
yolo系列学习笔记----yolov3
1,yolov3的结构
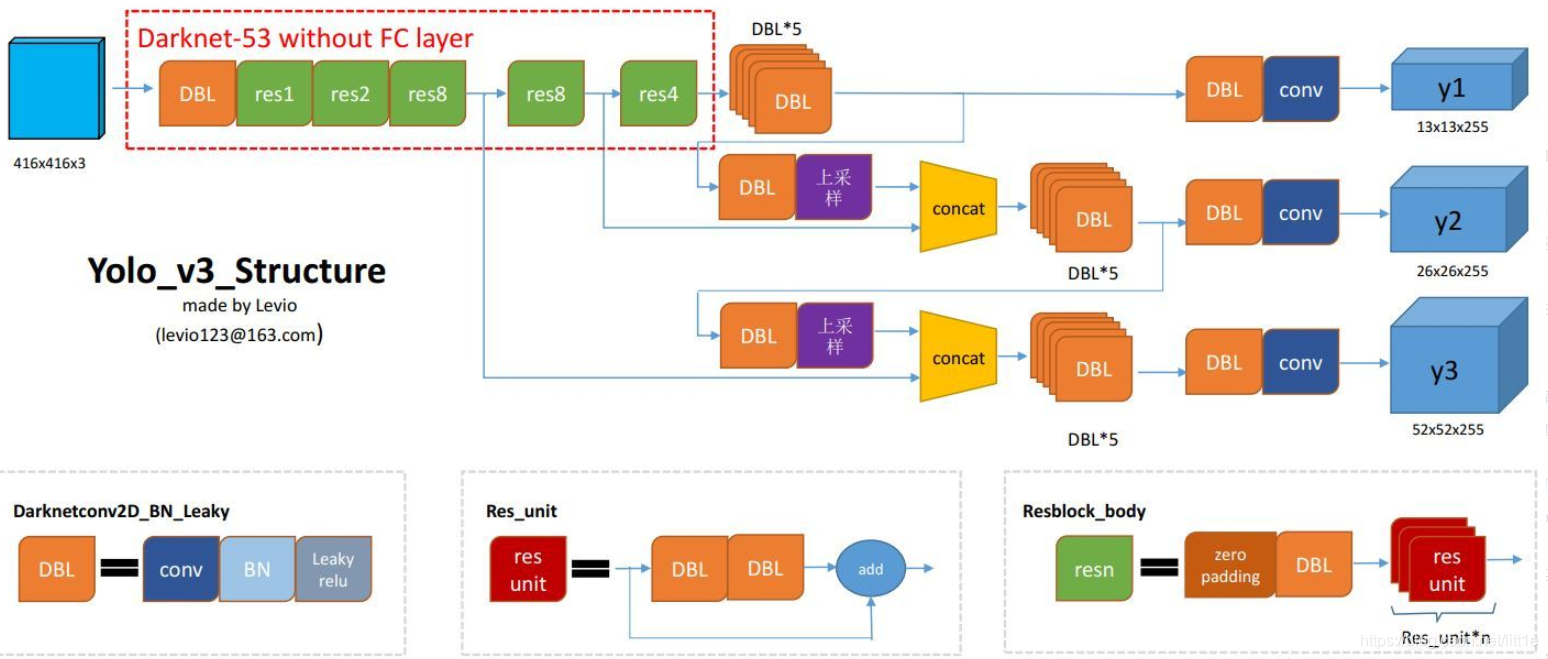
Yolov3中,只有卷积层,通过调节卷积步长控制输出特征图的尺寸。所以对于输入图片尺寸没有特别限制。
DBL:代码中的Darknetconv2d_BN_Leaky,是yolo_v3的基本组件。就是卷积+BN+Leaky relu。
resn:n代表数字,有res1,res2, … ,res8等等,表示这个res_block里含有多少个res_unit。
如下图所示:

