
更新数据时,MySQL的聚簇索引是如何变化的?
文章已收录在我的 GitHub 仓库,欢迎Star/fork:
Java-Interview-Tutorial
听说点赞、评论、收藏的人长得都很好看哦。
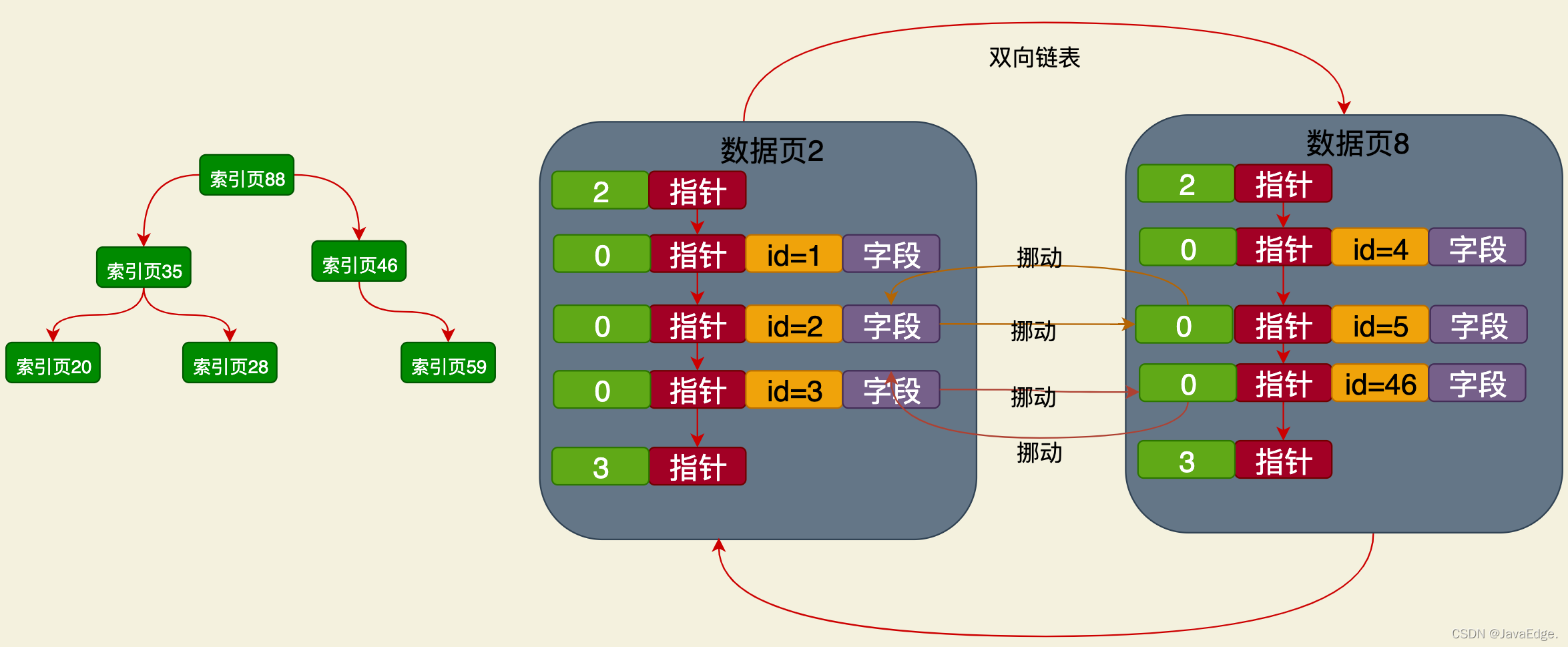
搜索一个主键id对应的行,先去顶层的索引页88里通过二分查找,定位到你应该去下层哪个索引页里继续找。
若现在定位到下层的索引页35,此时在索引页35里也有一些索引条目,分别都是下层各索引页(20、28、59)及他们里面最小的主键值,此时在索引页35的索引条目里继续二分查找,容易定位到,应该再到下层的索引页里找。
可能从索引页35接着就找到下层的索引页59,此时索引页59里也有索引条目,存放部分数据页页号(如数据页2、8)和每个数据页里最小的主键值。在此继续二分查找,就能定位到应该到哪个数据页里去找。
比如进入数据页2,里面就有个页目录,存放各行数据的主键值和行的实际物理位置。在此继续二分查找,即可快速定位到待搜索主键值对应行的物理位置,然后直接在数据页2里找到那条数据。这就是基于索引去查找主键的过程。
最下层的索引页,都有指针引用数据页,所以索引页之间跟数据页之间有指针连接。索引页内部,同一层级的索引页互相之间也是基于指针组成双向链表:
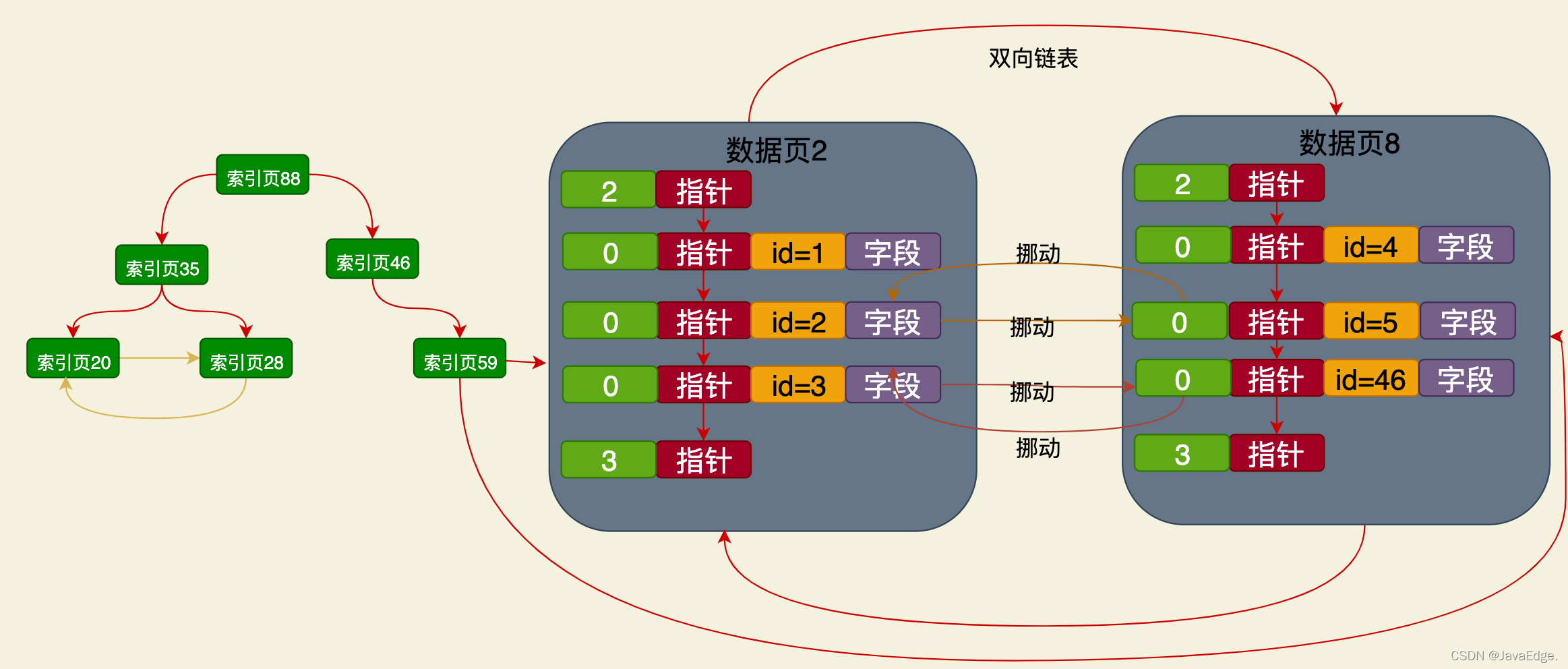
假设你把索引页和数据页综合起来看,他们都是连接在一起的,从根索引页88开始,一直到所有的数据页,组成了B+树。最底层的一层就是数据页,数据页也就是B+树里的叶节点。
所以,如果B+树索引数据结构里,叶节点就是数据页自己本身,即为聚簇索引!即上图中所有的索引页+数据页组成的B+树就是聚簇索引!
InnoDB下,对数据增删改时,就是直接把你的数据页放在聚簇索引,数据就在聚簇索引里,聚簇索引就包含了数据。比如你插入数据,那就是在数据页里插入数据。
若你的数据页开始进行页分裂,他此时会调整各数据页内部的行数据,保证数据页内的主键值都有序,:
下一个数据页的所有主键值>上一个数据页的所有主键值
页分裂时,也会维护你的上层索引数据结构,在上层索引页里维护你的索引条目,不同的数据页和最小主键值。
然后若你的数据页越来越多,一个索引页放不下了,就会再拉出新的索引页,同时再搞一个上层的索引页,上层索引页里存放的索引条目就是下层索引页页号和最下主键值。
