
Clickhouse 1亿条20列表的性能测试
建表
下面建了一个1亿行20列,随机值的表用于测试
-- 随机表
CREATE TABLE generate_engine_table (
id UInt64,
i8 Int8, i16 Int16, i32 Int32, i64 Int64,
ui8 UInt8, ui16 UInt16, ui32 UInt32, ui64 UInt64,
f32 Float32, f64 Float64,
s1 String, s2 String, s3 String,
s4 String, s5 String, s6 String, s7 String, s8 String,
date DateTime
) ENGINE = GenerateRandom(1,5,3);
-- 测试用表(预计填充1亿行20列数据)
CREATE TABLE test_100000000(
id UInt64,
i8 Int8, i16 Int16, i32 Int32, i64 Int64,
ui8 UInt8, ui16 UInt16, ui32 UInt32, ui64 UInt64,
f32 Float32, f64 Float64,
s1 String, s2 String, s3 String,
s4 String, s5 String, s6 String, s7 String, s8 String,
date DateTime
) ENGINE = ReplacingMergeTree() PARTITION BY toYYYYMM(date) PRIMARY KEY id ORDER BY id;
调整最大内存
使用 free -m 查看当前可以使用的最大内存。然后修改 /etc/clickhouse-server/users.xml 将 max_memory_usage 改为 最大可使用的内存
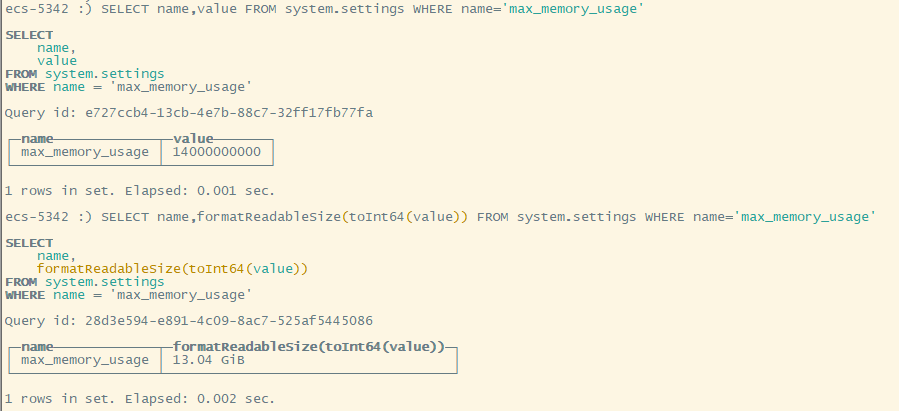
使用 clickhouse-client 命令进入交互模式,使用 SELECT name,value FROM system.settings WHERE name = 'max_memory_usage' 确认最大可以使用的内存
插入
准确的说,是从另一个数据库导入数据,需要较多的磁盘I/O
INSERT INTO test_100000000 SELECT * FROM generate_engine_table LIMIT 100000000;
0 rows in set. Elapsed: 332.193 sec. Processed 100.66 million rows, 14.70 GB (303.02 thousand rows/s., 44.24 MB/s.)

查询
SELECT * FROM test_100000000 LIMIT 200;
200 rows in set. Elapsed: 1.168 sec. Processed 8.19 thousand rows, 1.20 MB (7.01 thousand rows/s., 1.02 MB/s.)


条件判断
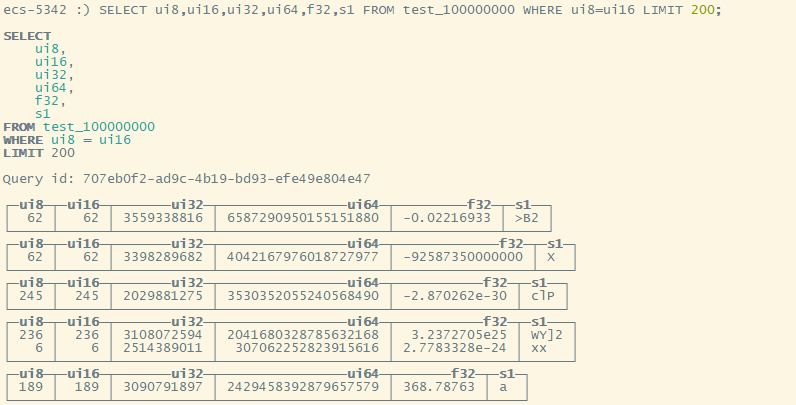
SELECT ui8,ui16,ui32,ui64,f32,s1 FROM test_100000000 WHERE ui8=ui16 LIMIT 200;
200 rows in set. Elapsed: 0.426 sec. Processed 12.45 million rows, 79.18 MB (29.18 million rows/s., 185.64 MB/s.)

