
pandas——DataFrame基本操作(一)【建议收藏】
pandas——DataFrame基本操作(一)
作者:i阿极
作者简介:Python领域新星作者、多项比赛获奖者:博主个人首页
😊😊😊如果觉得文章不错或能帮助到你学习,可以点赞👍收藏📁评论📒+关注哦!👍👍👍
📜📜📜如果有小伙伴需要数据集和学习交流,文章下方有交流学习区!一起学习进步!💪
文章目录
一、实验目的
熟练掌握pandas中DataFrame的基本操作
二、实验原理
DataFrame提供的是一个类似表的结构,由多个Series组成,而Series在DataFrame中叫columns。
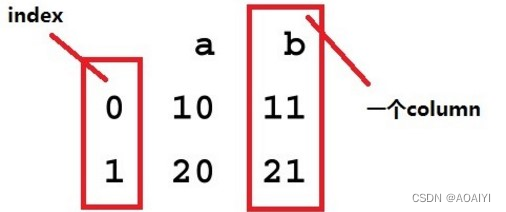
一、查看数据(查看对象的方法对于Series来说同样适用)
1.查看DataFrame前xx行或后xx行
a=DataFrame(data);
a.head(6)表示显示前6行数据,若head()中不带参数则会显示全部数据。
a.tail(6)表示显示后6行数据,若tail()中不带参数则也会显示全部数据。
2.查看DataFrame的index,columns以及values
a.index ; a.columns ; a.values 即可
3.describe()函数对数据快速统计汇总
a.describe()对每一列数据进行统计,包括计数,均值,std,各个分位数等。
4.对数据的转置
a.T
5.对轴进行排序
a.sort_index(axis=1,ascending=False);
其中axis=1表示对所有的columns进行排序,下面的数也跟着发生移动。后面的ascending=False表示按降序排列,参数缺失时默认升序。
6.对DataFrame中的值排序
a.sort(columns=‘x’)
即对a中的x这一列,从小到大进行排序。注意仅仅是x这一列,而上面的按轴进行排序时会对所有的columns进行操作。
二、选择对象
1.选择特定列和行的数据
a[‘x’] 那么将会返回columns为x的列,注意这种方式一次只能返回一个列。a.x与a[‘x’]意思一样。
取行数据,通过切片[]来选择
如:a[0:3] 则会返回前三行的数据。
2.loc是通过标签来选择数据
a.loc[‘one’]则会默认表示选取行为’one’的行;
a.loc[:,[‘a’,‘b’] ] 表示选取所有的行以及columns为a,b的列;
a.loc[[‘one’,‘two’],[‘a’,‘b’]] 表示选取’one’和’two’这两行以及columns为a,b的列;
a.loc[‘one’,‘a’]与a.loc[[‘one’],[‘a’]]作用是一样的,不过前者只显示对应的值,而后者会显示对应的行和列标签。
3.iloc则是直接通过位置来选择数据
这与通过标签选择类似
a.iloc[1:2,1:2] 则会显示第一行第一列的数据;(切片后面的值取不到)
a.iloc[1:2] 即后面表示列的值没有时,默认选取行位置为1的数据;
a.iloc[[0,2],[1,2]] 即可以自由选取行位置,和列位置对应的数据。
