
基于DataHub采集数据的营销报告分析
本案例是基于阿里云上的DataHub收集营销数据,并通过MaxCompute对营销数据进行分析。下面主要介绍如何用DataHub收集营销数据,以及在MaxCompute中如何对数据进行分析。
1 DataHub采集数据
阿里云的datahub提供了接口可将项目中产生的数据同步到Datahub中,并实时同步到MaxCompute项目对应的表中。下面介绍如何利用DataHub收集数据。
1.1 创建项目
DataHub地址为https://datahub.console.aliyun.com/datahub。页面如下:
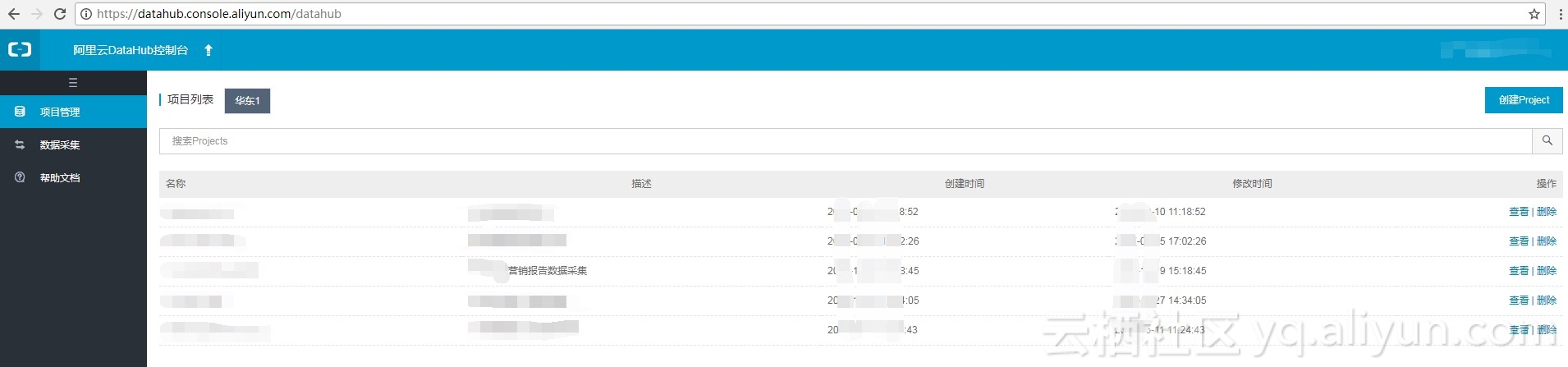
点击创建project按钮,可创建项目,窗口如下:
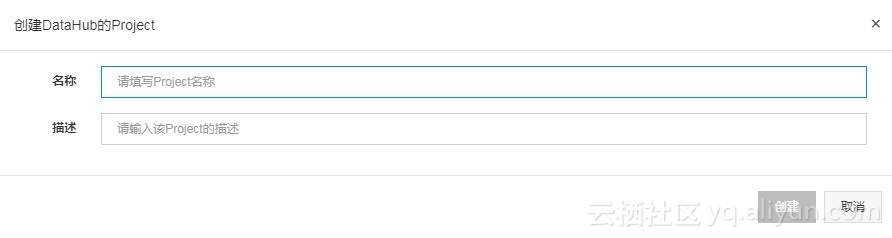
输入名称和描述之后点击创建可新建一个项目,刷新后会出现在项目列表中。点击查看可设置项目的各种信息。
1.2 创建Topic
点击项目后的查看按钮,进入如下页面:
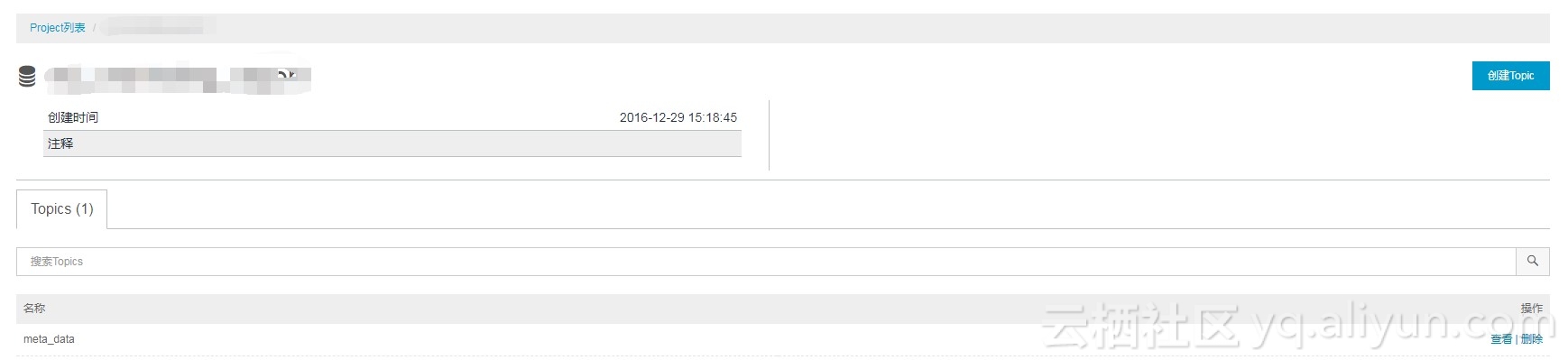
创建Topic设置同步数据到MaxCompute的数据表中。点击创建Topic,弹出页面如下:
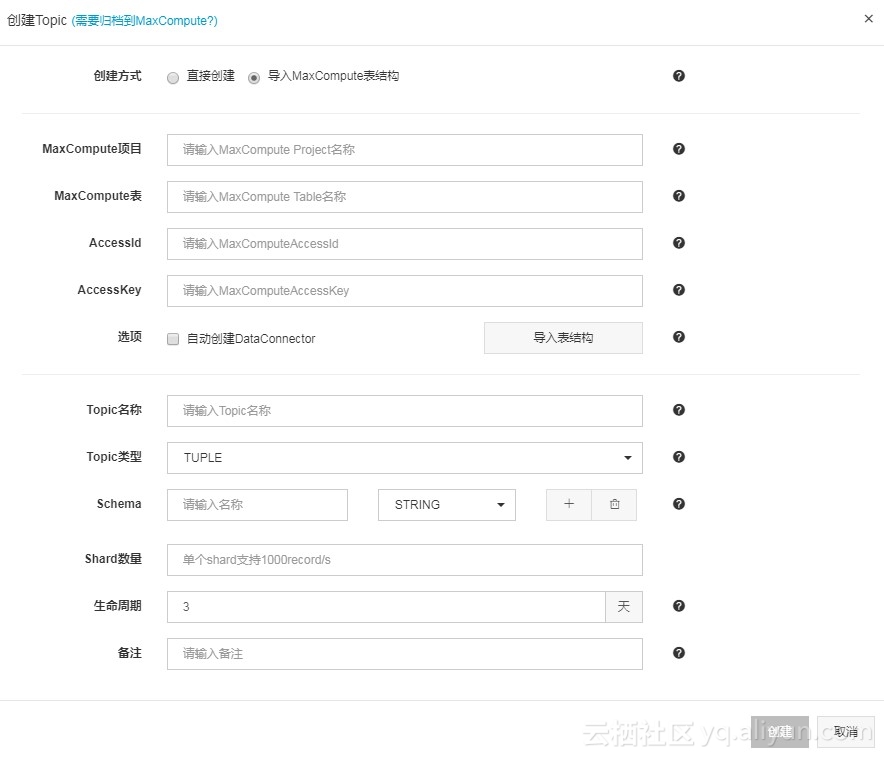
