
机器学习笔记三-----------------Prophet(时间序列模型)的复杂例程笔记
一,Prophet对象及接口说明
1.1 Prophet.make_future_dataframe()接口解读
首先解读 make_future_dataframe()接口的意义,查看该参数的命令:
help(Prophet.make_future_datafrme)
make_future_dataframe(self, periods, freq='D'【预测的最小单位】, include_history=True)
Parameters
----------
periods: Int number of periods to forecast forward.预测未来的周期数
freq: Any valid frequency for pd.date_range, such as 'D' or 'M'.
include_history: Boolean to include the historical dates in the data
frame for predictions.
1.2 Prophet对象接口的解读
通过帮助可以看到接口中的默认值
Prophet(growth='linear', changepoints=None, n_changepoints=25, changepoint_range=0.8, yearly_seasonality='auto', weekly_seasonality='auto', daily_seasonality='auto', holidays=None, seasonality_mode='additive', seasonality_prior_scale=10.0, holidays_prior_scale=10.0, changepoint_prior_scale=0.05, mcmc_samples=0, interval_width=0.8, uncertainty_samples=1000, stan_backend=None)
二,乘法季节性
2.1 航空旅客数量例子
默认情况下,Prophet能够满足附加的季节性,这意味着季节性的影响是加到趋势中得到了最后的预报(yhat)。
航空旅客数量的时间序列是一个附加的季节性不起作用的例子,使用以下代码得到的结果为:
import pandas as pd
import matplotlib.pyplot as plt
from fbprophet import Prophet
from prophet.plot import plot_plotly, plot_components_plotly
import time
from fbprophet.plot import plot_yearly
#原来数据大小是[144 rows x 2 columns]
df = pd.read_csv('example_air_passengers.csv')
print(df)
m = Prophet()
m.fit(df)
#预测是时间,是在原始数据上加入50个月变为[194 rows x 1 columns]
future = m.make_future_dataframe(50, freq='MS')
print(future)
forecast = m.predict(future)
fig = m.plot(forecast)
fig.show()
这个时间序列有一个明显的年度周期,但预测中的季节性在时间序列开始时太大,在结束时又太小。在这个时间序列中,季节性并不是Prophet所假定的是一个恒定的加性因子,而是随着趋势在增长。这就是乘法季节性(multiplicative seasonality)。
Prophet可以通过设置seasonality_mode='multiplicative'来建模乘法季节性:
import pandas as pd
import matplotlib.pyplot as plt
from fbprophet import Prophet
from prophet.plot import plot_plotly, plot_components_plotly
import time
from fbprophet.plot import plot_yearly
#原来数据大小是[144 rows x 2 columns]
df = pd.read_csv('example_air_passengers.csv')
print(df)
m = Prophet(seasonality_mode='multiplicative')
m.fit(df)
#预测是时间,是在原始数据上加入50个月变为[194 rows x 1 columns]
future = m.make_future_dataframe(50, freq='MS')