4.使用条件来选择
使用单独的列来选择数据
a[a.c>0] 表示选择c列中大于0的数据
使用where来选择数据
a[a>0] 表直接选择a中所有大于0的数据
使用isin()选出特定列中包含特定值的行
a1=a.copy()
a1[a1[‘one’].isin([‘2’,‘3’])] 表显示满足条件:列one中的值包含’2’,'3’的所有行。
三、设置值(赋值)
赋值操作在上述选择操作的基础上直接赋值即可。
例a.loc[:,[‘a’,‘c’]]=9 即将a和c列的所有行中的值设置为9
a.iloc[:,[1,3]]=9 表示1和2列的所有行中的值设置为9
同时也依然可以用条件来直接赋值
a[a>0]=-a 表示将a中所有大于0的数转化为负值
三、实验环境
Python 3.6.1以上
jupyter notebook
四、实验内容
练习pandas中DataFrame的创建与查询操作。
五、实验步骤
1.创建DataFrame。
1.通过字典对象创建一个DataFrame。
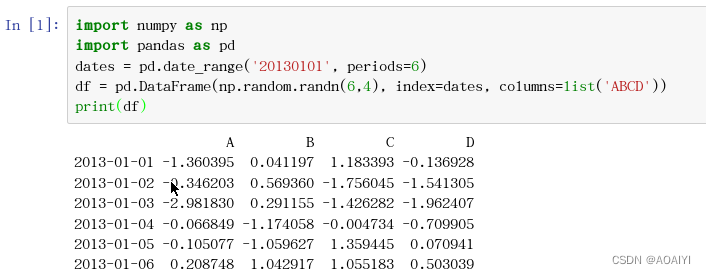
import numpy as np
import pandas as pd
dates = pd.date_range('20130101', periods=6)
df = pd.DataFrame(np.random.randn(6,4), index=dates, columns=list('ABCD'))
print(df)
2.基础操作
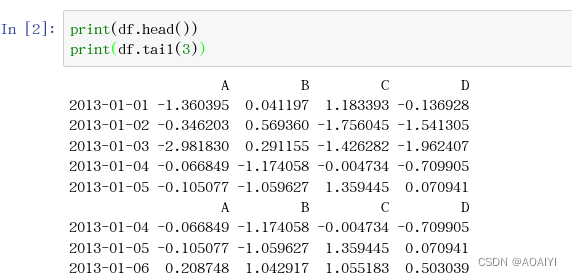
1.查看df的前5行,查看df的后3行。
print(df.head())
print(df.tail(3))
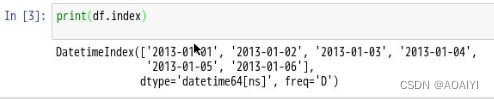
2.查看df的索引名index。
print(df.index)
3.查看df的列名columns。
print(df.columns)
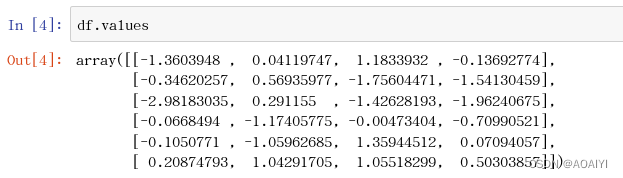
4.查看df的值values。
df.values
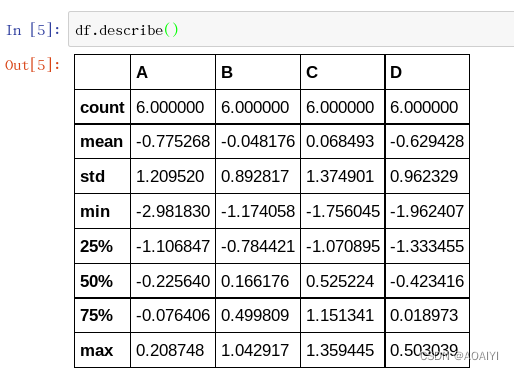
5.查看df的数据统计描述。
df.describe()
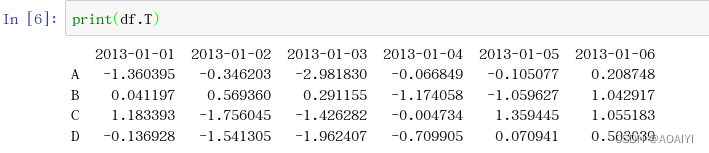
5.df的转置。
print(df.T)
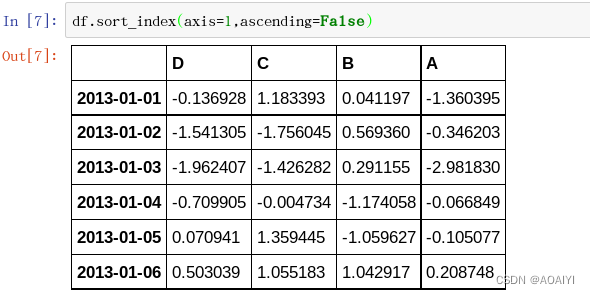
6.按axis对df数据进行排序,axis=1表示按行排序,axis=0表示按列排序。
df.sort_index(axis=1,ascending=False)
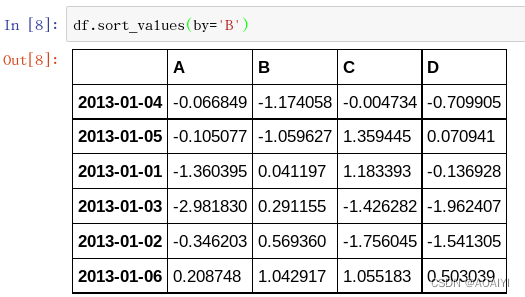
7.按value对df数据进行排序。
df.sort_values(by='B')
3.Selection查看操作
1.查看df中的A列,返回一个Series。
print(df['A'])

