
python爬虫笔记——Scrapy框架(浅学)
一、创建Scrapy爬虫项目
步骤:
- 安装scrapy:在pycharm项目(自己新建的爬虫项目)的终端输入 pip install scrapy
- 创建爬虫项目:同样在终端输入 scrapy startproject meijus(meijus是我的项目名称,可以自定义),通过tree crawler命令可以查看目录结构。
- 通过Scrapy的Spider基础模版建立一个基础的爬虫:在终端通过cd meijus到项目文件里,输入scrapy genspider meiju meijutt.tv自定义一个爬虫类,在spider文件下。(meiju这个自定义文件名尽量别和项目文件名meijus一样,可能无法创建。)
| 文件名 | 描述 |
|---|---|
| scrapy.cfg | 是整个Scrapy项目的配置文件 |
| settings.py | 是上层目录中scrapy.cfg定义的设置文件(决定由谁去处理爬取的内容) |
| init.pyc | 是__init__.py的字节码文件 |
| init.py | 作用就是将它的上级目录变成了一个模块 ,否则,文件夹没有__init__.py不能作为模块导入 |
| items.py | 是定义爬虫最终需要哪些项 (决定爬取哪些项目) |
| pipelines.py | Scrapy爬虫爬取了网页中的内容后,这些内容怎么处理就取决于pipelines.py如何设置 (决定爬取后的内容怎样处理) |
在创建项目中遇到一个问题:在pycharm终端出现报错——无法加载文件\venv\Scripts\activate.ps1,因为在此系统上禁止运行脚本。
解决步骤如下:
- 终端输入
get-executionpolicy,回车,结果为Restricted。 - 在电脑上找到 Windows Powershall 程序,并以管理员的身份运行,在该程序的命令窗口输入set-executionpolicy remotesigned,回车,输入Y,回车。
- pycharm终端写入
get-executionpolicy命令回车,结果为remotesigned。 - 输入scrapy startproject douban回车,没有报错,问题解决。
这样一个基础的爬虫项目就做好了,接下来是对该项目进行完善和拓展。
二、完善自己的程序
注意:以下的代码只是部分截取,你可以理解成截图的形式(每次都全放篇幅较长),如果一份代码第一行有跟之前代码靠后部分是一样的,那就可以拼接起来。
1. 首先在创建的meiju.py文件里调用Seleor库,创建数据解析对象sel。
import scrapy
from scrapy import Selector
from ..items import MeijusItem
class MeijuSpider(scrapy.Spider):
name = 'meiju' # 名字
allowed_domains = ['meijutt.tv'] # 域名
start_urls = ['https://www.meijutt.tv/new100.html'] # 要补充完整
def parse(self, response):
sel = Selector(response)#
movies = sel.xpath('//ul[@class="top-list fn-clear"]/li')2. 打开要爬取的网页,鼠标右键选择检查,效果如下图所示,
