
Text to image论文精读DR-GAN:分布正则化的生成对抗网络 Distribution-Regularization-for-Text-to-Image-Generation
DR-GAN是北京理工大学者和大连理工大学学于2022年4月提出的一种新的文本到图像生成模型,称为分布正则化生成对抗网络(Distribution-Regularization-for-Text-to-Image-Generation,DR-GAN)
论文地址:https://arxiv.org/abs/2204.07945
代码地址:https://github.com/Tan-H-C/DR-GAN-Distribution-Regularization-for-Text-to-Image-Generation
一、原文摘要
本文提出了一种新的文本到图像生成模型,称为分布正则化生成对抗网络(DR-GAN),用于从改进的分布学习中的文本描述生成图像。在DR-GAN中,我们引入了两个新的模块:语义分离模块(SDM)和分布规范化模块(DNM)。SDM结合了空间自关注机制和一种新的语义分离损失(SDL),以帮助生成器提取用于图像生成的关键语义信息。DNM使用变分自动编码器(VAE)对图像潜在分布进行归一化和去噪,这可以帮助鉴别器更好地区分合成图像和真实图像。DNM还采用分布对抗损失(DAL)来引导生成器与潜在空间中的归一化真实图像分布对齐。
在两个公共数据集上的大量实验表明,我们的DR-GAN在文本到图像任务中取得了具有竞争力的性能。
二、为什么提出DR-GAN?
许多最先进的T2I算法首先提取文本特征,然后使用生成对抗网络(GAN)生成相应的图像,它们的本质是将文本特征分布映射到图像分布。
基于GAN的T2I方法捕获真实图像分布有两大难点:
- 文本描述的抽象性和模糊性使得生成器很难捕获用于图像生成的关键语义信息;在多模态感知信息中,文本描述的语义通常是抽象和模糊的;图像信息通常是具体的,并且具有大量的空间结构信息。文本和图像信息以不同的模式表示,这使得难以基于特征向量或张量实现语义关联。因此,生成器很难从用于图像生成的文本描述中准确地捕获关键语义;
- 视觉信息的多样性使得图像的分布变得复杂,图像通常包含各种视觉信息、杂乱的背景和其他非关键视觉信息,图像潜在分布通常是复杂的,图像的分布很难明确建模。
因此,本研究探索了更好的分布学习策略以增强基于GAN的T2I模型:
- 图像特征包含大量非关键语义。这种不准确的语义往往导致图像分布生成无效,进而导致生成的图像往往语义不一致、结构和细节混乱等。为了缓解这一问题,DR-GAN的第一个策略是在中间特征上设计一种信息解纠缠机制,以便在执行跨模态分布学习之前更好地提取关键信息。
- 复杂的图像分布使得GAN中的鉴别器难以区分当前输入图像是从真实图像分布还是生成的图像分布采样的。因此,DR-GAN的第二个策略是设计一个有效的分布归一化机制来归一化图像的潜在分布,该机制旨在帮助鉴别器更好地学习生成的图像与真实图像之间的分布决策边界。
三、DR-GAN
3.1、框架结构
作者采用AttnGAN作为构建DR-GAN的基线模型,即一个文本编码器,三个生成器和三个鉴别器,框架结构如下:
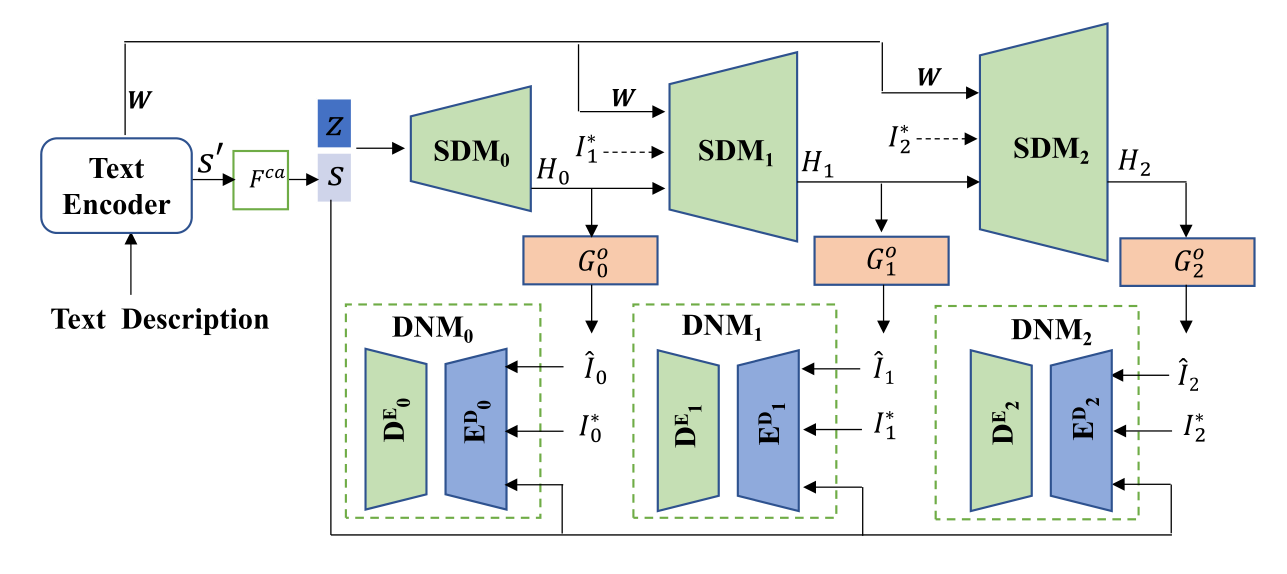
如图所示,DRGAN有两个新的设计,语义解缠模块(SDM)和分布归一化模块(DNM)。SDM在图像生成的中间阶段从文本或图像特征中提取关键信息,以便更好地接近真实的图像分布。在DNM中,作者将变分自动编码器(VAE)引入到基于GAN的T2I方法中,以规范潜在空间中的图像分布。
