
Simple Image Caption Tutorial
Simple Image Caption Tutorial
Data set: Flickr8k-Images-Captions
Video: Pytorch Image Captioning Tutorial
GitHub: Image Captioning
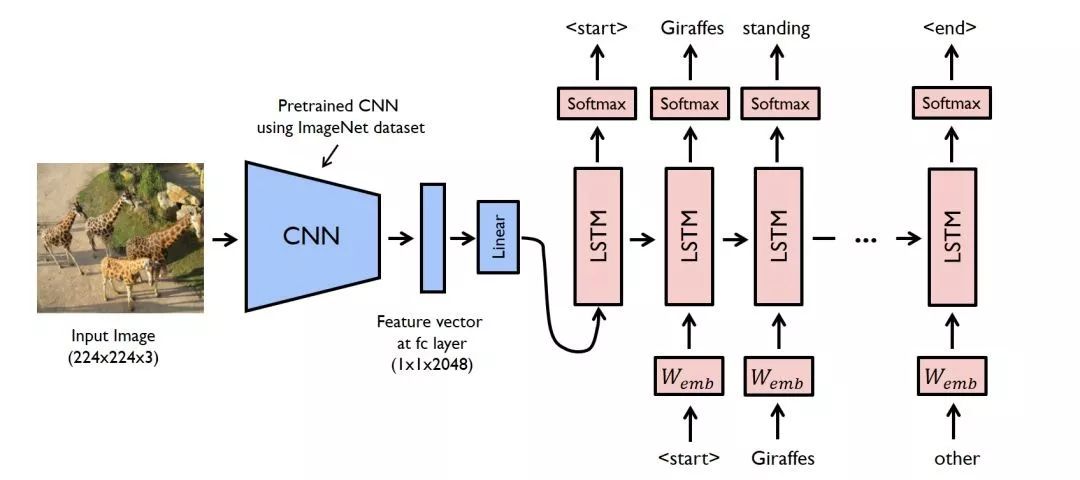
In this tutorial, inception v3 and LSTM are used to build the model.
Build Vocabulary
Build your own vocabulary
Convert text --> numerical values
-
We want to convert text -> numerical values
-
We need a Vocabulary mapping each word to a index
-
We need to setup a Pytorch dataset to load the data
-
Setup padding of every batch (all examples should be of same seq_len and setup data loader)
Use package spacy to tokenize the texts.
Create your own vocabulary
- Set a frequency threshold: If the number of occurrences of this word is less than the threshold, it is added to .
- Use
spacyto tokenize the sentence. - Numericized the token in the vocaluary.
class Vocabulary:
def __init__(self, freq_threshold):
# set standard value
self.itos = {0: "<PAD>", 1: "<SOS>", 2: "<EOS>", 3: "<UNK>"}
self.stoi = {"<PAD>": 0, "<SOS>": 1, "<EOS>": 2, "<UNK>": 3}
self.freq_threshold = freq_threshold
def __len__(self):
return len(self.itos)
@staticmethod
def tokenizer_eng(text):
return [tok.text.lower() for tok in spacy_eng.tokenizer(text)]
# Save words to itos and stoi
def build_vocabulary(self, sentence_list):
frequencies = {}
idx = 4
for sentence in sentence_list:
for word in self.tokenizer_eng(sentence):
if word not in frequencies:
frequencies[word] = 1
else:
frequencies[word] += 1
if frequencies[word] == self.freq_threshold:
self.stoi[word] = idx
self.itos[idx] = word
idx += 1
Prepare your own data set
- Flickr8k: The caption data set is in the following format:
| Image | Caption | |
|---|---|---|
| 0 | 1000268201_693b08cb0e.jpg | A child in a pink dress is climbing up a set of stairs in an entry way . |
| 1 | 1000268201_693b08cb0e.jpg | A girl going into a wooden building . |
| 2 | 1000268201_693b08cb0e.jpg | A little girl climbing into a wooden playhouse . |
| … | … | … |
- Create your own data set.
Use the series.tolist() function in pandas package to transfer the captions to a list of sentences. Then, build the vocabulary.
