
[论文笔记]YOLOF 阅读笔记
2023-09-27 14:20:18 时间
YOLOF阅读笔记
You Only Look One-level Feature(CVPR 2021)
摘要
- FPN的成功是因为它在目标检测优化问题中的divide-and-conquer(分而治之)方法而不是multi-scale feature fusion
- YOLOF不采用复杂的feature pyramid,而是只使用one-level feature
- YOLOF有两个重要的组件:Dilated Encoder 和 Uniform Matching
1. 引言
- 先来看FPN有什么优点:
- multi-scale feature fusion——融合低分辨率和高分辨率的特征图,以获取更好的特征表示
- divide-and-conquer(分而治之):在不同level进行目标检测而不考虑目标的scale
- 作者把FPN两个优点 进行解耦,并分别进行实验发现:
- C5 特征携带了足够的用于检测不同scale的物体的context
- multi-scale feature fusion的作用远远没有divide-and-conquer那么大,因为divide-and-conquer与目标检测中的优化问题有关。它将复杂的检测问题按对象scale划分为几个子问题,从而促进优化过程

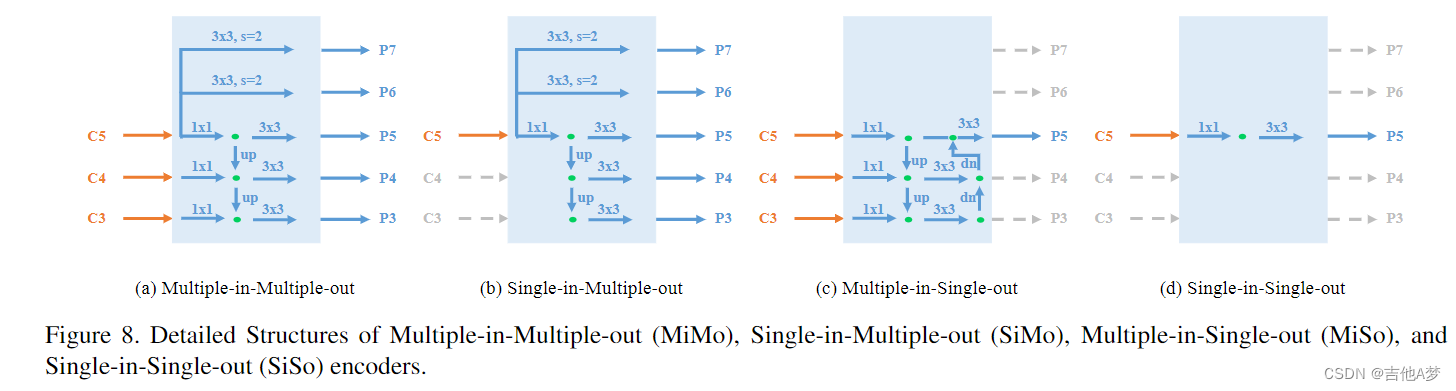
- 从上述分析可以看到,FPN可以用来解决优化问题,但是它太复杂了,因此作者用YOLOF构造了一个更为简单的替代方法,来解决优化问题并且弥补SiSo和MiMo之间的性能差异
