
[Paddle Detection]基于PP-PicoDet行车检测(完成安卓端部署)
基于PP-PicoDet行车检测(完成安卓端部署)_哔哩哔哩_bilibili
一、项目简介
项目背景:
基于视觉深度学习的自动驾驶场景,旨在对车载摄像头采集的视频数据进行道路场景解析(行车检测),为自动驾驶提供一种解决思路。该项目使用bdd100k_car数据集训练,并完成了安卓部署。
项目意义:
现如今,汽车在日益普及人们的生活,再给人们带来极大便利的同时也造成了拥堵的交通更为频发的交通事故。通过行车检测不仅能够更好的帮助司机检查路况,并且还能够更好的规化当前的路程管理,减轻道路的拥堵情况。 在车辆驾驶中主要考验的是司机如何应对其他行驶车辆的可能行为,这种预判断直接影响司机本人的驾驶决策,特别是在多车道环境或者交通灯变灯的情况下,司机的预测决定了下一秒行车的安全。因此,过渡到无人驾驶系统中,决策模块如何根据周围车辆的行驶状况决策下一秒的行驶行为显得至关重要。 利用PP-PicoDet在大规模车辆数据集 BDD100k上进行了60个epoch 的预训练,并导出了静态模型和ONNX模型实现高效推理。在静态图模型的基础上,利用Paddlelite进行安卓部署,使用官方提供的安卓部署demo 的develop分支实现了移动端的实时检测。
二、数据集介绍
官方数据集地址:BDD100K 自动驾驶数据集
视频数据: 超过1,100小时的100000个高清视频序列在一天中许多不同的时间,天气条件,和驾驶场景驾驶经验。视频序列还包括GPS位置、IMU数据和时间戳。
道路目标检测: 2D边框框注释了100,000张图片,用于公交、交通灯、交通标志、人、自行车、卡车、摩托车、小汽车、火车和骑手。
实例分割: 超过10,000张具有像素级和丰富实例级注释的不同图像。
引擎区域: 从10万张图片中学习复杂的可驾驶决策。
车道标记: 10万张图片上多类型的车道标注,用于引导驾驶。

三、技术路线
1、PaddleDetection简介:
PaddleDetection 为基于飞桨的端到端目标检测套件,内置30+模型算法及300+预训练模型,覆盖目标检测、实例分割、跟踪、关键点检测等方向,其中包括服务器端和移动端高精度、轻量化产业级 SOTA 模型、冠军方案和学术前沿算法,并提供即插即用的垂类场景预训练模型,覆盖人、车等20+场景,提供配置化的网络模块组件、十余种数据增强策略和损失函数等高阶优化支持和多种部署方案,在打通数据处理、模型开发、训练、压缩、部署全流程的基础上,提供丰富的案例及教程,加速算法产业落地应用。

PaddleDetection模块式地提供YOLOE,EfficientDet等10余种目标检测算法、ResNet-vd,MobileNetV3等10余种backbone,以及sync batch norm, IoU Loss、可变性卷积等多个扩展模块,这些模块可以定制化地自由组合,灵活配置;同时预置提供100余种训练好的检测模型。
2、模型库链接:
PaddleDetection代码GitHub链接: https://github.com/PaddlePaddle/PaddleDetection
PaddleDetection代码Gitee链接: https://gitee.com/paddlepaddle/PaddleDetection
PaddleDetection文档链接: https://paddledetection.readthedocs.io/
四、轻量检测器PP-PicoDet
PP-PicoDet模型有如下特点:
- 🌟 更高的mAP: 第一个在1M参数量之内mAP(0.5:0.95)超越30+(输入416像素时)。
- 🚀 更快的预测速度: 网络预测在ARM CPU下可达150FPS。
- 😊 部署友好: 支持PaddleLite/MNN/NCNN/OpenVINO等预测库,支持转出ONNX,提供了C++/Python/Android的demo。
- 😍 先进的算法: 我们在现有SOTA算法中进行了创新, 包括:ESNet, CSP-PAN, SimOTA等等。
- 技术报告地址:https://arxiv.org/abs/2111.00902

五、环境配置
- 首先更新pip
pip install --upgrade pip
# 克隆paddledetection仓库
# gitee 国内下载比较快
!git clone https://gitee.com/paddlepaddle/PaddleDetection.git
# github
# !git clone https://github.com/PaddlePaddle/PaddleDetection.git
#运行结果:
#Cloning into 'PaddleDetection'...
