
slam学习笔记五----视觉里程计的学习1
一,什么是视觉里程计
SLAM系统分为前端和后端,前端也称为是视觉里程计,主要功能是根据相邻图像的信息粗略的估计出相机的运动,为后端提供较好的初始值。
视觉里程计的算法有两大类特征点法和直接法。特征点法是常用方法,它具有稳定,对光照、动态物体不敏感的优势。视觉里程计的原理就是提取图像的特征点,通过匹配估计两帧之间相机运动和场景结构,实现一个两帧间的视觉里程计。其核心问题就是如何通过图像估计相机的运动。
二,特征点法的原理
从图像中选取比较有代表的点,该点在相机视角发生少量变化后依旧保持不变。这样我们就可以在前后帧的图像中找到这些点,然后估计相机的位姿。
图像的特征点可以简单的理解为图像中比较显著显著的点,如轮廓点,较暗区域中的亮点,较亮区域中的暗点等。
特征点由关键点和描述子两部分组成,关键点指出的是该特征点在图像中的位置,描述子通常是一个向量,按照某种人为设计的方式,描述了该关键点的周围的信息。描述子的设计师是安按照外观相似的特征应该有相似的描述子的原则设计的。常用的方法有SIFT、SURF、ORB等。简单介绍下算法的原理及区别:
2.1 SIFT
参考博文连接为:
SIFT算法原理_youkiaaa的博客-CSDN博客_sift
SIFT即尺度不变特征变换,是用于图像处理领域的一种描述。这种描述具有尺度不变性,可在图像中检测出关键点,是一种局部特征描述子。
SIFT算法的优点:
1、具有较好的稳定性和不变性,能够适应旋转、尺度缩放、亮度的变化,能在一定程度上不受视角变化、仿射变换、噪声的干扰。
2、区分性好,能够在海量特征数据库中进行快速准确的区分信息进行匹配
3、多量性,就算只有单个物体,也能产生大量特征向量
4、高速性,能够快速的进行特征向量匹配
5、可扩展性,能够与其它形式的特征向量进行联合
SIFT算法实质:
在不同的尺度空间上查找关键点,并计算出关键点的方向。
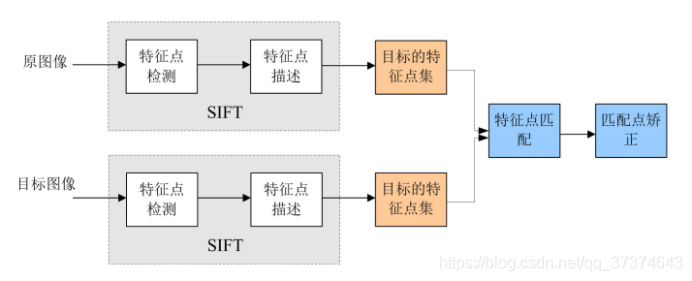
SIFT算法实现特征匹配主要有以下三个流程:
1、提取关键点:关键点是一些十分突出的不会因光照、尺度、旋转等因素而消失的点,比如角点、边缘点、暗区域的亮点以及亮区域的暗点。此步骤是搜索所有尺度空间上的图像位置。通过高斯微分函数来识别潜在的具有尺度和旋转不变的兴趣点。
2、定位关键点并确定特征方向:在每个候选的位置上,通过一个拟合精细的模型来确定位置和尺度。关键点的选择依据于它们的稳定程度。然后基于图像局部的梯度方向,分配给每个关键点位置一个或多个方向。所有后面的对图像数据的操作都相对于关键点的方向、尺度和位置进行变换,从而提供对于这些变换的不变性。
3. 通过各关键点的特征向量,进行两两比较找出相互匹配的若干对特征点,建立景物间的对应关系。
2.2 ORB算法
ORB算法原理解读_yang843061497的博客-CSDN博客_orb
ORB采用FAST(features from accelerated segment test)算法来检测特征点。使用基于BRIEF算法来计算一个特征点的描述子。
2.2.1 FAST特征点提取算法
FAST核心思想就是找出那些卓尔不群的点,即拿一个点跟它周围的点比较,如果它和其中大部分的点都不一样就可以认为它是一个特征点。
FAST具体计算过程:
1. 从图片中选取一个像素点P,下面我们将判断它是否是一个特征点。我们首先把它的密度(即灰度值)设为Ip。
2. 设定一个合适的阙值t :当2个点的灰度值之差的绝对值大于t时,我们认为这2个点不相同。
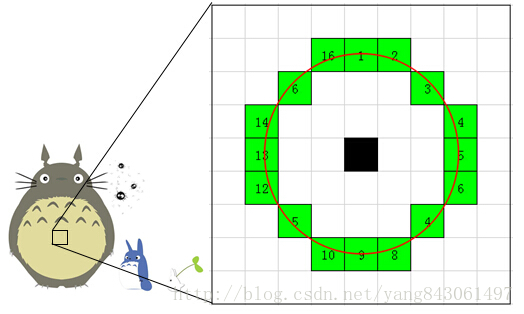