- 只使用C5 特征进行检测
- 设计dilated encoder(这个encoder我觉得可以理解成一个neck)来提取各种scale下的multi-scale context
- 设计uniform matching来解决单一特征中稀疏anchor引起的正anchor不平衡问题(单一特征会使得正anchor变少,而大的gt框会分配产生更多的正anchor,这就会使得训练时检测器检测大的目标)
2. 相关工作
3. Cost Analysis of MiMo Encoders(MiMo Encoder的开销分析)


- encoder可以理解成一个neck,decoder可以理解成head
4. 方法
- SiSo和MiMo之间的性能差异的原因(这里其实是在解释divide-and-conquer的作用),后面小节提出解决方案:
- scale不匹配:与 C5 特征的感受野匹配的scale范围是有限的,这阻碍了对不同scale对象的检测性能
- 样本不平衡:单层C5特征中稀疏anchor引起的正anchor上的不平衡问题
4.1 Limited Scale Range(有限尺度范围)

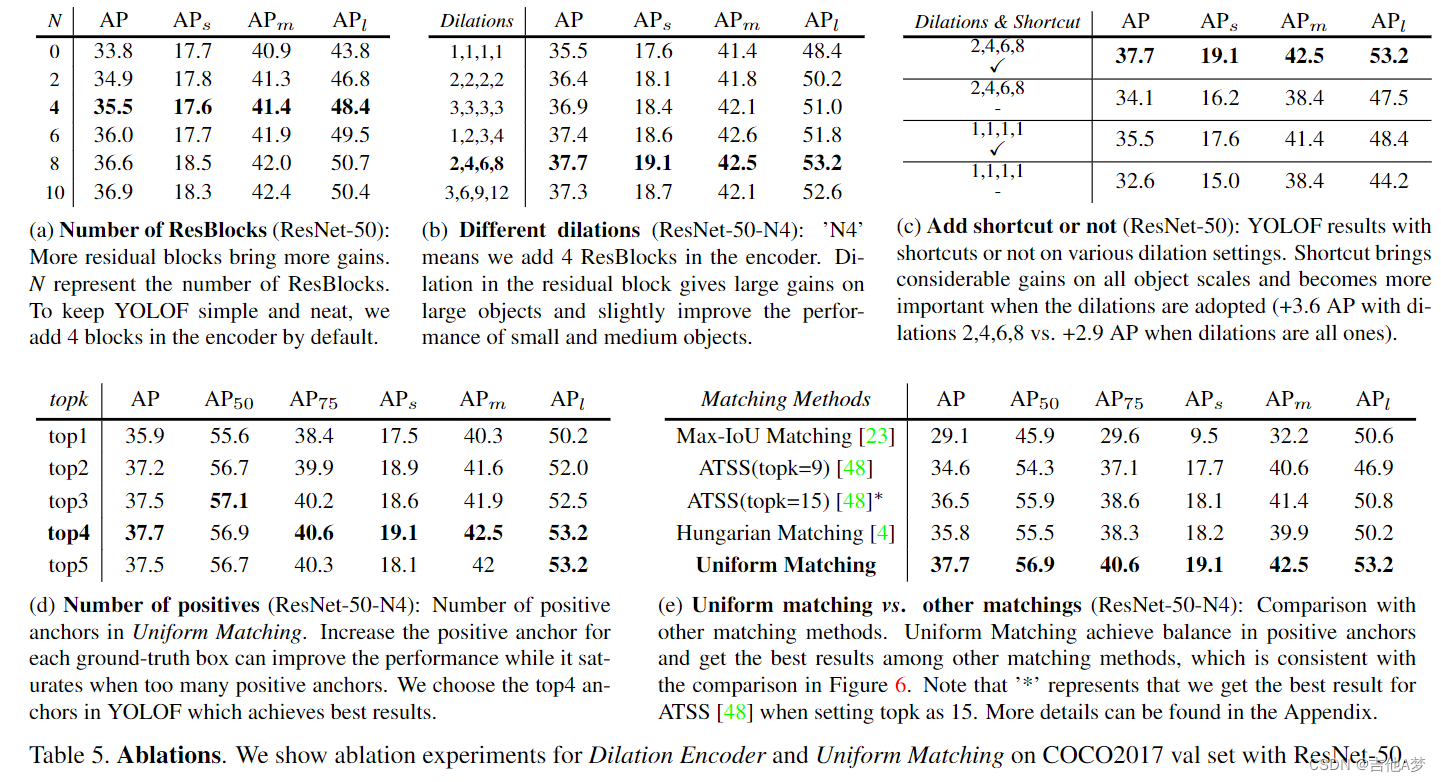
- C5 特征图的感受野只能覆盖上图中(a)的范围;如果使用膨胀卷积的话,那么只能覆盖图中(b)的范围;因此将将两者进行合并就能获得尺度全覆盖的特征图,如图 (c)
Dilated Encoder

