机制,数据以块的形式,同时分布在集群不同物理机器
3、Mapreduce
源自于谷歌的MapReduce论文,用以进行大数据量的计算,它屏蔽了分布式计算框架细节,将计算抽象成map和reduce两部分
4、HBASE(分布式列存数据库)
源自谷歌的Bigtable论文,是一个建立在HDFS之上,面向列的针对结构化的数据可伸缩,高可靠,高性能分布式和面向列的动态模式数据库
5、zookeeper
解决分布式环境下数据管理问题,统一命名,状态同步,集群管理,配置同步等
6、HIVE
由Facebook开源,定义了一种类似sql查询语言,将SQL转化为mapreduce任务在Hadoop上面执行
7、flume
日志收集工具
8、yarn分布式资源管理器
是下一代mapreduce,主要解决原始的Hadoop扩展性较差,不支持多种计算框架而提出的,架构如下
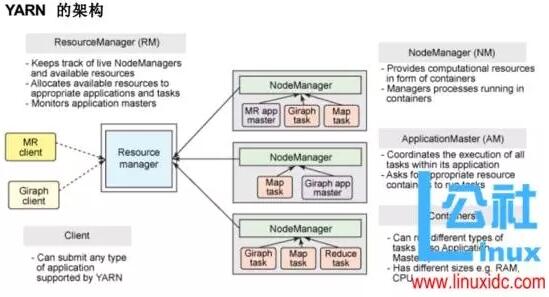
9、spark
spark提供了一个更快更通用的数据处理平台,和Hadoop相比,spark可以让你的程序在内存中运行
10、kafka
分布式消息队列,主要用于处理活跃的流式数据
11、Hadoop伪分布式部署
目前而言,不收费的Hadoop版本主要有三个,都是国外厂商,分别是
1、Apache原始版本 2、CDH版本,对于国内用户而言,绝大多数选择该版本 3、HDP版本这里我们选择CDH版本hadoop-2.6.0-cdh5.8.2.tar.gz,环境是CentOS7.1,jdk需要1.7.0_55以上
[root@hadoop1 ~]# useradd hadoop
我的系统默认自带的java环境如下
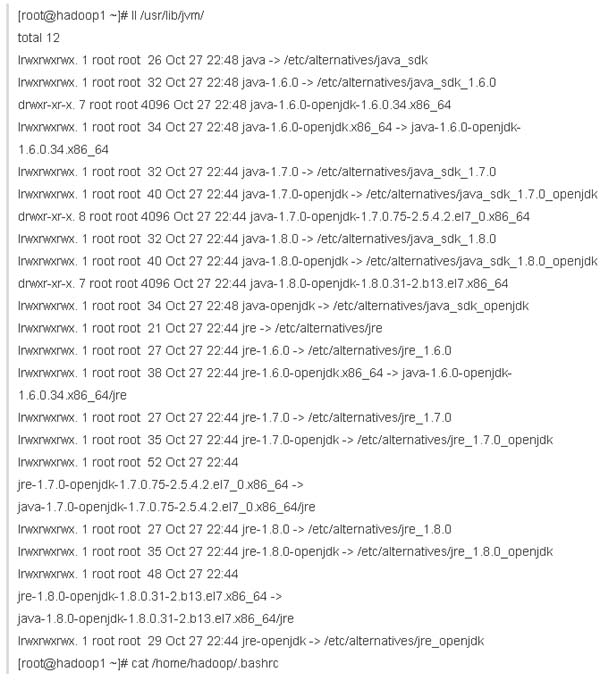
增加如下环境变量

做好如下授权

这里以Hadoop用户来进行管理和启动Hadoop的各种服务

查看服务启动情况
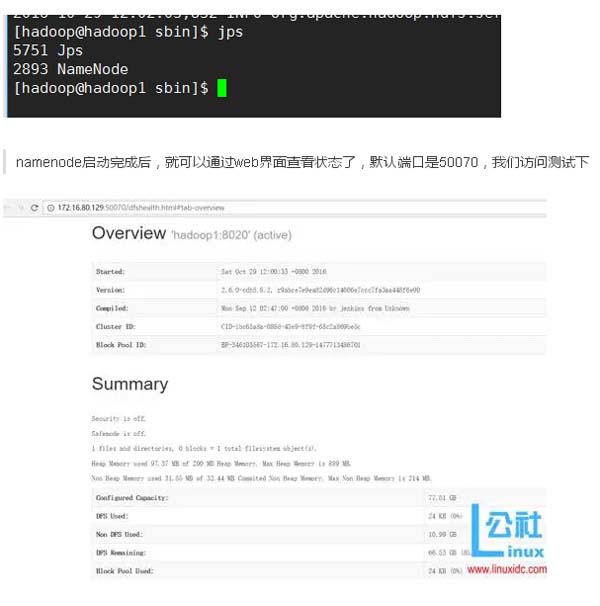
本文作者:佚名
来源:51CTO
大数据基础之初识Hadoop 你好看官,里面请!今天笔者讲的是大数据基础:初识Hadoop。不懂可以在评论区留言,我看到会及时回复。 注意:本文仅用与学习参考,不可用于商业用途。
大数据知识面试题-Hadoop Block与Splite区别:Block是HDFS物理上把数据分成一块一块;数据切片只是在逻辑上对输入进行分片,并不会在磁盘上将其切分成片进行存储。如下图所示,一个512M的文件在HDFS上存储时,默认一个block为128M,那么该文件需要4个block进行物理存储;若对该文件进行切片,假设以100M大小进行切片,该文件在逻辑上需要切成6片,则需要6个MapTask任务进行处理。
“后 Hadoop 时代”,大数据从业者如何应对新技术趋势带来的挑战? 对于大数据从业者们来说,开源大数据项目热力迁徙背后的技术发展逻辑及如何应对新技术趋势带来的挑战?刘京娟、贾扬清、王峰在此解读。
相关文章
- 大数据-Hadoop-HDFS(二):HDFS读写数据流程
- 大数据-Hadoop-搭建(一):搭建Hadoop完全分布式集群(在VMware中的Linux虚拟机)【CentOS6】【独立安装Apache Hadoop】
- 大数据框架Hadoop主要模块介绍
- Hadoop错误之namenode宕机的数据恢复
- 【最全的大数据面试系列】Hadoop面试题大全(一)
- TensorFlow的开源与Hadoop的开源有什么不同?
- hadoop学习笔记(八):hadoop2.x的高可用环境搭建
- 搭建分布式hadoop环境的前期准备---需要检查的几个点
- Hadoop Brief
- Hadoop快速入门
- 大数据应用还处于早期——专访Hadoop之父Doug Cutting
- 你想知道的关于Hadoop数据资源池的一切
- 大数据的下一个五年:Hadoop将推动数据平民化
- Hadoop(十七)之MapReduce作业配置与Mapper和Reducer类
- 【Hadoop】HDFS冗余数据块的自动删除
- 大数据初探——Hadoop历史
- 大数据Spark “蘑菇云”行动第102课:Hive性能调优之底层Hadoop引擎调优剖析和最佳实践
- hadoop fs命令
- Hadoop恢复namenode数据
- 【转载】Hadoop官方文档翻译——HDFS Architecture 2.7.3
- 大数据Hadoop(三十):Hadoop3.x的介绍
- Hadoop学习之SecondaryNameNode
- Hadoop、HBase、Hive、Spark
- Hadoop YARN 的工作流程简述