3. 考虑该像素点周围的16个像素。(见下图)
4. 现在如果这16个点中有连续的n个点都和点不同,那么它就是一个角点。 这里n设定为12。
5. 我们现在提出一个高效的测试,来快速排除一大部分非特征点的点。该测试仅仅检查在位置1、9、5和13四个位置的像素(首先检查1和9,看它们是否和点相同。如果是,再检查5和13)。如果是一个角点,那么上述四个像素点中至少有3个应该和点相同。如果都不满足,那么不可能是一个角点。
2.2.2 BRIEF算法特征点的描述
在现实生活中,我们从不同的距离,不同的方向、角度,不同的光照条件下观察一个物体时,物体的大小,形状,明暗都会有所不同。但我们的大脑依然可以判断它是同一件物体。理想的特征描述子应该具备这些性质。即,在大小、方向、明暗不同的图像中,同一特征点应具有足够相似的描述子,称之为描述子的可复现性。
得到特征点后我们需要以某种方式F描述这些特征点的属性。这些属性的输出我们称之为该特征点的描述子(Feature DescritorS).ORB采用BRIEF算法来计算一个特征点的描述子。BRIEF算法的核心思想是在关键点P的周围以一定模式选取N个点对,把这N个点对的比较结果组合起来作为描述子。
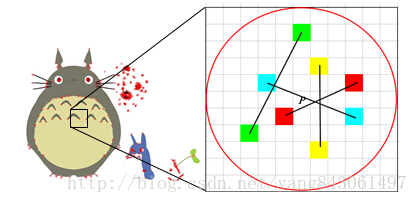
具体来讲分为以下几步。
1.以关键点P为圆心,以d为半径做圆O。
2.在圆O内某一模式选取N个点对。这里为方便说明,N=4,实际应用中N可以取512.
假设当前选取的4个点对如上图所示分别标记为:
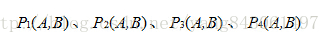
3.定义操作T

4.分别对已选取的点对进行T操作,将得到的结果进行组合。
假如:
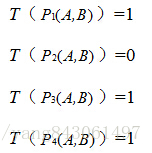
则最终的描述子为:1011
2.2.3 改进的BRIEF描述子
BRIEF算法得到的描述子并不具备以上这些性质。因此我们得想办法改进我们的算法。ORB并没有解决尺度一致性问题,在OpenCV的ORB实现中采用了图像金字塔来改善这方面的性能。ORB主要解决BRIEF描述子不具备旋转不变性的问题。
BRIEF描述子的计算过程:在当前关键点P周围以一定模式选取N个点对,组合这N个点对的T操作的结果就为最终的描述子。当我们选取点对的时候,是以当前关键点为原点,以水平方向为X轴,以垂直方向为Y轴建立坐标系。当图片发生旋转时,坐标系不变,同样的取点模式取出来的点却不一样,计算得到的描述子也不一样,这是不符合我们要求的。因此我们需要重新建立坐标系,使新的坐标系可以跟随图片的旋转而旋转。这样我们以相同的取点模式取出来的点将具有一致性。
打个比方,我有一个印章,上面刻着一些直线。用这个印章在一张图片上盖一个章子,图片上分处直线2头的点将被取出来。印章不变动的情况下,转动下图片,再盖一个章子,但这次取出来的点对就和之前的不一样。为了使2次取出来的点一样,我需要将章子也旋转同一个角度再盖章。(取点模式可以认为是章子上直线的分布情况)
ORB在计算BRIEF描述子时建立的坐标系是以关键点为圆心,以关键点和取点区域的形心的连线为X轴建立2维坐标系。
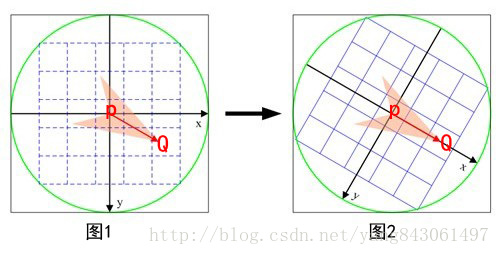
在图1中,P为关键点。圆内为取点区域,每个小格子代表一个像素。现在我们把这块圆心区域看做一块木板,木板上每个点的质量等于其对应的像素值。根据积分学的知识我们可以求出这个密度不均匀木板的质心Q。计算公式如下。其中R为圆的半径。
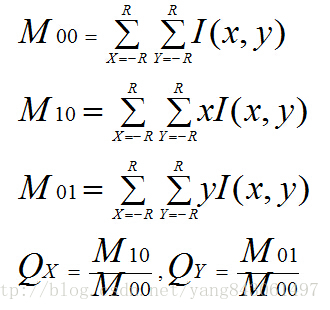