The __getitem__() and __len__() need to be overwritten. The return of the __getitem__() is the image and target caption of the image.
class FlickrDataset(Dataset):
def __init__(self, root_dir, captions_file, transform=None, freq_threshold=5):
self.root_dir = root_dir
self.df = pd.read_csv(captions_file)
self.transform = transform
# Get img, caption columns
self.imgs = self.df["image"]
self.captions = self.df["caption"]
# Initialize vocabulary and build vocab
self.vocab = Vocabulary(freq_threshold)
self.vocab.build_vocabulary(self.captions.tolist())
def __len__(self):
return len(self.df)
def __getitem__(self, index):
caption = self.captions[index]
img_id = self.imgs[index]
img = Image.open(os.path.join(self.root_dir, img_id)).convert("RGB")
if self.transform is not None:
img = self.transform(img)
numericalized_caption = [self.vocab.stoi["<SOS>"]]
numericalized_caption += self.vocab.numericalize(caption)
numericalized_caption.append(self.vocab.stoi["<EOS>"])
return img, torch.tensor(numericalized_caption)
After this function, each image and caption are combined as (image, caption) to form a data set.
Define the collate_fn
We need pad the caption with padding value in order to ensure the length of sentences in a batch is same. The MyCollate is to create our own collate function to batch the input data.
class MyCollate:
def __init__(self, pad_idx):
self.pad_idx = pad_idx
def __call__(self, batch):
# first item is image and cat all the image together
imgs = [item[0].unsqueeze(0) for item in batch]
imgs = torch.cat(imgs, dim=0)
targets = [item[1] for item in batch]
targets = pad_sequence(targets, batch_first=False, padding_value=self.pad_idx)
return imgs, targets
If the batch size is set as 32, the input image is the size: (3, 224, 224). The data set after batching is:
torch.Size([32, 3, 224, 224]) # image
torch.Size([23, 32]) # capthon: batch_first = False
TIP:
torch.nn.utils.rnn.pad_sequence(sequences, batch_first=False, padding_value=0.0)
Example:
>>> from torch.nn.utils.rnn import pad_sequence
>>> a = torch.ones(25, 300)
>>> b = torch.ones(22, 300)
>>> c = torch.ones(15, 300)
>>> pad_sequence([a, b, c]).size()
torch.Size([25, 3, 300])
If the batch_first set as True, the output will be: torch.Size([3, 25, 300])
Create the data loader
Use the data set and collect function created before to create your own data loader.
def get_loader(
root_folder,
annotation_file,
transform,
batch_size=32,
num_workers=8,
shuffle=True,
pin_memory=True,
):
dataset = FlickrDataset(root_folder, annotation_file, transform=transform)
pad_idx = dataset.vocab.stoi["<PAD>"]
loader = DataLoader(
dataset=dataset,
batch_size=batch_size,
num_workers=num_workers,
shuffle=shuffle,
pin_memory=pin_memory,
collate_fn=MyCollate(pad_idx=pad_idx),
)
return loader, dataset
The size of data in data loader is:
torch.Size([32, 3, 224, 224])
torch.Size([23, 32]) # 23: the longest length of sentence
Build Network
Encoder CNN
Use one CNN model to extract features from images. Change the size of fully connection layer to the same as the word embed_size.
class EncoderCNN(nn.Module):
def __init__(self, embed_size, train_CNN = False):
super(EncoderCNN, self).__init__()
self.train_CNN = train_CNN
self.inception = models.inception_v3(pretrained=True, aux_logistic = False)
self.inception.fc = nn.Linear(self.inception.fc.in_features, embed_size)
self.relu = nn.ReLU()
self.dropout = nn.Dropout(0.5)
def forward(self, images):
features = self.inception(images)
for name, param in self.inception.named_parameters():
if "fc.weight" in name or "fc.bias" in name:
param.requires_grad = True
else:
param.requires_grad = self.train_CNN
return self.dropout(self.relu(features))
Decoder RNN
In this part, LSTM is used to decoder the features. In this way, captions of images can be generated.
The use of nn.Embedding(vocab_size, embed_size):
vocab_size: The size of the vocabolary.
embed_size: The size of embedding vector. --> Use the embedding vector to represent each word in vocabolary.
One optional parameter padding_idx: If specified, the entries at padding_idx do not contribute to the gradient; therefore, the embedding vector at padding_idx is not updated during training. Usually, in a dictionary, there will have a word <PAD> to use as padding_index.
class DecoderRNN(nn.Module):
def __init__(self, embed_size, hidden_size, vocab_size, num_layers):
super(DecoderRNN, self).__init__()
self.embed = nn.Embedding(vocab_size, embed_size)
self.lstm = nn.LSTM(embed_size, hidden_size, num_layers)
self.linear = nn.Linear(hidden_size, vocab_size)
self.dropout = nn.Dropout(0.5)
def forward(self, features, captions):
embeddings = self.dropout(self.embed(captions))
embeddings = torch.cat((features.unsqueeze(0), embeddings), dim = 0)
hiddens, _ = self.lstm(embeddings)
outputs = self.linear(hiddens)
return outputs
Explain:
embeddings = torch.cat((features.unsqueeze(0), embeddings), dim = 0)
Suppose the features from the CNN as a input embedding at t=0. features.unsqueeze(0) is to add a time dimension.