- 作者构建了一个SiSo的encoder叫做dilated encoder,分为两个部分
- Projector:应用一个 1×1 卷积层来降低通道维度,然后添加一个 3×3 卷积层来细化semantic context,这与 FPN 中的相同
- Residual Block:在 3×3 卷积层中堆叠四个具有不同膨胀率的连续膨胀残差块,以生成具有多个感受野的输出特征,覆盖所有对象的scale
4.2 Imbalance Problem on Positive Anchors(正anchor的不平衡问题)
- anchor方面的问题:
- SiSo相比于MiMo会产生更少的正anchor
- 大的gt框相比小的gt框会产生更多的正anchor,这样会使得检测器在训练的时候更关注大的gt框

Uniform Matching
- uniform matching解决的是稀疏anchor下正样本之间的平衡(balance on posi-
tive samples with sparse anchors),做法如下:- 采用k个最近的anchor作为每个gt框的正anchors,这确保了所有不同大小的gt框可以与相同数量的正anchor统一匹配
- 按照 Max-IoU ,在 Uniform Matching 中设置 IoU 阈值以忽略大 IoU (>0.7) 负anchor和小 IoU (<0.15) 正anchor
4.3 YOLOF
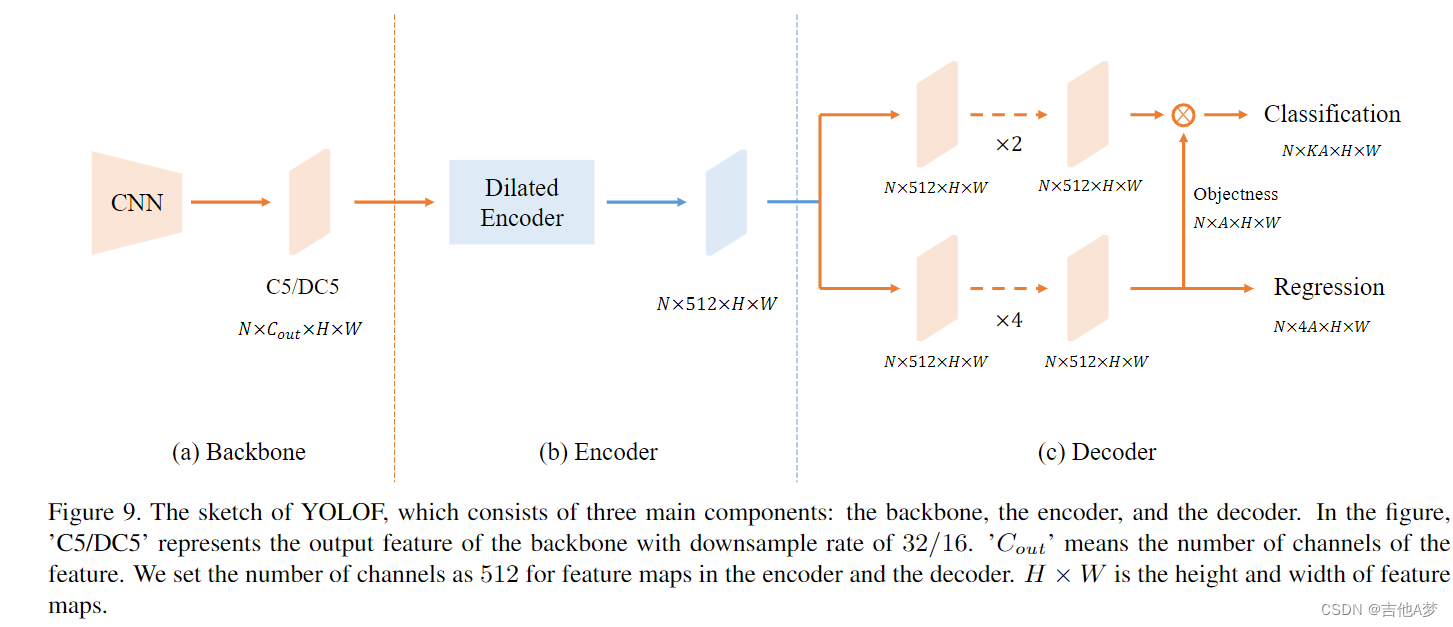
- decoder上的一些细节:
