
单阶段实例分割SOLO-v1& SOLO-v2论文笔记
参考代码:
这里提到的v1和v2版本分别对应的文章名称:
- SOLO: Segmenting Objects by Locations
- SOLOv2: Dynamic and Fast Instance Segmentation
1. 概述
导读:SOLO系列的文章解决的是单阶段的实例分割任务,相比之前的检测-分割(top-down)的方法在操作流程上简化不少,同时取得的效果也是不错的。在单阶段的实例分割任务中由于缺少检测带来的位置确定性,因而需要对实例分割的中的像素位置进行显式建模。在这篇文章中通过将输入的特征图划分为 S ∗ S S*S S∗S的网络(在实际数据分布下物体与物体中心的距离也是足够的,能够满足网格划分从而区分开不同的物体,物体不密集的情况-_-||),也就是通过网格划分的方式确定位置与实例mask的对应关系,并在对应的网格上完成目标的分类和网格对应实例mask的预测任务。
将文章的实例分割算法与Mask RCNN方法进行比较,见下图所示:
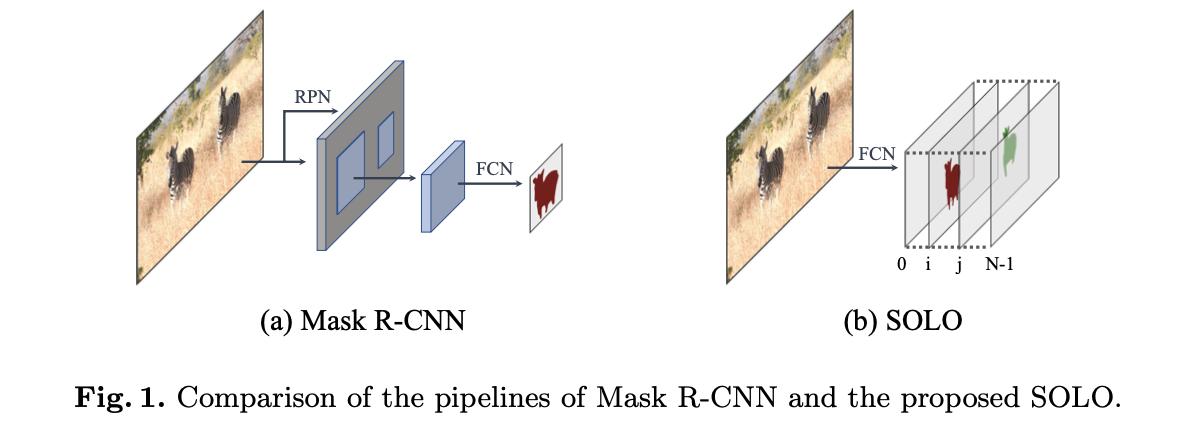
SOLO的方法直接建立位置与mask的关系,从而完成实例的分割。
2. SOLO-v1
2.1 网络结构
文章提出的网络结构见下图所示:
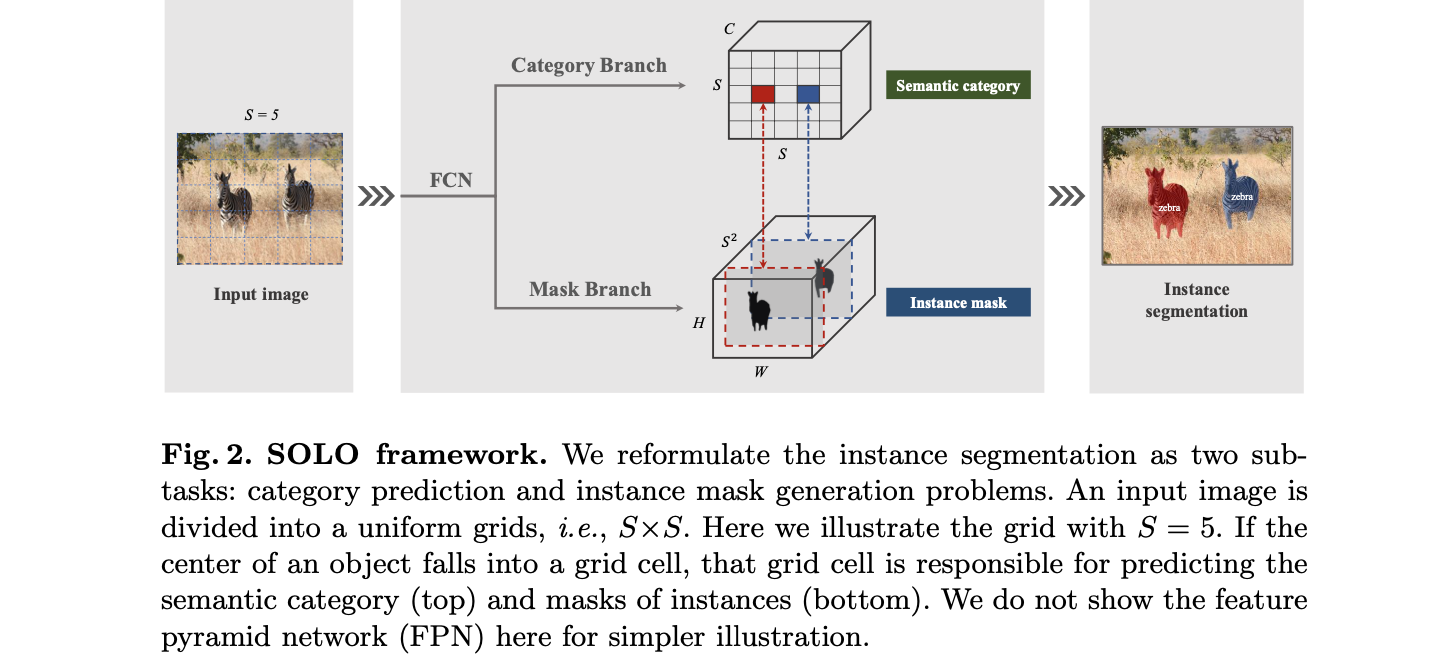
文章的方法首先使用FPN网络进行特征提取,之后预测头通过共享权重的策略实现实例mask的分割,这里采用了FPN网络的
P
2
−
P
6
P2-P6