分组汇总
汇总单个元素
求最大值
SELECT MAX(f64) FROM test_100000000 GROUP BY ui8 LIMIT 200;

求平均
SELECT AVG(ui64) FROM test_100000000 GROUP BY ui8 LIMIT 200;
200 rows in set. Elapsed: 0.647 sec. Processed 100.00 million rows, 900.00 MB (154.54 million rows/s., 1.39 GB/s.)

汇总多个元素
首次执行
SELECT AVG(i64), MAX(f32), MIN(f64) FROM test_100000000 GROUP BY i8 LIMIT 200;
200 rows in set. Elapsed: 20.006 sec. Processed 100.00 million rows, 2.10 GB (5.00 million rows/s., 104.97 MB/s.)

再次执行
由于首次执行后,clickhouse会将磁盘上的数据解压,并加载到内存中,然后并为它们建立内存索引,因此当再次查询相关字段时,速度会快很多
SELECT AVG(i64), MAX(f32), MIN(f64) FROM test_100000000 GROUP BY i8 LIMIT 200;
200 rows in set. Elapsed: 1.218 sec. Processed 100.00 million rows, 2.10 GB (82.08 million rows/s., 1.72 GB/s.)

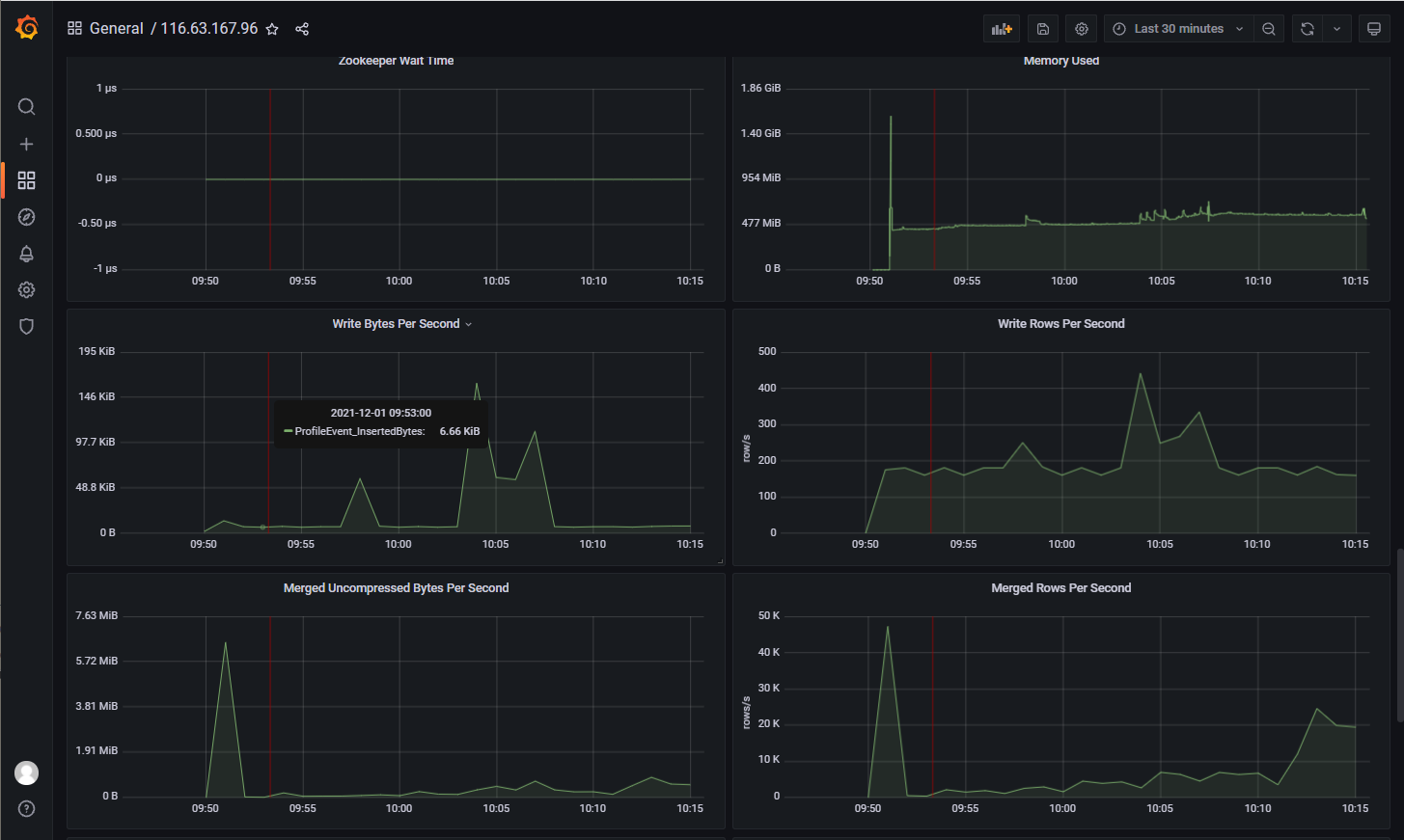
复杂SQL
SELECT * FROM
(SELECT i8, i16, AVG(i16) AS avg_i16, MAX(f32) FROM test_100000000 GROUP BY i8,i16 LIMIT 200) AS a
LEFT JOIN
(SELECT i8, i16, i32, i64 FROM test_100000000 WHERE i16 IN
(SELECT i16 FROM test_100000000 WHERE f32 < 100 AND f64 > -100 LIMIT 200)
) AS b
ON a.i16 = b.i16 WHERE b.i32 < 1000 LIMIT 200;
200 rows in set. Elapsed: 5.822 sec. Processed 200.08 million rows, 2.20 GB (34.37 million rows/s., 377.89 MB/s.)
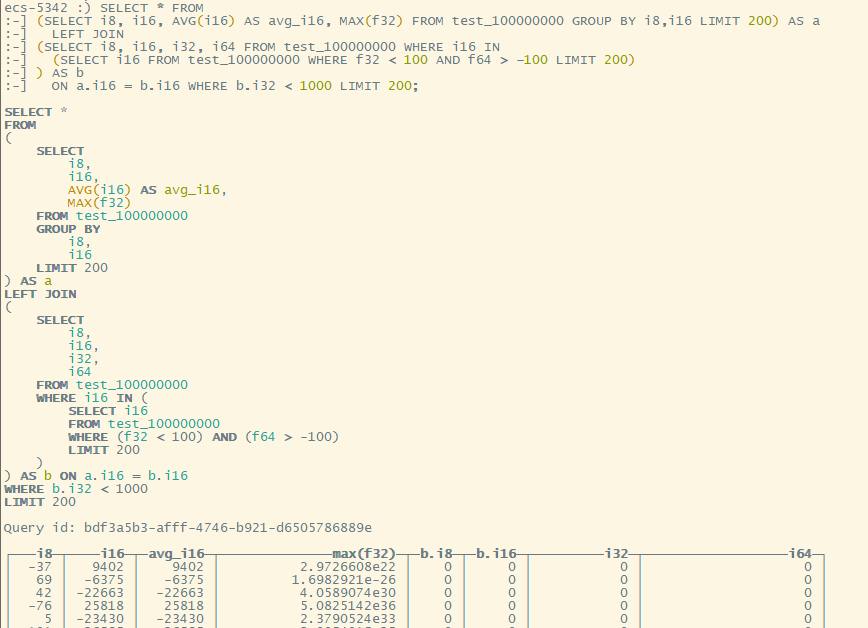

并发
并发测试需要用到 clickhouse-client 工具和 shell 知识。
