
NLP-预训练模型-2019-NLU+NLG:T5【Transfer Text-to-Text Transformer】【将所有NLP任务都转化成Text-to-Text任务】【 翻译、文本摘要..】
训练 to 模型 所有 任务 文本 2019 Text
2023-09-27 14:20:38 时间
《原始论文:Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》
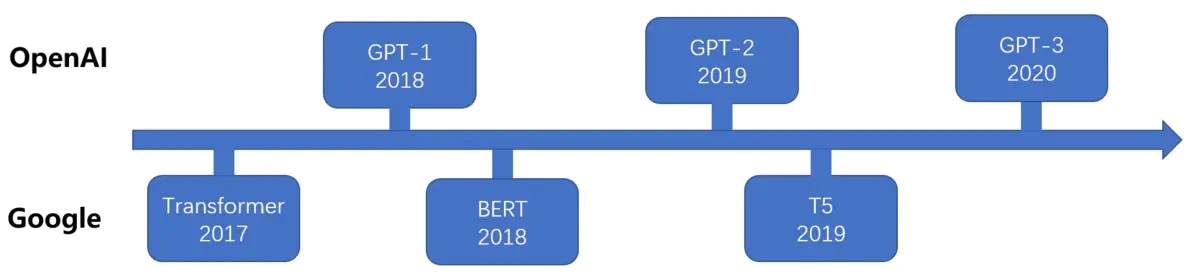
2019年10月,Google 在《Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer》这篇论文中提出了一个最新的预训练模型 T5(Text-To-Text Transfer Transformer),其参数量达到了 110 亿,完爆 Bert Large 模型,且在多项 NLP 任务中达到 SOTA 性能。有人说,这是一种将探索迁移学习能力边界的模型。
当然,最大的冲击还是财大气粗,bigger and bigger,但翻完它长达 34 页的论文,发现其中的分析无疑是诚意满满(都是钱)。类似这样的大型实验探索论文也有一些,首先提出一个通用框架,接着进行了各种比对实验,获得一套建议参数,最后得到一个很强的 baseline。而我们之后做这方面实验就能参考它的一套参数。
对于 T5 这篇论文,Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer,无疑也是类似的论文。它的意义不在烧了多少钱,也不在屠了多少榜(砸钱就能砸出来),其中 idea 创新也不大,它最重要作用是给整个 NLP 预训练
相关文章
- 蓝桥算法训练__普及组.Day10
- kares中如何从已保存的训练模型中了解模型的具体结构
- PyTorch训练加速技巧
- [计算机视觉][神经网络与深度学习]Faster R-CNN配置及其训练教程2
- GNN-图卷积模型-直推式-2016:GCN【消息传递(前向传播):聚合函数+更新函数】【聚合函数:mean(邻域所有节点取平均值)】【训练更新函数的参数】【空域+频域】【同质图】
- Audio-预训练模型(一):概述
- NLP-预训练模型:迁移学习(拿已经训练好的模型来使用)【预训练模型:BERT、GPT、Transformer-XL、XLNet、RoBerta、XLM、T5】、微调、微调脚本、【GLUE数据集】
- VLP:《视觉-语言预训练》综述
- 多模态预训练模型(一)
- OpenAI 和DeepMind开源人工智能训练平台
- 【一】分布式训练---单机多卡多机多卡(飞桨paddle1.8)
- 选择正确优化器,加速深度学习模型训练