
大象在飞吗?如何解决AI作画中的歧义问题 文本生成图像的消歧方法 Resolving Ambiguities in Text-to-Image Generative Models
自然语言天生包含固有的歧义。不同类型的歧义可归因于语法、词义、结构等等,这对文本生成图像的过程也会带来较大的歧义。
最近看到一篇文章研究如何解决文本到图像生成模型中的歧义问题,名为《Is the Elephant Flying? Resolving Ambiguities in Text-to-Image Generative Models》,作者来自于南加州大学信息科学研究所和Amazon Alexa AI-NU(研究语音助手的团队),发表于22年11月。
论文地址:https://arxiv.org/abs/2211.12503
本篇文章是阅读这篇论文的精读理解。
一、原文摘要
自然语言经常包含歧义,可能导致误解。虽然人类可以通过提出明确的问题和/或依靠上下文线索和常识知识来有效地处理歧义,但解决歧义对机器来说是出了名的困难。在这项工作中,我们研究了文本到图像生成模型中出现的歧义。我们策划了一个基准数据集,涵盖了这些系统中出现的不同类型的歧义。然后,我们提出了一个框架,通过征求用户的澄清来减轻系统提示中的歧义。通过自动和人工评估,我们展示了我们的框架在存在歧义的情况下生成符合人类真实意图的图像。
二、文本的歧义现象
由于对同一话语的潜在多重解释,自然对话包含固有的歧义。文本生成图像时,产生的不同类型的歧义可归因于:
- 语法:如an elephant and a bird flying,可以表示为有一只大象,然后有一只小鸟在飞,也可以表示为一只大象和一只小鸟都在飞行;
- 一词多义:如a picture of cricket,可以表示为一幅板球运动的图像,也可以表示为一副蟋蟀的图像;
- 模糊不清:如doctor talking to a nurse,模型应该生成医生和护士的性别应当是什么?
- …

虽然人类可以通过提出明确的问题和/或依靠上下文线索和常识知识来有效地处理歧义,但对机器来说解决歧义非常困难。而很多模型可能会导致不符合期望的结果和糟糕的用户体验。特别是,由于不明确而导致的歧义可能会导致有偏见的结果,并可能影响基础模型的公平性(比如性别、肤色…)。
三、为什么提出?
人类倾向于通过提出澄清问题、依赖其他形式的方式(如视觉)、使用上下文线索和利用常识和/或外部知识来源来解决歧义,比如人类画师在作画时,遇到歧义就会询问或者判断,询问大象是否在飞行,对方的cricket表示蟋蟀还是板球,画的人物性别选择等等,
如果在文本生成图像前插入一个语言模型,模型能够意识到这些歧义,并为用户提供更明确地指定其意图的机会,可以提高用户满意度, 并且引导T2I模型生成更多样更准确的图像。
受到这个启发,作者在文本到图像生成模型之上加入了基于语言模型的提示消歧过滤器。该过滤器能够提出澄清问题或生成不同的可能设置,这些设置稍后将通过人类交互解决。最终,消歧过滤器帮助文本到图像模型识别用于图像生成的单个视觉设置。
为了达成这个想法,更好地理解当前文本到图像生成模型的弱点,并评估提出的缓解框架的有效性,作者还策划了一个基准数据集,该数据集包含涵盖与文本到图像模型特别相关的不同类型的歧义提示。我们还提出了新的自动评估程序,以评估文本生成模型与图像生成模型中各代的可信度,并将其与人类评估进行比较。
主要工作如下:
- 引入了文本到图像模糊基准(TAB)数据集,该数据集包含不同类型的模糊提示以及不同的视觉设置。
- 提出了新的自动评估程序来评估文本到图像模型中的歧义。
- 提出了一种可以应用于任何文本到图像模型的消歧框架,使用基准数据集和度量来评估DALL-E的多种变体以及歧义消除框架。
四、方法
作者的提出的消除歧义框架。通过(1)语言模型生成澄清问题,该澄清问题将通过人工提供的答案来解决,或者(2)语言模型产生不同的可能视觉设置,并且人工代理选择期望的设置,来消除初始歧义提示。
将视觉设置/解释定义为不同可能视觉场景的文本描述。最终消除歧义的提示稍后将提供给下游文本到图像生成模型。
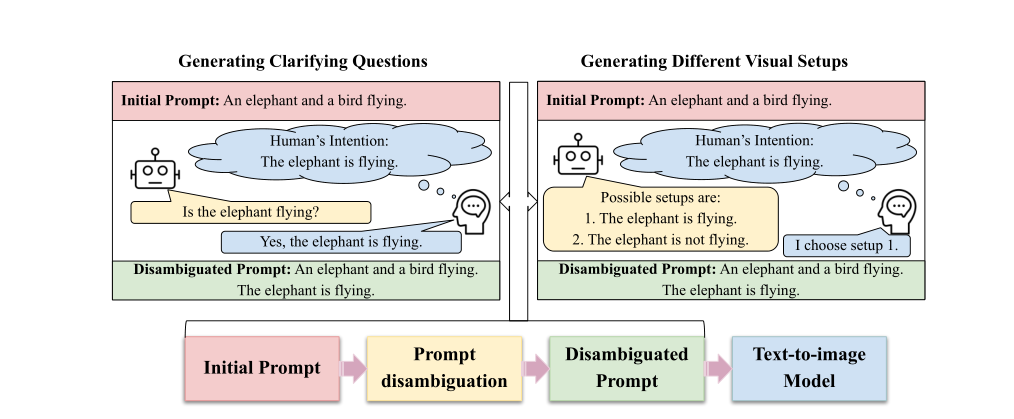