# remote: Enumerating objects: 254651, done.
# remote: Counting objects: 100% (235121/235121), done.
# remote: Compressing objects: 100% (42714/42714), done.
# remote: Total 254651 (delta 193702), reused 232759 (delta 191618), pack-reused 19530
# Receiving objects: 100% (254651/254651), 411.85 MiB | 14.40 MiB/s, done.
# Resolving deltas: 100% (208251/208251), done.
# Checking connectivity... done.# 导入package
!pip install -r ~/PaddleDetection/requirements.txt
# 继续安装依赖库
!python3 ~/PaddleDetection/setup.py install- 本项目使用平台提供的数据集🔗
# 解压数据集
# 注意数据集压缩包的位置
!unzip -oq /home/aistudio/data/data102832/bdd100kcar.zip -d /home/aistudio/PaddleDetection/dataset/bd100k- 将数据集中的json文件转换为xml文件,需要用到第三方库dicttoxml,请先在终端执行以下命令:
pip install dicttoxml# 生成train_list.txt和val_list.txt
import os
os.chdir('/home/aistudio/PaddleDetection/dataset/bd100k/')
base_dir = 'images/100k/'
label_dir = 'labels/voc_labels/'
with open('train_list.txt', 'w') as train:
for filename in os.listdir(base_dir + 'train'):
train.write(base_dir + 'train/' + filename + " " + label_dir + 'train/' + filename.split('.')[0] + '.xml\n')
with open('val_list.txt', 'w') as val:
for filename in os.listdir(base_dir + 'val'):
val.write(base_dir + 'val/' + filename + " " + label_dir + 'val/' + filename.split('.')[0] + '.xml\n')
# 查看一下数据集数量
import os
os.chdir('/home/aistudio/PaddleDetection/dataset/bd100k/')
base_dir = 'images/100k/'
imgs = os.listdir(base_dir + 'train')
print('训练集图片总量: {}'.format(len(imgs)))
imgs = os.listdir(base_dir + 'val')
print('验证集图片总量: {}'.format(len(imgs)))
imgs = os.listdir(base_dir + 'test')
print('测试集图片总量: {}'.format(len(imgs)))
# 结果:
# 训练集图片总量: 68943
# 验证集图片总量: 9882
# 测试集图片总量: 20000在PaddleDetection/dataset/bd100k中创建一个label_list.txt文件,用于存放标签,并添加标签

七、数据预处理
sample_transforms:
- Decode: {}
- RandomCrop: {}
- RandomFlip: {prob: 0.5}
- RandomDistort: {}
batch_transforms:
- BatchRandomResize: {target_size: [576, 608, 640, 672, 704], random_size: True, random_interp: True, keep_ratio: False}
- NormalizeImage: {is_scale: true, mean: [0.485,0.456,0.406], std: [0.229, 0.224,0.225]}
- Permute: {}
- PadGT: {}
- RandomCrop:随机裁剪图像。
- RandomFlip:实现图像的随机翻转(翻转概率为0.5)。
- RandomDistort:以一定的概率对图像进行随机像素内容变换,可包括亮度、对比度、饱和度、色相角度、通道顺序的调整,模型训练时的数据增强操作。
- BatchRandomResize:对一个批次中的图片随机指定尺寸,范围是[576, 608, 640, 672, 704],插值方式为随机插值,进行多尺度训练。
- Normalize:图像归一化,均值默认为[0.485, 0.456, 0.406]。长度应与图像通道数量相同。标准差默认为[0.229, 0.224, 0.225]。长度应与图像通道数量相同。
八、模型训练
- 本项目使用的配置文件是
~/PaddleDetection/configs/picodet/picodet_xs_416_coco_lcnet.yml
- 打开此文件,修改配置文件如下:
_BASE_: [
'../datasets/voc.yml',
'../runtime.yml',
'_base_/picodet_v2.yml',
'_base_/optimizer_300e.yml',
'_base_/picodet_416_reader.yml',
]
....