print(future)
forecast = m.predict(future)
fig = m.plot(forecast)
fig.show()
fig2 = m.plot_components(forecast)
fig2.show()
第一部分对成分图分析类似,我们这里对乘法模型的成分图进行一个分析:
①图1是根据trend画出来的,图2是根据yearly画出来的。
②因为是乘法模型,有:forecast['multiplicative_terms'] = forecast['yearly'];因此:forecast['yhat'] = forecast['trend'] * (1+forecast['multiplicative_terms'])。
使用seasonality_mode='multiplicative',节假日也将被建模为乘法效果。
随着seasonality_mode='multiplicative',假日效应也将被建模为乘法。默认情况下,任何添加的季节性或额外的回归量都将使用seasonality_mode设置的任何值,但可以通过在添加季节性或回归量时指定mode='additive'或mode='multiplicative'作为参数来覆盖。
import pandas as pd
import matplotlib.pyplot as plt
from fbprophet import Prophet
from prophet.plot import plot_plotly, plot_components_plotly
import time
from fbprophet.plot import plot_yearly
#原来数据大小是[144 rows x 2 columns]
df = pd.read_csv('example_air_passengers.csv')
print(df)
m = Prophet(seasonality_mode='multiplicative')
m.add_seasonality('quarterly', period=91.25, fourier_order=8, mode='additive')
m.fit(df)
#预测是时间,是在原始数据上加入50个月变为[194 rows x 1 columns]
future = m.make_future_dataframe(50, freq='MS')
print(future)
forecast = m.predict(future)
fig = m.plot(forecast)
fig.show()
fig2 = m.plot_components(forecast)
fig2.show()
这个时候是时间序列的混合模型:forecast['yhat'] = forecast['trend'] * (1+forecast['multiplicative_terms']) + forecast['additive_terms']。
加法和乘法额外回归量将显示在分量图的单独面板中。但是请注意,加法和乘法季节性混合的可能性很小,因此通常只有在有理由预期会出现这种情况时才使用这种方法。
三,预测区间
默认情况下,Prophet 将返回预测的不确定区间yhat。这些不确定区间背后有几个重要的假设。预测中存在三个不确定性来源:趋势中的不确定性、季节性估计中的不确定性以及额外的观测噪声。
3.1 趋势的不确定性
预测中,不确定性最大的来源就在于未来趋势改变的不确定性。在之前的时间序列实例中,我们可以发现历史数据具有明显的趋势性。 Prophet 能够监测并去拟合它,但是我们期望得到的趋势改变究竟会如何走向呢?或许这是无解的,因此我们尽可能地做出最合理的推断,假定 “未来将会和历史具有相似的趋势” 。尤其重要的是,我们假定未来趋势的平均变动频率和幅度和我们观测到的历史值是一样的,从而预测趋势的变化并通过计算,最终得到预测区间。
这种衡量不确定性的方法具有以下性质:变化速率灵活性更大时(通过增大参数 changepoint_prior_scale 的值),预测的不确定性也会随之增大。原因在于如果将历史数据中更多的变化速率加入了模型,也就代表我们认为未来也会变化得更多,就会使得预测区间成为反映过拟合的标志。
预测区间的宽度(默认下,是 80% )可以通过设置 interval_width 参数来控制:
m = Prophet(interval_width=0.95).fit(df)
future = m.make_future_dataframe(periods=365)
forecast = m.predict(future)
由于预测区间估计时假定未来将会和过去保持一样的变化频率和幅度,而这个假定可能并不正确,所以预测区间的估计不可能完全准确。
3.2 季节性的不确定性
