
【学习笔记-李宏毅】New Optimization
文章目录
视频链接
视频:https://www.youtube.com/watch?v=4pUmZ8hXlHM
PPT:http://speech.ee.ntu.edu.tw/~tlkagk/courses/ML2020/Optimization.pdf
本次课程会用到的符号(Notation)
- θ t \theta_t θt:第 t t t 步时,模型的参数
- Δ L ( θ t ) \Delta L(\theta_t) ΔL(θt) 或 g t g_t gt :模型参数为 θ t \theta_t θt 时,对应的梯度,用于计算 θ t + 1 \theta_{t+1} θt+1
- m t + 1 m_{t+1} mt+1:从第 0 0 0 步到第 t t t 步累计的momentum,用于计算 θ t + 1 \theta_{t+1} θt+1
为什么要做Optimization
- 为了找到一组参数 θ \theta θ ,可以使 ∑ x L ( θ ; x ) \sum_x L(\theta;x) ∑xL(θ;x) 最小
- 或者也可以说,针对某个特定的 x x x ,使得 L ( θ ) L(\theta) L(θ) 最小
On-line VS Off-line
- On-line:每次参数更新,只给一对
(
x
t
,
y
t
)
(x_t, y_t)
(xt,yt)
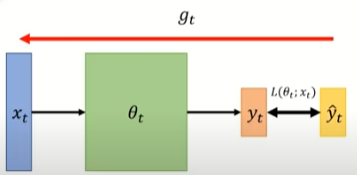
- Off-line:每次更新参数,考虑所有的训练资料
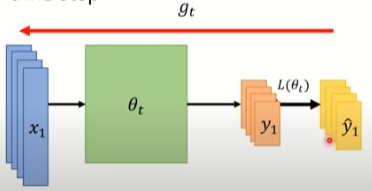
常用的优化算法
随机梯度下降法(SGD,Stochastic gradient descent)
思路:计算时梯度时,不取所有的样本来计算,只随机选取“其中一个”样本计算梯度,然后进行更新
但实际主流框架中所谓的SGD实际上都是Mini-batch Gradient Descent (MBGD,亦成为SGD)。对于含有N个训练样本的数据集,每次参数更新,仅依据一部分数据计算梯度。小批量梯度下降法既保证了训练速度,也保证了最后收敛的准确率。 所以在Pytorch的SGD算法中,就没有随机选取的这个动作,因为Train Data已经Shuffle数据,然后选取batch了。引用地址
SGD的过程为:

SGD with Momentum (SGDM)
思路:在SGD的基础上,考虑前一次更新的梯度。
SGDM的更新过程:

Adagrad
了解原理即可,不常用,因为没有Adam效果好
思路:让学习率随着迭代次数的增多越来越小。因为随着迭代次数增多,会越来越靠近结果,如果学习率太大会导致无法收敛。
Adagrad参数更新公式为:
θ t = θ t − 1 − η ∑ i = 0 t − 1 ( g i ) 2 g t − 1 \theta_t = \theta_{t-1} - \frac{\eta}{\sqrt{\sum_{i=0}^{t-1}(g_i)^2}}g_{t-1} θt=θt−1−∑i=0t−1(gi)2ηgt−1
Adagrad是依据过去的梯度值来减小学习率,但由于是累加,分母会越来越大,这样就会有一个致命的缺点:如果前几个gradient太大的话,就会导致后面学习率一直很小,后面就走不动了
RMSProp
了解原理即可,不常用,因为没有Adam效果好
思路:与Adagrad一致,但解决了Adagrad的缺点
RMSProp参数更新公式为:
θ t = θ t − 1 − η v t g t − 1 v 1 = g 0 2 v t = α v t − 1 + ( 1 − α ) ( g t ) 2 \begin{aligned} & \theta_t = \theta_{t-1} - \frac{\eta}{\sqrt{v_t}}g_{t-1} \\\\ & v_1 = {g_0}^2 \\\\ & v_t = \alpha v_{t-1} + (1-\alpha)(g_{t})^2 \end{aligned} θt=θt−1−vtηgt−1v1=g02vt=αvt−1+(1−α)(gt)2
其中 α ∈ [ 0 , 1 ] \alpha \in [0,1] α∈[0,1] 是需要调的超参数,默认值为 0.99 0.99 0.99
RMSProp解决了Adagrad的问题,因为RMSProp对过去的 v t v_t vt 每次都乘了 α \alpha α ,所以即使前几个gradient太大,迭代后期也不会有太大的影响
Adam
建议详细学,因为是Performance比较好的Optimizer
思路:将SGDM与RMSProp一起用
公式求解过程:
m t = β 1 m t − 1 + ( 1 − β 1 ) g t ( 1 ) v t = β 2 v t − 1 + ( 1 − β 2 ) g t 2 ( 2 ) m t ^ = m t 1 − β 1 t ( 3 ) v t ^ = v t 1 − β 2 t ( 4 ) θ t = θ t − 1 − η v t ^ + ε m t ^ ( 5 ) \begin{aligned} & m_t = \beta_1 m_{t-1} + (1-\beta_1) g_t ~~~~~~~(1)\\\\ & v_t = \beta_2 v_{t-1} + (1- \beta_2) {g_t}^2 ~~~~~~~(2)\\\\ & \widehat{m_t} = \frac{m_t}{1- {\beta_1}^t} ~~~~~~~(3)\\\\ & \widehat{v_t} = \frac{v_t}{1-{\beta_2}^t} ~~~~~~~(4)\\\\ & \theta_t = \theta_{t-1} - \frac{\eta}{\sqrt{\widehat{v_t}}+\varepsilon}\widehat{m_t} ~~~~~~~(5) \end{aligned} mt=β1mt−1+(1−β1)gt (1)vt=β2vt−1+(1−β2)gt2 (2)mt =1−β1tmt (3)vt =1−β2tvt (4)θt=θt−1−vt +εηmt (5)
- 公式(1)为SGDM的变种, m t − 1 m_{t-1} mt−1 为上次参数更新的“梯度”, g t g_t gt为本次计算的梯度, β 1 \beta_1 β1 为超参数,默认为 0.9 0.9 0.9,看起感觉只考虑了0.1的本次梯度,考虑了0.9的历史梯度,但本次梯度会在下次更新时被考虑进来。
- 公式(2)为RMSProp的 v t v_t vt , β 2 \beta_2 β2 为超参数,默认为 0.999 0.999 0.999
- 公式(3)对 m t m_t mt 做了处理, β 1 t {\beta_1}^t β1t 是 β 1 {\beta_1} β1 的 t t t次方。 看起来是对 m t m_t mt 做了放大了,而且随着 t t t 的增加,放大的越来越少,搞不懂。。TODO
- 公式(4)与公式(3)同理
- 公示(5)是最后的更新公式, ε \varepsilon ε 是用来防止分母为 0 0 0 的,默认值为 1 0 − 8 10^{-8} 10−8
AMSGrad
AMSGrad是对Adam的缺点进行了优化。
Adam的缺点:没搞懂。。。TODO
AMSGrad对 v t ^ \widehat{v_t} vt 做了调整:
v t ^ = max ( v ^ t − 1 , v t ) \widehat{v_t} = \text{max}(\widehat{v}_{t-1},v_t) vt =max(v t−1,vt)
Adam VS SGDM
- Adam: 训练快速(fast training ),在validation set上表现有比较大的落差(large generalization gap),不稳定(unstable)
- SGDM:稳定(stable),在validation set上表现稳定(little generalization gap),更容易收敛(better convergence)
SWATS(Simply combine Adam with SGDM)
思路:由于Adam快,但不稳定,而SGDM稳定,但是慢,所以,一开始用Adam,后面用SGDM

RAdam
另一种对Adam的优化
思路:没看懂TODO
RAdam 公式:

RAdam VS SWATS
| RAdam | SWATS | |
|---|---|---|
| 灵感来源 | 在训练开始时,loss分布比较崎岖,如果步子迈得太大,容易跑到不该去的地方 | Adam存在难以收敛和不稳定的问题,而SGDM存在训练慢的问题 |
| 做法 | 应用Warm-up(一开始学习率低一点,然后随着时间逐渐升高,之后再随时间降低),减少训练初期走错路的问题 | 先Adam后SGDM |
| 后面几项不懂TODO |

后面还有很多没听懂TODO
相关文章
- Maven学习笔记
- 【数据库和SQL学习笔记】10.(T-SQL语言)函数、存储过程、触发器
- python学习笔记(迭代器、生成器)
- 数据分析---《Python for Data Analysis》学习笔记【02】
- C++学习笔记:
- K8S学习笔记之周立Kubernetes开源书
- 机器学习笔记之正则化的线性回归的岭回归与Lasso回归
- Prometheus监控学习笔记之prometheus的federation机制
- Prometheus监控学习笔记之Prometheus存储
- SNMP学习笔记之Python的netsnmp和pysnmp的性能对比
- SQL学习笔记六之MySQL数据备份和pymysql模块
- Hadoop Pig学习笔记(一) 各种SQL在PIG中实现
- Angular 学习笔记 (消毒 sanitizer)
- Asp.net core 学习笔记 Razor Page
- Entity Framework with MySQL 学习笔记一(安装)
- Ceph分布式存储 - 学习笔记
- Neo4j学习笔记(1)——使用Java API实现简单的增删改查
- spring学习笔记 星球日one - xml方式配置bean
- 黑马程序员&传智播客 正则表达式学习笔记 匹配单个字符多个字符
- 第9章 逻辑回归 学习笔记 中
- Python学习笔记 day6 面向对象编程
- 深度学习 Deep Learning UFLDL 最新 Tutorial 学习笔记 1:Linear Regression
- 计算机网络-复习笔记
- python 排序模块 ———— heapq(学习笔记)
- Git学习笔记(一)
- 博客园美化笔记
- 读经典——《CLR via C#》(Jeffrey Richter著) 笔记_命名空间和程序集的关系
- 《棉花帝国:一部资本主义全球史》笔记
- 关于Vue和React区别的一些笔记