
使用C++的StringBuilder提升4350%的性能
经常出现客户端打电话抱怨说:你们的程序慢如蜗牛。你开始检查可能的疑点:文件IO,数据库访问速度,甚至查看web服务。 但是这些可能的疑点都很正常,一点问题都没有。
你使用最顺手的性能分析工具分析,发现瓶颈在于一个小函数,这个函数的作用是将一个长的字符串链表写到一文件中。
你对这个函数做了如下优化:将所有的小字符串连接成一个长的字符串,执行一次文件写入操作,避免成千上万次的小字符串写文件操作。
这个优化只做对了一半。
你先测试大字符串写文件的速度,发现快如闪电。然后你再测试所有字符串拼接的速度。
好几年。
怎么回事?你会怎么克服这个问题呢?
你或许知道.net程序员可以使用StringBuilder来解决此问题。这也是本文的起点。
如果google一下“C++ StringBuilder”,你会得到不少答案。有些会建议(你)使用std::accumulate,这可以完成几乎所有你要实现的:
#include iostream // for std::cout, std::endl
#include string // for std::string
#include vector // for std::vector
#include numeric // for std::accumulate
int main() {
using namespace std;
vector string vec = { "hello", " ", "world" };
string s = accumulate(vec.begin(), vec.end(), s);
cout s endl; // prints hello world to standard output.
return 0;
}
目前为止一切都好:当你有超过几个字符串连接时,问题就出现了,并且内存再分配也开始积累。
std::string在函数reserver()中为解决方案提供基础。这也正是我们的意图所在:一次分配,随意连接。
字符串连接可能会因为繁重、迟钝的工具而严重影响性能。由于上次存在的隐患,这个特殊的怪胎给我制造麻烦,我便放弃了Indigo(我想尝试一些C++11里的令人耳目一新的特性),并写了一个StringBuilder类的部分实现:
// Subset of http://msdn.microsoft.com/en-us/library/system.text.stringbuilder.aspx
template typename chr
class StringBuilder {
typedef std::basic_string chr string_t;
typedef std::list string_t container_t; // Reasons not to use vector below.
typedef typename string_t::size_type size_type; // Reuse the size type in the string.
container_t m_Data;
size_type m_totalSize;
void append(const string_t src) {
m_Data.push_back(src);
m_totalSize += src.size();
// No copy constructor, no assignement.
StringBuilder(const StringBuilder
StringBuilder operator = (const StringBuilder
public:
StringBuilder(const string_t src) {
if (!src.empty()) {
m_Data.push_back(src);
m_totalSize = src.size();
StringBuilder() {
m_totalSize = 0;
// TODO: Constructor that takes an array of strings.
StringBuilder Append(const string_t src) {
append(src);
return *this; // allow chaining.
// This one lets you add any STL container to the string builder.
template class inputIterator
StringBuilder Add(const inputIterator first, const inputIterator afterLast) {
// std::for_each and a lambda look like overkill here.
// b Not /b using std::copy, since we want to update m_totalSize too.
for (inputIterator f = first; f != afterLast; ++f) {
append(*f);
return *this; // allow chaining.
StringBuilder AppendLine(const string_t src) {
static chr lineFeed[] { 10, 0 }; // C++ 11. Feel the love!
m_Data.push_back(src + lineFeed);
m_totalSize += 1 + src.size();
return *this; // allow chaining.
StringBuilder AppendLine() {
static chr lineFeed[] { 10, 0 };
m_Data.push_back(lineFeed);
++m_totalSize;
return *this; // allow chaining.
// TODO: AppendFormat implementation. Not relevant for the article.
// Like C# StringBuilder.ToString()
// Note the use of reserve() to avoid reallocations.
string_t ToString() const {
string_t result;
// The whole point of the exercise!
// If the container has a lot of strings, reallocation (each time the result grows) will take a serious toll,
// both in performance and chances of failure.
// I measured (in code I cannot publish) fractions of a second using reserve, and almost two minutes using +=.
result.reserve(m_totalSize + 1);
//result = std::accumulate(m_Data.begin(), m_Data.end(), result); // This would lose the advantage of reserve
for (auto iter = m_Data.begin(); iter != m_Data.end(); ++iter) {
result += *iter;
return result;
// like javascript Array.join()
string_t Join(const string_t delim) const {
if (delim.empty()) {
return ToString();
string_t result;
if (m_Data.empty()) {
return result;
// Hope we dont overflow the size type.
size_type st = (delim.size() * (m_Data.size() - 1)) + m_totalSize + 1;
result.reserve(st);
// If you need reasons to love C++11, here is one.
struct adder {
string_t m_Joiner;
adder(const string_t s): m_Joiner(s) {
// This constructor is NOT empty.