我们知道圆心是固定的而且随着物体的旋转而旋转。当我们以PQ作为坐标轴时(图2),在不同的旋转角度下,我们以同一取点模式取出来的点是一致的。这就解决了旋转一致性的问题。
2.2.4 ORB特征点的匹配原理及优势
ORB算法最大的特点就是计算速度快 。 这首先得益于使用FAST检测特征点,FAST的检测速度正如它的名字一样是出了名的快。再次是使用BRIEF算法计算描述子,该描述子特有的2进制串的表现形式不仅节约了存储空间,而且大大缩短了匹配的时间。
例如特征点A、B的描述子如下。
A:10101011
B:10101010
我们设定一个阈值,比如80%。当A和B的描述子的相似度大于90%时,我们判断A,B是相同的特征点,即这2个点匹配成功。在这个例子中A,B只有最后一位不同,相似度为87.5%,大于80%。则A和B是匹配的。
我们将A和B进行异或操作就可以轻松计算出A和B的相似度。而异或操作可以借组硬件完成,具有很高的效率,加快了匹配的速度。
三、特征匹配
在SLAM技术中,特征匹配解决的问题是数据关联问题,即当前看到的路标和之前看到的路标之间对应的关系。通过图像与图像或者图像与地图之间的描述子进行准确的匹配,可以为后续的姿态估计、优化等操作减轻大量的负担。目前误匹配是SLAM中性能制约的一大瓶颈。部分原因是图像重复纹理较多,特征描述较为相似,所以导致误匹配。常用的匹配方法是暴力匹配(测量描述子的距离,缺点是数据量大的时候速度慢),目前常用的是快速近似最近邻(FLANN)
FLANN是快速最近邻搜索包(Fast_Library_for_Approximate_Nearest_Neighbors)的简称。它是一个对大数据集和高维特征进行最近邻搜索的算法的集合,而且这些算法都已经被优化过了。在面对大数据集是它的效果要好于BFMatcher。已经集成在OPENCV上,目前已经很成熟。
四、例程时间实践(SLAM十四讲中的ch7)
4.1 第七章第一个实践 (特征提取,计算描述子,匹配)
对内容进行编译,会出现以下的错误

解决方法:
修改CMakelists.txt,给使用李代库的添加库连接
target_link_libraries(orb_cv Sophus::Sophus)
cmake_minimum_required(VERSION 2.8)
project(vo1)
set(CMAKE_BUILD_TYPE "Release")
add_definitions("-DENABLE_SSE")
set(CMAKE_CXX_FLAGS "-std=c++11 -O2 ${SSE_FLAGS} -msse4")
list(APPEND CMAKE_MODULE_PATH ${PROJECT_SOURCE_DIR}/cmake)
find_package(OpenCV 3 REQUIRED)
find_package(G2O REQUIRED)
find_package(Sophus REQUIRED)
include_directories(
${OpenCV_INCLUDE_DIRS}
${G2O_INCLUDE_DIRS}
${Sophus_INCLUDE_DIRS}
"/usr/include/eigen3/"
)
add_executable(orb_cv orb_cv.cpp)
target_link_libraries(orb_cv Sophus::Sophus)
target_link_libraries(orb_cv ${OpenCV_LIBS})
add_executable(orb_self orb_self.cpp)
target_link_libraries(orb_self Sophus::Sophus)
