
第8章 使用卷积进行泛化(3)
本部分是练习题和一些函数介绍。
本书第一部分的代码和一些用到的数据:
链接(阿里云盘):
「Pytorch DeepLearning」https://www.aliyundrive.com/s/wQmXYZSqyv4 点击链接保存,或者复制本段内容,打开「阿里云盘」APP ,无需下载极速在线查看,视频原画倍速播放。
1 练习题
1.将模型改为使用5x5的卷积核,并将kernel_size=5传递给nn.Conv2d构造函数。
a.这种改变对模型中的参数数量有影响吗?
b.这种改变是否会改善或降低过拟合?
c.kernel_size(1,3)作用?
d.模型性能如何?
前边讲过使用5x5的卷积核,如果想要保证输入图像的大小不变,就需要设置padding=2
设计模型:
import torch.nn.functional as F
class Net1(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(3, 16, kernel_size=5, padding=2)
self.conv2 = nn.Conv2d(16, 8, kernel_size=5, padding=2)
self.fc1 = nn.Linear(8*8*8, 32)
self.fc2 = nn.Linear(32, 2)
def forward(self,x):
out = F.max_pool2d(torch.tanh(self.conv1(x)),2)
out = F.max_pool2d(torch.tanh(self.conv2(out)),2)
out = out.view(-1,8*8*8)
out = torch.tanh(self.fc1(out))
out = self.fc2(out)
return out训练模型的代码与之前的完全相同:
import datetime
epoch_list = []
loss_list = []
acc_train_list = []
acc_val_list = []
def training_loop(n_epochs, optimizer, model, loss_fn, train_loader):
for epoch in range(1, n_epochs+1):
loss_train = 0.0
epoch_list.append(epoch)
for imgs, labels in train_loader:
outputs = model(imgs)
loss = loss_fn(outputs, labels)
l2_lambda = 0.001
l2_norm = sum(p.pow(2.0).sum() for p in model.parameters())
loss = loss + l2_lambda * l2_norm
optimizer.zero_grad()
loss.backward()
optimizer.step()
loss_train += loss.item()
if epoch == 1 or epoch%10 == 0:
print('{} Epoch {}, Training loss {}'.format(datetime.datetime.now(), epoch, loss_train/len(train_loader)))
loss_list.append(loss_train/len(train_loader))device = (torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu'))
print(f"Training on device {device}.")
train_loader = torch.utils.data.DataLoader(cifar2, batch_size=64,shuffle=True)
model = Net1().to(device=device)
optimizer = optim.SGD(model.parameters(), lr=1e-2)
loss_fn = nn.CrossEntropyLoss()
training_loop(
n_epochs = 100,
optimizer = optimizer,
model = model,
loss_fn = loss_fn,
train_loader = train_loader)
##查看准确率:
train_loader = torch.utils.data.DataLoader(cifar2, batch_size=64, shuffle=False)
val_loader = torch.utils.data.DataLoader(cifar2_val, batch_size=64, shuffle=False)
def validate1(model, train_loader):
for name, loader in [("train",train_loader)]:
correct = 0
total = 0
with torch.no_grad():
for imgs, labels in loader:
outputs = model(imgs)
_, predicted = torch.max(outputs, dim=1)
total += labels.shape[0]
correct += int((predicted == labels).sum())
accuracy = correct/total
acc_train_list.append(accuracy)
print("Accuracy_{}: {:.2f}" .format(name,accuracy))
validate1(model, train_loader)
def validate2(model, val_loader):
for name, loader in [("val",val_loader)]:
correct = 0
total = 0
with torch.no_grad():
for imgs, labels in loader:
outputs = model(imgs)
_, predicted = torch.max(outputs, dim=1)
total += labels.shape[0]
correct += int((predicted == labels).sum())
accuracy = correct/total
acc_val_list.append(accuracy)
print("Accuracy_{}: {:.2f}" .format(name,accuracy))
validate2(model, val_loader) 输出:

同样可以用之前介绍过的跳跃连接网络进行训练:
网络:
class Net2(nn.Module):
def __init__(self, n_chans1=32):
super().__init__()
self.n_chans1 = n_chans1