3.2、语义解缠模块(SDM)
语义解缠模块(Semantic Disentangling Module, SDM)主要是用来帮助生成器抑制不相关的空间信息,突出相关的空间信息,以生成高质量的图像,其结构如下:
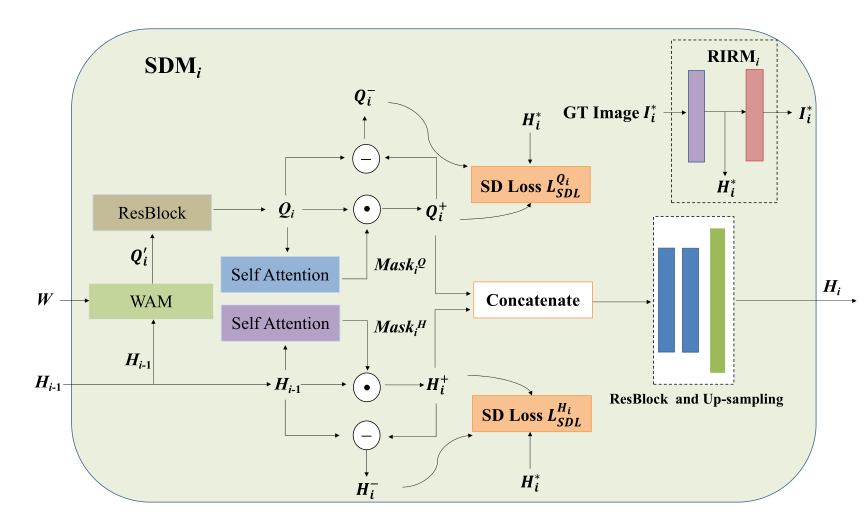
W表示单词特征,H表示图像特征,WAM表示词级注意机制(Word-level Attention Mechanism),ResBlock表示残差块,图像特征和单词特征首先计算单词级注意力生成上下文特征Q,然后上下文特征和图像特征分别经过一层自注意力提取关键信息,然后再将两者做concat连接。(H+、Q+表示关键信息,H-、Q-表示非关键信息,)其中:
-
WAM词级注意力机制:跟AttnGAN的部分相同,即先把单词特征映射到与图像特征相同的潜在语义空间,然后计算单词子区域和图像子区域的相似度特征: q j = ∑ i = 1 T θ j , i w i ′ , where θ j , i = exp ( S j , i ′ ) ∑ k = 1 T exp ( S j , k ′ ) q_{j}=\sum_{i=1}^{T} \theta_{j, i} w_{i}^{\prime}, \quad \text { where } \theta_{j, i}=\frac{\exp \left(S_{j, i}^{\prime}\right)}{\sum_{k=1}^{T} \exp \left(S_{j, k}^{\prime}\right)} qj=∑i=1Tθj,iwi′, where θj,i=∑k=1Texp(Sj,k′)exp(Sj,i′),WAM依据此方法根据给定的单词特征W和图像特征h生成单词级上下文特征 Q 0 Q_0 Q0,其中 Q 0 Q_0 Q0是表达图像特征h的单词特征的加权组合。 Q 0 Q_0 Q0可以有效丰富图像细节的语义。
-
Self Attention自注意力机制:使用的是空间自注意机制,分别表示词级上下文特征 Q 0 ‘ Q_0^‘ Q0‘和中间图像特征 H i − 1 H_{i−1} Hi−1的关键信息和非关键信息。而用于计算自注意力机制特征 H i − 1 H_{i−1} Hi−1的空间注意掩码 M a s k i H Mask^H_i MaskiH为: Mask i H = Sig . ( Conv 1 × 1 2 ( ReLU ( Conv 3 × 3 1 ( H i − 1 ) ) ) ) \operatorname{Mask}_{i}^{H}=\operatorname{Sig} .\left(\operatorname{Conv}_{1 \times 1}^{2}\left(\operatorname{ReLU}\left(\operatorname{Conv}_{3 \times 3}^{1}\left(H_{i-1}\right)\right)\right)\right) MaskiH=Sig.(Conv1×12(ReLU(Conv3×31(Hi−1)))),特征 Q i Q_i Qi的空间注意掩码 M a s k i Q Mask^Q_i MaskiQ定义为 Mask i Q = Sig ⋅ ( Conv 1 × 1 2 ( ReLU ( Conv 3 × 3 1 ( Q i ) ) ) ) \operatorname{Mask}_{i}^{Q}=\operatorname{Sig} \cdot\left(\operatorname{Conv}_{1 \times 1}^{2}\left(\operatorname{ReLU}\left(\operatorname{Conv}_{3 \times 3}^{1}\left(Q_{i}\right)\right)\right)\right) MaskiQ=Sig⋅(Conv1×12(ReLU(Conv3×31(Qi))))