ResNeXt的基本模块包含了32个分支,每个分支一模一样。每个矩形框中的参数分别表示输入维度,卷积大小,输出维度。它主要是通过1*1的卷积 层进行降维然后再升维。
下图中是ResNet-50 和 ResNeXt-50 的内部结构,最后两行说明二者之间的参数复杂度差别不大。
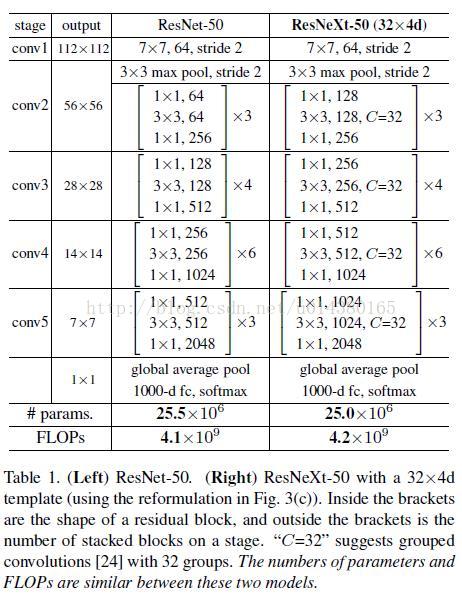
50 的原因: 1+9+12+18+9+1=50 只算卷积层,不计算池化层
concat:张量拼接。将darknet中间层和后面的某一层的上采样进行拼接。拼接的操作和残差层add的操作是不一样的,拼接会扩充张量的维度,而add只是直接相加不会导致张量维度的改变。
backbone:darknet-53
为了达到更好的分类效果,作者自己设计训练了darknet-53。作者在ImageNet上实验发现这个darknet-53,的确很强,相对于ResNet-152和ResNet-101,darknet-53不仅在分类精度上差不多,计算速度还比ResNet-152和ResNet-101强多了,网络层数也比他们少。

Yolo_v3使用了darknet-53的前面的52层(没有全连接层),yolo_v3这个网络是一个全卷积网络,大量使用残差的跳层连接,并且为了降低池化带来的梯度负面效果,作者直接摒弃了POOLing,用conv的stride来实现降采样。在这个网络结构中,使用的是步长为2的卷积来进行降采样。
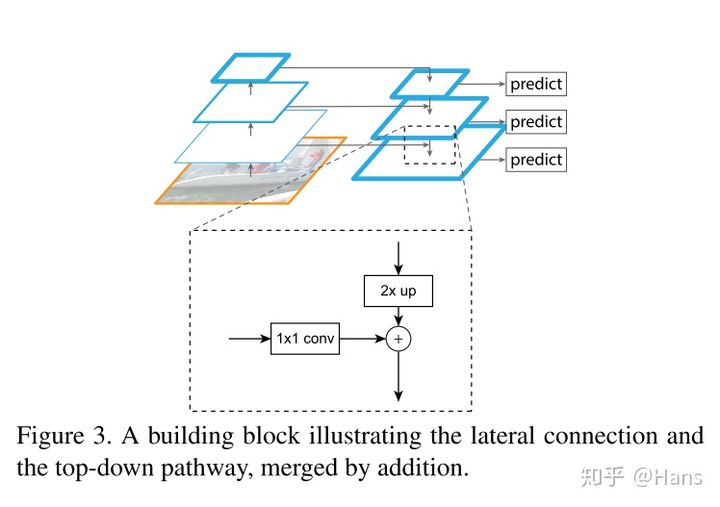
为了加强算法对小目标检测的精确度,YOLO v3中采用类似FPN(特征金字塔结构如下图所示)的upsample和融合做法(最后融合了3个scale,其他两个scale的大小分别是26×26和52×52),在多个scale的feature map上做检测。
作者在3条预测支路采用的也是全卷积的结构,其中最后一个卷积层的卷积核个数是255,是针对COCO数据集的80类:3*(80+4+1)=255,3表示一个grid cell包含3个bounding box,4表示框的4个坐标信息,1表示objectness score。
backbone部分由Yolov2时期的Darknet-19进化至Darknet-53,加深了网络层数,引入了Resnet中的跨层加和操作。
2.yolov3的输出
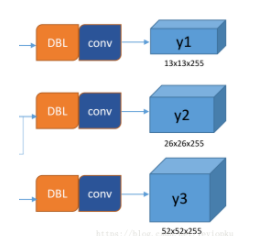
所谓的多尺度就是来自这3条预测之路,y1,y2和y3的深度都是255,边长的规律是13:26:52。yolo v3设定的是每个网格单元预测3个box,所以每个box需要有(x, y, w, h, confidence)五个基本参数,然后还要有80个类别的概率。所以3×(5 + 80) = 255。这个255就是这么来的。
下面我们具体看看y1,y2,y3是如何而来的。
网络中作者进行了三次检测,分别是在32倍降采样,16倍降采样,8倍降采样时进行检测,这样在多尺度的feature map上检测跟SSD有点像。在网络中使用up-sample(上采样)的原因:网络越深的特征表达效果越好,比如在进行16倍降采样检测,如果直接使用第四次下采样的特征来检测,这样就使用了浅层特征,这样效果一般并不好。如果想使用32倍降采样后的特征,但深层特征的大小太小,因此yolo_v3使用了步长为2的up-sample(上采样),把32倍降采样得到的feature map的大小提升一倍,也就成了16倍降采样后的维度。同理8倍采样也是对16倍降采样的特征进行步长为2的上采样,这样就可以使用深层特征进行detection。
作者通过上采样将深层特征提取,其维度是与将要融合的特征层维度相同的(channel不同)。如下图所示,85层将13×13×256的特征上采样得到26×26×256,再将其与61层的特征拼接起来得到26×26×768。为了得到channel255,还需要进行一系列的3×3,1×1卷积操作,这样既可以提高非线性程度增加泛化性能提高网络精度,又能减少参数提高实时性。52×52×255的特征也是类似的过程。
3.其他改进
1,Bounding Box
YOLO v3的Bounding Box由YOLOV2又做出了更好的改进。在yolo_v2和yolo_v3中,都采用了对图像中的object采用k-means聚类。 feature map中的每一个cell都会预测3个边界框(bounding box) ,每个bounding box都会预测三个东西:(1)每个框的位置(4个值,中心坐标tx和ty,,框的高度bh和宽度bw),(2)一个objectness prediction ,(3)N个类别,coco数据集80类,voc20类。(yolo_v2是一个特征图预测且每个grid cell有9个anchor box的话,一共是13*13*9=1521个)
三次检测,每次对应的感受野不同,32倍降采样的感受野最大,适合检测大的目标,所以在输入为416×416时,每个cell的三个anchor box为(116 ,90); (156 ,198); (373 ,326)。16倍适合一般大小的物体,anchor box为(30,61); (62,45); (59,119)。8倍的感受野最小,适合检测小目标,因此anchor box为(10,13); (16,30); (33,23)。所以当输入为416×416时,实际总共有(52×52+26×26+13×13)×3=10647个proposal box。

