
探索未对齐内存CPU的访问逻辑
目录
问题:
如下结构体在未对齐的情况下,读取数据时CPU需要对成员变量i进行两次访问才能完全读取其中数据。
struct text
{
char c;
int i;
};
struct text a;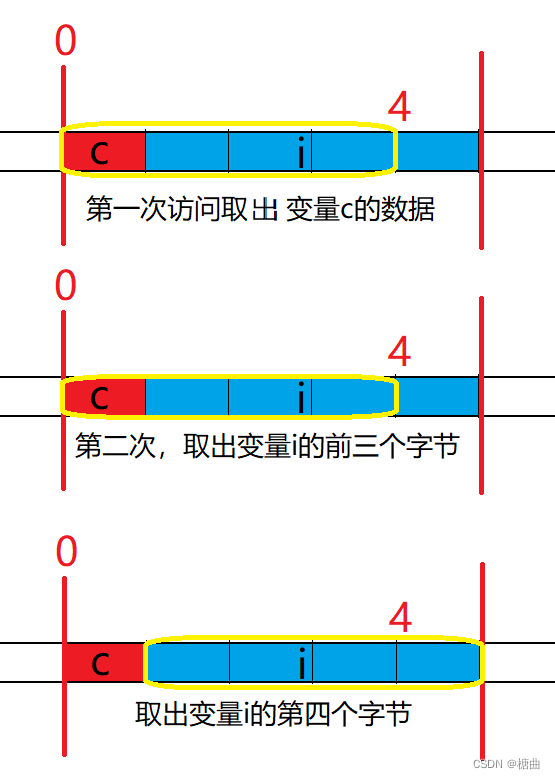
基于32位平台,CPU每次访问4个字节
为什么不能在取变量i的数据时直接从偏移量为1的位置直接开始读取呢?
这是由于计算机CPU和计算机数据存储的特点造成的,而且这个问题在硬件上大多数是没有办法有效处理。(我对硬件不熟悉,因为遇到了问题所以查资料解决一下,这里只谈实现过程)
数据在内存的存储
计算机中数据存储在内存中,而内存以硬件的形式出现,表现为不同的内存块,比如内存0有它自己的一块空间,还有内存1、内存2、内存3这些不同的内存块。这些内存的访问顺序又是对应偏移量走的,看下图:
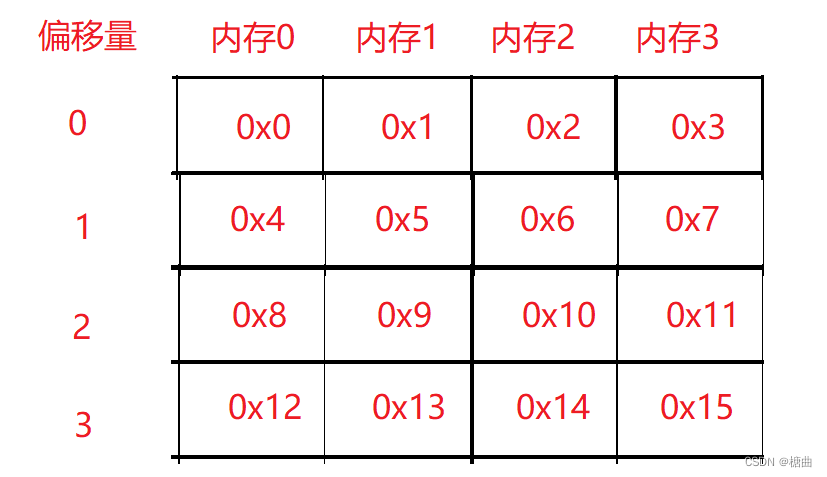
CPU每次访问都是以偏移量访问的,每次读取4个字节,首先从偏移量为0的内存开始,之后是1,依次往后。
CPU的访问
让我们回到之前的问题,结构体中成员变量c的数据存在0x0地址处,成员变量i的数据存储在0x1、0x2、0x3、0x4地址处,此时变量i的存储范围以经到了偏移量为1的地址处。
CPU首先访问偏移量为0的四个地址,取出i变量i的三个字节。
CPU其次访问偏移量为1的四个地址,取出i变量的一个字节。
总共访问两次。
如果是在对齐的情况下
地址0x0处存放变量 c 的数据 —— 访问偏移量为0的四个地址一次取出数据
地址0x4、0x5、0x6、0x7存放变量 i 的数据 —— 访问偏移量为1的四个地址一次取出数据
总结:
虽然内存的对齐浪费掉了一些空间,但它的执行速度得以提升。在计算机内存大小持续上涨的今天,浪费掉的内存和所换取的时间相比,是可以接受的。
查阅文献:performance - Why misaligned address access incur 2 or more accesses? - Stack Overflow
相关文章
- sqlserver默认的内存策略
- 内存问题的排查工具和方法– Clang的AddressSanitizer
- Elasticsearch 缓存及使用 Circuit Breaker 限制内存使用
- Nginx/OpenResty内存泄漏/目录穿越漏洞通告
- C语言那年踩过的坑--局部变量,静态变量,全局变量在内存中存放的位置
- Go Web:数据存储(1)——内存存储
- SetProcessWorkingSetSize() 方法使内存降低了很多(把内存放到交换区,其实会降低性能)——打开后长时间不使用软件,会有很长时间的加载过程,原来是这个!
- 非io优化实例CentOS 7系统 4G内存 free -m 显示内存3.5g左右
- jmap查看内存使用情况与生成heapdump--转