epoch: 60- 对configs/datasets/voc.yml文件进行修改如下:
- (num_classes为标签数量加背景数量)
metric: VOC
map_type: 11point
num_classes: 2
TrainDataset:
!VOCDataSet
dataset_dir: dataset/bd100k
anno_path: train_list.txt
label_list: label_list.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
EvalDataset:
!VOCDataSet
dataset_dir: dataset/bd100k
anno_path: val_list.txt
label_list: label_list.txt
data_fields: ['image', 'gt_bbox', 'gt_class', 'difficult']
TestDataset:
!ImageFolder
anno_path: dataset/bd100k/label_list.txt- 对configs/picodet/base/optimizer_300e.yml文件进行修改如下:
- (本次设置60个epoch,学习率lr=0.05)
epoch: 60
LearningRate:
base_lr: 0.05
schedulers:
- !CosineDecay
max_epochs: 300
- !LinearWarmup
start_factor: 0.1
steps: 300
OptimizerBuilder:
optimizer:
momentum: 0.9
type: Momentum
regularizer:
factor: 0.00004
type: L2- 训练阶段采用的学习率衰减策略为余弦衰减,最大迭代轮次为200,由于该数据集只进行二分类,即汽车和背景类,观察vdl模型基本收敛即可停止训练。
- 至此,文件配置完成,就开始炼丹咯
# 开启训练
%cd ~/PaddleDetection
!python3 tools/train.py -c configs/picodet/picodet_xs_416_coco_lcnet.yml --eval \