// This functor runs under accumulate() without reallocations, if l has reserved enough memory.
string_t operator()(string_t l, const string_t r) {
l += m_Joiner;
l += r;
return l;
} adr(delim);
auto iter = m_Data.begin();
// Skip the delimiter before the first element in the container.
result += *iter;
return std::accumulate(++iter, m_Data.end(), result, adr);
}; // class StringBuilder
有趣的部分
函数ToString()使用std::string::reserve()来实现最小化再分配。下面你可以看到一个性能测试的结果。
函数join()使用std::accumulate(),和一个已经为首个操作数预留内存的自定义函数。
你可能会问,为什么StringBuilder::m_Data用std::list而不是std::vector?除非你有一个用其他容器的好理由,通常都是使用std::vector。
好吧,我(这样做)有两个原因:
1. 字符串总是会附加到一个容器的末尾。std::list允许在不需要内存再分配的情况下这样做;因为vector是使用一个连续的内存块实现的,每用一个就可能导致内存再分配。
2. std::list对顺序存取相当有利,而且在m_Data上所做的唯一存取操作也是顺序的。
你可以建议同时测试这两种实现的性能和内存占用情况,然后选择其中一个。
为了测试性能,我从Wikipedia获取一个网页,并将其中一部分内容写死到一个string的vector中。
随后,我编写两个测试函数,第一个在两个循环中使用标准函数clock()并调用std::accumulate()和StringBuilder::ToString(),然后打印结果。
void TestPerformance(const StringBuilder wchar_t tested, const std::vector std::wstring tested2) {
const int loops = 500;
clock_t start = clock(); // Give up some accuracy in exchange for platform independence.
for (int i = 0; i loops; ++i) {
std::wstring accumulator;
std::accumulate(tested2.begin(), tested2.end(), accumulator);
double secsAccumulate = (double) (clock() - start) / CLOCKS_PER_SEC;
start = clock();
for (int i = 0; i loops; ++i) {
std::wstring result2 = tested.ToString();
double secsBuilder = (double) (clock() - start) / CLOCKS_PER_SEC;
using std::cout;
using std::endl;
cout "Accumulate took " secsAccumulate " seconds, and ToString() took " secsBuilder " seconds."
" The relative speed improvement was " ((secsAccumulate / secsBuilder) - 1) * 100 "%"
endl;
}
第二个则使用更精确的Posix函数clock_gettime(),并测试StringBuilder::Join()。
#ifdef __USE_POSIX199309
// Thanks to a href="http://www.guyrutenberg.com/2007/09/22/profiling-code-using-clock_gettime/" Guy Rutenberg /a .
timespec diff(timespec start, timespec end) {
timespec temp;
if ((end.tv_nsec-start.tv_nsec) 0) {
temp.tv_sec = end.tv_sec-start.tv_sec-1;
temp.tv_nsec = 1000000000+end.tv_nsec-start.tv_nsec;
} else {
temp.tv_sec = end.tv_sec-start.tv_sec;
temp.tv_nsec = end.tv_nsec-start.tv_nsec;
return temp;
void AccurateTestPerformance(const StringBuilder wchar_t tested, const std::vector std::wstring tested2) {
const int loops = 500;
timespec time1, time2;
// Dont forget to add -lrt to the g++ linker command line.
////////////////
// Test std::accumulate()
////////////////
clock_gettime(CLOCK_THREAD_CPUTIME_ID, time1);
for (int i = 0; i loops; ++i) {
std::wstring accumulator;
std::accumulate(tested2.begin(), tested2.end(), accumulator);
clock_gettime(CLOCK_THREAD_CPUTIME_ID, time2);
using std::cout;
using std::endl;
timespec tsAccumulate =diff(time1,time2);
cout tsAccumulate.tv_sec ":" tsAccumulate.tv_nsec endl;
////////////////
// Test ToString()
////////////////
clock_gettime(CLOCK_THREAD_CPUTIME_ID, time1);
for (int i = 0; i loops; ++i) {
std::wstring result2 = tested.ToString();
clock_gettime(CLOCK_THREAD_CPUTIME_ID, time2);
timespec tsToString =diff(time1,time2);
cout tsToString.tv_sec ":" tsToString.tv_nsec endl;
////////////////
// Test join()
////////////////
clock_gettime(CLOCK_THREAD_CPUTIME_ID, time1);
for (int i = 0; i loops; ++i) {
std::wstring result3 = tested.Join(L",");
clock_gettime(CLOCK_THREAD_CPUTIME_ID, time2);
timespec tsJoin =diff(time1,time2);
cout tsJoin.tv_sec ":" tsJoin.tv_nsec endl;
////////////////
// Show results
////////////////
double secsAccumulate = tsAccumulate.tv_sec + tsAccumulate.tv_nsec / 1000000000.0;
double secsBuilder = tsToString.tv_sec + tsToString.tv_nsec / 1000000000.0;
double secsJoin = tsJoin.tv_sec + tsJoin.tv_nsec / 1000000000.0;
cout "Accurate performance test:" endl " Accumulate took " secsAccumulate " seconds, and ToString() took " secsBuilder " seconds." endl
" The relative speed improvement was " ((secsAccumulate / secsBuilder) - 1) * 100 "%" endl
" Join took " secsJoin " seconds."
