
[论文笔记] SODA小目标综述(西工大)
2023-09-27 14:20:18 时间
SODA小目标综述(西工大)
Towards Large-Scale Small Object Detection:Survey and Benchmarks
这篇文章需要后续跟踪一下,可能有一些数据集SODA-A和SODA-D等等发布
动机
- 从小物体的有限和扭曲的信息中学习正确特征表示本来就很困难。解决的办法有如下6种:data-manipulation methods, scale-aware methods, feature-fusion methods, super-resolution methods, context-modeling methods, other approaches
- 小目标检测缺乏大规模的数据集。因此提出了两个数据集SODA-A(航拍图片)和 SODA-D(交通图片)
1、小目标检测难点
- 信息丢失。下采样会导致小目标的信息产生大量的丢失。(检测小目标的时候能不能不进行下采样,或者我能够在原图上提取出小目标的区域来减少计算量吗?)
- 噪声特征。小目标的特征很容易被背景、其他物体的特征污染。
- 边界框扰动容限低。(用一种新的IoU评价规则来处理小目标可以吗,不然小目标的mAP和大目标的mAP不公平)

2、小目标检测算法
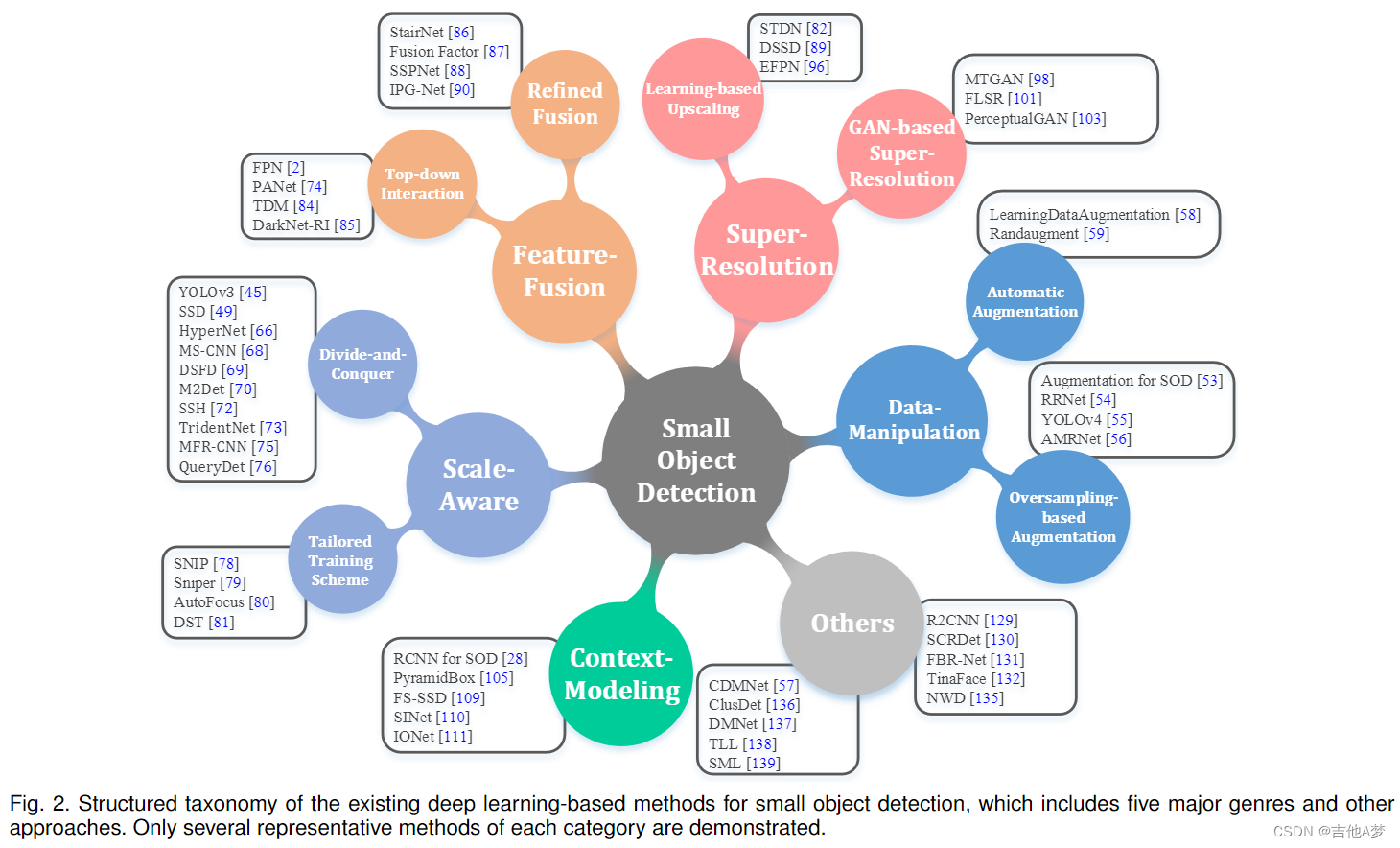
数据增强(Data-manipulation methods)
- 不同尺度的目标之间的数量差异巨大,一般小目标的数量都比较少,因此一个直观的方法是使用数据增强的方法来增加小目标的数量;
- 但是这样的方法也有弊端,就是它们的效果取决于数据集,而不具有通用性、迁移性。(能不能和 跨域检测 牵扯上关系)
-
基于过采样的增强策略(Oversampling-based augmentation strategy):例如Mosaic这样的方法、复制一个小物体并将其随机变换粘贴到相同图像的不同位置上
-
自动增强方案(Automatic augmentation scheme):将一些数据增强的方法进行组合使用
