
使用StreamAPI 断言组合,结合本地缓存做模糊查询(比mysql效率提升近1000倍)
2023-09-27 14:19:45 时间
使用StreamAPI 断言结合本地缓存做模糊查询(比mysql效率提升近1000倍)
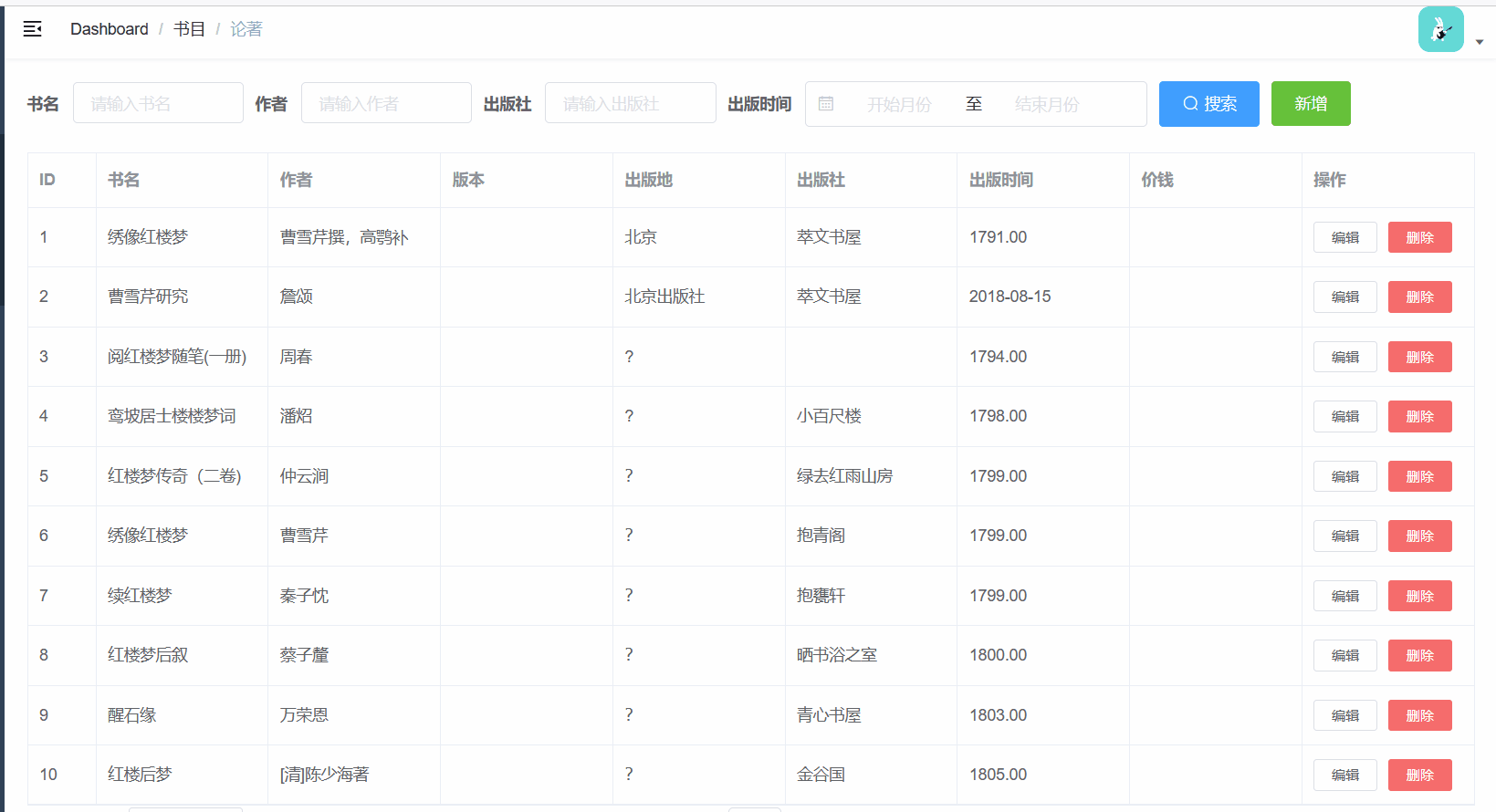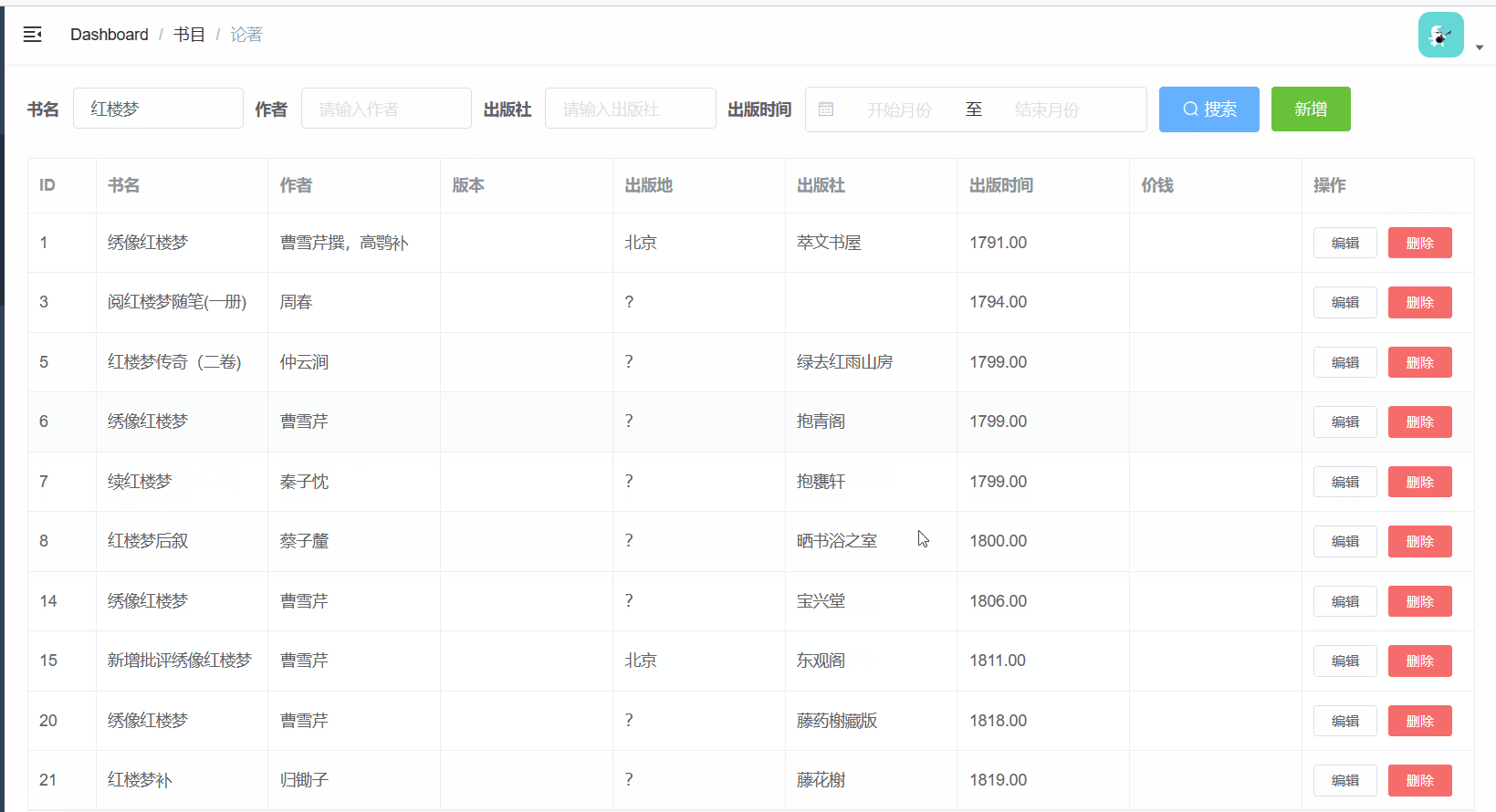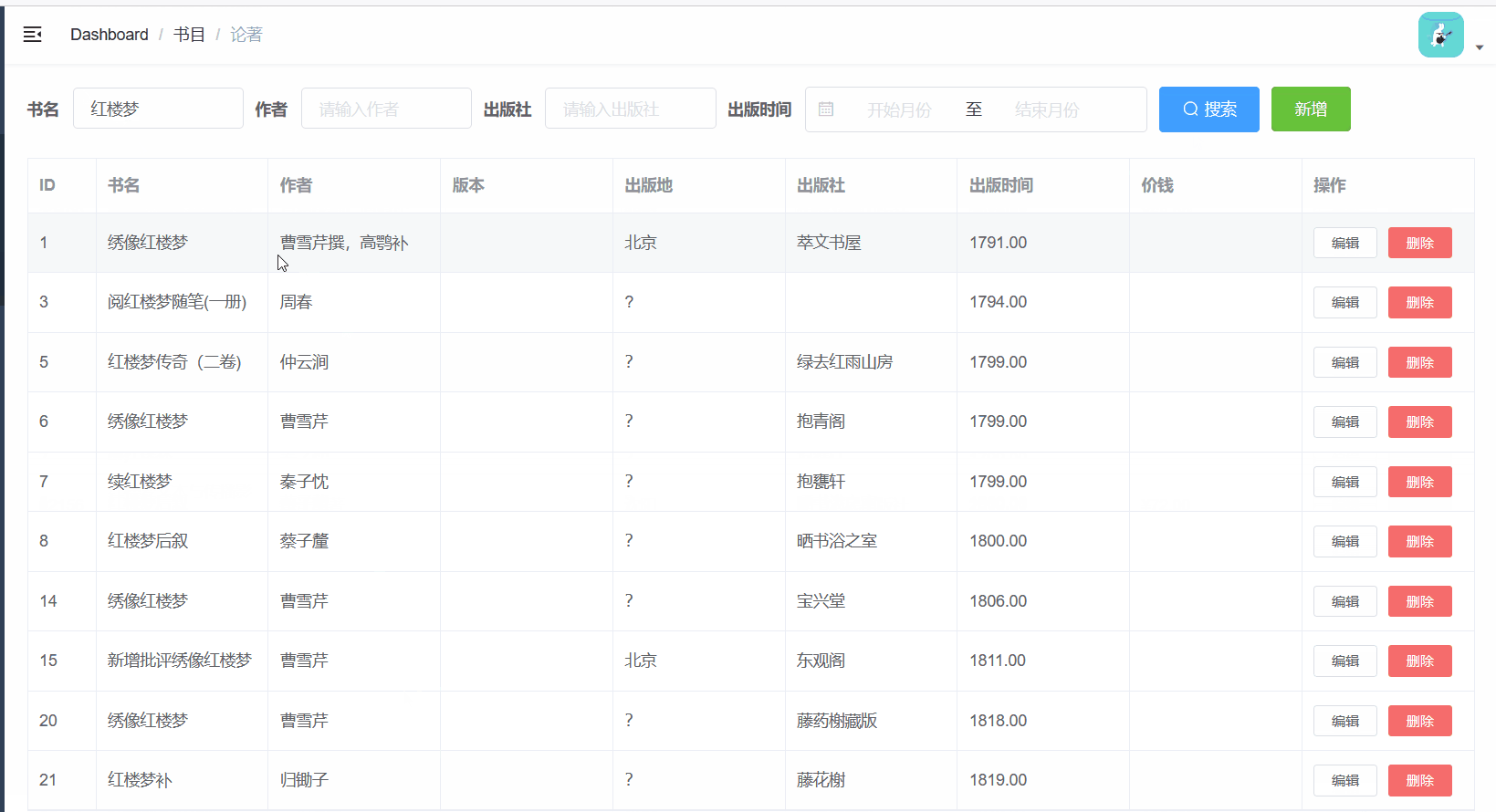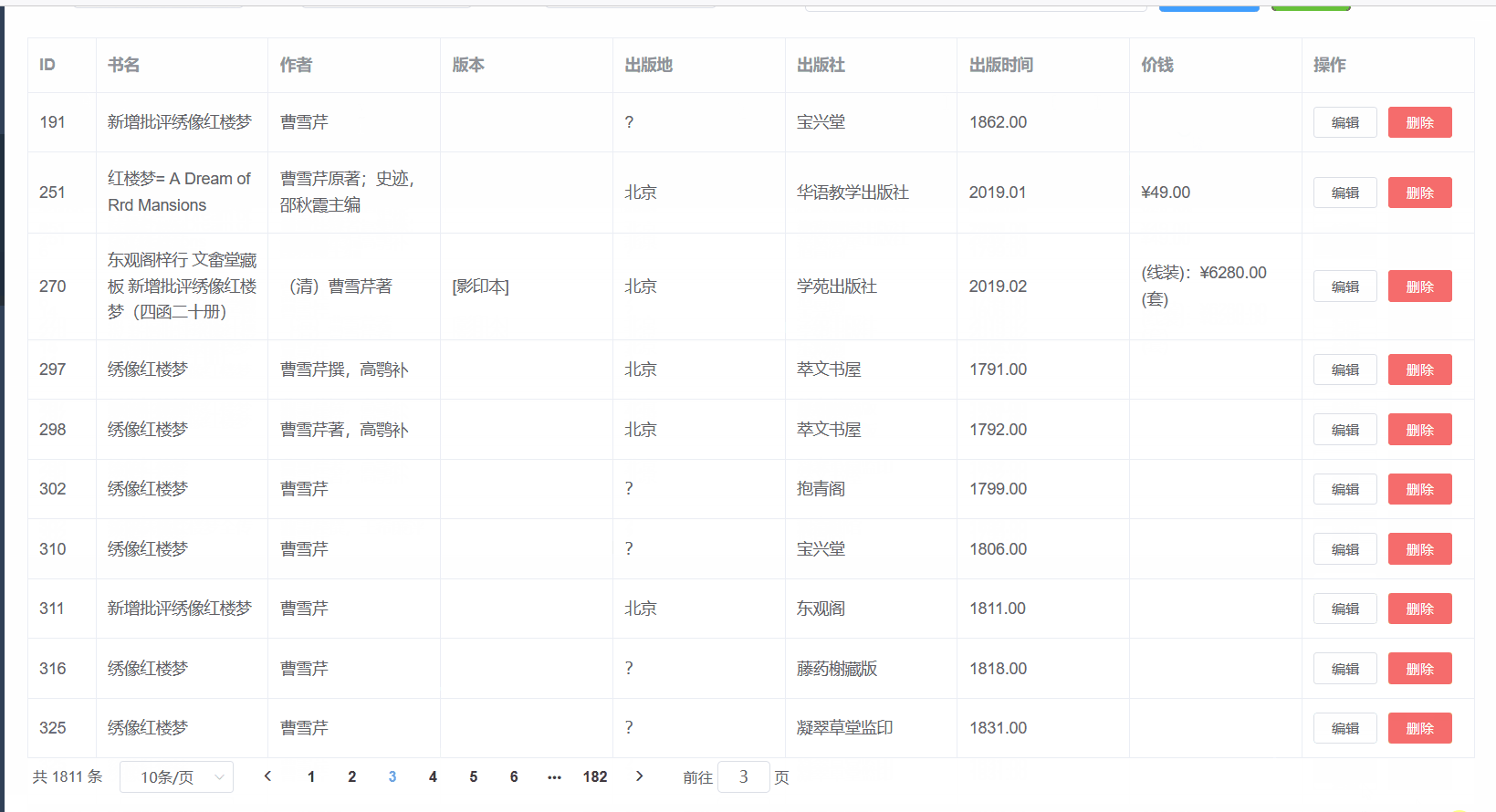
最近手上有个需求,需要做模糊查询,第一时间想到的是mysql分页模糊查询,但是甲方的需求是模糊查询所有的数据,且这个模糊查询也不好通过添加索引进行优化
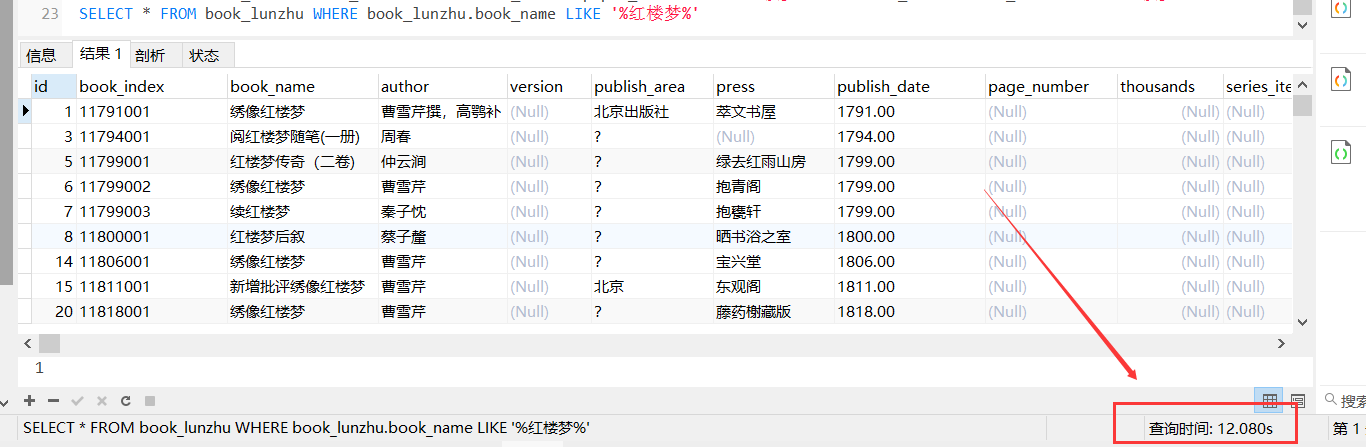
拿到这个需求后,我往大概2w条数据的数据库中全表模糊查询了一下,耗时大概在10s左右:
然后我想其实我的数据量并不大,表中的数据很难也几乎不可能突破十万条数据,如果我直接存在JVM缓存中是不是快一些