-
RIRM实数图像重建模块:包含一个编码器和一个解码器。编码器以实像 I i ∗ I_i^* Ii∗作为输入,输出实像特征 H i ∗ H_i^* Hi∗。解码器取实像特征 H i ∗ H_i^* Hi∗,利用重构损失函数 ∥ R I R M ( I i ∗ ) − I i ∗ ∥ 1 \left\|R I R M\left(I_{i}^{*}\right)-I_{i}^{*}\right\|_{1} ∥RIRM(Ii∗)−Ii∗∥1对实像进行重构,解码器和生成模块 G 0 G^0 G0组成了Siamese网络,可以为SDM提供高质量的真实图像特征。
-
Semantic Disentangling Loss 语义解缠损失:为了驱动SDM更好地区分 Q i Q_i Qi和 H i − 1 H_{i−1} Hi−1的关键信息和非关键信息。作者进一步设计了一个新的语义解缠损失(SDL),对于图像特征和上下文特征: L S D L H i = S P ( ∥ μ ( H i + ) − μ ( H i ∗ ) ∥ − ∥ μ ( H i − ) − μ ( H i ∗ ) ∥ ) + S P ( ∥ σ ( H i + ) − σ ( H i ∗ ) ∥ − ∥ σ ( H i − ) − σ ( H i ∗ ) ∥ ) \begin{aligned} \mathcal{L}_{S D L}^{H_{i}}= & S P\left(\left\|\mu\left(H_{i}^{+}\right)-\mu\left(H_{i}^{*}\right)\right\|-\left\|\mu\left(H_{i}^{-}\right)-\mu\left(H_{i}^{*}\right)\right\|\right)+S P\left(\left\|\sigma\left(H_{i}^{+}\right)-\sigma\left(H_{i}^{*}\right)\right\|-\left\|\sigma\left(H_{i}^{-}\right)-\sigma\left(H_{i}^{*}\right)\right\|\right) \end{aligned} LSDLHi=SP(∥∥μ(Hi+)−μ(Hi∗)∥∥−∥∥μ(Hi−)−μ(Hi∗)∥∥)+SP(∥∥σ(Hi+)−σ(Hi∗)∥∥−∥∥σ(Hi−)−σ(Hi∗)∥∥)
L S D L Q i = S P ( ∥ μ ( Q i + ) − μ ( H i ∗ ) ∥ − ∥ μ ( Q i − ) − μ ( H i ∗ ) ∥ ) + S P ( ∥ σ ( Q i + ) − σ ( H i ∗ ) ∥ − ∥ σ ( Q i − ) − σ ( H i ∗ ) ∥ ) \begin{aligned} \mathcal{L}_{S D L}^{Q_{i}}= & S P\left(\left\|\mu\left(Q_{i}^{+}\right)-\mu\left(H_{i}^{*}\right)\right\|-\left\|\mu\left(Q_{i}^{-}\right)-\mu\left(H_{i}^{*}\right)\right\|\right) +S