多尺度(Scale-aware methods)
不同level的特征图负责进行不同尺度的物体的检测
- 以 分而治之 的方式进行多尺度检测(Multi-scale detection in a divide-and-conquer fashion):不同level的特征只负责检测相应尺度的物体
- 针对小目标检测的定制方法(Tailored training schemes)
特征融合(Feature-fusion methods)
- 不同level的特征图不能同时拥有语义信息和空间信息,因此使用特征融合来让一个特征图同时拥有这两种信息;
- 问题是,我们不仅要赋予浅层特征更多的语义,而且要防止小物体的原始响应被更深层特征掩盖,这是一个dilemma
- 自上而下的信息融合(Top-down information interaction):用自上而下的路径来进行浅层和深层特征的融合(将深层特征图融合到浅层特征图当中去),使高分辨率特征图同时具有丰富的语义特征和小物体的空间特征。
- 细化的特征融合(Refined feature fusion):top-down方法一般采用简单的上采样来进行融合,无法处理内在的尺度层面的不一致。因此可以使用例如反卷积等可学习的方法来优化特征融合的过程。
超分辨率(Super-resolution methods)
- 传统方法放大图片使用基于插值的方法,它是一种局部操作,无法捕捉全局信息并且会有马赛克效应,同时它们的外观等信息也会在放大的过程中保持扭曲和模糊,不会得到优化
- 现在有些方法采用生成对抗网络(GAN)来计算有利于小目标检测的高质量表示,而还有方法则选择参数化上采样操作来放大特征
- 可学习上采样(Learning-based upscaling):例如使用反卷积进行上采样
- 基于GAN的超分辨率框架(GAN-based super-resolution frameworks):直接对RoI进行超分辨率;但是容易丢失context信息
上下文建模(Context-modeling methods)
是不是有助于遮挡目标检测,例如x-ray,小目标检测和遮挡目标检测进行融合?