说干就干,这里我使用Stream中断言组合的方式进行模糊查询,不熟悉的小伙伴可以看附录中的小例子
这里我根据模糊查询的字段进行断言组合:
@Override
public List<T> likeQuery(Map<String, Object> queryMap) {
// 这里需要先组合断言,因为是与运算,所以初始化一个成功的断言
Predicate<Book> p = Objects::nonNull;
for (Entry<String, Object> entry : queryMap.entrySet()) {
String k = entry.getKey();
String v = String.valueOf(entry.getValue());
Predicate<Book> p2 = null;
if (k.equalsIgnoreCase("bookName")) {
p2 = book -> book.matchName(v);
} else if (k.equalsIgnoreCase("author")) {
p2 = book -> book.matchAuthor(v);
} else if (k.equalsIgnoreCase("publishArea")) {
p2 = book -> book.matchPublishArea(v);
}
// 断言组合
if (p2 != null){
p = p.and(p2);
}
}
// 我是自己用List做的缓存,所有这里通过this获取
return this.stream()
.filter(p)
.collect(Collectors.toList());
}
然后在实体类中写上比较的逻辑:
@Override
public boolean matchName(String str) {
if(this.bookName == null) return false;
return this.bookName.contains(str);
}
接下来就是看效果的时候了,实测两万条数据做模糊查询不会超过100ms,一般会更低,且这里还包括http请求的时间