有两种创建方式,直接创建和导入MaxCompute表结构。第一种方式需要自己填写表结构,比较麻烦,如果在MaxCompute中已经创建好了表,推荐使用导入MaxCompute表结构。按提示填写完信息即可创建成功(提示:备注也要写,否则创建按钮不可点击)。创建完成后会出现在Topic列表中。
此时在DataHub中的配置已经完成,点击Topic后面的查看可查看配置的各种信息。如下图:

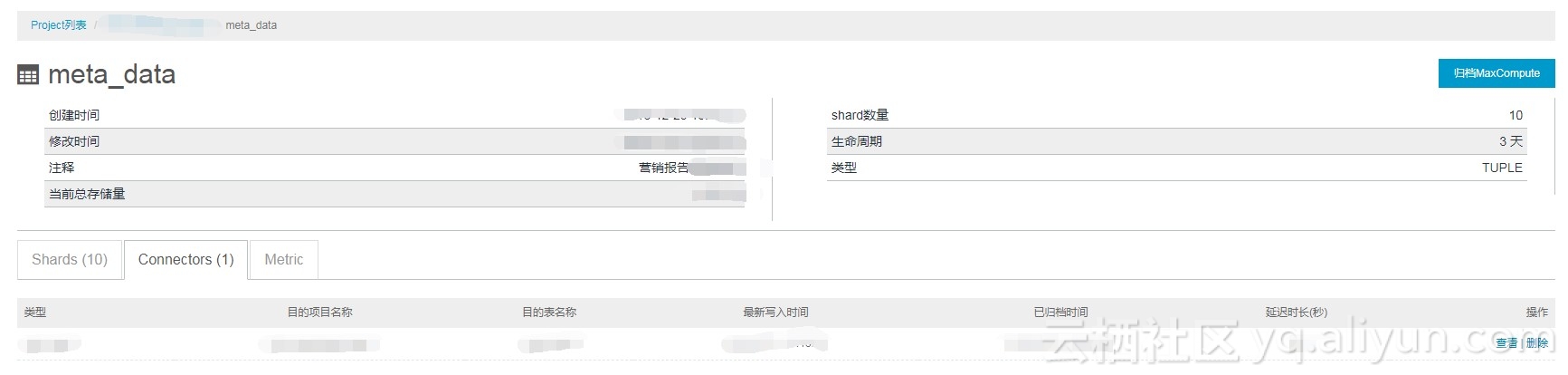
点击第二张图片Connectors中的查看,弹出如下页面:
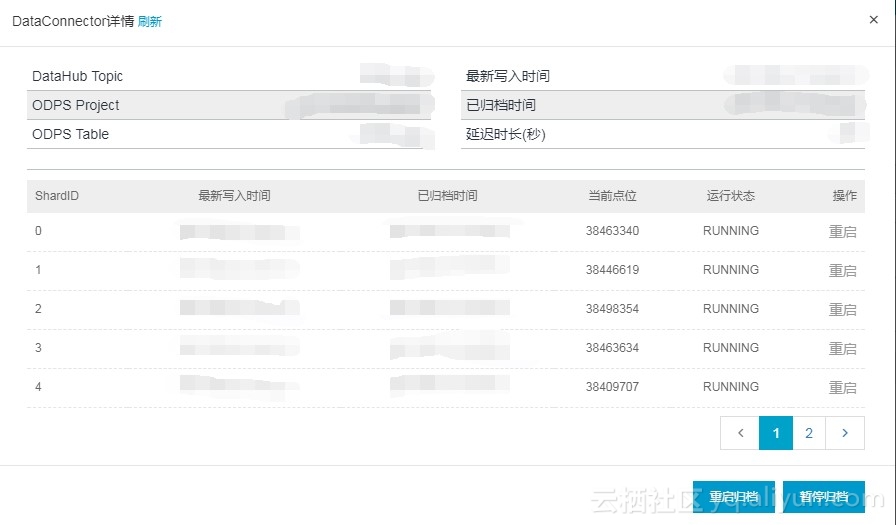
重启归档和暂停归档可设置是否将DataHub中的数据同步到MaxCompute中。
注:创建Topic的时候会设置生命周期,如生命周期为三天,表示DataHub只保存三天的数据。超过三天的数据会被删除,且不可恢复。因此需经常看看DataHub是否因未知的原因而归档失败了。因为当归档失败时,DataHub没有失败自动重启的功能,此时会一直处于失败状态,数据无法归档到MaxCompute中,超过三天数据会丢失(也可将生命周期设置的长一些)。
1.3 数据采集
DataHub中提供了很多工具将本地项目中的数据同步到DataHub中。提供的工具如下:

点击需要用的工具即可进入帮助文档页面,按帮助文档的步骤进行操作即可。
2 利用MaxCompute进行数据分析
用MaxCompute进行数据分析,首先需要创建odps项目,其产品名如下:

创建成功后的页面如下:
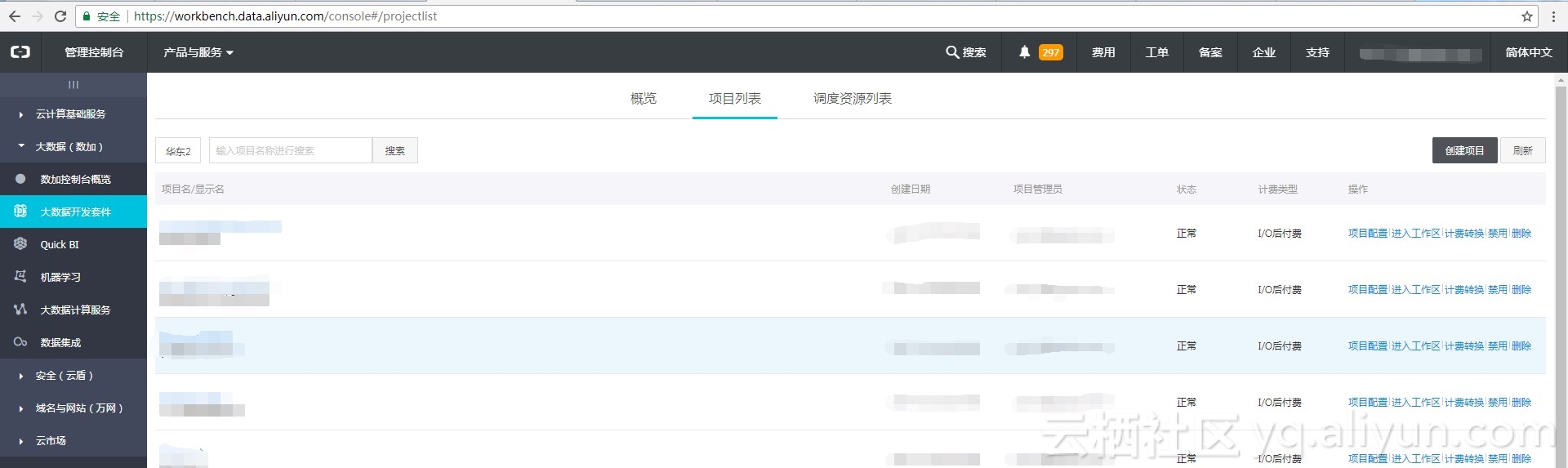
点击项目列表中的项目名即可进入项目空间(需操作不同项目空间的表需要再表前加上项目名,用“.”连接)。项目空间如下:
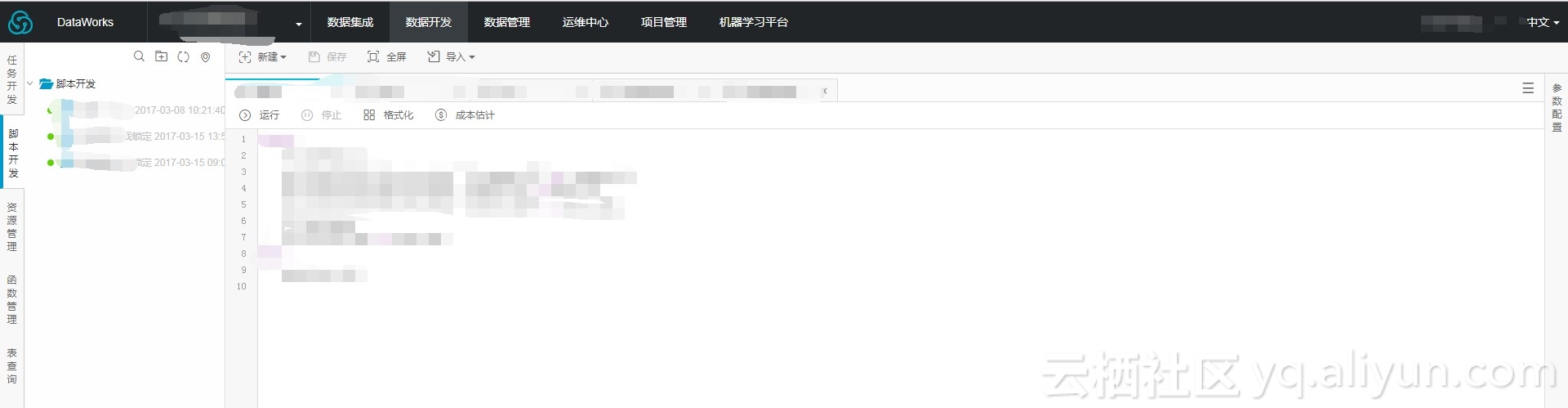
任务开发:可创建一些定时任务,定时运行一些数据同步任务、机器学习实验、Sql语句等。
脚本开发:可写一些Sql语句对项目空间的表进行分析。
函数管理:提供了一些系统自带的函数。
表查询:可查看MaxCompute中的所有表,查看表结构及预览部分数据。
下面介绍一下本案例的营销报告所做的工作,主要是新建一个任务,在任务中添加一些sql语句节点,定时每天跑这些任务。
2.1 创建任务
点击新建,出现如下页面:
点击新建任务,出现如下页面:
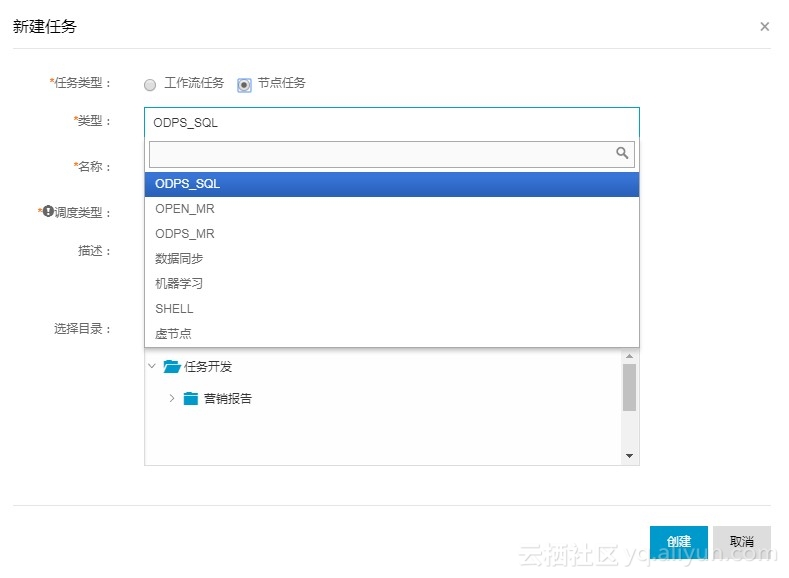
分为工作流任务和节点任务,节点任务有如图所示的几种任务类型,顾名思义,节点任务就是只能执行一种任务类型的一个任务。而工作流任务是将节点任务连接成一个工作流,可让多个节点任务一起执行。我们这里创建工作流任务,其页面如下:
创建成功后的页面如下:

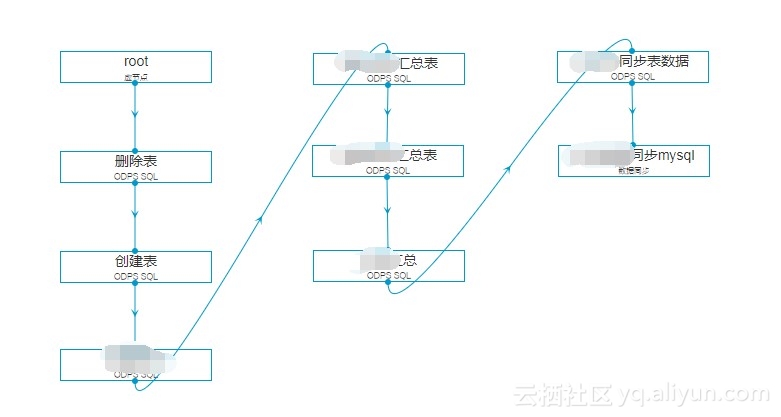
左边提供了节点组件。本案例的营销报告工作流如下:
鼠标选择节点组件,点击右键会出现设置节点信息的菜单,如下:
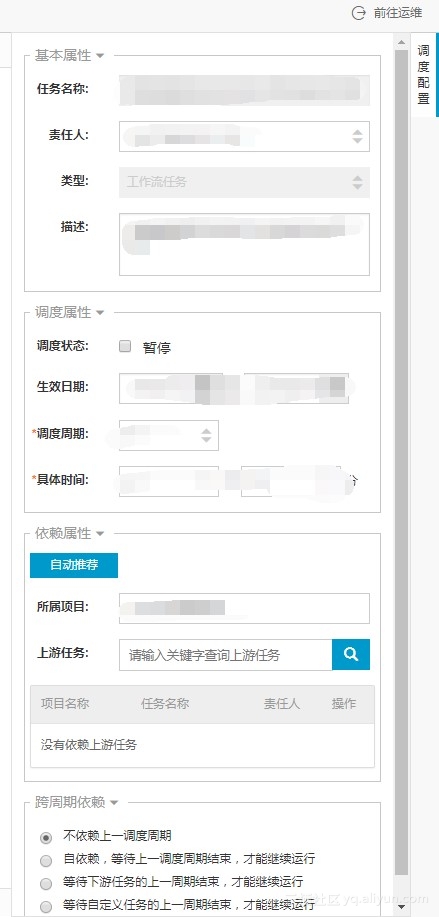
任务配置完成后,可在右边的调度配置中配置调度信息,如下:
各种信息都设置后之后,点击菜单栏中的保存、提交即可定时执行任务,菜单栏如下:

其中,测试运行可测试任务配置的是否有问题。
2.2 同步数据到RDS数据库
用MaxCompute平台分析后的数据可同步存放到RDS数据库中,然后在本地项目即可获取分析结果。
2.2.1 新建数据源
同步数据到RDS中需要新建数据源,将MaxCompute的项目与RDS数据库连通起来。数据源在数据集成中创建,页面如下:

点击新建数据源按提示创建即可。
2.2.2 创建数据同步任务
本案例是利用DataHub采集营销数据,然后利用MaxCompute对数据定时进行分析,然后同步到RDS数据库中,供本地项目获取结果。
#MaxCompute最佳实践#