--use_vdl True \
--vdl_log_dir output/vdl_picodet_xs/ \
-o use_gpu=true九、模型评估
# 评估 默认使用训练过程中保存的best_model
# -c 参数表示指定使用哪个配置文件
# -o 参数表示指定配置文件中的全局变量(覆盖配置文件中的设置),需使用单卡评估
%cd ~/PaddleDetection
!python tools/eval.py -c configs/picodet/picodet_xs_416_coco_lcnet.yml \
-o weights=output/picodet_xs_416_coco_lcnet/best_model.pdparams \
-o use_gpu=true十、模型测试
动态图测试
# 测试 -c 参数表示指定使用哪个配置文件
# -o 参数表示指定配置文件中的全局变量(覆盖配置文件中的设置)
# --infer_dir 参数指定预测图像所在文件夹路径
# --infer_img 参数指定预测图像路径
# --output_dir 输出结果文件夹路径
# 预测结束后会在output文件夹中生成一张画有预测结果的同名图像
%cd ~/PaddleDetection
!python tools/infer.py -c configs/picodet/picodet_xs_416_coco_lcnet.yml \
--infer_dir=dataset/bd100k/images/100k/test \
--output_dir=dataset/result \
-o use_gpu=true \
-o weights=output/picodet_xs_416_coco_lcnet/best_model.pdparams测试集效果

静态图测试
# 将训练好的模型导出为静态图
%cd ~/PaddleDetection
!python tools/export_model.py -c configs/picodet/picodet_xs_416_coco_lcnet.yml \
-o weights=output/picodet_xs_416_coco_lcnet/best_model.pdparams \
--output_dir=inference导出文件结构如下