self.conv1 = nn.Conv2d(3, n_chans1, kernel_size=5, padding=2)
self.conv2 = nn.Conv2d(n_chans1, n_chans1//2, kernel_size=5, padding=2)
self.conv3 = nn.Conv2d(n_chans1//2, n_chans1//2, kernel_size=5, padding=2)
self.fc1 = nn.Linear(4*4*n_chans1//2, 32)
self.fc2 = nn.Linear(32, 2)
def forward(self,x):
out = F.max_pool2d(torch.relu(self.conv1(x)),2)
out = F.max_pool2d(torch.relu(self.conv2(out)),2)
out1 = out
out = F.max_pool2d(torch.relu(self.conv3(out))+out1,2)
out = out.view(-1,4*4*self.n_chans1//2)
out = torch.relu(self.fc1(out))
out = self.fc2(out)
return out结果:

很明显,过拟合了~
说实话第二题我没看懂题目啥意思。。。
2 一些之前涉及的函数
先来说一说为什么需要参数初始化的函数对参数进行初始化。
以fully connected network为例,同一层中的任意神经元都是同构的,也就是输入输出都是相同的,若将参数初始化为同样的值,那么无论前向传播还是反向传播的值也是完全相同的。
学习过程永远无法打破这种对称性,最终同一网络层中各个参数仍然是相同的。
因此,我们需要随机初始化神经网络的参数值,以打破这种对称性。
2.1 常见的参数初始化方式
这里主要介绍两种初始化函数:以下公式中的fan_in是权值张量中输入神经元的个数,fan_out是权值张量中输出神经元的个数,也就是下一层的输入神经元个数。
由于卷积神经网络不一定是全连接的,因此两者计算公式不同:![]()
![]()
假设四维tensor的size()是 (channels_in,channels_out,3,3)
fan_in=channels_in*3*3
fan_out=channels_out*3*3
(1) torch.nn.init.xavier_()
基本思想是维持输入和输出的方差一致,避免了所有的输出值都为0, 使用于任何激活函数
但是Xavier初始化在tanh中表现的很好, 在relu中表现很差。
对于每层网络来说保持输入和输出的方差一致,以避免所有输出值趋向于0,从而避免梯度消失现象。因此,Xavier的特点是:正向传播时,激活值的方差保持不变;反向传播时,关于状态值的梯度的方差保持不变。
正态化的Xavier初始化Xavier_normal():
从以0为均值,标准差为![]() 的截断正态分布中抽取样本。
的截断正态分布中抽取样本。
torch.nn.init.xavier_normal_(tensor, gain=1)均匀化的Xavier初始化 Xavier_uniform:
张量中填充的值来自于均匀分布U[-a,a],其中![]() 。
。
torch.nn.init.xavier_uniform_(tensor, gain=1)以上的gain是可缩放的因子。
Xavier初始化的缺点:
其推导过程是基于几个假设的:
(1)激活函数是线性的,因此不适用于ReLU,Sigmoid等非线性激活函数。
(2)激活值关于0对称,同样不适用于ReLU,Sigmoid等激活函数。
(2) torch.nn.init.kaiming_()
针对Xavier在relu表现不佳被提出。基本思想仍然从“输入输出方差一致性”角度出发,在Relu网络中, 假设每一层有一半的神经元被激活,另一半为0。一般在使用Relu的网络中推荐使用这种初始化方式。
因此,Kaiming的特点是:正向传播时,状态值的方差保持不变;反向传播时,关于激活值的梯度的方差保持不变。
正态化的Kaiming初始化He_normal:
张量中填充的值来自于以0为均值,标准差为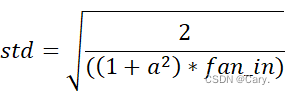 的截断正态分布。
的截断正态分布。
torch.nn.init.kaiming_normal_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’)其中,a代表该层后面一层的激活函数中负的斜率(默认为Relu函数,a = 0)
mode:默认为fan_in。使用fan_in保持weights的方差在前向传播中不变;使用fan_out保持weights的方差在反向传播中不变。
nonlinearity代表非线性激活函数。
均匀化的Kaiming初始化He_uniform:
张量中填充的值来自于均匀分布U[-a,a],其中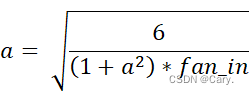 。
。
torch.nn.init.kaiming_uniform_(tensor, a=0, mode=‘fan_in’, nonlinearity=‘leaky_relu’)2.2 numel()函数
获取张量中一共包含多少个元素。
params = sum(p.numel() for p in list(net.parameters())) net.parameters()返回net网络中的参数。
params中即为net中的参数总个数。
相关文章
- 第8章 使用卷积进行泛化(2)
- 第8章 使用卷积进行泛化(1)
- 图卷积神经网络进行二分类实践(pytorch实现)
- CV-CNN-2015:GoogleNet-V2【首次提出Batch Norm方法:每次先对input数据进行归一化,再送入下层神经网络输入层(解决了协方差偏移问题)】【小的卷积核代替掉大的卷积核】
- 移动端/嵌入式-CV模型-2017:MobelNets-v1【利用“深度可分离卷积”来减少参数量】【分解卷积层:①各通道分别用3×3的核进行卷积;②各通道用1×1×C的核融合】【α、β调整模型大小】
- 全球首款人工智能性爱机器人,可进行感情交流,售价10000美元你会买吗?
- 利用卷积自编码器对图片进行降噪
- 利用卷积自编码器对图片进行降噪
- mysql排序,可以对统计的数据进行排序
- OpenStack并非科学项目,但仍须“对各组件进行整合”
- 使用binlog2sql针对mysql进行数据恢复
- iOS 对模型对象进行归档
- 体验Unity2017.2.0f3进行Vuforia开发
- logback在springBoot项目中的使用 springboot中使用日志进行持久化保存日志信息
- Tensorflow使用CNN卷积神经网络以及RNN(Lstm、Gru)循环神经网络进行中文文本分类
- PowerShell中进行文件读取,信息排序,分类计数。
- 利用云效度量功能进行质量运营和效率驱动提升
- 使用Boost Regex 的regex_search进行遍历搜索