- 当前的上下文建模机制以启发式和经验的方式确定上下文区域,这不能保证构建的表示具有足够的可解释性以进行检测(能不能把context-modeling变成一个可以学习的过程)
其他方法(Others)
- 基于注意力的方法(Attention-based methods):需要看一下相关的论文
- 本地化驱动的优化(Localization-driven optimization):检测器回归分支的目标是IoU,但是对于小目标来说,IoU并不是一个很好的方法
- 密度分析引导的检测(Density analysis guided detection):小目标一般在图片中的位置比较多且分散,我们可以抽离出包含目标的区域然后再进行检测。
- 其他方法(Other issues)
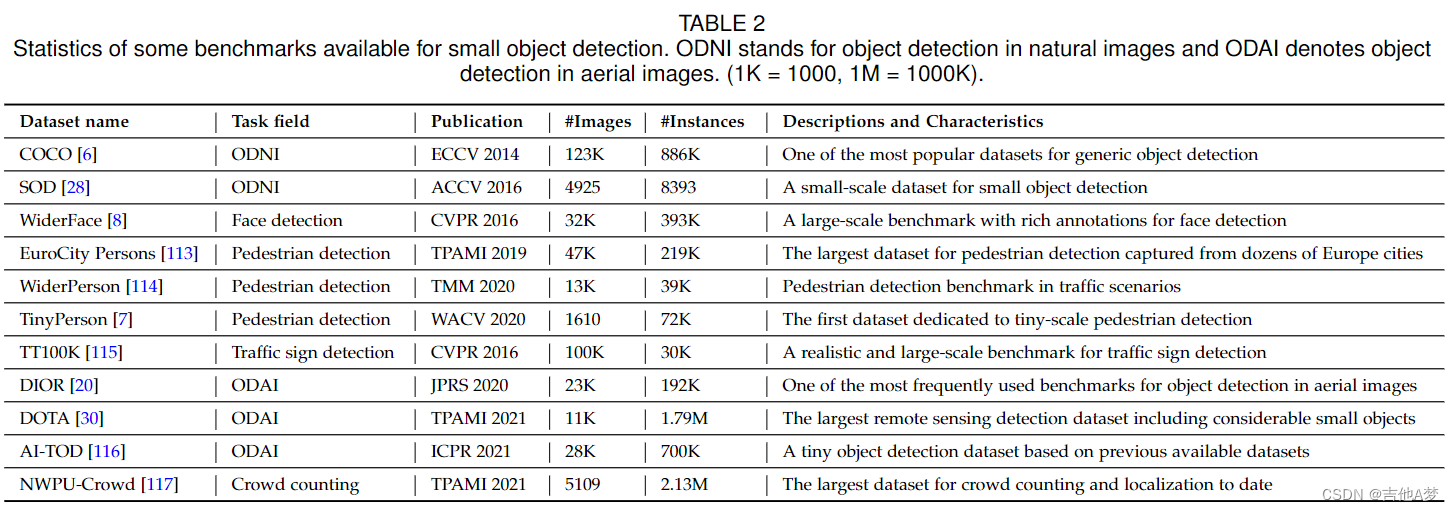
3、小目标检测数据集