inference/picodet_xs_416_coco_lcnet
|--infer_cfg.yml
|--model.pdmodel
|--model.pdiparams
|--model.pdiparams.infoPicodet静态图性能测试 在这里,随机从20000张测试集中选择1000张图片进行性能测试,测试环境包括以下三种配置:
- CPU+4 Thread
- CPU+MKL+4 Thread
- GPU
# 随机采样
import shutil
import os
import numpy as np
data_dir = "dataset/bd100k/images/100k/test/"
pathlist= os.listdir(data_dir)
t = np.random.choice(pathlist, size=1000, replace=False)
for path in t:
src = data_dir + path
dst = "dataset/static_test/" + path
shutil.copy(src, dst)# CPU测试推理模型(不开启mkldnn加速)
!python deploy/python/infer.py --model_dir=inference/picodet_xs_416_coco_lcnet \
--image_dir dataset/static_test \
--output_dir dataset/static_result \
--device=CPU --batch_size=1 \
--cpu_threads=4# CPU测试推理模型(开启mkldnn加速)
!python deploy/python/infer.py --model_dir=inference/picodet_xs_416_coco_lcnet \
--image_dir dataset/static_test \
--output_dir dataset/static_result \
--device=CPU --batch_size=1 \
--cpu_threads=4 \
--enable_mkldnn=True# GPU测试推理模型