默认情况下,Prophet 只会返回趋势和观察噪声的不确定性。要获得季节性的不确定性,您必须进行完整的贝叶斯抽样。这是使用参数mcmc.samples(默认为 0)完成的。我们在这里为快速入门中 Peyton Manning 数据的前六个月执行此操作:
m = Prophet(mcmc_samples=300)
forecast = m.fit(df).predict(future)
这用 MCMC 采样取代了典型的 MAP 估计,并且可能需要更长的时间,具体取决于有多少观察 - 预计几分钟而不是几秒钟。如果您进行完全抽样,那么当您绘制季节性成分时,您会看到它们的不确定性:
fig = m.plot_components(forecast)
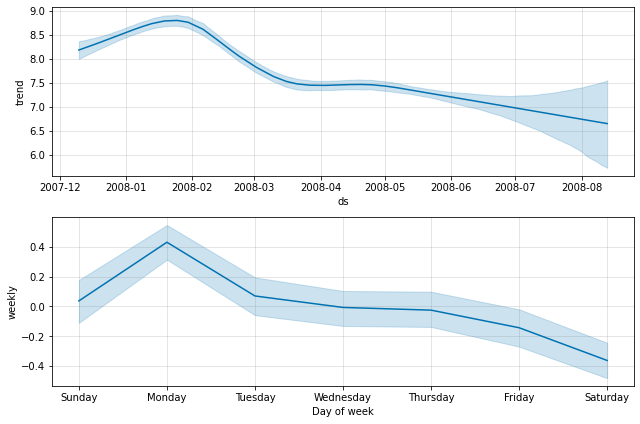
四,异常值 (将数据的异常值区间设置为none)
异常值可以通过两种主要方式影响 Prophet 的预测。在这里,我们对之前记录的对 R 页面的 Wikipedia 访问进行了预测,但带有一个坏数据块:
import pandas as pd
import matplotlib.pyplot as plt
from fbprophet import Prophet
from prophet.plot import plot_plotly, plot_components_plotly
import time
from fbprophet.plot import plot_yearly
#原来数据大小是[2863 rows x 2 columns]
df = pd.read_csv('example_wp_log_R_outliers1.csv')
print(df)
m = Prophet()
m.fit(df)
#预测是时间,是在原始数据上加入50个月变为[3959 rows x 1 columns]
future = m.make_future_dataframe(1096)
print(future)
forecast = m.predict(future)
fig = m.plot(forecast)
fig.show()
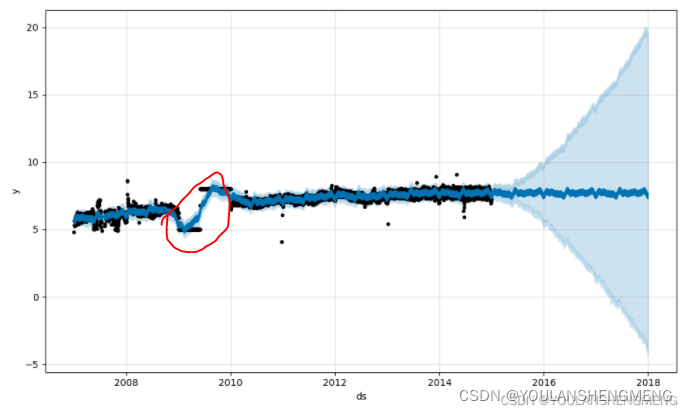
趋势预测似乎合理,但不确定性区间似乎太宽了。Prophet 能够处理历史中的异常值,但只能通过将它们与趋势变化相匹配。然后,不确定性模型预计类似幅度的未来趋势变化。
解决方法:
处理异常值的最佳方法是删除它们 - Prophet 没有丢失数据的问题。如果您将它们的值设置NA在历史记录中但将日期保留在 中future,那么 Prophet 将为您提供对它们值的预测。
import pandas as pd
import matplotlib.pyplot as plt
from fbprophet import Prophet
from prophet.plot import plot_plotly, plot_components_plotly
import time
from fbprophet.plot import plot_yearly
#原来数据大小是[2863 rows x 2 columns]
df = pd.read_csv('example_wp_log_R_outliers1.csv')
#将坏的数据设置为none
df.loc[(df['ds'] > '2010-01-01') & (df['ds'] < '2011-01-01'), 'y'] = None
print(df)
m = Prophet()
m.fit(df)
#预测是时间,是在原始数据上加入50个月变为[3959 rows x 1 columns]
future = m.make_future_dataframe(1096)
print(future)
forecast = m.predict(future)
fig = m.plot(forecast)
fig.show()

在上面的例子中,异常值扰乱了不确定性估计,但没有影响主要预测yhat。情况并非总是如此,例如在此示例中添加了异常值:
import pandas as pd
import matplotlib.pyplot as plt
from fbprophet import Prophet
from prophet.plot import plot_plotly, plot_components_plotly
import time
from fbprophet.plot import plot_yearly
#原来数据大小是[2863 rows x 2 columns]
df = pd.read_csv('example_wp_log_R_outliers2.csv')
#将坏的数据设置为none
#df.loc[(df['ds'] > '2010-01-01') & (df['ds'] < '2011-01-01'), 'y'] = None