P2−P6的特征图(多尺度预测下的性能最佳),其对应的网络尺寸为
S
∈
[
40
,
36
,
24
,
16
,
12
]
S\in[40,36,24,16,12]
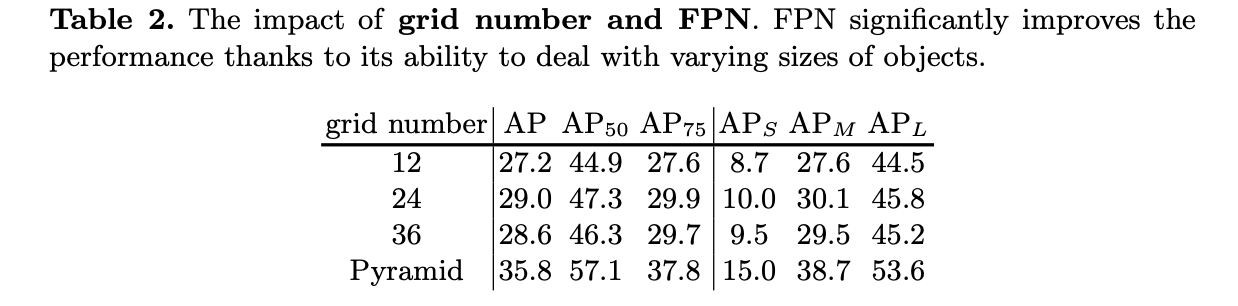
S∈[40,36,24,16,12],对应网格大小和数量对性能的影响见下表:
2.2 预测头
这里使用到的预测头其结构见下图所示:
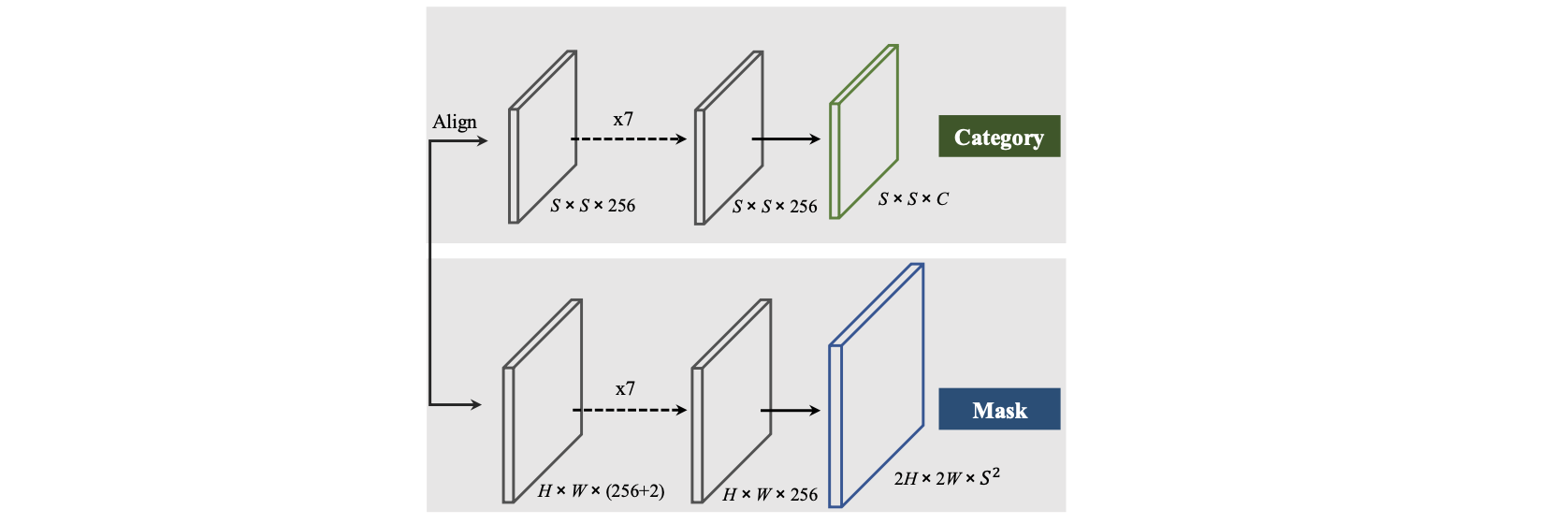
分类分支:
若当前特征图需要的网格数量为
S
∗
S
S*S
S∗S,那么这里会首先将输入的特征进行resize操作(也就是对应上图中的Align操作),从而得到空间分辨率为
S
∗
S
S*S
S∗S的特征图,之后就是对这些网格进行类别回归。对于这些特征图的分类标签是通过判断GT box的中心区域落在是否落在对应网格内部确定的,落在了对应的网格内部那么对应的网络回归的目标就是GT box的类别。其中这里对GT box中心区域的确定使用的是
(
c
x
,
c
y
,
ϵ
h
,
ϵ
w
)
,
ϵ
=
0.2
(c_x,c_y,\epsilon h,\epsilon w),\epsilon=0.2
(cx,cy,ϵh,ϵw),ϵ=0.2。
mask分支:
由于CNN网络(conv+pool)存在一定的平移不变性,这就会给mask的定位带来一定的影响,那么解决的办法便是显式为mask分支添加空间坐标先验,也就是X和Y两个方向的归一化坐标:
# mmdet/models/anchor_heads/solo_head.py#L148
# concat coord
x_range = torch.linspace(-1, 1, ins_feat.shape[-1], device=ins_feat.device)
y_range = torch.linspace(-1, 1, ins_feat.shape[-2], device=ins_feat.device)
y, x = torch.meshgrid(y_range, x_range)
y = y.expand([ins_feat.shape[0], 1, -1, -1])
x = x.expand([ins_feat.shape[0], 1, -1, -1])
coord_feat = torch.cat([x, y], 1)
之后要做的便是将 S ∗ S S*S S∗S的网格与对应的mask对应起来,这里采用的是网格中的块儿和mask在预测的channel上一一对应的形式,也就是一个网格中的块儿会根据分类的类别会存在一个与之对应的mask。这样下来就将分类和mask组合起来完成了实例分割任务。
这里的实现代码可以参考:
# mmdet/models/anchor_heads/solo_head.py
mask头解耦的形式:
在上述的过程中会存在mask的预测结果channel和网格呈现
S
∗
S
S*S
S∗S的倍数关系,特别是在一些FPN浅层的特征图上,其channel是很大的。对此文章使用X和Y方向解耦(这里使用到的坐标先验会分别concat到对应的分支)的形式减少channel的数量,则上面的mask头就可以改为下面的样子:
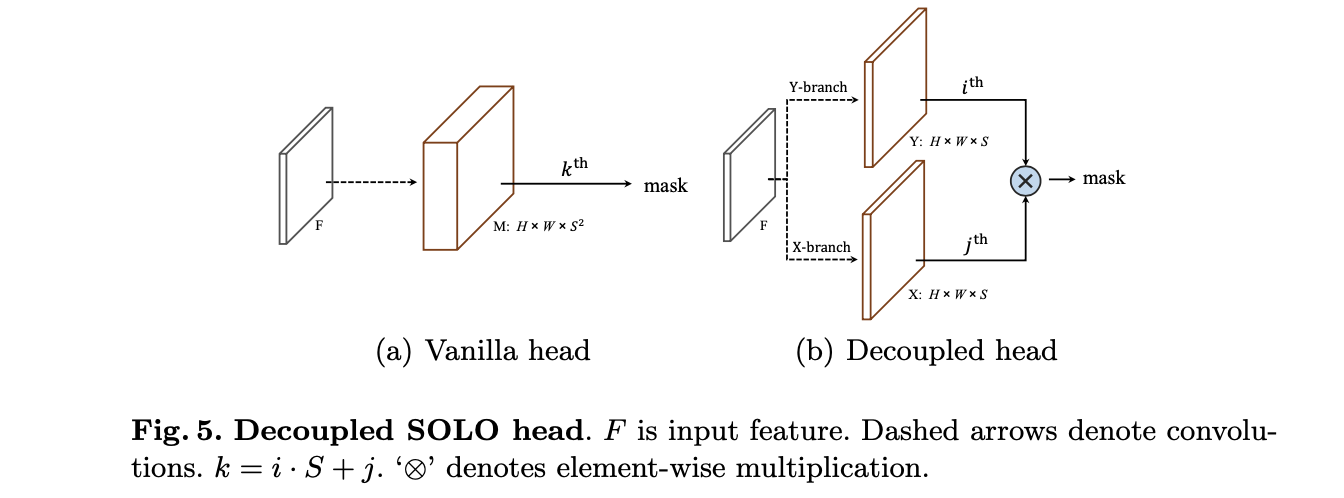