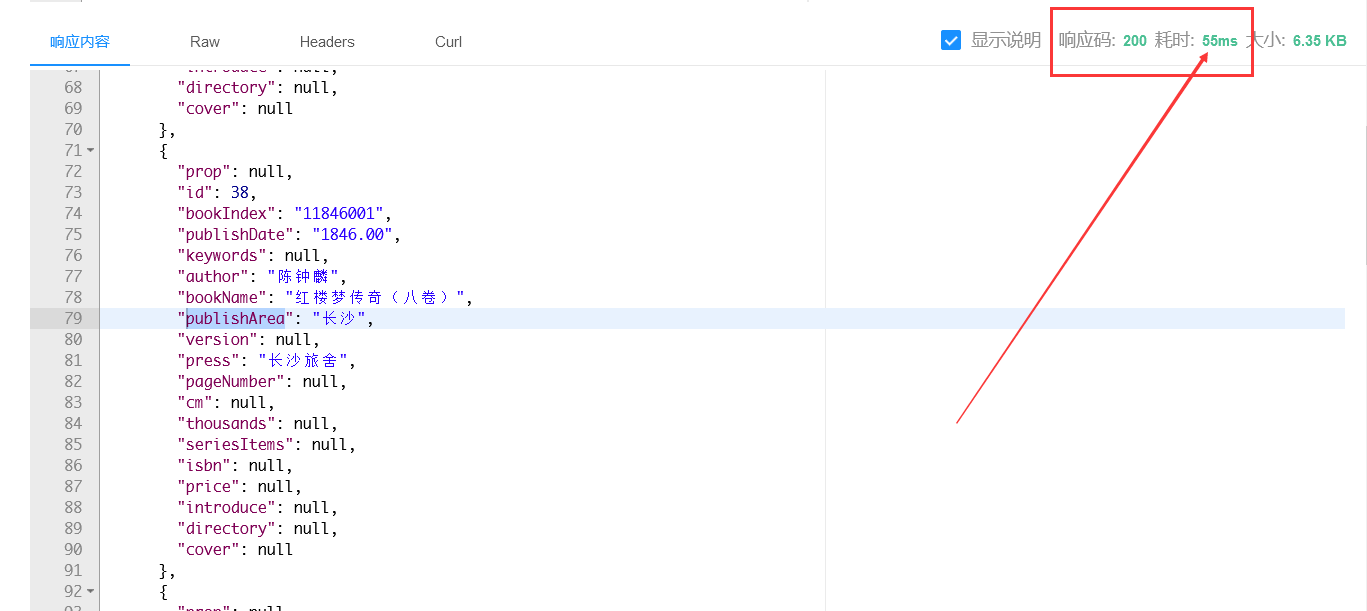
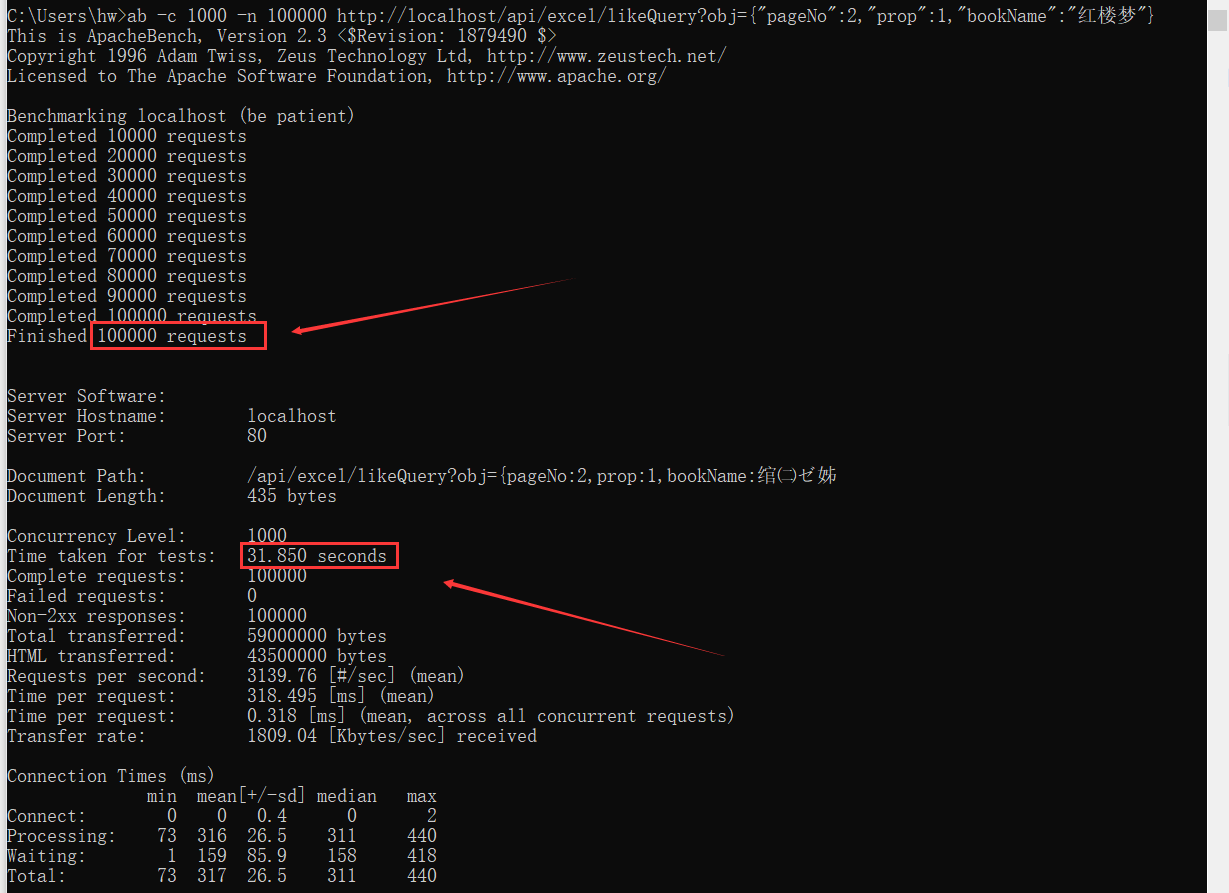
通过
AB测对该接口做一下压测,共设置1000个线程,做十万次请求并记录时间
十万个请求仅耗时31秒
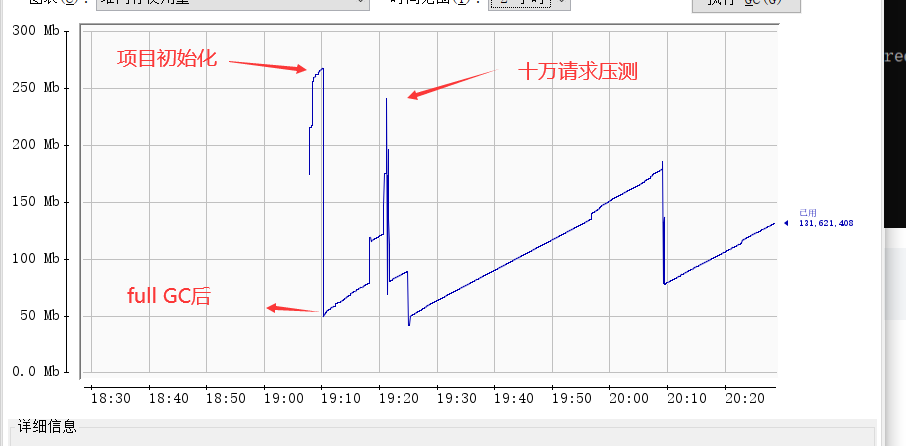
查看JVM堆空间占用情况
发现缓存2万条数据,堆空间占用也在合理范围,且GC后占用内存会大大降低
线程数也在合理范围
在前端模糊查询,非常丝滑,毫无卡顿
小结:
这里建议不要轻易使用并行流对性能进行提升,因为并且流在处理过程中有许多不可控的风险,例如如果使用线程不安全的集合类进行并行流操作时,极有可能产生线程安全问题
笔者建议使用fork/join框架手动拆分任务,保证线程安全
附录,Stream断言组合模糊查询例子
Predicate:<T>断言型接口; 输入一个对象,返回一个Boolean值,需要实现的抽象函数为boolean test(T t)
例如:
/**
* 4.Predicate<T>:断言型接口