使用 clickhouse-client 发送单条sql,然后使用 shell,让命令循环并且并行发送。最后,查看执行时间与统计信息
这里要创建两个文件 mysql.sql(用来保存sql语句),concurrent.sh(用来并行执行sql语句)
- mysql.sql
(1)简单sql
WITH rand32() % 200 AS rand_200
SELECT ui8,ui16,s1,s2,s3 FROM test_100000000 WHERE ui8=rand_200 LIMIT 200;
(2)复杂sql
WITH rand32() % 50 AS rand_50, rand32() % 300 AS rand_300, rand32() % 3000 AS rand_3000
SELECT * FROM
(SELECT i8, AVG(i32) AS avg_i32, count(1) AS cnt FROM
(SELECT i8, i32 FROM test_100000000 WHERE i32 < rand_300 LIMIT 1000)
GROUP BY i8 HAVING cnt > 0 LIMIT 50) AS a
INNER JOIN
(SELECT i8, i32, s1, s2 FROM test_100000000 WHERE i32 < rand_3000 AND i32 > -1 * rand_300 LIMIT 1000) AS b
ON a.i8 = b.i8 LIMIT 200;
- concurrent.sh
#!/bin/bash
echo "==============================================="
echo 当前文件名:$0
echo 循环次数为:$1
echo 是否要回显:$2(0表示不要,1表示要)
str=$(cat mysql.sql)
echo -e "命令为:\n$str\n"
start=$[$(date +%s%N)/1000000]
for i in $(seq 1 $1)
do
{
start0=$[$(date +%s%N)/1000000]
if [ $2 = 0 ]; then
clickhouse-client --query "$str" &>/dev/null
else
clickhouse-client --query "$str" & tail -n 1
fi
end0=$[$(date +%s%N)/1000000]
echo $i.执行耗时: $(($end0-$start0)) ms
}&
done
wait
end=$[$(date +%s%N)/1000000]
echo sql执行总耗时: $(($end-$start)) ms
echo '=============================================='
chmod +x concurrent.sh 为其加上可执行权限,然执行该命令
简单sql
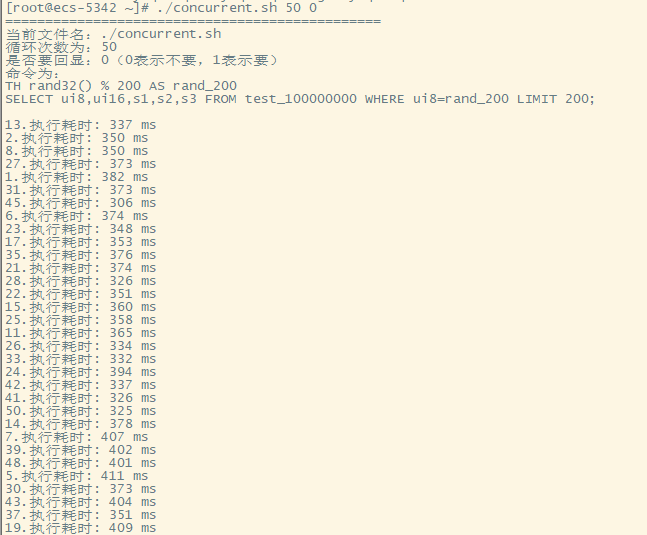