首先通过(1)语言模型生成澄清问题,该澄清问题将通过人工提供的答案来解决,或者(2)语言模型产生不同的可能视觉设置,并且人工选择期望的设置,来消除初始歧义。
如由上图文本为:an elephant and a bird flying,将其输入到1)生成澄清问题模块,机器生成澄清问题如:大象在飞吗?人工回答:在飞,生成无歧义的提示文本:一只大象和一只鸟在飞翔。大象在飞翔。 或者将其输入到2)不同的视觉设置的生成模块。机器生成可以消除提示歧义的不同的可能设置:1.大象正在飞行。2.大象没有飞。人工选择1,生成无歧义的提示文本:一只大象和一只鸟在飞翔。大象在飞翔。
消除歧义的框架涉及到GPT、OPT等语言模型,因为与文本生成图像主流网络相关性不高,此处不展开,感兴趣可以看原文了解。
作者在此基础上还额外设计了文本到图像模糊基准(TAB)数据集,该数据集包含不同类型的模糊提示以及不同的视觉设置,利用数据集评估语言模型在每个歧义提示生成一个澄清问题、每个提示生成多个澄清问题或每个提示生成多种可能的视觉解释方面的能力。
五、实验
作者在OpenAI的DALL-E和DALL-E Mega模型中证明了所提出的消歧框架在生成更准确真实的图像方面的有效性,这些图像根据人类的评估和意图更加一致。

第一行是DALL-E生成的图像,第二行是DALL-E Mega生成的图像,左边是原始并存在歧义的,右边是消歧后,输入模型生成的图像。
总结
在这项工作中,作者研究了即时歧义在文本到图像生成模型中的作用,并提出了一个消歧义框架,以帮助该模型生成更忠实、更符合用户意图的图像。
作者首先建立了一个由不同类型的歧义组成的基准数据集。然后测量了各种语言模型通过人类交互产生消除歧义信号的能力,方法是生成清晰的问题,或者利用少数镜头学习的概念直接生成多种可能的视觉设置。
在通过语言模型与人类交互获得信号并执行不同的自动和人类评估之后,输入文本到图像生成模型来测量图像生成的一致性,该模型向这些系统提供了歧义消除的效果。
💡 最后
我们已经建立了🏤T2I研学社群,如果你对Dreamfields和DreamFusion还有其他疑问或者对🎓文本生成图像很感兴趣,可以私信我加入社群。
📝 加入社群 抱团学习:中杯可乐多加冰-采苓AI研习社
🔥 限时免费订阅:文本生成图像T2I专栏
🎉 支持我:点赞👍+收藏⭐️+留言📝
相关文章
- win10中打开SQL Server配置管理器方法
- js apply/call/caller/callee/bind使用方法与区别分析
- 【转】snprintf()函数使用方法
- 运维前线:一线运维专家的运维方法、技巧与实践2.3 Puppet及Facter介绍
- MATLAB 数据分析方法(第2版)2.3 数据变换
- 干货丨乔俊飞:面向污水处理过程控制的多目标智能优化方法研究
- 知网上下载硕博论文为PDF格式的方法
- OC学习篇之---类的初始化方法和点语法的使用
- AI创作教程之Stable Diffusion 与Photoshop融合使用(含安装方法)
- html 页面内锚点定位及跳转方法总结
- Delphi调用爷爷类的方法(自己构建一个procedure of Object)
- 【Vue】vue基础语法——computed计算、watch监听、class和style,最后回顾JavaScript里面的常用方法(vue学习day03)
- 再探 游戏 《 2048 》 —— AI方法—— 缘起、缘灭(8) —— 2021年9月SOTA的TDL算法——《Optimistic Temporal Difference Learning for 2048》——完结篇
- 再探 游戏 《 2048 》 —— AI方法—— 缘起、缘灭(7) —— Python版本实现的《2048》游戏的TDL算法
- 再探 游戏 《 2048 》 —— AI方法—— 缘起、缘灭(4) —— state-of-the-art
- Codeforces C. Pattern 412 解决问题的方法
- Java程序猿的JavaScript学习笔记(5——prototype和Object内置方法)
- Ubuntu下deb包的安装方法
- MaxCompute平台非标准日期和气象数据处理方法--以电力AI赛为例