找到右侧代码中存储电影信息的列表,图中存着电影信息的列表标签为<li>,鼠标右键点记该标签,在复制里选择你要复制xpath的方式,回到meiju.py里选择解析方式(我用的是xpath)进行解析,
格式为://ul[@class=类名]/所需数据位置的对应标签
结果如步骤1的代码所示。
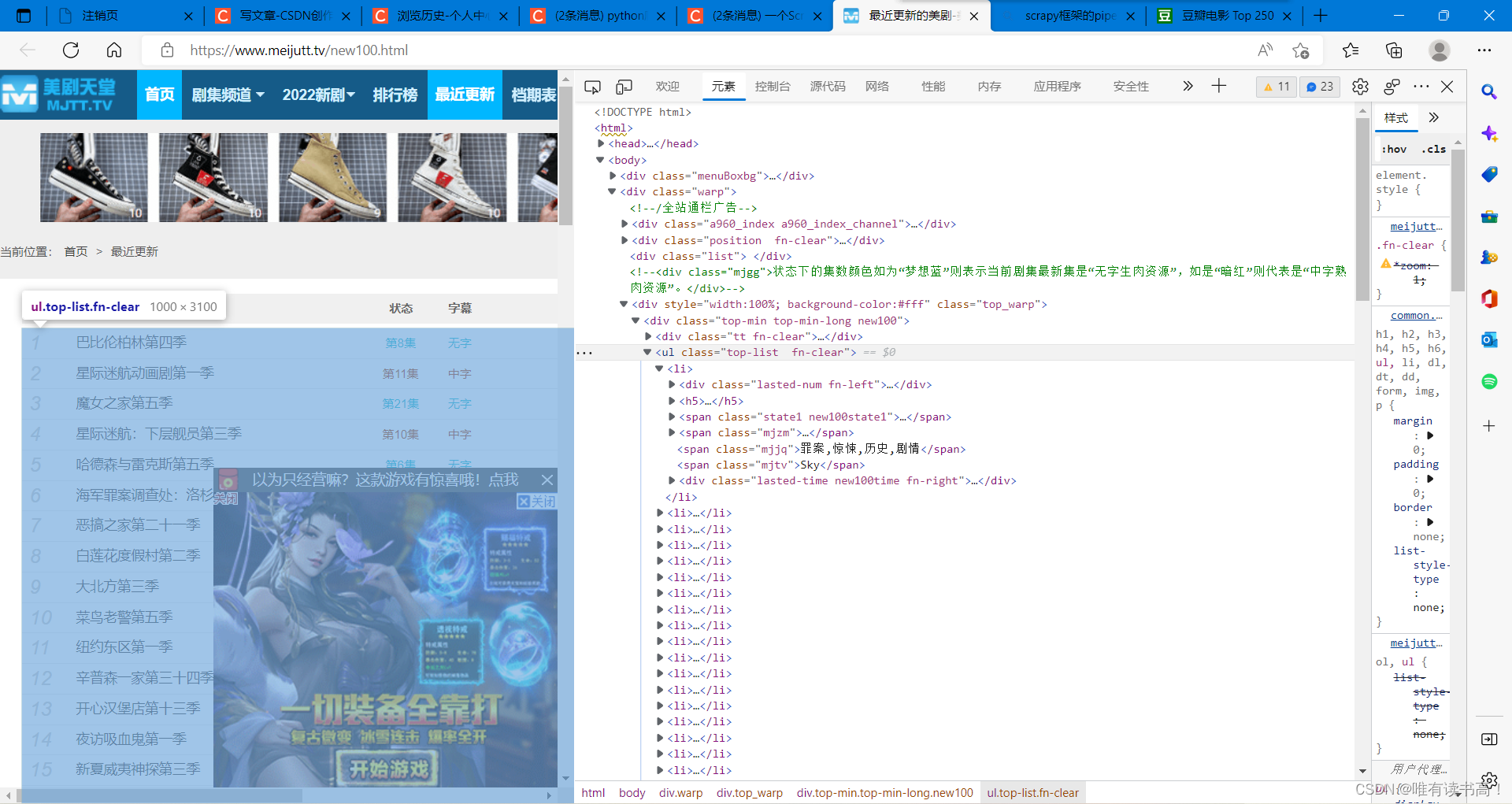
3. 现在我们得到多个电影的信息,接下来需要建立循环对每个电影的信息进行解析,参照步骤2的方法找到电影名的位置查看对应标签,右键复制xpath,
在xpath方法里输入格式:./该标签(<li>)下的一级标签/二级标签/.....等等,
直到目标位置的对应标签,extract()[0]表示抽取里面的第一条数据,不加该函数的话返回的是选择器对象,不是数据。具体如下图所示
movies = sel.xpath('//ul[@class="top-list fn-clear"]/li')
for each_movie in movies:
item = MeijusItem()
item['name'] = each_movie.xpath('./span[3]').extract()[0]
yield item #返回多个数据4. 打开items.py文件,创建要爬取的数据对象,名字可以随便取
class DoubanItem(scrapy.Item): #爬虫获取到的数据组装成item对象
# define the fields for your item here like:
name = scrapy.Field()
5. 回到meiju.py文件创建电影对象,对象里的键值要和itrmd.py文件里刚刚取的名字一样,否则无法匹配。
for each_movie in movies:
item = MeijusItem()
item['name'] = each_movie.xpath('./span[3]').extract()[0]
yield item #返回多个数据6. 打开setting.py文件,进行浏览器伪装,将USER_AGENT的值改为'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23,DOWNLOAD_DELAY为时间延迟,
BOT_NAME = 'meijus'
SPIDER_MODULES = ['meijus.spiders']
NEWSPIDER_MODULE = 'meijus.spiders'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'MSIE (MSIE 6.0; X11; Linux; i686) Opera 7.23'
# Obey robots.txt rules
ROBOTSTXT_OBEY = True
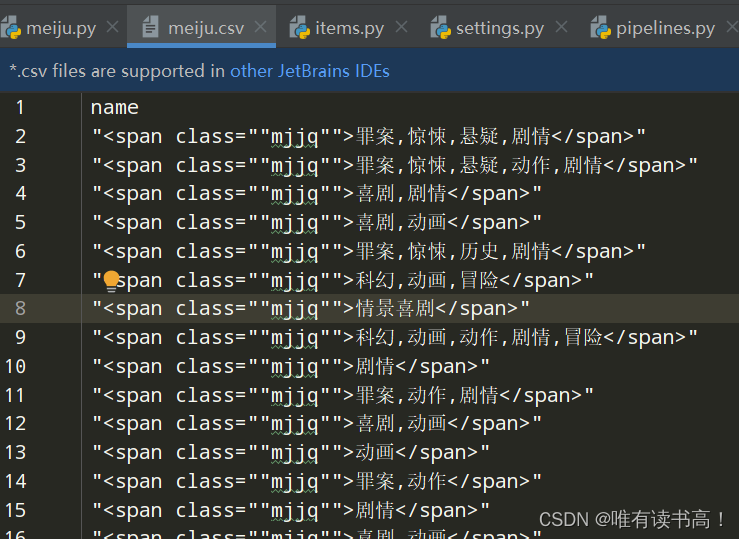
7. 在终端输入:scrapy crawl meiju(爬虫名) -o meiju.csv(存储数据的文件),结果如下,随意弄的,没做数据处理。
三、多网页爬取
如果是网页结构还和之前爬取的网页一样的,可以在meiju.py代码下面加上靠后一段代码,如下图所示,该方法适合用在像豆瓣Top250那种翻页情况。
for each_movie in movies:
item = MeijusItem()