则原本在网格
S
∗
S
S*S
S∗S位置为
(
i
,
j
)
(i,j)
(i,j)的mask其表达被描述为了:
M
i
,
j
=
s
i
g
m
o
i
d
(
X
i
)
⊗
s
i
g
m
o
i
d
(
Y
j
)
M_{i,j}=sigmoid(X_i)\otimes sigmoid(Y_j)
Mi,j=sigmoid(Xi)⊗sigmoid(Yj)
也就是对应了上图右边的形式。
对于训练的损失函数是分类损失加上mask分割损失的形式:
L
=
L
c
a
t
e
+
λ
(
L
m
a
s
k
b
c
e
+
L
m
a
s
k
d
i
c
e
)
L=L_{cate}+\lambda(L_{mask}^{bce}+L_{mask}^{dice})
L=Lcate+λ(Lmaskbce+Lmaskdice)
2.3 消融实验
位置编码特征对性能的影响:
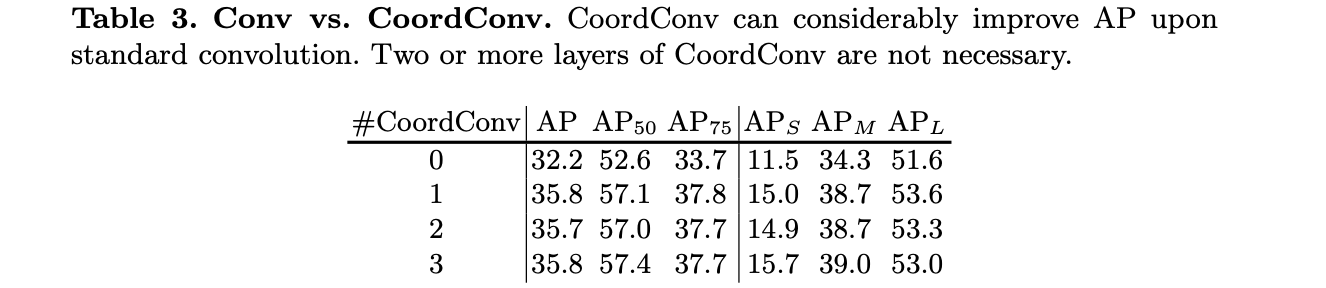
预测头中重叠卷积的数量(depth)对性能的影响:

2.4 实验结果
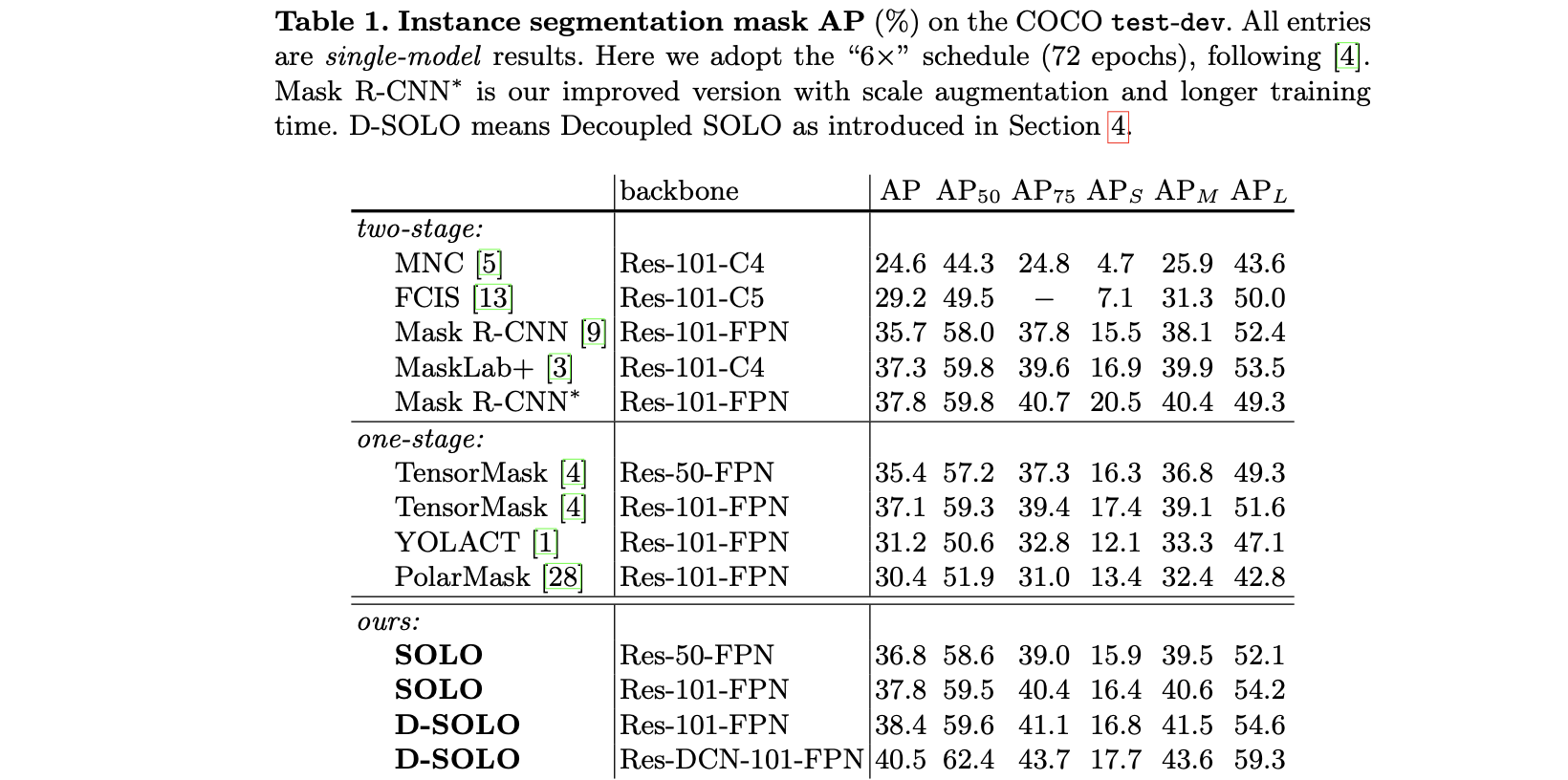
3. SOLO-v2
SOLO-v2是在v1版本的基础上进行改进而来的,其改进的出发点源自于下面3个理由:
- 1)v1版本中通过在channel中编码位置的形式实现实例分割,但是这样带来的开销是比较大的,这就导致了整体算法的运行效率不是很高;
- 2)v1版本中处理实例分割的mask分辨率比较小,这就导致了实例分割的效果比较差,在这篇文章中通过将FPN网络聚合的形式在高分辨(stride=4)下的实例分割;