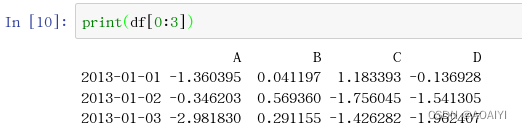
2.通过[]查看df 的行片段。
print(df[0:3])
4.通过label查看df数据
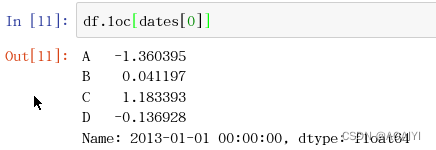
1.使用loc查看df中dates[0]的部分。
df.loc[dates[0]]
2.使用loc查看A、B两列的值
print(df.loc[:,['A','B']])

3.使用loc查看日期从20130102到20130104的A,B量列的值。
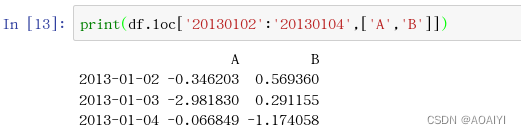
print(df.loc['20130102':'20130104',['A','B']])
4.减少维度,查看日期为20130102中A,B两列的值。
df.loc['20130102',['A','B']]

5.得到一个标量值,使用loc查看df中date[0],A列的值。
print(df.loc[dates[0],'A'])

6.使用at快速查找df中dates[0],A列的值。
print(df.at[dates[0],'A'])

7.使用iloc查看df的第4行数据。
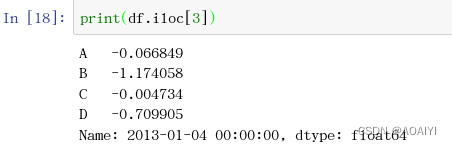
print(df.iloc[3])
8.使用iloc查看df中行下标为3:5,列下标为0:2的数据(不包含行下标为5的行,也不包含列下标为2的列)。
print(df.iloc[3:5,0:2])

9.使用iloc查看df中行下标为1,2,4,列下标为0,2的数据。
print(df.iloc[[1,2,4],[0,2]])

10.使用iloc查看df行下标为1:3的数据(不包含下标为3的行)。
print(df.iloc[1:3,:])

11.使用iloc查看df行列下标都为1的值。
print(df.iloc[1,1])

5.使用布尔索引查看df的数据
1.查看df中满足df.A>0布尔条件的值。
print(df[df.A>0])

2.查看df中满足df>0布尔条件的值。
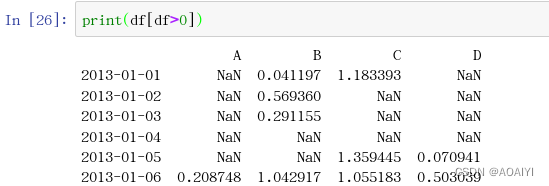
print(df[df>0])
相关文章
- 【数据分析之道-Pandas(一)】Series操作
- Pandas——Series操作【建议收藏】
- pandas——DataFrame基本操作(二)【建议收藏】
- Pandas学习笔记
- Python pandas.DataFrame.to_timestamp函数方法的使用
- Python import pandas_datareader报错(ImportError cannot import name 'is_list_like')
- Python pandas.DataFrame.rename_axis函数方法的使用
- Python pandas.DataFrame.merge函数方法的使用
- Python pandas.DataFrame.ewm函数方法的使用
- Python pandas.DataFrame.iat函数方法的使用
- Python Pandas pandas.DataFrame.from_records函数方法的使用