
Apache CarbonData的Update/Delete功能设计实现
本文将介绍Apache CarbonData 0.3.0的Update/Delete功能设计实现。
CarbonData是由华为开发、开源并支持Apache Hadoop的列式存储文件格式,支持索引、压缩以及解编码等,其目的是为了实现同一份数据达到多种需求,而且能够实现更快的交互查询。目前该项目正处于Apache孵化过程中。
当前,CarbonData暂不支持修改表中已经存在的数据。但是在现实情况下,我们可能很希望这个功能,比如修改维度表,事实表的数据校正以及数据清洗等。很多使用CarbonData的用户很希望其能够提供数据的修改和删除功能。为此,社区已经有人提了Issue(CARBONDATA-440),其目标就是为CarbonData提供Update/Delete功能,这个功能应该会在CarbonData 0.3.0版本发布。本文将介绍CarbonData的Update/Delete功能设计实现。下面是实现这个功能的高层次设计目标:
(1)、提供标准的SQL接口,以便能够执行更新和删除操作;
(2)、对CarbonData表执行更新和删除操作的时候,不需要对已经存在的整个CarbonData块重写,而是将修改写到差异文件中(differential files);
(3)、在更新和删除操作之后,CarbonData readers应该能够跳过删除的记录,并且能够无缝地读取更新的记录,而这些操作不需要用户更新自己的应用程序。
下面我将详细地介绍 CarbonData 的修改和删除实现设计。
更新操作实现
我们都知道,CarbonData的数据是存储在HDFS之上,而HDFS中的文件是不可修改的(immutable),所以CarbonData的数据块并不能原地进行修改。更新数据的一种方法就是删除和重写整个数据块。然而这种方法的效率很低,会导致性能瓶颈。其实我们可以把更新操作认为是先"删除",然后"插入",这也就是CarbonData中更新的实现。下面我将详细地介绍CarbonData的更新操作实现:CarbonData的更新操作分为以下两步:
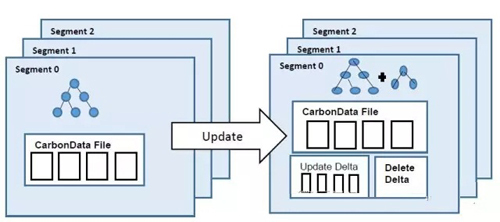
1、第一步包括两个部分:
(1)、首先,CarbonData能够通过执行过滤和Join操作识别出需要更新的行。为了能够唯一标识行数据,CarbonData会使用到ROWID属性。一旦需要更新的数据被标识后,这些数据将会在单独的文件中被标识为deleted,而且这些文件是存放在当前表的目录下,这些文件被称为"Delete Delt"。
(2)、然后,CarbonData将会从源表中收集需要更新的列值并组成新的一行。新的行数据是由更新后的列值和目标表现有的列值数据组成的。这些更新的行数据将会在Spark处理层组成一个源RDD。
2、第二步:CarbonData将会使用现有的数据加载方法将源RDD中的行数据转换成CarbobData数据格式。这个操作类似于数据的增量加载。这个新创建的CarbonData文件称为"Update Delta"。Update Delta文件将存储在同一个segment中,而且Update Delta本身拥有btree和块级别的统计,正如正常的CabonData文件。这个新的btree应该追加到全局的btree中,并且缓存起来。
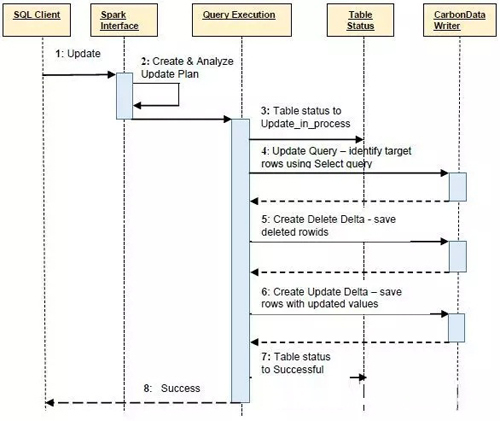
下面就是CabonData更新操作的时序图:
删除操作的实现
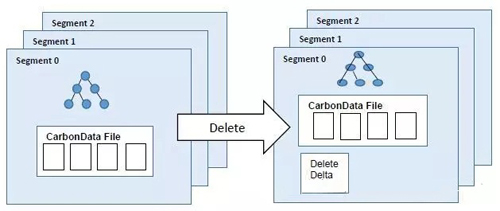
在删除数据的情况,CarbonData也是通过过滤和Join操作来识别需要删除的行。为了能够唯一标识行数据,CarbonData会使用到ROWID属性。一旦需要删除的数据被标识后,这些数据将会在单独的文件中被标识为deleted,这个文件也称为"Delete Delta"文件。CarbonData记录扫描程序将会把这些删除的文件排除到结果集之外。在删除操作之后,CarbonData不需要更新全局字典表,因为字典表中有些entries对其他的segment还是有效的。
删除操作的原子性
CarbonData的删除操作具有原子性,也就是说,删除的数据要么全部被删除,要么全部都没删除。删除操作产生的Delete delta文件在删除操作仍然进行时,对readers事不可见的;只有删除操作成功进行,新删除的行数据才会对readers可见。删除的操作如下图所示:
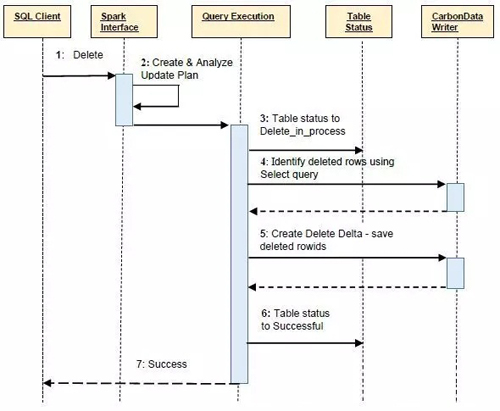
下面就是CabonData删除操作的时序图:
文件合并