!python deploy/python/infer.py --model_dir=inference/picodet_xs_416_coco_lcnet \
--image_dir dataset/static_test \
--output_dir dataset/static_result \
--device=GPU --batch_size=1十一、模型安卓端部署
官方使用指南(注意:这不是下载链接,链接连接后边会提到)
1.Paddle Lite安装
# 首先安装PaddleLite
!pip install paddlelite==2.9.02.Paddle Lite模型转换
将Paddle模型转换为Paddle Lite模型:使用Paddle Lite opt工具将Paddle模型转换为Paddle Lite模型。执行命令如下
(注意如果跳过 将训练好的模型导出为静态图导出骤,'./inference/picodet_xs_416_coco_lcnet'将不存在,执行模型导出为静态图导出步骤后再执行此步骤)
'''
--model_dir: 指定模型文件夹位置
--valid_targets: 指定模型可执行的 backend,默认为arm
--optimize_out: 优化模型的输出路径
'''
%cd ~/PaddleDetection/
!paddle_lite_opt --model_dir=./inference/picodet_xs_416_coco_lcnet \
--valid_targets=arm \
--optimize_out=lite_model!ls -l |grep lite_model
# 结果:
# -rw-r--r-- 1 aistudio users 4476918 Mar 12 21:51 lite_model.nb可见模型已转换完毕,文件名为 lite_model.nb
3.Android Studio配置
3.1下载Android SDK 选择与你运行设备相同的版本。
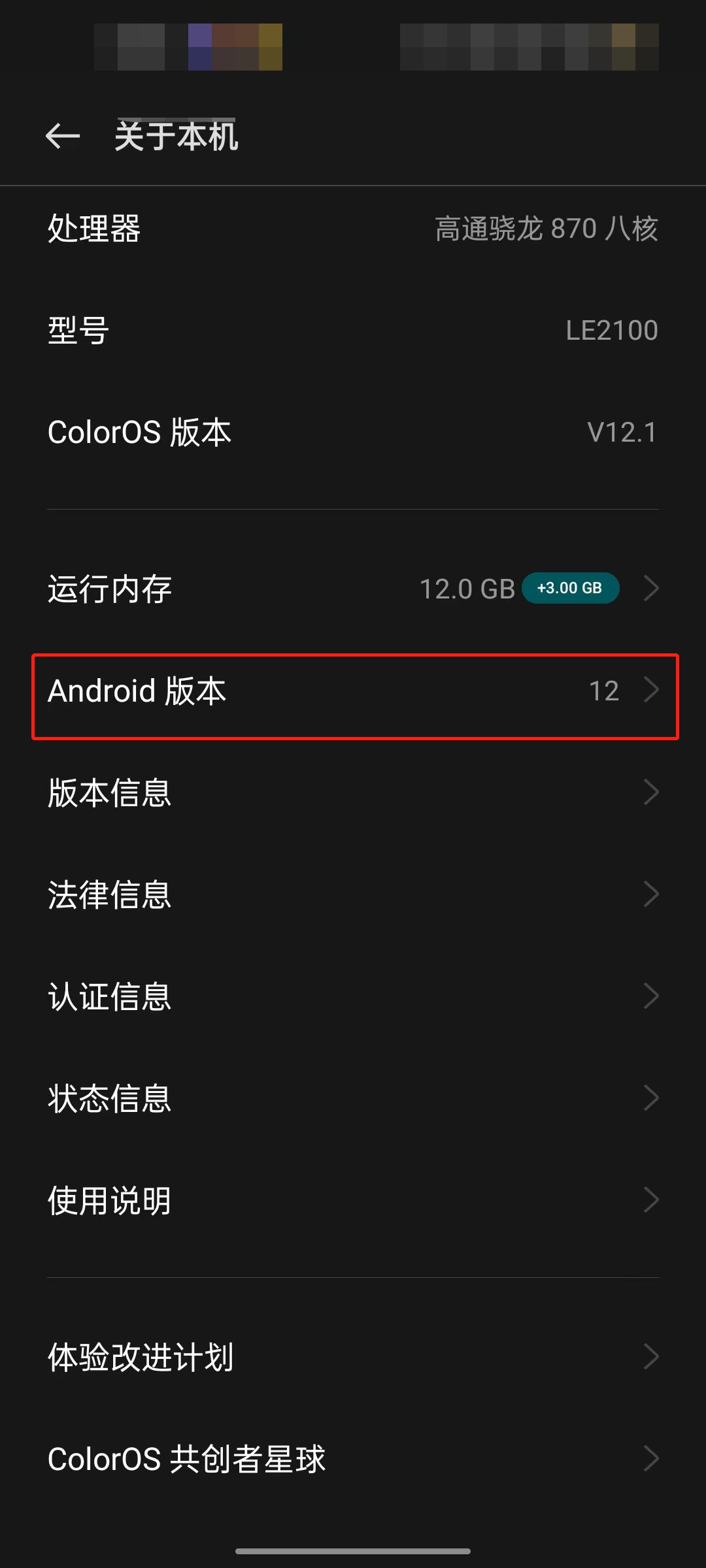
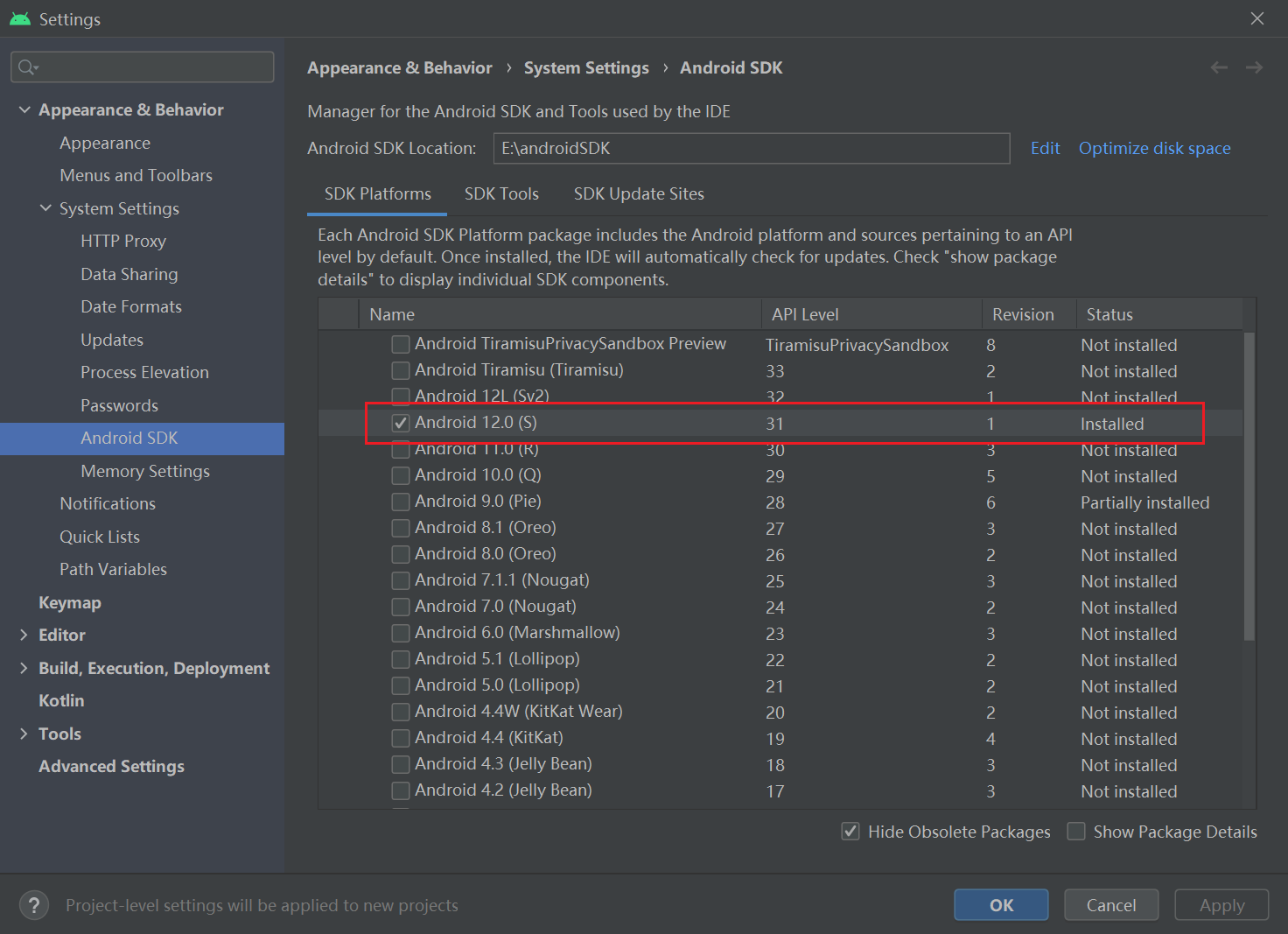
3.2下载 NDK和CMake 打开工具栏中Tool->SDK Manager,然后根据 图3步骤安装NDK等工具,下载NDK 21.4.7075529 版本和CMake 3.10.2.4988404版本。