endl;
#endif // def __USE_POSIX199309
最后,通过一个main函数调用以上实现的两个函数,将结果显示在控制台,然后执行性能测试:一个用于调试配置。
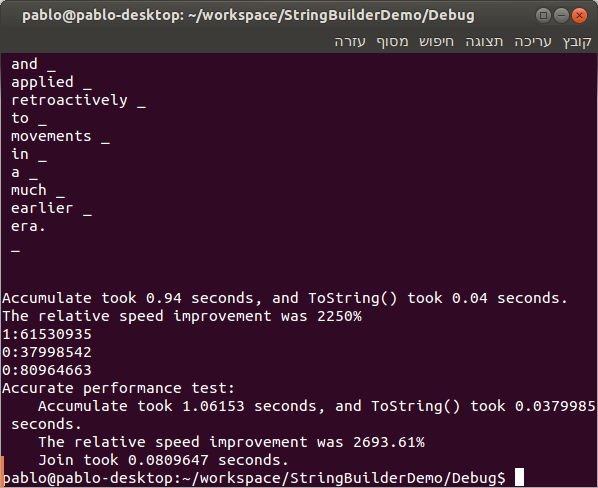
t另一个用于发行版本:
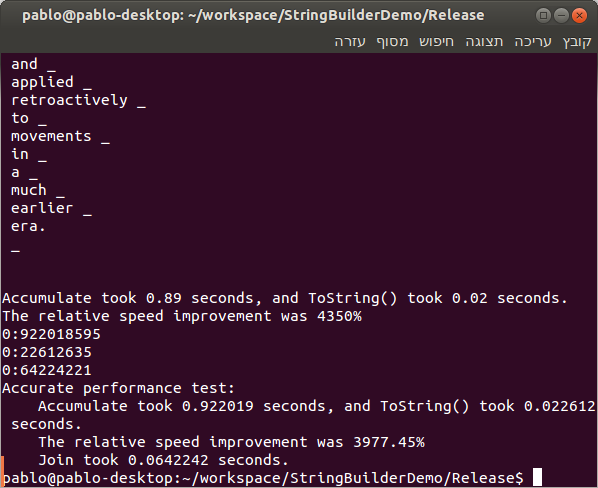
看到这百分比没?垃圾邮件的发送量都不能达到这个级别!
在使用这段代码前, 考虑使用ostring流。正如你在下面看到Jeff先生评论的一样,它比这篇文章中的代码更快些。
你可能想使用这段代码,如果:
你正在编写由具有C#经验的程序员维护的代码,并且你想提供一个他们所熟悉接口的代码。 你正在编写将来会转换成.net的、你想指出一个可能路径的代码。 由于某些原因,你不想包含 sstream 。几年之后,一些流的IO实现变得很繁琐,而且现在的代码仍然不能完全摆脱他们的干扰。要使用这段代码,只有按照main函数实现的那样就可以了:创建一个StringBuilder的实例,用Append()、AppendLine()和Add()给它赋值,然后调用ToString函数检索结果。
就像下面这样:
int main() {
////////////////////////////////////
// 8-bit characters (ANSI)
////////////////////////////////////
StringBuilder char ansi;
ansi.Append("Hello").Append(" ").AppendLine("World");
std::cout ansi.ToString();
////////////////////////////////////
// Wide characters (Unicode)
////////////////////////////////////
// http://en.wikipedia.org/wiki/Cargo_cult
std::vector std::wstring cargoCult
L"A", L" cargo", L" cult", L" is", L" a", L" kind", L" of", L" Melanesian", L" millenarian", L" movement",
// many more lines here...