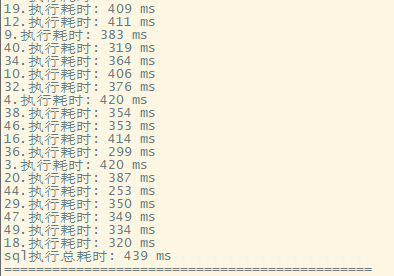
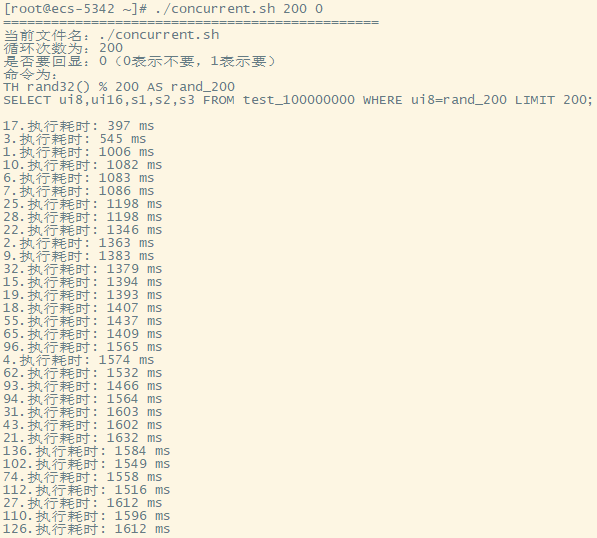
简单的sql,1亿行数据,500个并发同时查询不是问题
10个并发
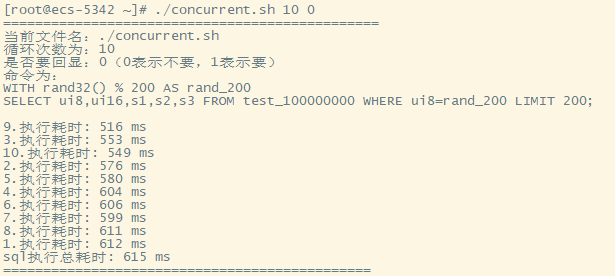
50个并发
- 首次执行
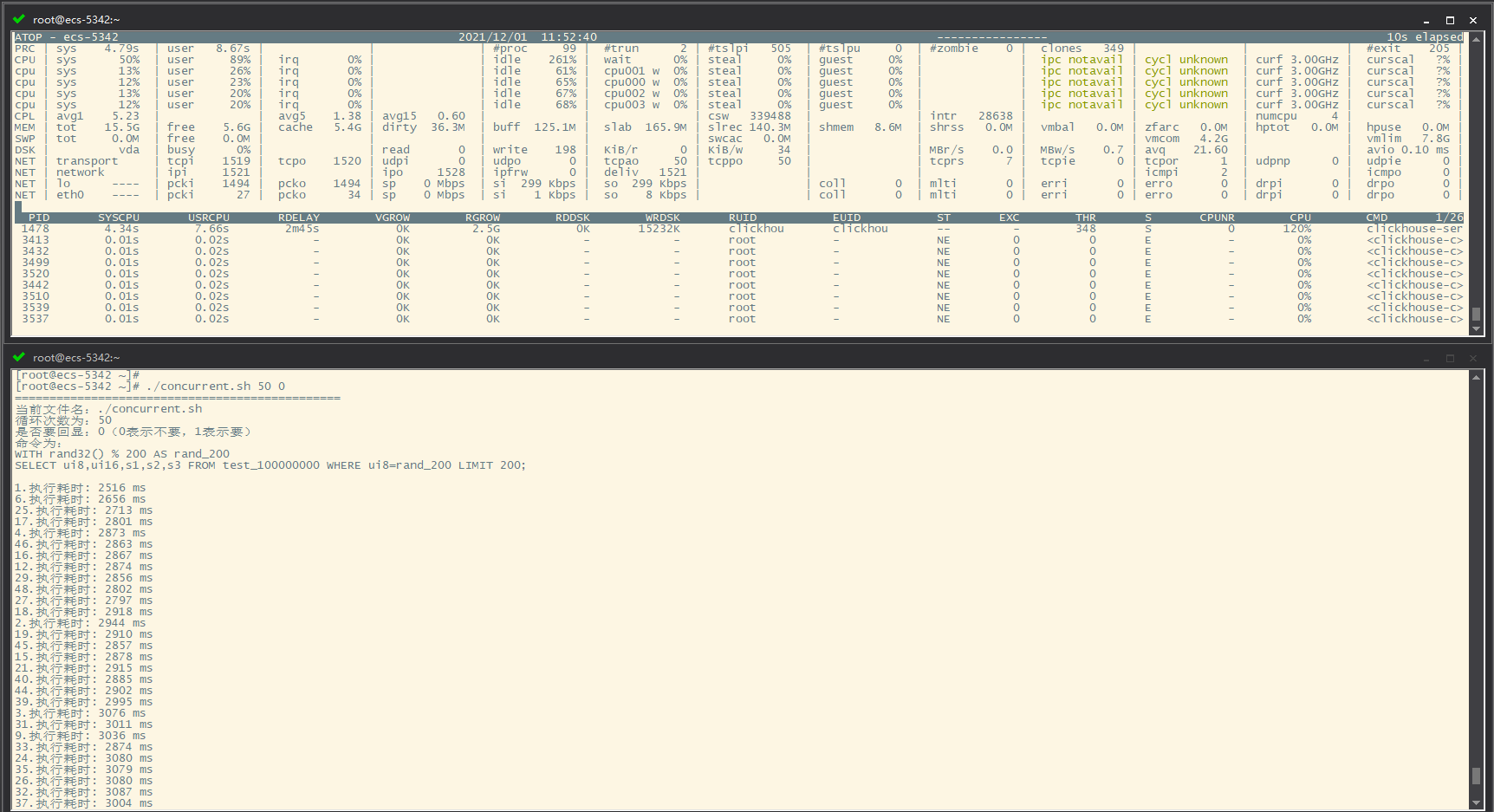

- 再次执行
200个并发
300 个并发
400个并发
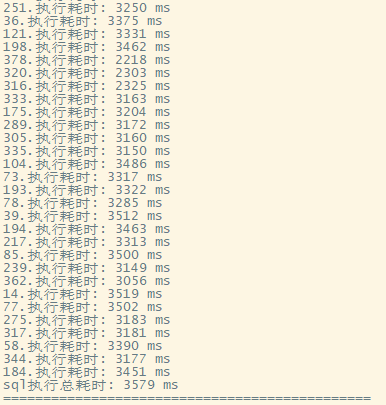
复杂sql
复杂的查询语句,同时10个并发是极限(同时对SQL也有着一定的要求)
10个并发
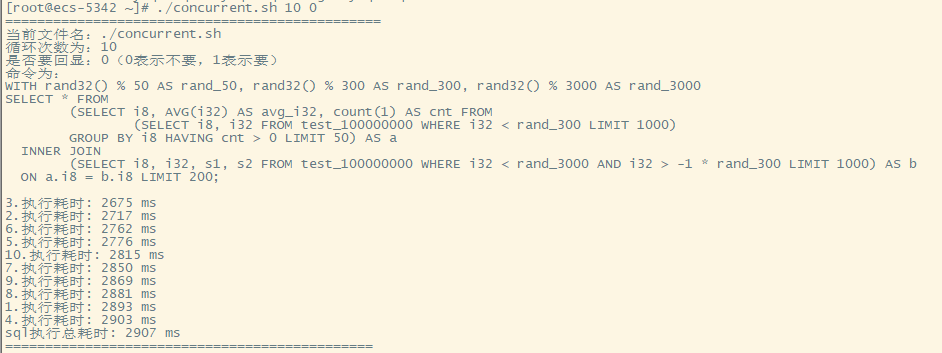
50个并发
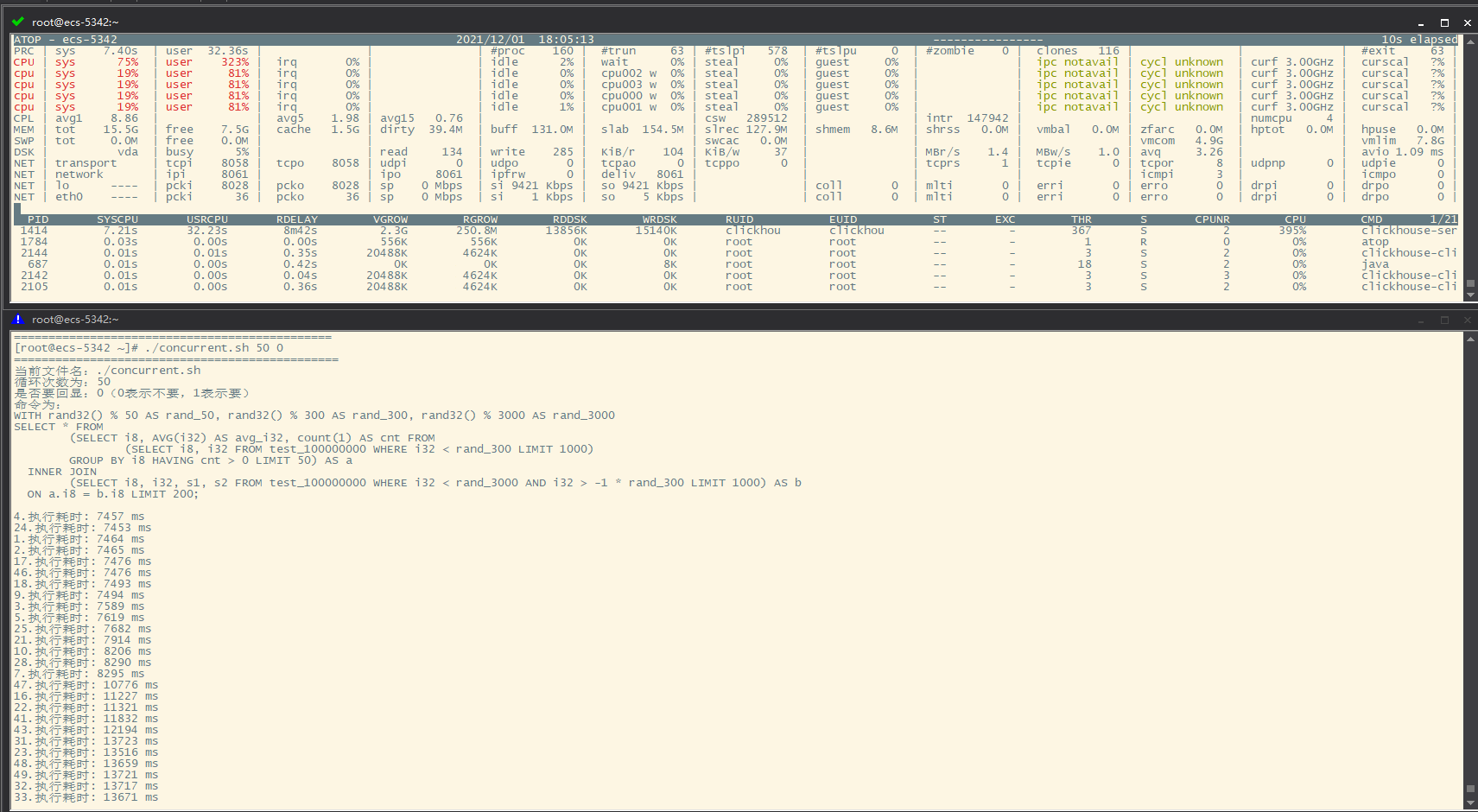
从 atop 这个监控命令可以看到,多条复杂的查询语句同时执行时,4核CPU基本被吃满

总结
- 正常查询语句的瓶颈在于CPU,尤其是并发多时
- 大量插入时(超过 100万行 或 255 MB),磁盘I/O会成为瓶颈(我们租用服务器时,一般用的是华为云的SAS硬盘,速度在 150MB/s 左右)

相关文章
- Go语言的list包(列表)链表
- Android Listview SimpleAdapter的使用完整示例(实现用户列表)