P\left(\left\|\sigma\left(Q_{i}^{+}\right)-\sigma\left(H_{i}^{*}\right)\right\|-\left\|\sigma\left(Q_{i}^{-}\right)-\sigma\left(H_{i}^{*}\right)\right\|\right) \end{aligned} LSDLQi=SP(∥∥μ(Qi+)−μ(Hi∗)∥∥−∥∥μ(Qi−)−μ(Hi∗)∥∥)+SP(∥∥σ(Qi+)−σ(Hi∗)∥∥−∥∥σ(Qi−)−σ(Hi∗)∥∥)
其中,u表示均值、 σ \sigma σ表示方差,SP (x) = ln(1 + e x e^x ex),最终的SDL损失如下:
L S D L i = λ 1 L S D L H i + λ 2 L S D L Q i + λ 3 ∥ R I R M ( I i ∗ ) − I i ∗ ∥ 1 \mathcal{L}_{S D L_{i}}=\lambda_{1} \mathcal{L}_{S D L}^{H_{i}}+\lambda_{2} \mathcal{L}_{S D L}^{Q_{i}}+\lambda_{3}\left\|R I R M\left(I_{i}^{*}\right)-I_{i}^{*}\right\|_{1} LSDLi=λ1LSDLHi+λ2LSDLQi+λ3∥RIRM(Ii∗)−Ii∗∥1
下图展示了,在加入基于SDM驱动的关键信息选择策略,可以更好地过滤出
H
1
H_1
H1和
Q
2
‘
Q_2^`
Q2‘上的非关键结构性信息,进而使得图像特征
H
2
H_2
H2的结构和语义变得更加合理。因此,合成图像的结构也更合理:

3.3、分布归一化模块(DNM)
在鉴别器方面,复杂的图像分布使得鉴别器很难区分当前输入图像是从真实图像分布中采样的还是从生成的图像分布中采样的。并且生成器很难使生成的分布与真实图像分布保持一致,有必要降低分布的复杂性。而数据归一化机制可以降低数据的噪声和内部协变量移位,进一步提高模型的学习效率,是一种有效的去噪和降低复杂性的策略。
对于此,归一化模块使用变分自动编码器以帮助鉴别器更好地区分“真”图像和“假”图像。变分自动编码器(VAE)[24]作为一种生成模型,可以有效地去噪潜在分布,降低分布的复杂性。假设图像的潜在嵌入向量服从高斯分布N(µ,σ),然后将N(µ,σ)归一化为标准正态分布N(0,1)。基于VAE图像重建的优势,归一化后的嵌入向量可以保留关键语义视觉信息。DNM的结构如下所示:
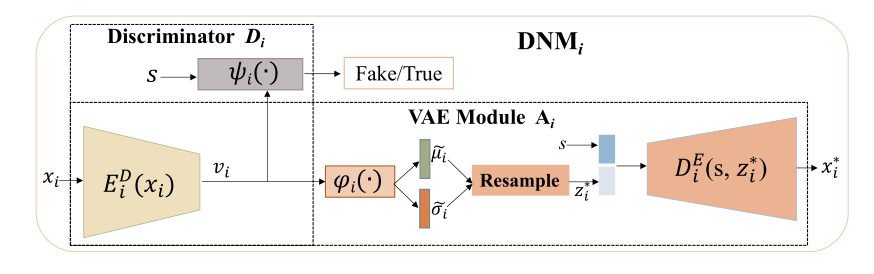
其包含两个子模块:鉴别器Di和VAE模块Ai:
-
鉴别器模块很常规,其由编码器 E D E^D ED(·)和逻辑分类器ψ(·)组成。 E D E^D ED(·)将图像x编码为嵌入向量v.将嵌入向量v与文本嵌入s结合,馈送给逻辑分类器ψ(·),用于识别x是真实图像还是生成图像。
图像中视觉信息的多样性、背景的杂乱性以及其他非关键视觉信息使得嵌入向量v的分布变得复杂,使得x的识别更加困难。 -
因此采用VAE模块对嵌入向量V的潜在分布进行归一化和去噪。除了降低图像潜在分布的复杂性外,使用VAE还可以推动编码后的图像特征向量V来记录重要的图像语义。
DNM模块将V AE和鉴别器j相结合,可以有效地降低图像嵌入V构造的分布的复杂性,丰富图像嵌入V的高级语义信息,这种归一化的嵌入有助于鉴别器更好地区分“假”图像和“真”图像。因此,生成器也可以更好地将生成的分布与真实图像分布对齐。
整个DNM主要步骤如下:
- 给定图像x, x首先被馈送给编码器ED(·),ED(·)输出图像潜在嵌入v
- 逻辑分类器φ(·)给出v的均值和方差,并构建一个高斯分布: N ( μ ~ ( φ ( v ) ) , σ ~ ( φ ( v ) ) ) N(\tilde{\mu}(\varphi(v)), \tilde{\sigma}(\varphi(v))) N(μ~(φ(v)),σ~(φ(v))),通过KL散度进一步将这个高斯分布归一化为 z ∗ = z ⋅ σ ~ ( φ ( v ) ) ) + μ ~ ( φ ( v ) ) , z ∼ N ( 0 , 1 ) \left.z^{*}=z \cdot \tilde{\sigma}(\varphi(v))\right)+\tilde{\mu}(\varphi(v)), z \sim N(0,1) z∗=z⋅σ~(φ(v)))+μ~(φ(v)),z∼N(0,1),
- z ∗ z^* z∗和文本嵌入s进行拼接,然后输入解码器DE(·)重构图像 x ∗ x^* x∗。
- 重构的图像与原图像计算损失,优化模型。
VAE与GAN联合训练,基于VAE的下变分界,DNM中VAE模块的损失函数可以定义为:
L
D
i
D
D
=
∥
I
^
i
−
D
i
E
(
φ
i
(
E
D
(
I
^
i
)
)
,
s
)
∥
1
+
∥
I
i
∗
−
D
i
E
(
φ
i
(
E
D
(
I
i
∗
)
)
,
s
)
∥
1
+
K
L
(
N
(
μ
~
i
(
φ
i
(
E
D
(
I
^
i
)
)
)
,
σ
~
i
(
φ
i
(
E
D
(
I
^
i
)
)
)
)
)
∥
N
(
0
,
1
)
)
+
K
L
(
N
(
μ
~
i
(
φ
i
(
E
D
(
I
i
∗
)
)
)
,
σ
~
i
(
φ
i
(
E
D
(
I
i
∗
)
)
)
)
)
∥
N
(
0
,
1
)
)
\begin{aligned} \mathcal{L}_{D_{i}^{D}}^{D}= & \left\|\hat{I}_{i}-D_{i}^{E}\left(\varphi_{i}\left(E^{D}\left(\hat{I}_{i}\right)\right), s\right)\right\|_{1}+\left\|I_{i}^{*}-D_{i}^{E}\left(\varphi_{i}\left(E^{D}\left(I_{i}^{*}\right)\right), s\right)\right\|_{1} \\ & \left.+K L\left(N\left(\tilde{\mu}_{i}\left(\varphi_{i}\left(E^{D}\left(\hat{I}_{i}\right)\right)\right), \tilde{\sigma}_{i}\left(\varphi_{i}\left(E^{D}\left(\hat{I}_{i}\right)\right)\right)\right)\right) \| N(0,1)\right) \\ & \left.+K L\left(N\left(\tilde{\mu}_{i}\left(\varphi_{i}\left(E^{D}\left(I_{i}^{*}\right)\right)\right), \tilde{\sigma}_{i}\left(\varphi_{i}\left(E^{D}\left(I_{i}^{*}\right)\right)\right)\right)\right) \| N(0,1)\right) \end{aligned}