*/
@Test
public void test04(){
List<String> list= Arrays.asList("Hello","我乃梁奉先是也","Lambda","www","ok");
//过滤长度大于三的字符串
System.out.println(filterStr(list,(str)->str.length()>3));
}
//需求,将满足条件的字符串添加到集合中
private List<String> filterStr(List<String> list, Predicate<String> predicate) {
List<String> strList = new ArrayList<>();
for (String str : list) {
if (predicate.test(str)) {
strList.add(str);
}
}
return strList;
}
断言组合(谓词组合),与或非
public class PredicateFunction {
//抽取公共代码
static List<Apple> filterApples(List<Apple> inventory, Predicate<Apple> p){
List<Apple> result = new ArrayList<>();
inventory.forEach(apple -> {
if(p.test(apple)){
result.add(apple);
}
});
return result;
}
public static void main(String[] args) {
String[] colors = {"green","yellow","blue"};
Random r = new Random();
List<Apple> list = new ArrayList<>();
for (int i = 0; i < 10; i++) {
list.add(new Apple(colors[r.nextInt(colors.length)],r.nextInt(200)));
}
System.out.println(filterApples(list,Apple::isGreenApple));
System.out.println(filterApples(list,Apple::isHealthyApple));
//组合两个条件
Predicate<Apple> p1 = Apple::isGreenApple;
Predicate<Apple> p2 = Apple::isHealthyApple;
//或运算
System.out.println(filterApples(list,p1.or(p2)));
//and运算
System.out.println(filterApples(list,p1.and(p2)));
}
}
@Data
@AllArgsConstructor
class Apple{
private String color;
private int weight;
public static boolean isGreenApple(Apple apple){
return "green".equalsIgnoreCase(apple.getColor());
}
public static boolean isHealthyApple(Apple apple){
return apple.getWeight() > 150;
}
}
相关文章
- python通过ssh连接mysql数据库的注意事项
- mysql中RAND()随便查询记录效率问题和解决的方法分享
- MySQL用户管理及SQL语句详解
- MySQL 大表如何优化查询效率?
- 在 Linux 中修改 MySQL 或 MariaDB 的 Root 密码
- Open-Falcon 监控系统监控 MySQL/Redis/MongoDB 状态监控
- MySQL逗号分割字段的列转行
- mysql字符串函数(转载)
- ELK收集tomcat访问日志并存取mysql数据库案例
- MySQL基础之 逻辑运算符
- mysql自增获取id
- MySQL -A不预读数据库信息(use dbname 更快)
- 基于Docker的MYSQL 配置主从复制
- [Mysql] CHAR_LENGTH函数