- react 项目实战(五)渲染用户列表
- 渗透测试-2022红队必备工具列表总结
- Vue - 搜索关键字标红高亮(用户输入关键词搜索后,在搜索结果的列表标题上匹配并标红加粗)怎么使内容文本标红高亮的最详细教程,Nuxt.js uni-app 也适用,搜索功能及搜索结果关键字高亮源码
- 腾讯Android自动化测试实战3.3.2 ListView列表遍历
- 【Python】【排序】字符串列表排序/题目排序/首字母排序
- 华为联机对战服务玩家快速匹配后,不同玩家收到的同一房间内玩家列表不同
- 展示华为游戏的排行榜列表,提示“无法连接服务器,请点击屏幕重试”
- 实现列表二级展开/收起/选择
- 仿网易/QQ空间视频列表滚动连播炫酷效果
- ---html链接-表格table-列表ul-布局div-表单form-input属性-多层嵌套的跳转-实体H5-新增属性
- dedecms调用【同级或下级】栏目的方法,channelartlist在列表页和内容页调用【同级或下级】栏目文章
- Python项目列表
- [Acwing]840. 模拟散列表
- 力扣解法汇总599-两个列表的最小索引总和
- python中强大优雅的列表推导表达式
- Python列表推导式使用举例
- 164、【动态规划】leetcode ——213. 打家劫舍 II:环形列表线性化(C++版本)
- 共谋节点两个单列表
- 定义函数,给定一个列表作为函数参数,将列表中的非数字字符去除