target_link_libraries(orb_self ${OpenCV_LIBS})
# add_executable( pose_estimation_2d2d pose_estimation_2d2d.cpp extra.cpp ) # use this if in OpenCV2
add_executable(pose_estimation_2d2d pose_estimation_2d2d.cpp)
target_link_libraries(pose_estimation_2d2d Sophus::Sophus)
target_link_libraries(pose_estimation_2d2d ${OpenCV_LIBS})
# # add_executable( triangulation triangulation.cpp extra.cpp) # use this if in opencv2
add_executable(triangulation triangulation.cpp)
target_link_libraries(triangulation Sophus::Sophus)
target_link_libraries(triangulation ${OpenCV_LIBS})
add_executable(pose_estimation_3d2d pose_estimation_3d2d.cpp)
target_link_libraries(pose_estimation_3d2d
g2o_core g2o_stuff
Sophus::Sophus)
target_link_libraries(pose_estimation_3d2d
g2o_core g2o_stuff
${OpenCV_LIBS})
add_executable(pose_estimation_3d3d pose_estimation_3d3d.cpp)
target_link_libraries(pose_estimation_3d3d
g2o_core g2o_stuff
Sophus::Sophus)
target_link_libraries(pose_estimation_3d3d
g2o_core g2o_stuff
${OpenCV_LIBS})
编译成功后如图所示:

运行第一个例程,返回到文件夹的build的上一级目录:
执行
Build/orb_cv 1.png 2.png




第二个示例,和第一个示例的区别,是特征描述和匹配分别使用了作者自己的优化方法,速度较第一个提升了很多。
五,计算相机运动
提取相机的特征点同时特征描述进行匹配后,得到了两张图像上的匹配结果,接下来要做的事情就是如何根据匹配点,计算相机的运动。
我们的目标是求解相机的运动计算,也就是求解相机的R 和t,这是SLAM的最基本问题之一,常用的有三种方法如下,分别是对极几何、ICP、PnP,对应的是2d2d、2d3d和3d3d三种求解方法。如下图所示:
5.1 对极几何
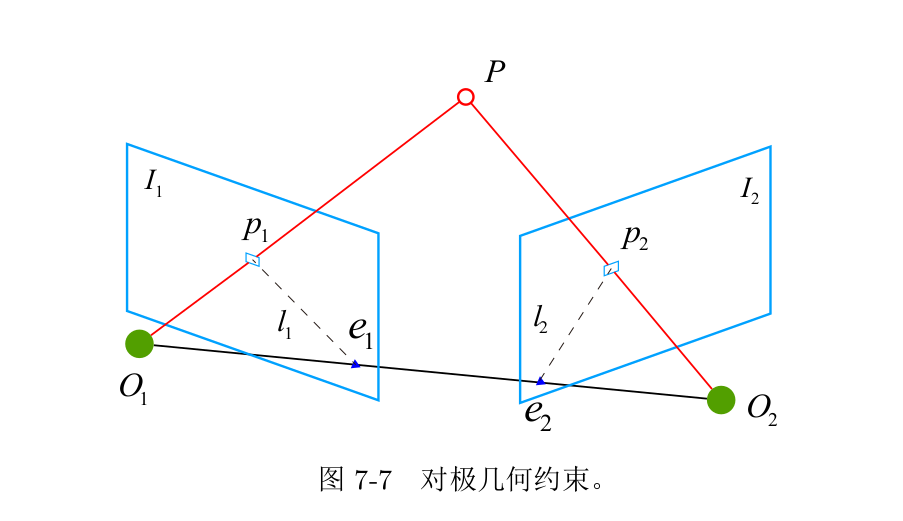
对极几何(Epipolar Geometry)描述的是两幅视图之间的内在射影关系,与外部场景无关,只依赖于摄像机内参数和这两幅视图之间的的相对姿态。
提到对极几何,一定是对二幅图像而言,对极几何实际上是“两幅图像之间的对极几何”,它是图像平面与以基线为轴的平面束的交的几何(这里的基线是指连接摄像机中心的直线),以下图为例:对极几何描述的是左右两幅图像(点x和x’对应的图像)与以CC’为轴的平面束的交的几何!