- 第一个是作者遵循 DETR 中 FFN 的设计,使两个 head 中的卷积层数不同。回归头上有四个卷积,后面是批归一化层和 ReLU 层,而分类头只有两个。
- 第二个是作者遵循 Autoassign 并为回归头上的每个锚点添加一个隐式对象性预测(没有直接监督)。所有预测的最终分类分数是通过将分类输出乘以相应的隐含对象性生成的
- 其他细节:
- YOLOF 中预设的anchor很少,降低了anchor和gt框之间的匹配质量。因此作者在image上添加一个随机移位操作来规避这个问题。该操作在左、右、上和下方向上随机移动image,最多 32 个像素,目的是为物体在image中的位置注入噪声,增加高质量gt框与anchor匹配的概率。同时添加一个限制,所有anchor的中心偏移应小于 32 像素
5. 实验
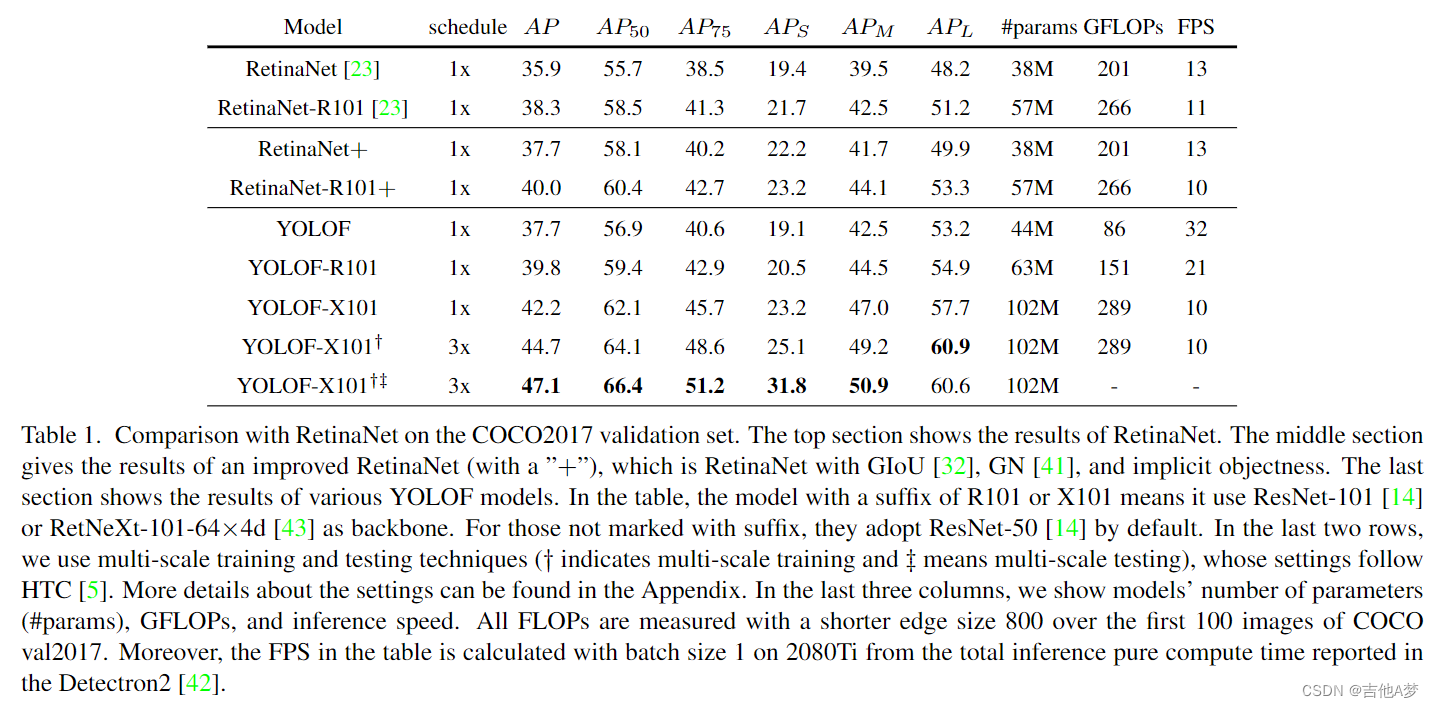
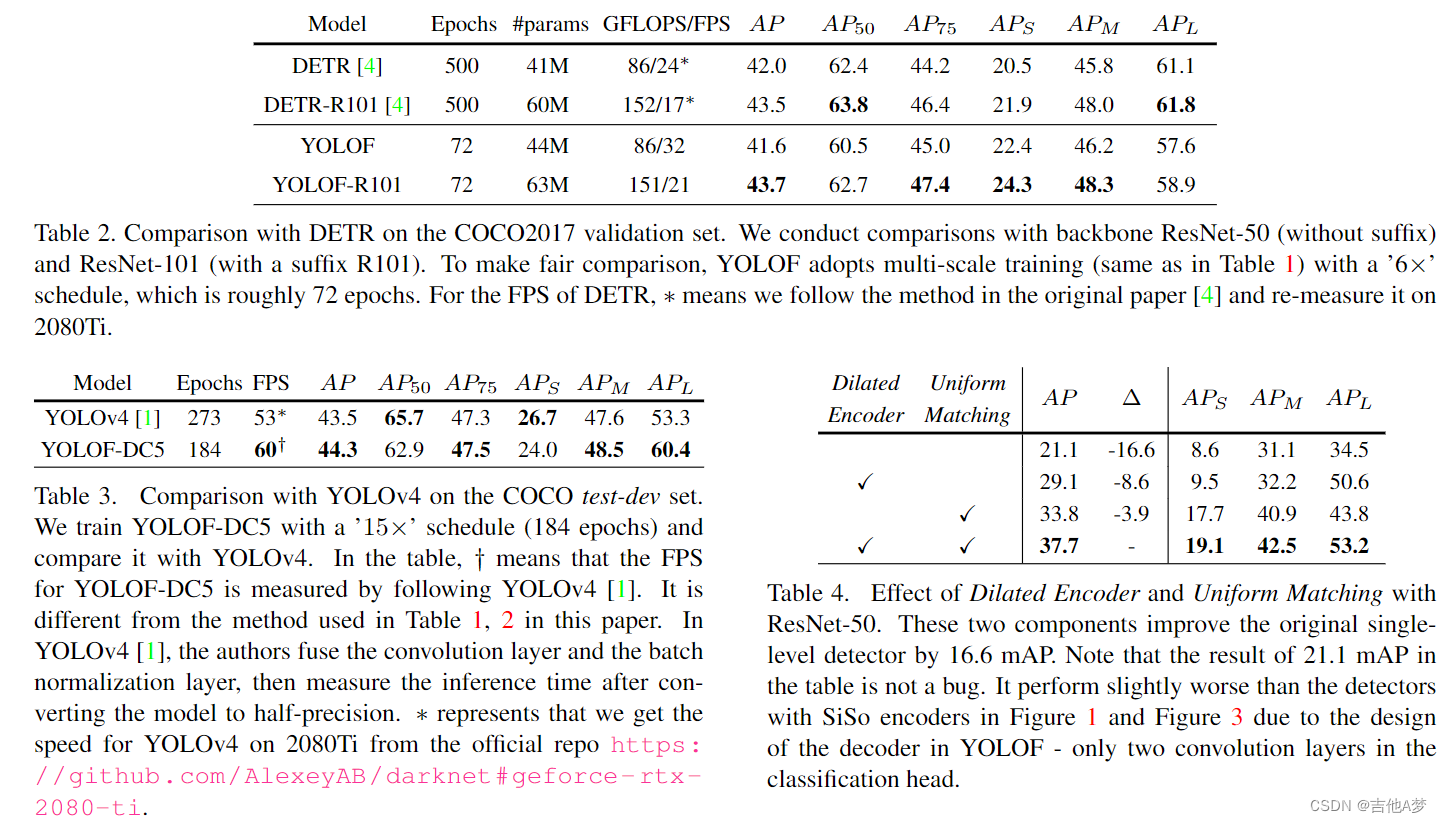

6. 结论
附录A:更多细节
Detailed Structures of All Encoders(所有encoder的结构)
- 前面的Figure 8
Network Architecture of YOLOF(YOLOF的网络架构)
- 前面的Figure 9
Training Time & Memory(训练时间和内存)

More Implementation Details(应用细节)
Detailed Settings to Compare with YOLOv4(与YOLOv4比较时的设置)
附录B:其他实验结果
Number of Anchors(anchor的数量)