print(df)
m = Prophet()
m.fit(df)
#预测是时间,是在原始数据上加入50个月变为[3959 rows x 1 columns]
future = m.make_future_dataframe(1096)
print(future)
forecast = m.predict(future)
fig = m.plot(forecast)
fig.show()
 2015 年 6 月的一组极端异常值扰乱了季节性估计,因此它们的影响将永远回荡在未来。同样正确的方法是删除它们:
2015 年 6 月的一组极端异常值扰乱了季节性估计,因此它们的影响将永远回荡在未来。同样正确的方法是删除它们:
import pandas as pd
import matplotlib.pyplot as plt
from fbprophet import Prophet
from prophet.plot import plot_plotly, plot_components_plotly
import time
from fbprophet.plot import plot_yearly
#原来数据大小是[2863 rows x 2 columns]
df = pd.read_csv('example_wp_log_R_outliers2.csv')
#将坏的数据设置为none
df.loc[(df['ds'] > '2015-06-01') & (df['ds'] < '2015-06-30'), 'y'] = None
print(df)
m = Prophet()
m.fit(df)
#预测是时间,是在原始数据上加入50个月变为[3959 rows x 1 columns]
future = m.make_future_dataframe(1096)
print(future)
forecast = m.predict(future)
fig = m.plot(forecast)
fig.show()

五,非每日数据
5.1 子日数据
Prophet 可以通过在列中传入带有时间戳的数据框来对具有日观察的时间序列进行预测ds。时间戳的格式应为 YYYY-MM-DD HH:MM:SS - 请参见此处的示例 csv 。当使用次日数据时,将自动拟合日季节性。在这里,我们将 Prophet 拟合到 5 分钟分辨率的数据(优胜美地的每日温度):【原始数据是每5分钟时间间隔的温度测试】
df = pd.read_csv('example_yosemite_temps.csv')
print(df)
m = Prophet(changepoint_prior_scale=0.01).fit(df)
#预测原数据300小时后的数据
future = m.make_future_dataframe(periods=300, freq='H')
print(future)
import pandas as pd
import matplotlib.pyplot as plt
from fbprophet import Prophet
from prophet.plot import plot_plotly, plot_components_plotly
import time
from fbprophet.plot import plot_yearly
#[18721 rows x 2 columns]是一个每5分钟的监测
df = pd.read_csv('example_yosemite_temps.csv')
print(df)
m = Prophet(changepoint_prior_scale=0.01).fit(df)
#预测原数据300小时后的数据
future = m.make_future_dataframe(periods=300, freq='H')
print(future)
fcst = m.predict(future)
fig = m.plot(fcst)
fig.show()
成分图中的日季节性:
fig = m.plot_components(fcst)

5.2 有规则间隔的数据
假设上面的数据集只有每天早上6点之前的观测值:
import pandas as pd
import matplotlib.pyplot as plt
from fbprophet import Prophet
from prophet.plot import plot_plotly, plot_components_plotly
import time
from fbprophet.plot import plot_yearly
#[18721 rows x 2 columns]是一个每5分钟的监测
df = pd.read_csv('example_yosemite_temps.csv')