CNN to RNN
In this part, the output of CNN will be sent to RNN to generate the caption of the image.
class CNNtoRNN(nn.Module):
def __init__(self, embed_size, hidden_size, vocab_size, num_layers):
super(CNNtoRNN, self).__init__()
self.encoderCNN = EncoderCNN(embed_size)
self.decoderRNN = DecoderRNN(embed_size, hidden_size, vocab_size, num_layers)
def forward(self, images, captions):
features = self.encoderCNN(images)
outputs = self.decoderRNN(features, captions)
return outputs
def caption_image(self, image, vocabulary, max_length=50):
result_caption = []
with torch.no_grad():
x = self.encoderCNN(image).unsqueeze(0)
states = None
for _ in range(max_length):
hiddens, states = self.decoderRNN.lstm(x, states)
output = self.decoderRNN.linear(hiddens.unsqueeze(0))
predicted = output.argmax(1)
result_caption.append(predicted.item())
x = self.decoderRNN.embed(predicted).unsqueeze(0)
The unsqueeze(0) is to add an additional dimension for batch size.
Train the Model
Create the Model
model = CNNtoRNN(embed_size, hidden_size, vocab_size, num_layers).to(device)
criterion = nn.CrossEntropyLoss(ignore_index=dataset.vocab.stoi["<PAD>"])
optimizer = optim.Adam(model.parameters(), lr=learning_rate)
Set the ignore index: dataset.vocab.stoi["<PAD>"]
Training the Model
# Only finetune the CNN
for name, param in model.encoderCNN.inception.named_parameters():
if "fc.weight" in name or "fc.bias" in name:
param.requires_grad = True
else:
param.requires_grad = train_CNN
if load_model:
step = load_checkpoint(torch.load("my_checkpoint.pth.tar"), model, optimizer)
model.train()
for epoch in range(num_epochs):
# Uncomment the line below to see a couple of test cases
# print_examples(model, device, dataset)
print(f'>>>>>> epoch: {epoch} >>>>>>')
if save_model:
checkpoint = {
"state_dict": model.state_dict(),
"optimizer": optimizer.state_dict(),
"step": step,
}
save_checkpoint(checkpoint)
for idx, (imgs, captions) in tqdm(enumerate(train_loader),
total=len(train_loader), leave=False):
imgs = imgs.to(device)
captions = captions.to(device)
outputs = model(imgs, captions[:-1])
# (seq_len, N, vocab_size), (seq_len, N)
loss = criterion(
outputs.reshape(-1, outputs.shape[2]), captions.reshape(-1)
)
writer.add_scalar("Training loss", loss.item(), global_step=step)
step += 1
optimizer.zero_grad()
loss.backward(loss)
optimizer.step()
Explain: loss = criterion(outputs.reshape(-1, outputs.shape[2]), captions.reshape(-1))
The maximum input size of the CrossEntropy is 2. From official document, we can see:
- Input: (N,C) where C = number of classes, or(N,C,d1,d2,…,d**K) with K ≥ 1 K \geq 1 K≥1 in the case of K-dimensional loss.
- Target: (N) where each value is 0 ≤ t a r g e t s [ i ] ≤ C − 1 0≤targets[i]≤C−1 0≤targets[i]≤C−1 , or(N,d1,d2,…,d**K) with K ≥ 1 K \geq 1 K≥1 in the case of K-dimensional loss.
For the seq2seq model, the target size is (seq_len, N) and the output size is (seq_len, N, vocab_size). The vocab_size is like the classes of the word. ( N ∗ s e q _ l e n ) (N*seq\_len) (N∗seq_len) is like the all numbers of the prediction.
相关文章
- Google Earth Engine(GEE)——ee.image.cumulativeCost函数的使用(多波段影像值变为0)
- c#中字节数组byte[]、图片image、流stream,字符串string、内存流MemoryStream、文件file,之间的转换
- iOS8 Core Image In Swift:自动改善图像以及内置滤镜的使用
- SwiftUI实战之Picker带Image和图标效果(教程和源码)
- Android-Universal-Image-Loader学习笔记(4)--download
- maptalks 开发GIS地图(36)maptalks.three.29- custom-image-plane
- Image-guided Surgery 链接
- 835. Image Overlap