LDiDD=∥∥∥I^i−DiE(φi(ED(I^i)),s)∥∥∥1+∥∥Ii∗−DiE(φi(ED(Ii∗)),s)∥∥1+KL(N(μ~i(φi(ED(I^i))),σ~i(φi(ED(I^i)))))∥N(0,1))+KL(N(μ~i(φi(ED(Ii∗))),σ~i(φi(ED(Ii∗)))))∥N(0,1))
分布一致性损失为:
L G i D = K L ( N ( μ ~ i ( φ i ( E D ( I ^ i ) ) ) , σ ~ i ( φ i ( E D ( I ^ i ) ) ) ) ) ∥ N ( 0 , 1 ) ) + ∥ I i ∗ − D i E ( φ i ( E D ( I ^ i ) ) , s ) ∥ 1 , \begin{aligned} \mathcal{L}_{G_{i}^{D}}= & \left.K L\left(N\left(\tilde{\mu}_{i}\left(\varphi_{i}\left(E^{D}\left(\hat{I}_{i}\right)\right)\right), \tilde{\sigma}_{i}\left(\varphi_{i}\left(E^{D}\left(\hat{I}_{i}\right)\right)\right)\right)\right) \| N(0,1)\right) \\ & +\left\|I_{i}^{*}-D_{i}^{E}\left(\varphi_{i}\left(E^{D}\left(\hat{I}_{i}\right)\right), s\right)\right\|_{1}, \end{aligned} LGiD=KL(N(μ~i(φi(ED(I^i))),σ~i(φi(ED(I^i)))))∥N(0,1))+∥∥∥Ii∗−DiE(φi(ED(I^i)),s)∥∥∥1,
将两个损失函数 L G i D L_{G^D_i} LGiD和LDDi表示为分布对抗损失(DAL)项。在鉴别器的训练阶段,LDDi有助于鉴别器更好地区分合成图像与真实图像,更好地学习生成图像与真实图像潜在分布之间的分布决策边界。在生成器的训练阶段,LGDi可以帮助生成器学习并捕获归一化潜空间中的真实图像分布。
四、损失函数
结合上述模块,在DRGAN的第i阶段,定义生成损耗
L
G
i
L_{Gi}
LGi和判别损耗
L
D
i
L_{Di}
LDi为:
L
G
i
=
−
1
2
E
I
^
i
∼
P
G
i
[
log
D
i
(
I
^
i
)
]
⏟
unconditional loss
−
1
2
E
I
^
i
∼
P
G
i
[
log
D
i
(
I
^
i
,
s
)
]
⏟
conditional loss
;
\mathcal{L}_{G_{i}}=\underbrace{-\frac{1}{2} \mathbb{E}_{\hat{I}_{i} \sim P_{G_{i}}}\left[\log D_{i}\left(\hat{I}_{i}\right)\right]}_{\text {unconditional loss }}-\underbrace{\frac{1}{2} \mathbb{E}_{\hat{I}_{i} \sim P_{G_{i}}}\left[\log D_{i}\left(\hat{I}_{i}, s\right)\right]}_{\text {conditional loss }} ;
LGi=unconditional loss
−21EI^i∼PGi[logDi(I^i)]−conditional loss