同理可得,若你的数据量越大,此时可能就多出更多索引页层级,不过一般索引页里可以放很多索引条目,即使你是亿级大表,基本上大表里建的索引的层级也就三四层。
聚簇索引默认按主键组织的,所以你在增删改数据时:
- 会更新数据页
- 会给你自动维护B+树结构的聚簇索引,给新增和更新索引页,这个聚簇索引是默认就会给你建立
相关文章
- MySQL的索引条件下推(index condition pushdown,ICP)
- 新增数据时,MySQL索引树的自调整过程
- mysql的索引
- mysql数据库迁移
- mysql数据索引,加快查询速度
- 从.Net到Java学习第三篇——spring boot+mybatis+mysql
- MySQL获取Schema表名和字段信息
- Linux下mysql的远程连接(转)
- mysql的数据表同步工具 canal的使用
- MySQL 性能调优之索引
- java 解决date类型的时间插入mysql中差8小时
- MySQL 定时备份的几种方式,这下稳了!
- MySQL 中如何计算一个索引的长度
- [转载]MySQL之char、varchar和text的设计
- MySQL命令
- 【ChatGPT】我同时问 ChatGLM / Sage / ChatGPT :MySQL 添加索引之后 数据库做了些什么? 看看它们分别怎么回答……
- MySQL大表优化方案
- 图解MySQL索引--B-Tree(B+Tree)
- MySQL性能调优——索引详解与索引的优化
- mysql数据库误删除后的数据恢复操作说明
- yum安装mysql-5.6(centos7)-阿里云备份恢复到本地
- MySQL索引和SQL调优
- MySQL在线DDL gh-ost 使用说明
- MYSQL中唯一约束和唯一索引的区别
- MySQL联合索引最左匹配范例
- [转]mongodb与mysql相比的优缺点
- MYSQL错误解决:ERROR 2002 (HY000): Can't connect to local MySQL server through socket '/var/lib/mysql/mysql.sock' (2)
- mysql查看索引
- MySQL 索引的使用