阿里云热门场景上云解决方案,助力企业上云/数据/营销等多场景业务上云 本文介绍了阿里云官方推出的一些常见上云解决方案,包含高并发云上架构解决方案、Web与移动App云上部署解决方案、企业数据存储与备份解决方案、企业标准版数据分析解决方案、智能客服解决方案、视觉人像通用技术解决方案等
使用 Databricks 进行营销效果归因分析的应用实践【Databricks 数据洞察公开课】 本文介绍如何使用Databricks进行广告效果归因分析,完成一站式的部署机器学习,包括数据ETL、数据校验、模型训练/评测/应用等全流程。
数据治理方案技术调研 Atlas VS Datahub VS Amundsen 数据治理意义重大,传统的数据治理采用文档的形式进行管理,已经无法满足大数据下的数据治理需要。而适合于Hadoop大数据生态体系的数据治理就非常的重要了。 大数据下的数据治理作为很多企业的一个巨大的难题,能找到的数据的解决方案并不多,但是好在近几年,很多公司已经进行了尝试并开源了出来,本文将详细分析这些数据发现平台,在国外已经有了十几种的实现方案。
解决方案应用实例 |借助阿里云数据智能,李宁实现全域精准营销 李宁借助阿里云数据智能,实现了与用户全新互动方式,大数据精准触达消费者支持业务快速创新,从而实现全链路数据拉通,全域精准营销。
函数计算FC助力游戏群采集营销数据滴水不漏 稳定、高可靠的采集数据并回传以及成本最优化是客户的核心诉求,为了同时实现高性能和成本最优化,游戏群选择阿里云函数计算FC为该业务场景兜底。