3.3 NDK/SDK配置 打开工具栏中File->Project Structure

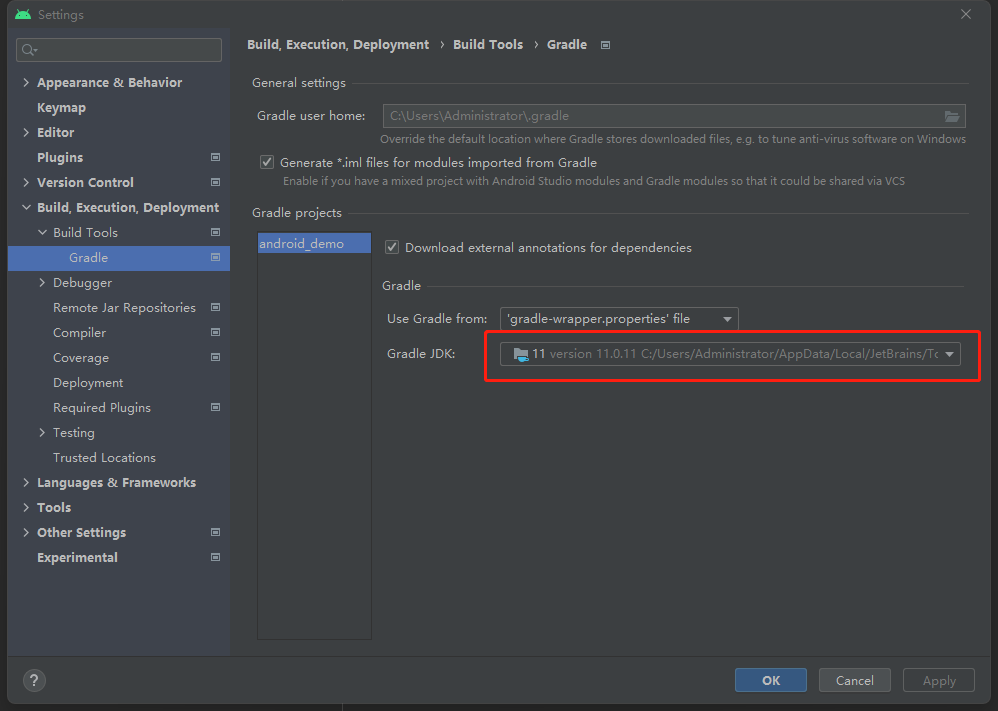
3.4 JDK配置 打开工具栏中File->Settings
4.下载Android项目
-
解压出官方demo
-
Android Studio打开Paddle-Lite-Demo/object_detection/android/app/cxx/picodet_detection_demo 目录
-
手机连接电脑,打开 USB 调试和文件传输模式,并在 Android Studio 上连接自己的手机设备(手机需要开启允许从 USB 安装软件权限)
-
注意;一定要检查时候与刚刚Android Studio配置的是否相同 此时可一运行官方demo

-
运行后手机会提示安装名叫SSD Detection的APP,安装后允许权限。
5.项目配置
5.1 首先看一下需要用的.nb文件结构

发现输入为416X416
5.2 替换模型文件及标签
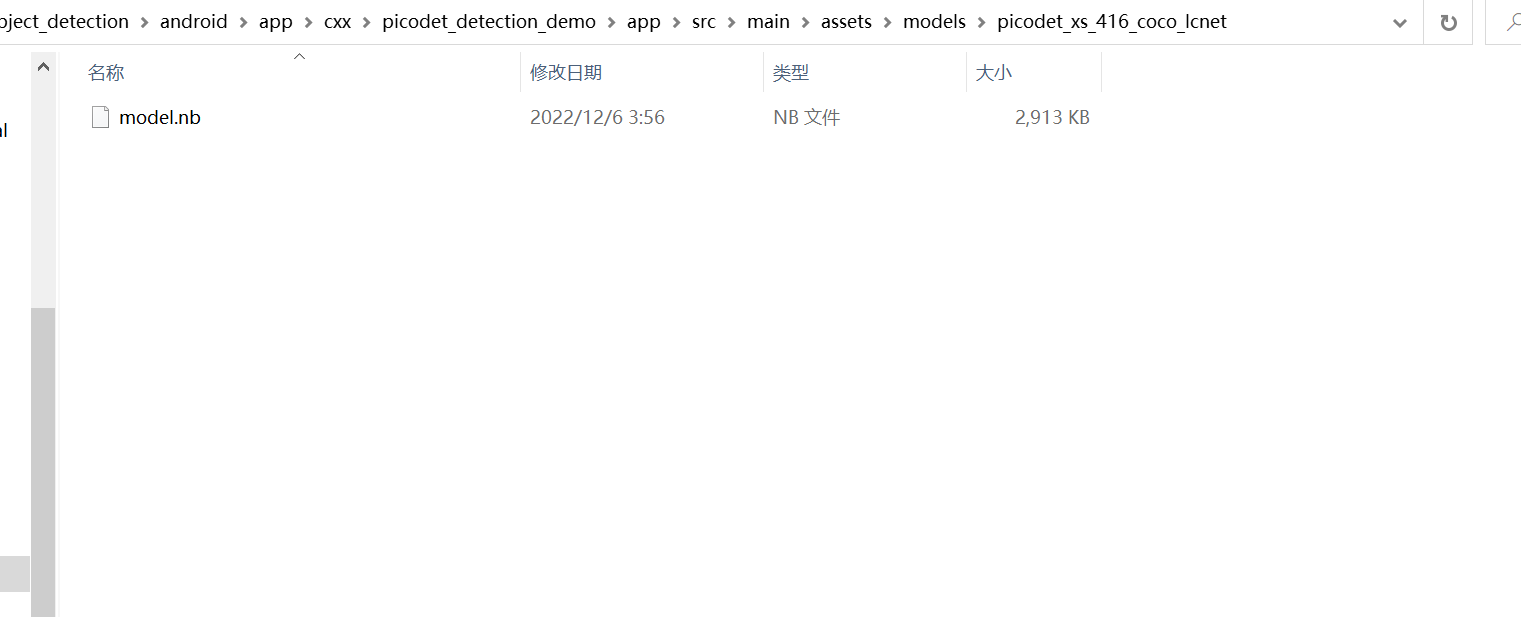
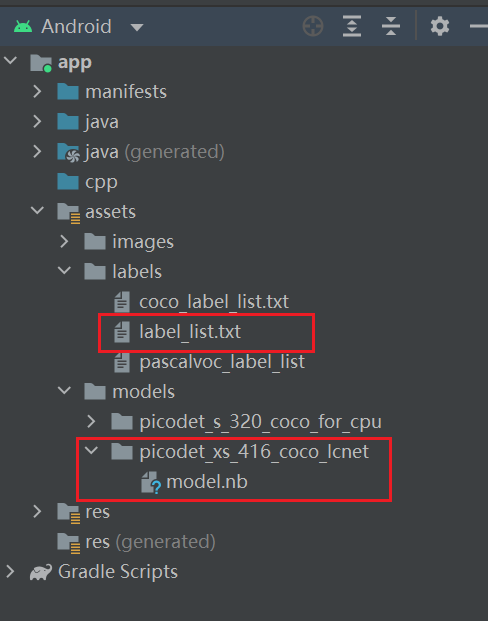
在assets/model文件夹下新建一个picodet_xs_416_coco_lcnet文件夹并把刚才转换生成的nb文件复制在里边,重命名nb文件为model.nb。如图
在assets/labels文件夹下复制标签文件(训练模型前创建的)。如图
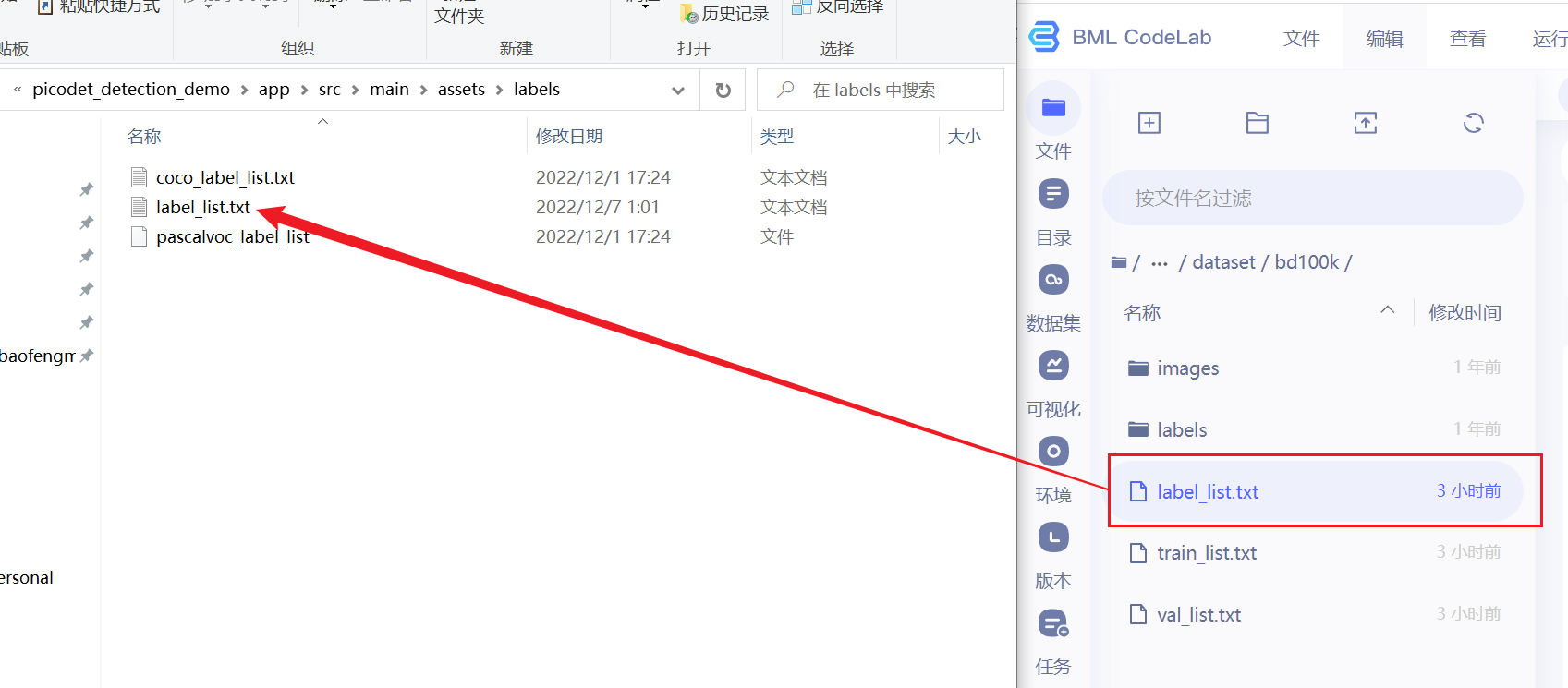
结果
5.4 修改strings.xml文件
修改
<string name="MODEL_DIR_DEFAULT">
<string name="LABEL_PATH_DEFAULT">
<string name="INPUT_WIDTH_DEFAULT">416</string>
<string name="INPUT_HEIGHT_DEFAULT">416</string>【"MODEL_DIR_DEFAULT"】为模型路径,修改为刚刚直接建的模型文件夹。