#假设数据只有每天早上六点之前的观测值
df2 = df.copy()
df2['ds'] = pd.to_datetime(df2['ds'])
df2 = df2[df2['ds'].dt.hour < 6]
m = Prophet().fit(df2)
future = m.make_future_dataframe(periods=300, freq='H')
fcst = m.predict(future)
fig = m.plot(fcst)
fig.show()
预测似乎很差,未来的波动比历史上看到的要大得多。这里的问题是,我们已将每日周期拟合到仅包含一天中部分时间(12a 到 6a)的数据的时间序列。因此,在一天的剩余时间里,每日的季节性【就是预测值】是不受限制的,因此估计得不好。解决方案是仅对有历史数据的时间窗口进行预测。在这里,这意味着将future数据帧的时间限制为 12a 到 6a:

同样的原则也适用于数据中有规律间隙的其他数据集。例如,如果历史记录仅包含工作日,则应仅对工作日进行预测,因为无法很好地估计周末的每周季节性。
5.3 月数据
可以使用Prophet来匹配每月的数据。然而,Prophet 的基本模型是连续时间的,这意味着如果将模型与每月的数据相匹配,然后要求每天的预测,我们会得到奇怪的结果。
下面使用美国零售业销售量数据来预测未来 10 年的情况:
首先分析输入数据:按月为单位,记录了1992年1月到2016年5月的每个月的销售额,且数据只有每个月的第一天的数据

设置的预测到的时间是10年后,需要预测是并不是每一个月的第一天的数据,而是预测的是10年后每一天的销售额

import pandas as pd
import matplotlib.pyplot as plt
from fbprophet import Prophet
from prophet.plot import plot_plotly, plot_components_plotly
import time
from fbprophet.plot import plot_yearly
df = pd.read_csv('example_retail_sales.csv')
print(df)
#使用的是乘法模型
m = Prophet(seasonality_mode='multiplicative').fit(df)
#预测未来10年的零售额
future = m.make_future_dataframe(periods=3652)
print(future)
fcst = m.predict(future)
fig = m.plot(fcst)
fig.show()
这与上面的数据集具有常规间隙的问题相同。当我们拟合年度季节性时,它只有每个月的第一天的数据,其余天的季节性分量无法识别且过拟合。这可以通过做 MCMC 来清楚地看到季节性的不确定性:
m = Prophet(seasonality_mode='multiplicative', mcmc_samples=300).fit(df)
fcst = m.predict(future)
fig = m.plot_components(fcst)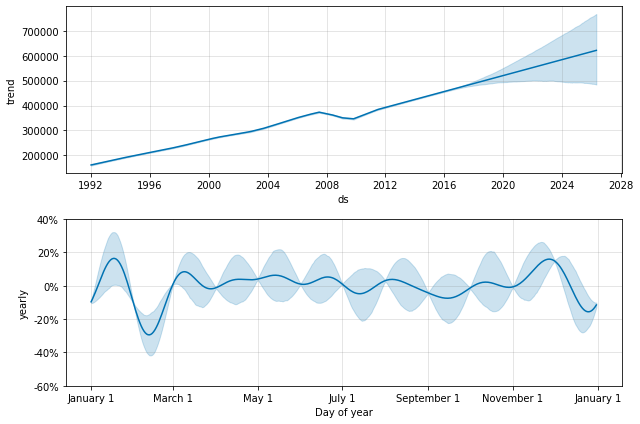
季节性在有数据点的每个月初具有较低的不确定性,但在其间具有非常高的后验方差。将 Prophet 拟合到月度数据时,只进行月度预测,这可以通过将频率传递给 来完成make_future_dataframe:
future = m.make_future_dataframe(periods=120, freq='MS')
fcst = m.predict(future)
fig = m.plot(fcst)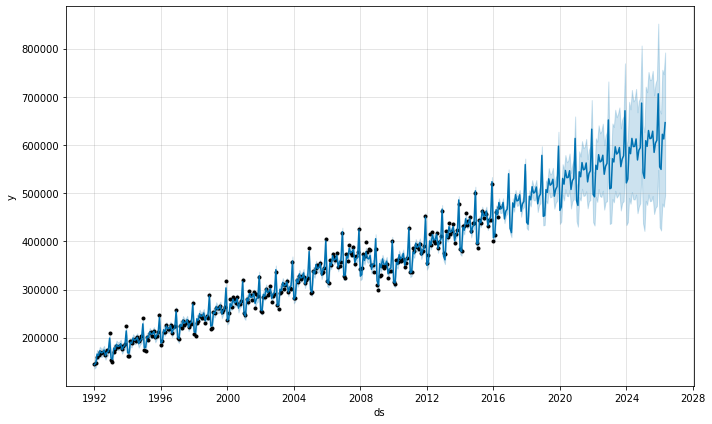
相关文章
- 机器学习笔记五-----------------Prophet(时间序列模型)的保存及调用,微调及总结
- 机器学习/Machine Learning:综述
- 机器爱人即将一统江湖,谁还稀罕过什么情人节
- 美联储加持的小众语言 Julia ,能否成为机器学习的明日之星?
- 机器学习零基础?手把手教你用TensorFlow搭建图像识别系统(一)| 干货
- [转载]基于机器学习的专业级摄影照片处理器
- 《构建实时机器学习系统》一第2章 实时监督式机器学习 2.1 什么是监督式机器学习
- 《Web安全之机器学习入门》一 2.1 Python在机器学习领域的优势
- 机器学习入门:线性回归及梯度下降
- 机器学习数学知识积累之概率论
- Python库【数据处理、机器学习、大数据、文件处理等14个类的所有python库整理】
- 第7课:spark机器学习第7课:spark机器学习内幕剖析
- 聊聊机器学习中的无监督学习
- 机器学习之正则化图文讲解
- 机器学习常见算法分类汇总