
在大数据里:Hadoop可能是你的救命稻草
用于数据分析的开源Hadoop架构的巨大增长是由其结构化和非结构化数据量的增长所驱动的,并且很多权威组织也预测,未来Hadoop架构还将继续增长,并需要复杂的可访问工具来从数据中提取业务和市场信息。
对于Hadoop来说,前景很乐观——开源框架旨在促进巨大数据集的分布式处理。Hadoop对企业越来越具有吸引力,因为它既可以获取大数据的好处,同时又避免了基础架构费用。
联合市场研究部门最近的一份报告表明,Hadoop市场将实现从2013年到2020年的复合年增长率为58.2%,到2020年整个市场将达到502亿美元,而2012年为15亿美元。
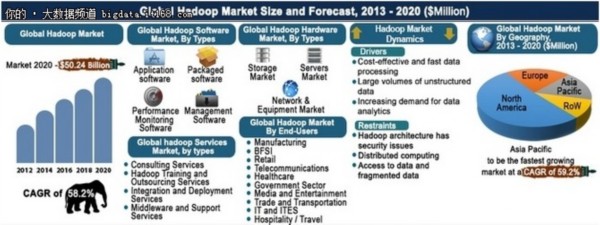
大数据到底有多“大”?根据IBM的说法,每天都会产生2.5万亿字节的数据,世界上所有数据的90%都是在过去两年中创建的。意识到这个巨大的信息商店的价值就需要数据分析工具,这些数据分析工具足够复杂,价格便宜,而且对于各种规模的公司来说都很容易使用。
许多企业认为其专有数据太重要,无法在其他场合存储和处理。然而,云服务现在提供与内部系统相同的安全性和可用性。通过访问云中的数据库,企业也意识到可承受和可扩展的云架构的优势。
Morpheus数据库即服务提供企业对其数据智能操作所需的安全性,高可用性和可扩展性。通过Morpheus使用100%的裸机SSD托管和性能最大化。该服务为Amazon Web Services和其他对等点以及云托管平台提供超低延迟。
Hadoop的Nuts和Bolts大数据分析
Hadoop架构将数据存储和处理都分配到网络上的所有节点。 通过将处理数据的小程序放置在具有更大数据集的节点中,不需要将数据流传输到处理模块。Hadoop调度和资源管理框架执行映射并减少集群环境中的阶段步骤。
Hadoop分布式文件系统(HDFS)数据存储层使用副本来克服节点故障,并针对顺序读取进行了优化,以支持大规模并行处理。当框架扩展到支持Amazon Web Services S3和其他云存储文件系统时,Hadoop的市场真的要起飞了。
尽管由于设置和运行Hadoop集群的复杂性、框架的成本低和可扩展性等优势,在中小型企业中采用Hadoop仍然很难。新服务通过提供受管理并可以使用的Hadoop集群来消除复杂性:无需在集群节点上配置或安装任何服务。
Netflix数据仓库将Hadoop和Amazon S3结合在一起,实现无限可扩展性
Netflix针对其PB级数据仓库,通过Hadoop分布式文件系统选择亚马逊的存储服务(S3),以实现基于云服务的动态可扩展性和无限数据计算能力。Netflix从来自电视,计算机和移动设备的数十亿个流媒体事件中收集数据。
以S3作为其数据仓库,可以为具有数百个节点的Hadoop集群配置各种工作负载,所有这些都能够访问相同的数据。Netflix使用Amazon的弹性MapReduce分发Hadoop,并开发了自己的Hadoop平台即服务,它称之为Genie。Genie允许用户从Hadoop,Pig,Hive和其他工具提交作业,而无需通过RESTful API来配置新的集群或安装新的客户端。
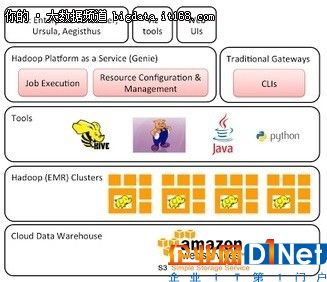
▲Netflix Hadoop-S3数据仓库在广泛分布的网络中提供了无与伦比的数据和计算能力。
Wired的Marco Visibelli在2014年8月13日的文章中解释说,结合Hadoop和云服务有显着的潜力。Visibelli描述了公司如何利用Big Data进行预测,通过Amazon Web Services从小型项目扩展,并在小项目取得成功的同时进行扩展。例如,一家欧洲汽车制造商使用Hadoop将几个供应商数据库结合到一个单一的15TB数据库中,两年内节省了1600万美元。
Hadoop为各种规模的组织打开了“大数据”大门。 利用Morpheus数据库作为服务的云服务的可扩展性,安全性,可访问性和可承受性的项目有更大的成功机会。
本文转自d1net(转载)
大数据基础之初识Hadoop 你好看官,里面请!今天笔者讲的是大数据基础:初识Hadoop。不懂可以在评论区留言,我看到会及时回复。 注意:本文仅用与学习参考,不可用于商业用途。
【Hadoop技术栈篇】认识Hadoop,起源和发展 Hadoop是Apache旗下的一个用java语言实现开源软件框架,是一个开发和运行处理大规模数据的软件平台。允许使用简单的编程模型在大量计算机集群上对大型数据集进行分布式处理。
相关文章
- 报错:Flink Hadoop is not in the classpath/dependencies
- Hadoop和大数据:60款顶级开源工具
- 对话Hadoop之父Doug Cutting|大数据和开源的未来
- Lars George , 关于Hadoop和HBase的Blog
- 大数据探索:在树莓派上通过 Apache Spark on YARN 搭建 Hadoop 集群
- 15-Hadoop解决数据倾斜方法
- 浅析 Hadoop 中的数据倾斜
- hadoop job解决大数据量关联时数据倾斜的一种办法
- 《Hadoop实战手册》一1.3 使用distcp实现集群间数据复制
- 《Hadoop实战手册》一1.9 使用Pig从HDFS导出数据到MongoDB
- Hadoop案例(一)之日志清洗
- 《深入理解大数据:大数据处理与编程实践》一一第2章 Hadoop系统的安装与操作管理
- 大数据学习——HADOOP集群搭建
- Deploy custom service on non hadoop node with Apache Ambari
- 别老扯什么hadoop,你的数据根本不够大
- 《Spark与Hadoop大数据分析》一一3.5 持久化与缓存
- 《Hadoop与大数据挖掘》——2.4 Hadoop编程开发
- Kudu:为大数据快速分析量身定制的 Hadoop 存储系统
- Hadoop 2.5.1集群安装配置
- 【Hadoop学习项目】2. 数据去重
- Hadoop Serialization -- hadoop序列化具体解释 (2)【Text,BytesWritable,NullWritable】
- 大数据:Spark和Hadoop是友非敌
- 【大数据Hadoop】HDFS3.3.1-Namenode系列源码阅读
- 【大数据Hadoop】HDFS-Namenode-bootstrapStandby同步元数据的源码步骤分析
- 【大数据】记一次hadoop集群missing block问题排查和数据恢复
- Hadoop家族学习路线图--转载
- windows环境下一键搭建大数据开发环境,Java+hadoop+hbase+elasticsearch+apache-tomcat,对上海出租车历史数据进行了分析并做了轨迹数据可视化展现