4、基准(Benchmark)



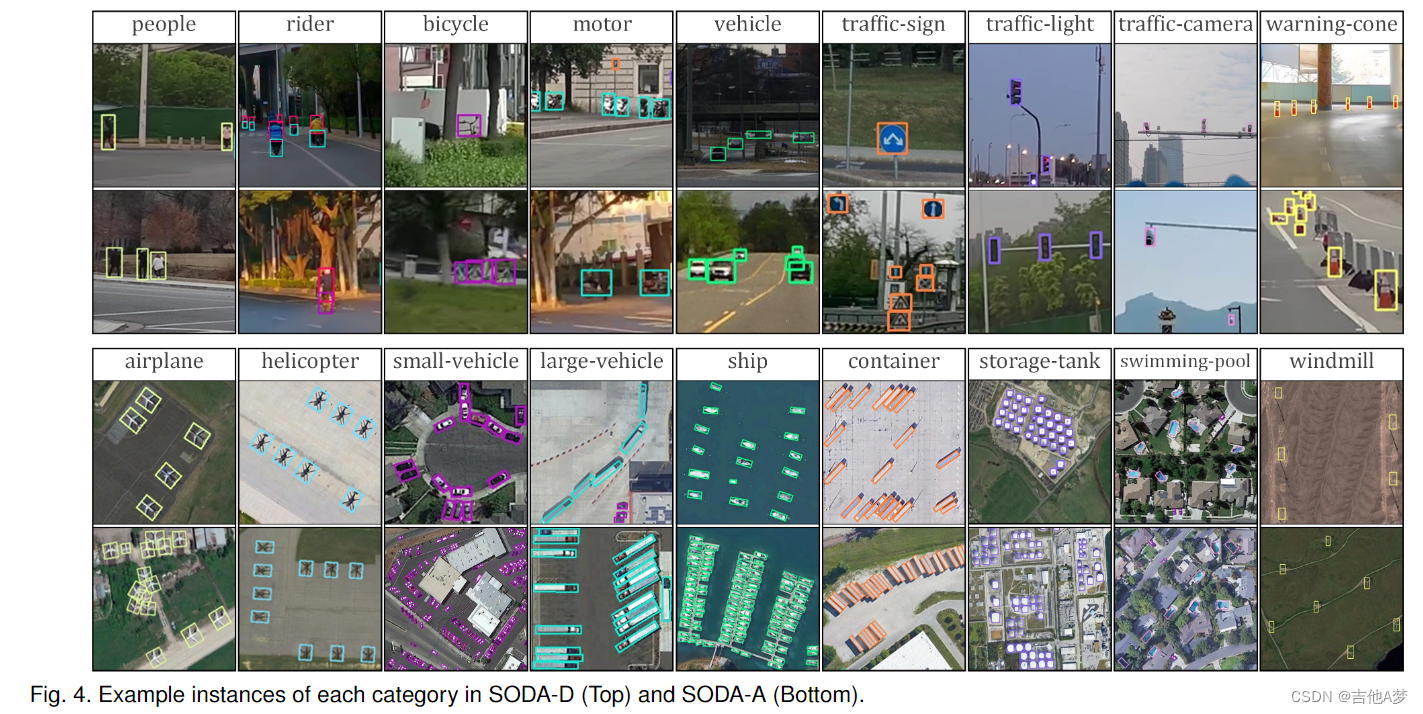
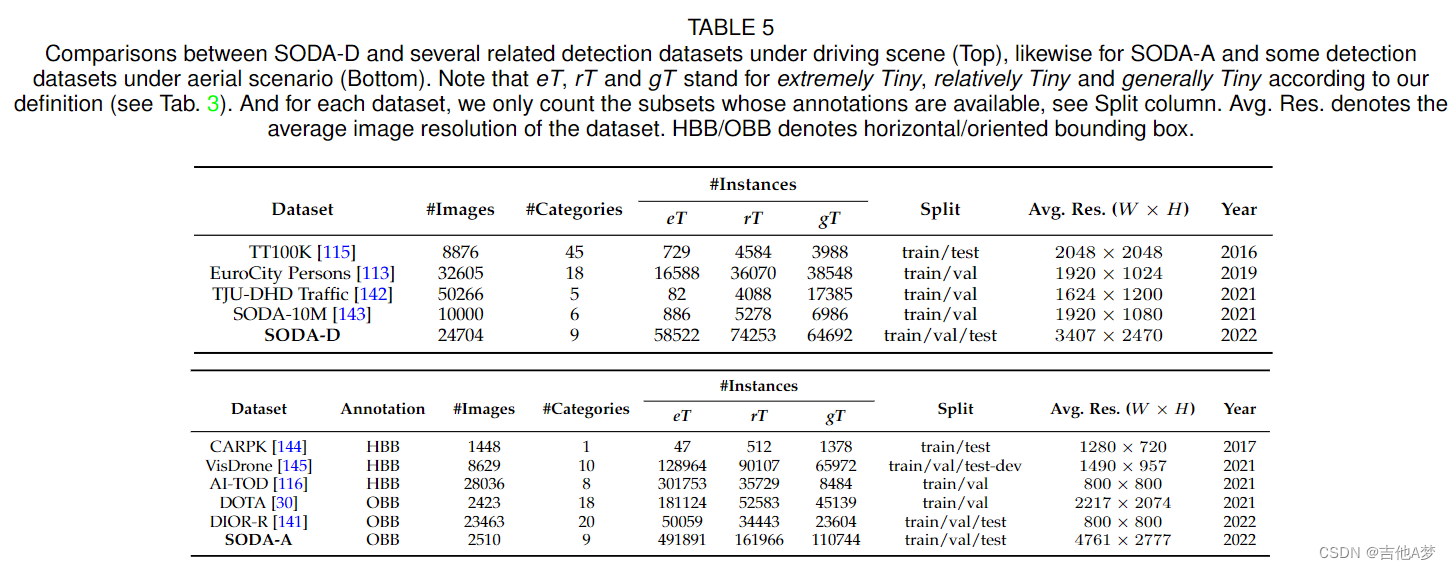



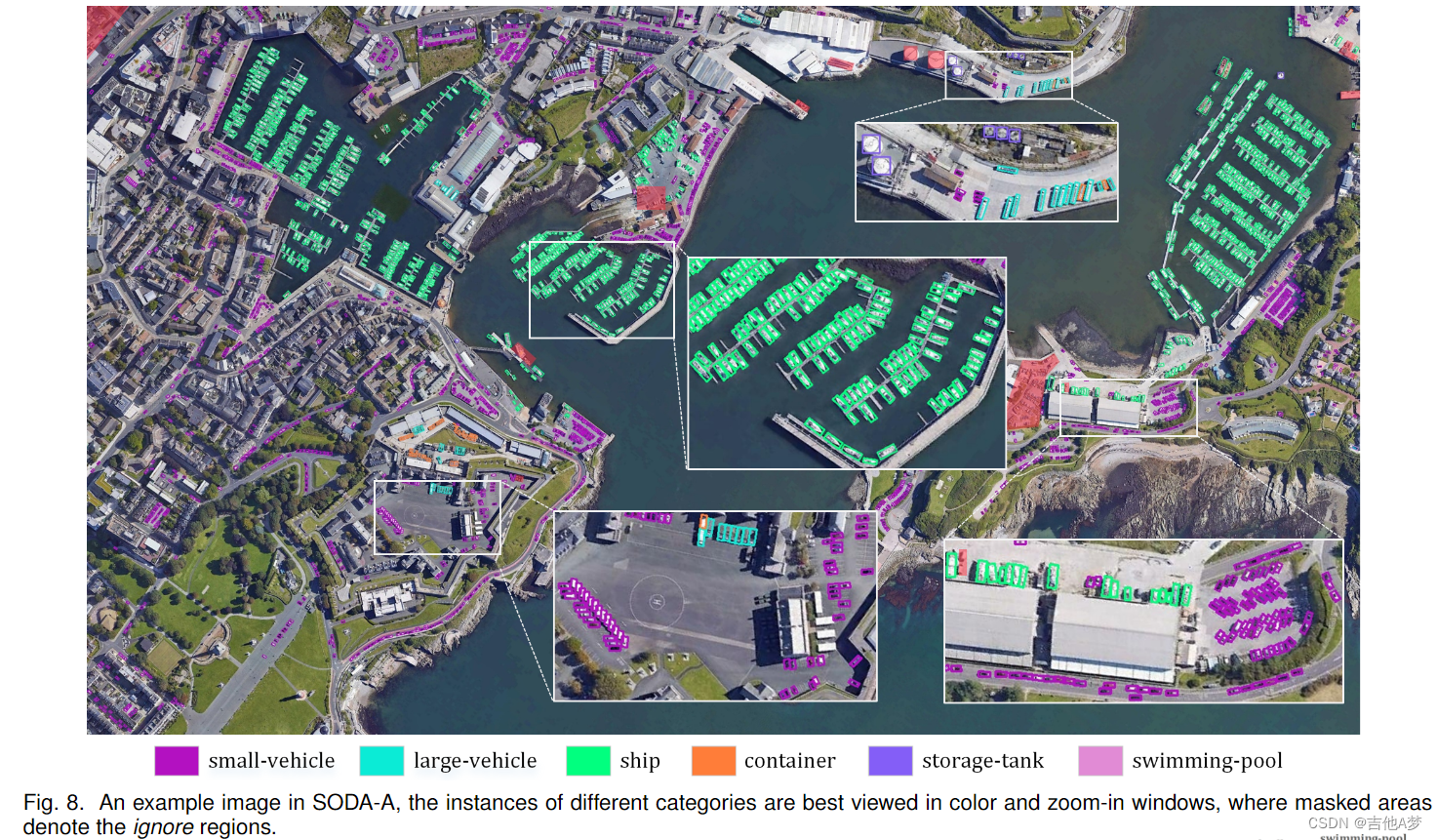


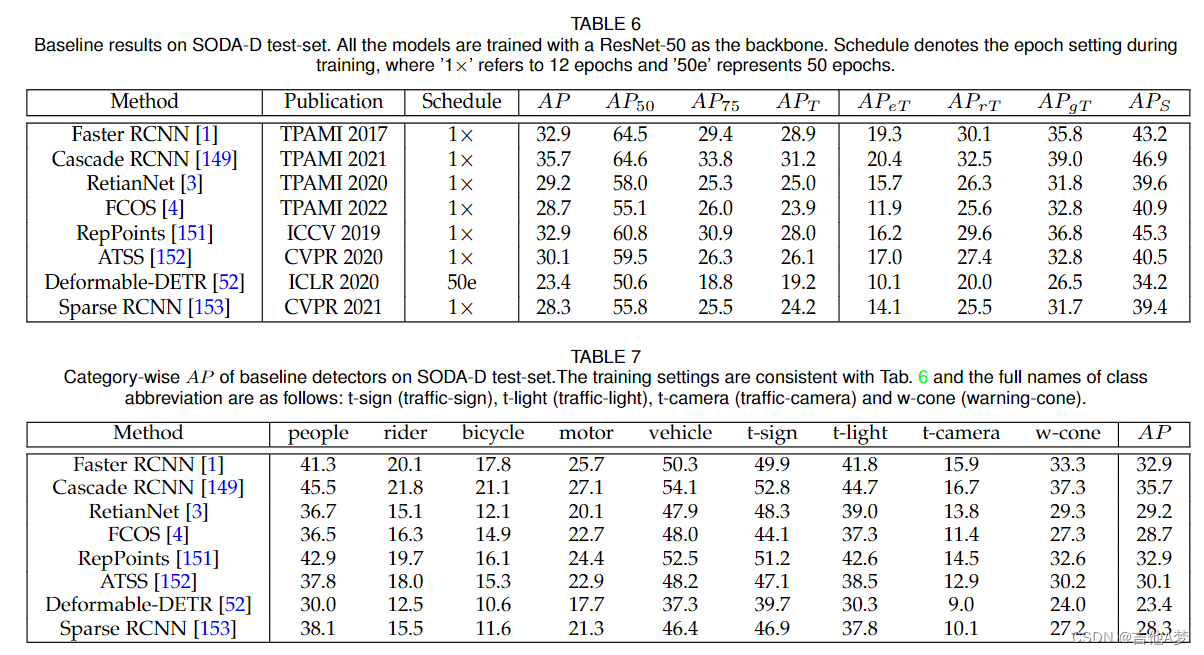
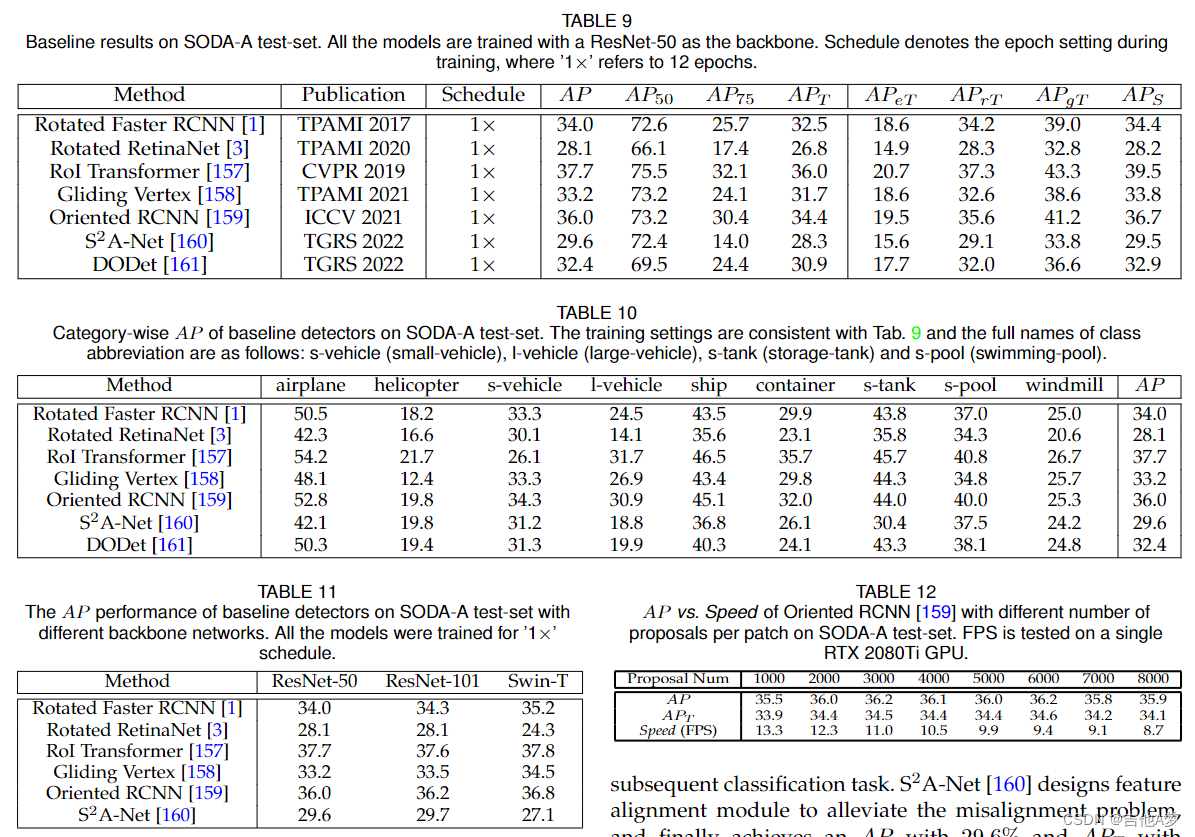
5、实验



相关文章
- Text to image论文精读 MirrorGAN: Learning Text-to-image Generation by Redescription(通过重新描述学习从文本到图像的生成)
- 带你读论文丨基于视觉匹配的自适应文本识别
- 跟我读论文丨ACL2021 NER 模块化交互网络用于命名实体识别