21EI^i∼PGi[logDi(I^i,s)];
L
D
i
=
−
1
2
E
I
i
∗
∼
P
data
i
[
log
D
i
(
I
i
∗
)
]
−
1
2
E
I
^
i
∼
P
G
i
[
log
(
1
−
D
i
(
I
^
i
)
]
⏟
unconditional loss
+
−
1
2
E
I
i
∗
∼
P
data
i
[
log
D
i
(
I
i
∗
,
s
)
]
−
1
2
E
I
^
i
∼
P
G
i
[
log
(
1
−
D
i
(
I
^
i
,
s
)
]
⏟
conditional loss
\begin{aligned} \mathcal{L}_{D_{i}}= & \underbrace{-\frac{1}{2} \mathbb{E}_{I_{i}^{*} \sim P_{\text {data }_{i}}}\left[\log D_{i}\left(I_{i}^{*}\right)\right]-\frac{1}{2} \mathbb{E}_{\hat{I}_{i} \sim P_{G_{i}}}\left[\log \left(1-D_{i}\left(\hat{I}_{i}\right)\right]\right.}_{\text {unconditional loss }}+ \\ & \underbrace{-\frac{1}{2} \mathbb{E}_{I_{i}^{*} \sim P_{\text {data }_{i}}}\left[\log D_{i}\left(I_{i}^{*}, s\right)\right]-\frac{1}{2} \mathbb{E}_{\hat{I}_{i} \sim P_{G_{i}}}\left[\log \left(1-D_{i}\left(\hat{I}_{i}, s\right)\right]\right.}_{\text {conditional loss }} \end{aligned}
LDi=unconditional loss
−21EIi∗∼Pdata i[logDi(Ii∗)]−21EI^i∼PGi[log(1−Di(I^i)]+conditional loss
−21EIi∗∼Pdata i[logDi(Ii∗,s)]−21EI^i∼PGi[log(1−Di(I^i,s)]
与之前的AttnGAN、MirrorGAN等等相同,训练无条件损失以生成符合真实图像分布的高质量图像以欺骗鉴别器,训练条件损失以生成更好地匹配文本描述的图像。
为了生成逼真的图像,生成训练阶段(LG)和辨别训练阶段(LD)的最终目标函数分别定义为:
L
G
=
∑
i
=
0
m
−
1
(
L
G
i
+
λ
4
L
G
i
D
+
L
S
D
L
i
)
+
α
L
D
A
M
S
M
\mathcal{L}_{G}=\sum_{i=0}^{m-1}\left(\mathcal{L}_{G_{i}}+\lambda_{4} \mathcal{L}_{G_{i}^{D}}+\mathcal{L}_{S D L_{i}}\right)+\alpha \mathcal{L}_{D A M S M}
LG=∑i=0m−1(LGi+λ4LGiD+LSDLi)+αLDAMSM
L D = ∑ i = 0 m − 1 ( L D i + λ 5 L D i D ) \mathcal{L}_{D}=\sum_{i=0}^{m-1}\left(\mathcal{L}_{D_{i}}+\lambda_{5} \mathcal{L}_{D_{i}^{D}}\right) LD=∑i=0m−1(LDi+λ5LDiD)