- 3)v1中使用的基于pixel的NMS存在耗时的问题,对此开发了基于matrix的NMS算法,从而通过矩阵运算的形式在CUDA设备上加快了计算过程;
将SOLO-v2方法与其它的一些方法进行比较见下图所示:
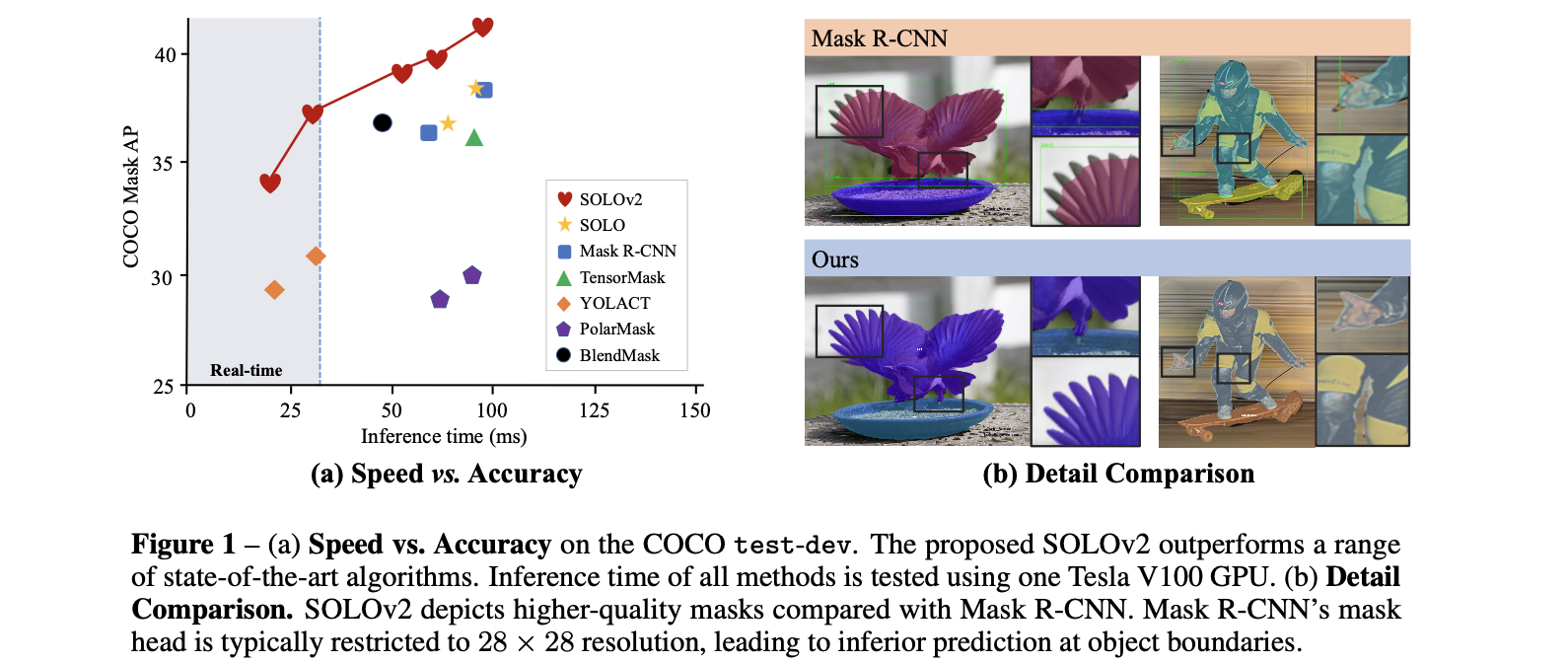
3.1 网络结构
文章的网络结构见下图所示:
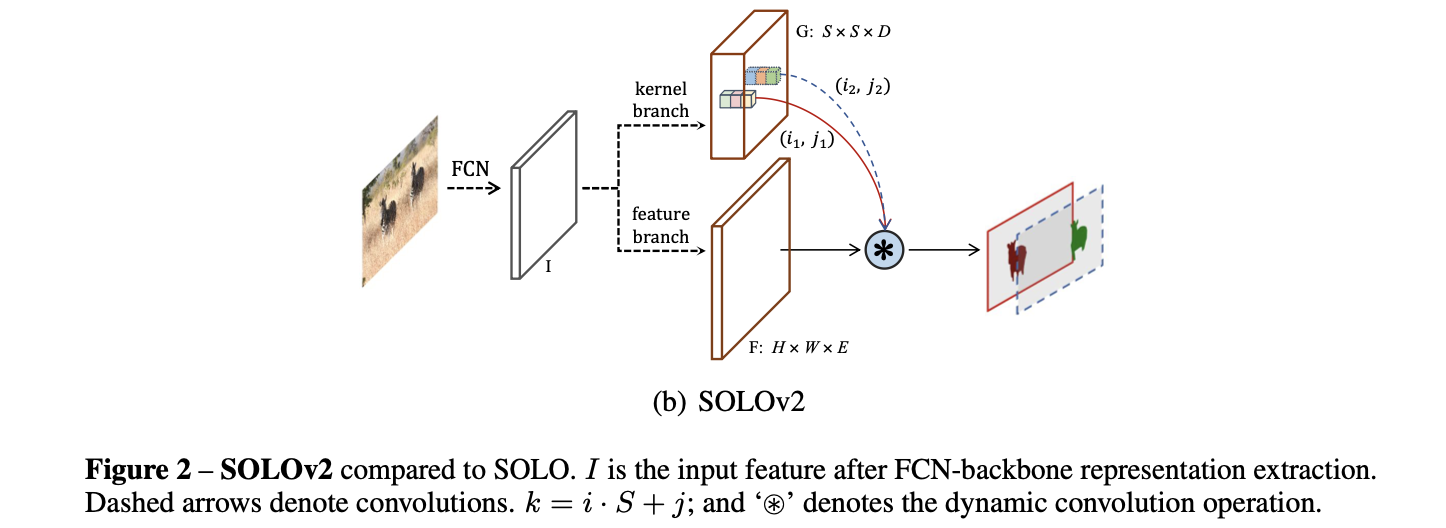
将该网络结构与之前的v1版本进行比较可以看到其中添加了动态的卷积kernel预测(也就是上图中
S
∗
S
S*S
S∗S网格上的点),其原理是通过矩阵相乘的形式得到对应的mask特征:
M
i
,
j
=
G
i
,
j
∗
F
M_{i,j}=G_{i,j}*F
Mi,j=Gi,j∗F
其中,卷积kernel的维度为:
G
i
,
j
∈
R
1
∗
1
∗
D
G_{i,j}\in R^{1*1*D}
Gi,j∈R1∗1∗D,对应的输入特征图的分辨率为:
F
∈
R
H
∗
W
∗
D
F\in R^{H*W*D}
F∈RH∗W∗D。那么接下来就是需要去确定动态的卷积的kernel
G
G
G和所需要的输入特征图
F
F
F了。
动态的卷积的kernel:
该卷积核参数确定是通过卷积的形式实现的,其过程可以参考:
# mmdet/models/anchor_heads/solov2_head.py#L162
# kernel branch
kernel_feat = ins_kernel_feat