L" applied", L" retroactively", L" to", L" movements", L" in", L" a", L" much", L" earlier", L" era.\n"
StringBuilder wchar_t wide;
wide.Add(cargoCult.begin(), cargoCult.end()).AppendLine();
// use ToString(), just like .net
std::wcout wide.ToString() std::endl;
// javascript-like join.
std::wcout wide.Join(L" _\n") std::endl;
////////////////////////////////////
// Performance tests
////////////////////////////////////
TestPerformance(wide, cargoCult);
#ifdef __USE_POSIX199309
AccurateTestPerformance(wide, cargoCult);
#endif // def __USE_POSIX199309
return 0;
}
任何情况下,当连接超过几个字符串时,当心std::accumulate函数。
现在稍等一下!你可能会问:你是在试着说服我们提前优化吗?
不是的。我赞同提前优化是糟糕的。这种优化并不是提前的:是及时的。这是基于经验的优化:我发现自己过去一直在和这种特殊的怪胎搏斗。基于经验的优化(不在同一个地方摔倒两次)并不是提前优化。
当我们优化性能时,“惯犯”会包括磁盘I-O操作、网络访问(数据库、web服务)和内层循环;对于这些,我们应该添加内存分配和性能糟糕的 Keyser Söze。
首先,我要为这段代码在Linux系统上做的精准分析感谢Rutenberg。
多亏了Wikipedia,让“在指尖的信息”的梦想得以实现。
最后,感谢你花时间阅读这篇文章。希望你喜欢它:不论如何,请分享您的意见。
作者:oschina
来源:51CTO
PyTorch1.0预览版发布:超越Python性能的C++前端接口? 今年 5 月份,F8 大会的第二天中,Facebook 曾宣布 PyTorch1.0 即将与大家见面,这是继先前发布 0.4.0 后的一次较大调整。今日,在首届 PyTorch 开发者大会上,Facebook 宣布了有关该框架生态一系列更新,包括软件、硬件和教育方面的合作。于此同时,PyTorch 1.0 预览版也正式发布了。
C/C++中榨干硬件性能的N种并行姿势初探 # 1. 前言 关于并行计算介绍参见 https://computing.llnl.gov/tutorials/parallel_comp/ 下面主要就部分单进程中常见的几种并行优化技术和相应的框架做一些简单的整理和分析对比,并且主要偏重于端,不涉及多节点多进程!
C++ Primer Plus 第6版 读书笔记(2)第2章 开始学习 C++ C++是在 C 语言基础上开发的一种集面向对象编程、泛型编程和过程化编程于一体的编程语言,是C语言的超集。本书是根据2003年的ISO/ANSI C++标准编写的,通过大量短小精悍的程序详细而全面地阐述了 C++的基本概念和技术,并专辟一章介绍了C++11新增的功能。
C++ STL学习之【反向迭代器】 适配器模式是 STL 中的重要组成部分,在上一篇文章中我们学习了 容器适配器 的相关知识,即 stack 与 queue,除了 容器适配器 外,还有 迭代器适配器,借助 迭代器适配器,可以轻松将各种容器中的普通迭代器转变为反向迭代器,这正是适配器的核心思想
相关文章
- 【C++保姆级入门】循环详解,带你告别死循环
- 剑指offer——把字符串转换成整数(c++)
- C++中的乱七八糟问题
- C++模板不支持分离编译的问题
- 转:C++ 性能测试支持
- C++——流类库和输入/输出
- C++性能优化指南
- [C++]Linux之间隔时间内循环执行指定程序
- C#调用C++写的dll,C++调用C++的dll
- 格雷码编解码学习(一):格雷码编码原理与C++代码实现
- C/C++ C# unity经常使用的一些快捷键
- c++中 #if #ifdef #ifndef #elif #else #endif的用法
- Duanxx的Design abroad: C++矩阵运算库Eigen 概要
- 【C/C++】C/C++中Static的作用详述
- 阅读《深入应用C++11:代码优化与工程级应用》
- VC++ 进度条的使用
- C++最小生成树问题
- Linux环境下使用eclipse开发C++动态链接库程序
- c++: 获取delete[]中的数组大小
- c++性能之对象与指针性能比较、以及java与c++性能对比实测
- C++:什么是RAII? | 智能指针的初步讲解 | 智能指针是为了避免什么问题?| 被遗弃的auto_ptr
- Makefile第三讲:终端传值给Makefile、Makefile传值给C++代码
- Visual Leak Detector 2.2.3 Visual C++内存检测工具