五、实验
5.1、实验设置
数据集:CUB-Bird 和 MS-COCO;
评价指标:IS、FID、R-precision和人类评分;
5.2、实验结果
5.2.1、DR-GAN效果


5.2.2、泛化性研究
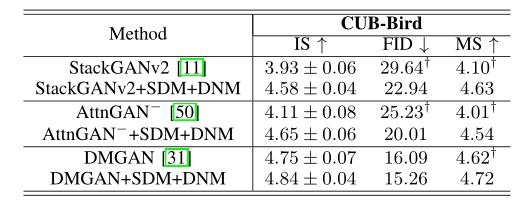
作者将SDM、DNM也融合到了其他多种GAN模型当中测试,实验取得较好效果:

5.2.3、消融研究
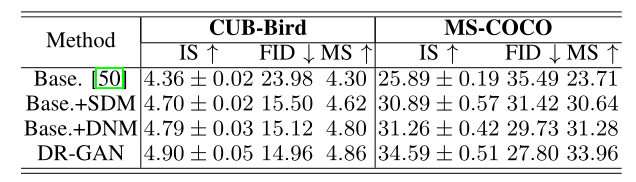

实验内容非常丰富,建议阅读原文。
六、创新点总结
作者提出了一种新的分布正则化生成对抗网络(DR-GAN)。DR-GAN包含两个新模块:语义分离模块(SDM)和分布规范化模块(DNM)
- 在SDM中,作者引入了一种空间自我关注机制,并提出了一种新的语义分离损失(SDL),以帮助生成器在捕获图像分布过程中更好地从文本和图像中提取关键信息。
- 在DNM中,作者将变分自动编码器(VAE)引入到基于GAN的T2I方法中,以规范潜在空间中的图像分布。
- 作者还提出了分布对抗损失(DAL),以将学习的分布与归一化潜在空间中的真实分布对齐。
💡 最后
我们已经建立了🏤T2I研学社群,如果你还有其他疑问或者对🎓文本生成图像很感兴趣,可以私信我加入社群。
📝 加入社群 抱团学习:中杯可乐多加冰-采苓AI研习社
🔥 限时免费订阅:文本生成图像T2I专栏
🎉 支持我:点赞👍+收藏⭐️+留言📝
相关文章
- 企业进销存仓库管理系统的设计与实现(论文+源码)_kaic
- 大学生志愿者管理信息系统设计与实现(论文+源码)_kaic
- 校园二手商品交易系统的设计与实现(论文+源码)_kaic
- Text to image论文精读 StackGAN:Text to Photo-realistic Image Synthesis with Stacked GAN具有堆叠生成对抗网络文本到图像合成
- Text to image论文精读GigaGAN: 生成对抗网络仍然是文本生成图像的可行选择
- 论文复现丨基于ModelArts进行图像风格化绘画
- 论文解读丨【CVPR 2022】不使用人工标注提升文字识别器性能
- 经典论文研读:LeNet —— Gradient-Based Learning Applied to Document Recognition
- [论文笔记] ULSD 阅读笔记
- 【计算机视觉】论文笔记:Ten years of pedestrian detection, what have we learned?
- 下载的论文乱码
- 计算机专业毕业设计(论文+系统)_kaic
- [含论文+源码等]javaweb网络考试系统的设计与实现
- CVPR 2017最佳论文解读:密集连接卷积网络
- B.图算法:图神经网络图学习之基于UniMP算法的论文引用网络节点分类任务[系列九]
- ImageNet 2017目标定位冠军论文:双路径网络
- 2022-12-23 数据库查询优化器相关论文
- 【论文精读】基于骨架行为识别—STGCN
- 机器学习论文和开源代码
- PostgreSQL设计之初的大量论文
- Neurons字幕组 | 2分钟看AI通过2D照片设计出面部3D模型(附论文下载)
- 阿里iDST ICCV 2017录用论文详解:基于层次化多模态LSTM的视觉语义联合嵌入
- 9 篇顶会论文解读推荐中的序列化建模:Session-based Neural Recommendation