seg_num_grid = self.seg_num_grids[idx]
kernel_feat = F.interpolate(kernel_feat, size=seg_num_grid, mode='bilinear')
cate_feat = kernel_feat[:, :-2, :, :]
kernel_feat = kernel_feat.contiguous()
for i, kernel_layer in enumerate(self.kernel_convs):
kernel_feat = kernel_layer(kernel_feat)
kernel_pred = self.solo_kernel(kernel_feat)
特征图F:
特征图的生成过程中参考之前的位置编码将位置信息先验通过channel上concat的形式考虑进去。
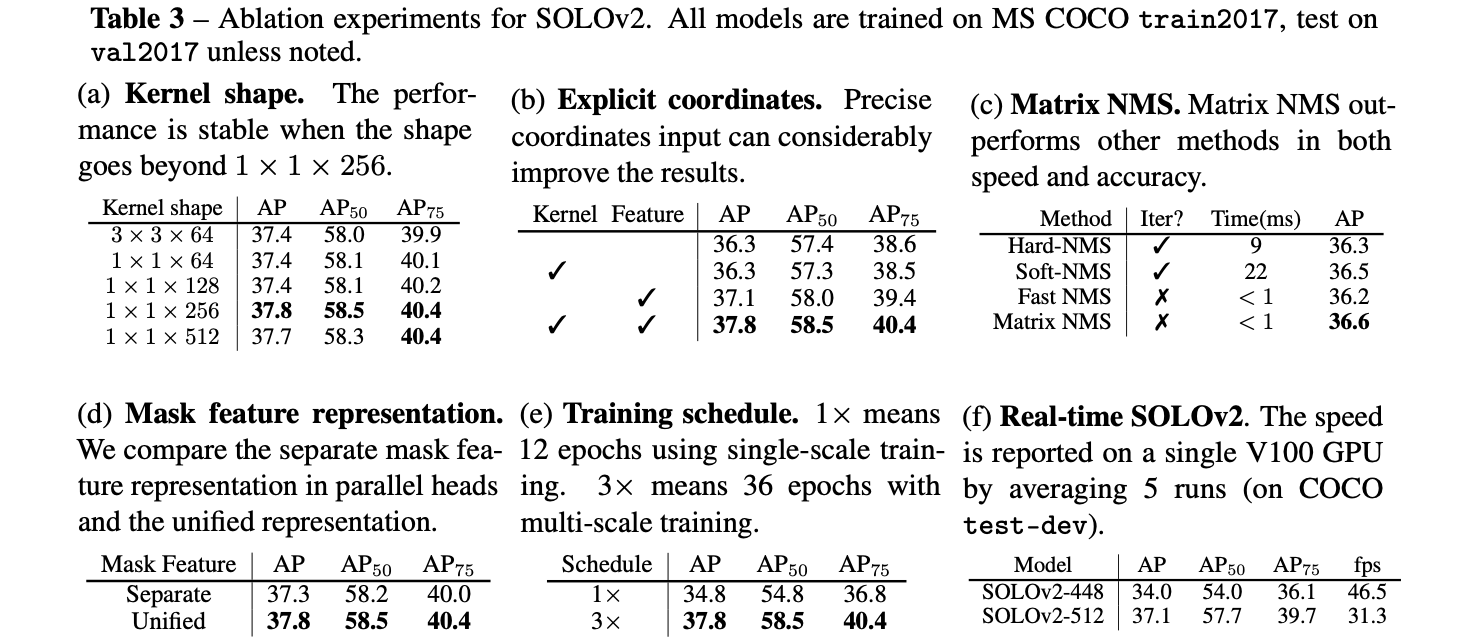
上述设计到的一些超参数其消融实验见下表:
这里的实现代码可以参考:
# mmdet/models/anchor_heads/solov2_head.py
3.2 matrix NMS
这里使用并行设备运算matrix快速的特性,对之前的pixel的计算过程进行改进,从而得到改进之后的NMS:
def matrix_nms(scores, masks, method=’gauss’, sigma=0.5): # scores: mask scores in descending order (N)