相关文章
- 中国大数据市场规模分析及预测
- 学习各种预测数据的方法
- vue框架,数据展示和分析,报告管理界面
- 32-第3章 数据链路层--抓包分析数据帧格式-OSI一图了然-小结
- nginx重新整理——————分析log数据[六]
- FastAdmin控制管理员只显示自己添加的数据
- Python数据挖掘之决策树DTC数据分析及鸢尾数据集分析
- 【STM32H7的DSP教程】第47章 STM32H7的IIR带阻滤波器实现(支持逐个数据的实时滤波)
- 一段简单的JavaScript代码,模拟Angular数据绑定信息的解析和替换
- NLP之TEA之NB/LoR:基于NB和LoR算法对Kaggle IMDB影评数据集(国外类似豆瓣电影)情感分析进行分类
- Dataset之图片数据增强:基于TF实现图片数据增强(原始的训练图片reshaped_image→数据增强→distorted_image(训练时直接使用))
- 湖仓一体天花板,大数据一站式SQL分析技术实践
- 跨湖跨仓场景下如何实现海量数据分钟级分析
- 基于多源数据画像的失败用例智能分析
- 利用 Flask 动态展示 Pyecharts 图表数据的几种方法
- 第四次考核 Jimmy 学徒考核 Linux安装软件 rnaseq上游分析-2 ascp kingfisher数据下载ena Linux高速下载 Linux下载网页内容 rna-seq上游Linux
- SmaterWeatherApi---签名加密和数据訪问--简单粗暴一步搞定
- Rplidar学习(四)—— ROS下进行rplidar雷达数据采集源码分析
- Intel TDT检测 & PMU数据采集分析——todo,待使用实际恶意样本跑数据分析效果
- wazuh hips规则引擎和ossec的差异分析——本质上语法层面和ossec没有变化,但是公共字段提取出来了,同时正则匹配数据提取灵活性更强
- 伪基站,卒于5G——本质上是基于网络和UE辅助的伪基站检测,就是将相邻基站的CI、信号强度等信息通过测量报告上报给网络,网络结合网络拓扑、配置信息等相关数据,对所有数据进行综合分析,确认在某个区域中是否存在伪基站
- 基于Python项目的Redis缓存消耗内存数据简单分析(附详细操作步骤)
- 行为分析(商用级别)05 -使用标注工具标注自己的数据集-落地核心关键(重点篇)
- 数据分析案例-基于PCA主成分分析法对葡萄酒数据进行分析
- Mybatis源码分析之(五)mapper如何将数据库数据转换成java对象的
- 【大数据开发运维解决方案】GoldenGate replicat进程延迟分析步骤