Hyper-parameter of ATSS(ATSS的超参数)

Results with Dilated C5(Dilated C5的结果)

思考
- 作者是怎么分配的anchor,是在P5特征图上直接进行anchor生成然后映射到输入image上去的吗?
- C5 已经是一个很小的特征图了吧,对应输入image的感受野应该很大了,后面还在用膨胀卷积扩大感受野,这小物体检测是不要做了嘛,淦
- 前面一直说FPN的收益是divide-and-conquer获得的,后面也没看他是这样做啊
相关文章
- 【论文笔记】(对比学习经典论文MoCo) Momentum Contrast for Unsupervised Visual Representation Learning
- 【论文笔记】Rethinking and Improving Relative Position Encoding for Vision Transformer
- 【论文笔记】InverseForm: A Loss Function for Structured Boundary-Aware Segmentation
- 【论文笔记】DEEP FEATURE SELECTION-AND-FUSION FOR RGB-D SEMANTIC SEGMENTATION
- 【论文笔记】Transformers in Remote Sensing: A Survey 中的相关论文链接
- 【论文笔记】EPSANet: An Efficient Pyramid Squeeze Attention Block on Convolutional Neural Network
- 【论文笔记】Street-View Change Detection with Deconvolutional Networks
- 【论文笔记】Learning to Compare Image Patches via Convolutional Neural Networks
- 论文笔记:Gradient-Based Learning Applied to Document Recognition
- [论文笔记] A Survey on Vision Transformer 阅读笔记
- [论文笔记] WoodScape 论文笔记
- [论文笔记] ULSD 阅读笔记
- [论文笔记] BCNet 阅读笔记
- [论文笔记] ETHSeg 阅读笔记
- [论文笔记] Detect to Track and Track to Detect 阅读笔记
- [论文笔记] Temporal RoI Align 阅读笔记
- [论文笔记] 大型车牌检测数据集CRPD 阅读笔记
- [论文笔记]AutoAssign 阅读笔记
- [论文笔记]YOLACT 阅读笔记
- 【计算机视觉】论文笔记:Ten years of pedestrian detection, what have we learned?
- 医院预约挂号系统设计与实现(论文+源码)_kaic
- 论文阅读 状态压缩
- (一)One-Shot Learning for Semantic Segmentation论文阅读笔记