感受一下9种先验框的尺寸,下图中蓝色框为聚类得到的先验框。黄色框式ground truth,红框是对象中心点所在的网格。

这里注意bounding box 与anchor box的区别:
Bounding box它输出的是框的位置(中心坐标与宽高),confidence以及N个类别。
anchor box只是一个尺度即只有宽高。
三个特征图一共可以解码出 8 × 8 × 3 + 16 × 16 × 3 + 32 × 32 × 3 = 4032 个box以及相应的类别、置信度。这4032个box,在训练和推理时,使用方法不一样:
- 训练时4032个box全部送入打标签函数,进行后一步的标签以及损失函数的计算。
- 推理时,选取一个置信度阈值,过滤掉低阈值box,再经过nms(非极大值抑制),就可以输出整个网络的预测结果了。
2,损失


3,训练策略
ground truth为什么不按照中心点分配对应的预测box?
在Yolov3的训练策略中,不再像Yolov1那样,每个cell负责中心落在该cell中的ground truth。原因是Yolov3一共产生3个特征图,3个特征图上的cell,中心是有重合的。训练时,可能最契合的是特征图1的第3个box,但是推理的时候特征图2的第1个box置信度最高。所以Yolov3的训练,不再按照ground truth中心点,严格分配指定cell,而是根据预测值寻找IOU最大的预测框作为正例。
第一种,ground truth先从9个先验框中确定最接近的先验框,这样可以确定ground truth所属第几个特征图以及第几个box位置,之后根据中心点进一步分配。第二种,全部4032个输出框直接和ground truth计算IOU,取IOU最高的cell分配ground truth。第二种计算方式的IOU数值,往往都比第一种要高,这样wh与xy的loss较小,网络可以更加关注类别和置信度的学习;其次,在推理时,是按照置信度排序,再进行nms筛选,第二种训练方式,每次给ground truth分配的box都是最契合的box,给这样的box置信度打1的标签,更加合理,最接近的box,在推理时更容易被发现。
相关文章
- 前端笔记----jquery入门知识点总结
- 前端笔记----类型转换display
- 【学习笔记09】:JavaScript单引号、双引号和反引号的区别
- OpenCV入门笔记(三) 图片处理
- 数据挖掘,计算机网络、操作系统刷题笔记40
- Python学习笔记----1.MAC OS配置Sublime Text使用Python3
- PHP学习笔记_01_基础入门
- CSS学习笔记
- 考研政治 | 自用笔记记录
- Java_jdbc 基础笔记之一 数据库连接
- MySQL Group Replication 学习笔记
- Linux学习笔记(16)Linux前后台进程切换(fg/bg/jobs/ctrl+z)
- 小波说雨燕 第三季 构建 swift UI 之 UI组件集-视图集(四)Alert View视图 学习笔记
- Tensorflow基础笔记
- latex学习笔记----基本知识、文档排版