示例实现:

5.2 3D-2D:PnP算法原理
PnP(Perspective-n-Point)是求解 3D 到 2D 点对运动的方法。它描述了当我们知道n 个 3D 空间点以及它们的投影位置时,如何估计相机所在的位姿。——《视觉SLAM十四讲》
通俗的讲,PnP问题就是在已知世界坐标系下N个空间点的真实坐标以及这些空间点在图像上的投影,如何计算相机所在的位姿。罗嗦一句:已知量是空间点的真实坐标和图像坐标,未知量(求解量)是相机的位姿。
PnP 问题有很多种求解方法,例如用三对点估计位姿的 P3P 、直接线性变换(DLT)、EPnP。此外,还能用非线性优化的方式,构建最小二乘问题并迭代求解,也就是万金油式的 Bundle Adjustment。
3D-2D:PnP算法原理_Andy是个男子名的博客-CSDN博客_pnp算法
示例实现:

5.3 ICP
ICP算法,就是利用点云的匹配关系求解相机的运动变化。实际上点云的匹配应该指的是两个相机坐标系下的点云,那么求解出来的就是两个相机坐标系的变换,也就是相机的运动。所以ICP本质上实际是根据不同坐标系下点多匹配关系,求不同坐标系间的转换矩阵。
示例实现:

相关文章
- 七月工作笔记 7.4 - 7.18
- jQuery 追加元素、拼接元素的方法总结(append、html、insertBefore、before等) 初识document.onkeydown及其兼容性问题 js学习笔记27----键盘事件 JavaScript onkeydown事件入门实例(键盘某个按键被按下)
- SpringCloud学习笔记(3)——Hystrix
- kali 漏洞篇-CSRF 学习笔记
- Hystrix使用笔记
- Machine Learning学习笔记(1)Introduction
- Go分布式爬虫学习笔记(十五)
- 一份拿下了阿里、网易、滴滴等大厂 offer 的学习笔记
- 《模式识别》学习笔记(十九)参数估计,最大似然估计
- Kubernetes---Pod笔记
- Dynamic CRM 2015学习笔记(3)oData 查询方法及GUID值比较
- Drupal创建Omega 4.x 子主题layout笔记
- Oracle数据库学习笔记
- “物联网开发实战”学习笔记-(四)智能音箱制作和语音控制
- 【工作笔记】Git与Github经常使用使用方法
- Odoo owl 学习笔记之九—环境context
- 红帽操作系统——初学笔记(一)
- Redis学习笔记4-Redis配置具体解释
- Linux学习笔记(20)linux exec
- 学习笔记(46):Python实战编程-protocol
- 学习笔记(22):Python网络编程&并发编程-什么是线程
- maven学习笔记四(聚合和继承)
- Spring笔记
- Linux下汇编语言学习笔记71 ---
- Linux下汇编语言学习笔记51 ---
- Arduino学习笔记67
- 《R2CNN:Rotational Region CNN for Orientation Robust Scene Text Detection》论文笔记
- 《Fully Convolutional Networks for Semantic Segmentation》学习笔记
- Python入门学习笔记第四章——操作列表~~~