【"LABEL_PATH_DEFAULT"】为标签文件,修改为刚复制的lable_list.text
【"INPUT_WIDTH_DEFAULT"】 【"INPUT_HEIGHT_DEFAULT"】 分别为输入图片的宽高,需要与nb文件模型对应,刚已经查看为416X416
6.编译运行


项目总结
-
利用PP-PicoDet在大规模车辆数据集BDD100k上进行了60个epoch的预训练,并导出了静态模型实现高效推理。
-
在静态图模型的基础上,利用Paddlelite进行安卓部署,使用官方提供的安卓部署demo的develop分支实现了移动端的实时检测。
-
后续完成基于DeepLabv3p实现车道线分割
相关文章
- 【linux系统版本Centos7】基于nonebot与go-cqhttp的机器人云端部署
- Linux系统:自然语言处理(NLP)环境搭建【基于智能文本分类系统安装部署】
- Pytorch部署方案(一):基于TensorRT(一个C++库)【最成熟&最优化】【①Pytorch->ONNX->TensorRT;②Pytorch->Caffe->TensorRT】
- 基于OpenResty部署nginx以及nginx+lua开发hello world课程笔记整理
- 005.基于docker部署etcd集群部署
- 基于 Kubernetes 部署 Zookeeper,太有意思了!
- D.8零样本文本分类应用:基于UTC的医疗意图多分类,打通数据标注-模型训练-模型调优-预测部署全流程。
- 容器技术教程:如何将Docker应用持续部署至Kubernetes当中
- OpenEuler2203 基于容器和本地文件部署Redis Cluster的过程以及简单性能测试
- 【转】网络加速原理与方法:静态CDN、动态CDN、全站加速、GAAP、AIA、CLB跨地域部署
- 总所有成本计算 部署固态硬盘的必要步骤
- 在Nginx中部署基于IP的虚拟主机
- CentOS7部署fabric
- 十分钟教你部署一个属于自己的chatgpt网站
- Ceph-集群内分布式存储解决方案及基于Docker的部署
- Moving to Docker(三)基于Docker的Rails自动化部署
- tomcat - 部署Web应用
- 来看看基于Kubernetes的Spark部署完全指南