对每次更新操作,都会产生update delta 和 delete delta文件,随着频繁地更新和删除操作,会产生越来越多的delta文件。这将会产生许多小文件,这可能会影响scan操作的性能,所以我们需要将这些delta文件合并成单独的delta文件。将许多个delta文件合并成一个delta文件的操作称为compaction或 minor compaction. 操作如下:
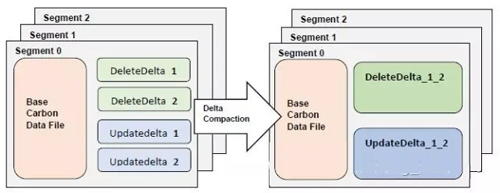
而且compaction操作可以通过配置达到多少个delta files来触发。在删除或者更新操作之后,如果delta文件的数量达到了配置的阈值,compaction操作将会触发。
本文作者:佚名
来源:51CTO
MSE 支持 Apache Shenyu 网关实现全链路灰度 我们希望可以对这些服务的新版本同时进行小流量灰度验证,这就是微服务架构中特有的全链路灰度场景,通过构建从网关到整个后端服务的环境隔离来对多个不同版本的服务进行灰度验证。
MSE支持Apache Shenyu网关实现全链路灰度 微服务引擎MSE面向业界主流开源微服务项目, 提供注册配置中心和分布式协调(原生支持Nacos/ZooKeeper/Eureka)、云原生网关(原生支持Ingress/Envoy)、微服务治理(原生支持Spring Cloud/Dubbo/Sentinel,遵循 OpenSergo 服务治理规范)能力。
通过 MSE 实现基于Apache APISIX的全链路灰度 微服务引擎MSE面向业界主流开源微服务项目, 提供注册配置中心和分布式协调(原生支持Nacos/ZooKeeper/Eureka)、云原生网关(原生支持Ingress/Envoy)、微服务治理(原生支持Spring Cloud/Dubbo/Sentinel,遵循 OpenSergo 服务治理规范)能力。
在阿里云ECS上配置Apache+wsgi实现blog的部署 利用Django框架搭建个人博客网站,将网站通过Apache+wsgi部署到阿里云服务器。主要采用html、css、javascript作为前端,并使用了JQuery框架和Bootstrap框架;采用django框架作为后台开发技术、后台数据库使用mysql。本篇幅着重于Django框架介绍、数据库mysql配置和服务器部署。
使用 Apache Doris HyperLogLog 实现近似去重 在实际的业务场景中,随着业务数据量越来越大,对数据去重的压力也越来越大,当数据达到一定规模之后,使用精准去重的成本也越来越高,在业务可以接受的情况下,通过近似算法来实现快速去重降低计算压力是一个非常好的方式,本文主要介绍 Doris 提供的 HyperLogLog(简称 HLL)是一种近似去重算法。
基于Ansible实现Apache Doris快速部署运维指南 Apache Doris是一个现代化的MPP分析型数据库产品。仅需亚秒级响应时间即可获得查询结果,有效地支持实时数据分析。Apache Doris的分布式架构非常简洁,易于运维,并且可以支持10PB以上的超大数据集。
相关文章
- 解决apache httpd列出目录列表中文乱码问题
- Apache Kafka源码分析 – Broker Server
- Apache Storm 官方文档 —— 内部技术实现
- Apache Tomcat安全绕过漏洞(CVE-2018-1305)
- HTTP 笔记与总结(7)HTTP 缓存(配合 Apache 服务器)
- Apache Commons Configuration远程代码执行漏洞(CVE-2022-33980)分析&复现
- Apache + Tomcat +mod_jk实现集群服务
- 《PHP、MySQL和Apache入门经典(第5版)》一一2.1 MySQL的当前版本和未来版本
- 使用Apache的Base64类实现Base64加解密
- 查看 apache 的编译参数
- Linkedin官方kafka性能压测-kafkaBenchmarking Apache Kafka: 2 Million Writes Per Second (On Three Cheap Machines)
- Apache网页文件目录模板
- openssl命令行将pfx格式转.key和.crt文件,Apache适用
- HttpClient_用Apache HttpClient实现URL重定向
- Centos部署nagios+apache实现服务器监控
- apache开源项目 -- tajo
- apache开源项目--lucence
- apache virtualhost配置 apache配置多个网站