item['name'] = each_movie.xpath('./span[3]').extract()[0]
yield item #返回多个数据
hrefs_list = sel.css( 'div.paginator > a : : attr(href)')
for href in hrefs_list:
url = response.urljoin(href.extract())
Request(url=url)
如果网页与之前的不一样,但是每个新的网页结构又是一样的,最笨的方法是获取它们的网页,再从新做个爬虫爬一遍,大概如下所示
#以本文爬取的网页为例,想进一步爬取每个电影更详细的信息,就将每个电影对应的链接爬下来
def parse(self, response):
sel = Selector(response)#
movies = sel.xpath('//ul[@class="top-list fn-clear"]/li')
href_list=[] #建立获取网页的列表
for each_movie in movies:
item = MeijusItem()
item['name'] = each_movie.xpath('./span[3]').extract()[0]
href = response.urljoin(each_movie.xpath('./h5/a/@href').extract()[0]) # 获取该电影详情信息的网页
href_list.append(href) #将网页信息存进列表
yield item #返回多个数据下面具体怎么获取爬到的href_list里的内容也不难,写个读取就行,实在不会就在之前的代码print出来,复制内容在下面的代码创建成新列表。
#这是新写的爬取详细电影信息网页的爬虫,
#这里介绍一个start_request()方法,可以遍历每个需要去的网页
def start_requests(self):
for i in range(len(href_list)): #遍历每个新的到的网页
yield Request(url=href_list[i]) #通过request请求爬每个网页
def parse(self, response):
#这里要爬取的内容参考之前自己写之后爬更多的东西建议找网课看看,浅学到这也能用一下了,如果以后用的要求更高的再学,现在学了用不上也容易忘。
相关文章
- Python大作业---微博爬虫及简单数据分析
- Python爬虫之多线程下载豆瓣Top250电影图片
- Python爬虫:scrapy从项目创建到部署可视化定时任务运行
- Python爬虫:Scrapy调试运行单个爬虫
- python爬虫:scrapy命令失效,直接运行爬虫
- Python爬虫:scrapy框架请求参数meta、headers、cookies一探究竟
- Python爬虫项目整理
- Python爬虫之三种网页抓取方法性能比较
- dir、help 查看python 库 对应的方法 和使用
- python 爬虫系列09-selenium+拉钩
- PyQt(Python+Qt)学习随笔:containers容器类部件QStackedWidget堆叠窗口属性
- 如何入门 Python 爬虫?
- Python小白爬虫(一) _使用requests模块进行Get请求网页得到页面内容(案例)
- Python:爬虫框架Scrapy的安装与基本使用