# masks: binary masks (NxHxW)
# method: ’linear’ or ’gauss’
# sigma: std in gaussian method
# reshape for computation: Nx(HW)
masks = masks.reshape(N, HxW)
# pre−compute the IoU matrix: NxN
intersection = mm(masks, masks.T)
areas = masks.sum(dim=1).expand(N, N)
union = areas + areas.T − intersection
ious = (intersection / union).triu(diagonal=1)
# max IoU for each: NxN
ious_cmax = ious.max(0)
ious_cmax = ious_cmax.expand(N, N).T # Matrix NMS, Eqn.(4): NxN
if method == ’gauss’: # gaussian
decay = exp(−(ious^2 − ious_cmax^2) / sigma) else: # linear
decay = (1 − ious) / (1 − ious_cmax)
# decay factor: N
decay = decay.min(dim=0) return scores ∗ decay
3.3 实验结果
相关文章
- return & exit . in GO
- 泛函编程(36)-泛函Stream IO:IO数据源-IO Source & Sink
- shell中>/dev/null 2>&1
- [SMS&WAP]实例讲解制作OTA短信来自动配置手机WAP书签[附源码]
- linux 的nohup & 和daemon 总结(转)
- [Bootstrap] 2. class 'row' & 'col-md-x' & 'col-md-offset-x'
- Error: Failed to connect to MySQL server: DBI connect(';
- 【RF库测试】Variable Should not Exist & variable should exist
- 华为OD机试 - 货币单位换算(Java & JS & Python)
- 华为OD机试 - 快递业务站(Java & JS & Python)
- 华为OD机试 - 工号不够用了怎么办?(Java & JS & Python)
- AI&BlockChain:“知名博主独家讲授”人工智能创新应用竞赛【精选实战作品】之《基于计算机视觉、自然语言处理和区块链技术的乘客智能报警系统》案例的界面简介、功能介绍分享之汽车驾驶乘客自动报警
- 翻翻git之---"有趣效果"的自己定义View EasyArcLoading
- VB编程:全局变量&控件数组实例简单计算器-12_彭世瑜_新浪博客
- Redis 作者 Antirez 讲如何实现分布式锁?Redis 实现分布式锁天然的缺陷分析&Redis分布式锁的正确使用姿势!...
- UVA 12103 - Leonardo's Notebook(数论置换群)
- 特征工程--有序类别变量&单数值变量特征工程