- 【论文笔记】提高超高分辨率图像的语义分割准确性的两种方法:MagNet(CVPR2021)与FCtL(ICCV2021)
- 【论文笔记】Semantic-Aware Domain Generalized Segmentation
- 【论文笔记】Understanding Long Programming Languages with Structure-Aware Sparse Attention
- 【论文笔记】ObjectBox: From Centers to Boxes for Anchor-Free Object Detection
- 【论文笔记】Urban change detection for multispectral earth observation using convolution neural network
- 【论文笔记】Masked Autoencoders Are Scalable Vision Learners
- [论文笔记] RFLA 阅读笔记
- [论文笔记] WoodScape 论文笔记
- [论文笔记] Temporal RoI Align 阅读笔记
- [论文笔记] 大型车牌检测数据集CCPD 阅读笔记
- [论文笔记] ASFD 阅读笔记
- MathType 7试用版写论文科研必备神器
- 动漫网站的设计与实现(源码+论文)_kaic
- 电影推荐系统的设计与实现(论文+源码)_kaic
- 1.特定领域知识图谱知识融合方案(实体对齐、实体链接)论文合集
- 【论文&模型学习】从自然语言监督中学习可迁移视觉 CLIP(Learning Transferable Visual Models From Natural Language Supervision)
- 级联残差特征融合超分辨率重建(论文实验)
- 如何写SCI论文
- 如何看论文信息(期刊会议,引用数,期刊等级,会议层次)
- 目标检测——deformable detr论文解读【DEFORMABLE DETR: DEFORMABLE TRANSFORMERS FOR END-TO-END OBJECT DETECTION】
- (一)One-Shot Learning for Semantic Segmentation论文阅读笔记
- 计算机视觉系列-论文学习 INTERN: A New Learning Paradigm Towards General Vision
- 我是怎样阅读技术论文的
- 【重磅】Hinton大神Capsule论文首次公布,深度学习基石CNN或被取代
- Latex 论文elsevier,手把手如何用Latex写论文